第22章: M估计量
22 M估计量
22.1 介绍
到目前为止,在本教科书中,我们主要关注具有显式代数表达式的估计器。然而,许多计量经济学估计量需要通过数值方法来计算。这些估计量统称为非线性估计量。许多属于称为 m 估计器的广泛类别。在教科书的这一部分中,我们描述了计量经济学中广泛使用的一些 m 估计量。它们具有共同的结构,可以统一处理估计和推理。
m 估计量被定义为样本平均值的最小化器
\[ \begin{gathered} \widehat{\theta}=\underset{\theta \in \Theta}{\operatorname{argmin}} S_{n}(\theta) \\ S_{n}(\theta)=\frac{1}{n} \sum_{i=1}^{n} \rho\left(Y_{i}, X_{i}, \theta\right) \end{gathered} \]
其中 \(\rho(Y, X, \theta)\) 是 \((Y, X)\) 的某个函数和参数 \(\theta \in \Theta\)。函数 \(S_{n}(\theta)\) 称为准则函数或目标函数。为了符号简单,设置\(\rho_{i}(\theta)=\rho\left(Y_{i}, X_{i}, \theta\right)\)。
这包括当 \(\rho_{i}(\theta)\) 是负对数密度函数时的最大似然。 “m-估计量”是一个更广泛的类别;前缀“m”代表“最大似然类型”。
本章我们关注的问题是:(1)识别; (2) 估算; (3)一致性; (4)渐近分布; (5)协方差矩阵估计。
22.2 例子
计量经济学中有许多常见的 m 估计量。一些示例包括以下内容。
1.普通最小二乘法:\(\rho_{i}(\theta)=\left(Y_{i}-X_{i}^{\prime} \theta\right)^{2}\)。
非线性最小二乘法:\(\rho_{i}(\theta)=\left(Y_{i}-m\left(X_{i}, \theta\right)\right)^{2}\)(第 23 章)。
最小绝对偏差:\(\rho_{i}(\theta)=\left|Y_{i}-X_{i}^{\prime} \theta\right|\)(第 24 章)。
分位数回归:\(\rho_{i}(\theta)=\left(Y_{i}-X_{i}^{\prime} \theta\right)\left(\tau-\mathbb{1}\left\{\left(Y_{i}-X_{i}^{\prime} \theta\right)<0\right\}\right)\)(第 24 章)。
最大似然:\(\rho_{i}(\theta)=-\log f\left(Y_{i} \mid X_{i}, \theta\right)\)。最后一类 - 最大似然估计 - 包括许多特殊情况的估计器。这包括有限因变量模型的许多标准估计量(第 25-27 章)。为了说明这一点,二元因变量的概率模型为
\[ \mathbb{P}[Y=1 \mid X]=\Phi\left(X^{\prime} \theta\right) \]
其中 \(\Phi(u)\) 是正态累积分布函数。我们将在第 25 章详细研究概率估计。负对数密度函数是
\[ \rho_{i}(\theta)=-Y_{i} \log \left(\Phi\left(X_{i}^{\prime} \theta\right)\right)-\left(1-Y_{i}\right) \log \left(1-\Phi\left(X_{i}^{\prime} \theta\right)\right) . \]
并非所有非线性估计器都是 m 估计器。示例包括矩量法、GMM 和最小距离。
22.3 识别与估算
如果参数向量 \(\theta\) 由观测值的概率分布唯一确定,则该参数向量被识别。这是概率分布的属性,而不是估计量的属性。
然而,在讨论特定估计量时,通常用准则函数来描述识别。假设\(\mathbb{E}|\rho(Y, X, \theta)|<\infty\)。定义
\[ S(\theta)=\mathbb{E}\left[S_{n}(\theta)\right]=\mathbb{E}[\rho(Y, X, \theta)] \]
及其人口最小化
\[ \theta_{0}=\underset{\theta \in \Theta}{\operatorname{argmin}} S(\theta) . \]
如果最小化器 \(\theta_{0}\) 是唯一的,我们就说 \(\theta\) 被 \(S(\theta)\) 标识(或标识点)。
在非线性模型中,很难提供识别参数的一般条件。识别需要逐个模型地进行检查。
根据定义,m 估计器 \(\widehat{\theta}\) 会最小化 \(S_{n}(\theta)\)。当解没有明确的代数表达式时,最小化将以数值方式完成。 《经济学家的概率与统计》第 12 章对此类数值方法进行了回顾。
我们使用上一节的概率模型进行说明。我们使用 \(Y\) 的 CPS 数据集作为个人已婚 \({ }^{1}\) 的指标,并将回归量设置为等于受教育年限、年龄和年龄的平方。我们得到以下估计
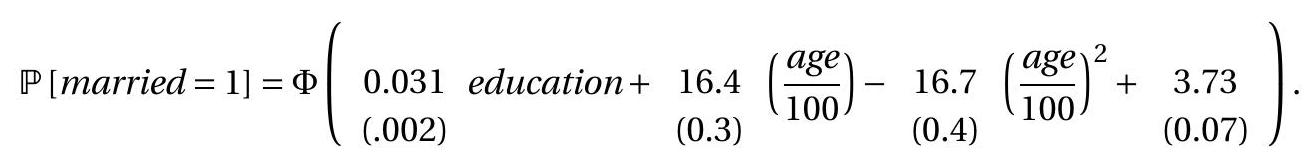
标准误差计算将在第 22.8 节中讨论。在此应用中,我们看到结婚的概率随着受教育年限的增加而增加,并且是年龄的递增凹函数。
22.4 一致性
似乎可以合理地预期,如果确定了一个参数,那么我们应该能够一致地估计该参数。对于线性估计器,我们通过将 WLLN 应用于
\({ }^{1}\) 如果 marital 等于 1,2 或 3,我们定义结婚 \(=1\)。估计器的显式代数表达式。这对于非线性估计器来说是不可能的,因为它们没有显式的代数表达式。
相反,我们可以使用 m 估计器最小化标准函数 \(S_{n}(\theta)\),它本身就是一个样本平均值。对于任何给定的 \(\theta\),WLLN 显示 \(S_{n}(\theta) \underset{p}{\longrightarrow} S(\theta)\)。直观地说,\(S_{n}(\theta)\) 的最小值(m 估计器 \(\widehat{\theta}\) )将在概率上收敛到 \(S(\theta)\) 的最小值(参数 \(\theta_{0}\) )。然而,WLLN 本身不足以进行此扩展。
- 非均匀收敛
.jpg)
- 一致收敛
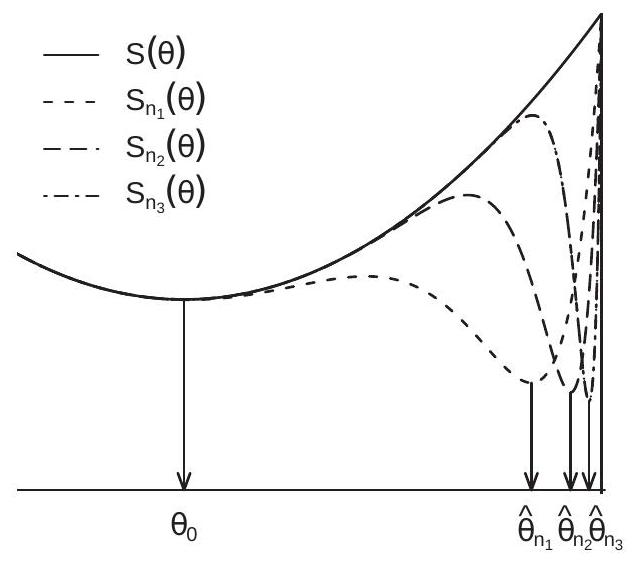
图 22.1:非均匀收敛与均匀收敛
要了解问题,请查看图 22.1(a)。这显示了 \(n\) 三个值的函数 \(S_{n}(\theta)\) 序列(虚线)。图中所示的是,对于每个 \(\theta\),函数 \(S_{n}(\theta)\) 向极限函数 \(S(\theta)\) 收敛。然而,对于每个 \(n\),函数 \(S_{n}(\theta)\) 在右侧区域都有严重的下降。结果是样本最小化器 \(\widehat{\theta}_{n}\) 收敛到参数空间的右极限。相反,极限准则 \(S_{n}(\theta)\) 的极小值 \(\theta_{0}\) 位于参数空间的内部。我们观察到,对于每个 \(S_{n}(\theta)\),\(S_{n}(\theta)\) 收敛到 \(S_{n}(\theta)\),但最小化器 \(S_{n}(\theta)\) 不会收敛到 \(S_{n}(\theta)\)。
排除这种病态行为的充分条件是参数空间 \(\Theta\) 上的均匀收敛-均匀性。正如我们在定理 22.1 中所示,\(S_{n}(\theta)\) 到 \(S(\theta)\) 的概率一致收敛足以证明 m 估计量 \(\widehat{\theta}\) 对于 \(\theta_{0}\) 是一致的。
定义 22.1 \(S_{n}(\theta)\) 在 \(\theta \in \Theta\) 上均匀地收敛于 \(S(\theta)\) 如果
\[ \sup _{\theta \in \Theta}\left|S_{n}(\theta)-S(\theta)\right| \underset{p}{\longrightarrow} 0 \]
作为 \(n \rightarrow \infty\)
均匀收敛排除了 \(S_{n}(\theta)\) 在 \(\theta\) 和 \(n\) 上一致的不稳定摆动(例如,图 22.1(a) 中发生的情况)。这个想法如图 22.1(b) 所示。粗实线是函数 \(S(\theta)\)。虚线是 \(S(\theta)+\varepsilon\) 和 \(S(\theta)-\varepsilon\)。细实线是样本标准 \(S_{n}(\theta)\)。该图说明了样本标准满足 \(\sup _{\theta \in \Theta}\left|S_{n}(\theta)-S(\theta)\right|<\varepsilon\) 的情况。显示的样本标准上下波动,但保持在 \(S_{n}(\theta)\) 的 \(\varepsilon\) 范围内。如果图 22.1(b) 所示的事件对于 \(S_{n}(\theta)\) 足够大、对于任何任意小的 \(S_{n}(\theta)\) 都以高概率成立,则一致收敛成立。
定理 \(22.1 \hat{\theta} \underset{p}{\longrightarrow} \theta_{0}\) 等于 \(n \rightarrow \infty\) 如果
\(S_{n}(\theta)\) 在 \(\theta \in \Theta\) 上均匀地收敛到 \(S(\theta)\)。
\(\theta_{0}\) 唯一地最小化 \(S(\theta)\),因为对于所有 \(\epsilon>0\),
\[ \inf _{\theta:\left\|\theta-\theta_{0}\right\| \geq \epsilon} S(\theta)>S\left(\theta_{0}\right) . \]
定理 \(22.1\) 表明 m 估计量与其总体参数是一致的。只有两个条件。首先,准则函数在概率上均匀收敛于其期望值,其次,最小值 \(\theta_{0}\) 是唯一的。该假设排除了 \(\lim _{j} S\left(\theta_{j}\right)=S\left(\theta_{0}\right.\) ) 对于某些序列 \(\theta_{j} \in \Theta\) 不收敛到 \(\theta_{0}\) 的可能性。
定理 \(22.1\) 的证明在第 22.9 节中提供。
22.5 统一大数定律
定义 \(22.1\) 的一致收敛是一个高级假设。在本节中,我们提供较低级别的充分条件。
定理 22.2 一致大数定律 (ULLN) 假设
\(\left(Y_{i}, X_{i}\right)\) 是独立同分布的。
\(\rho(Y, X, \theta)\) 在 \(\theta \in \Theta\) 中连续,概率为 1。
\(|\rho(Y, X, \theta)| \leq G(Y, X)\) 其中 \(\mathbb{E}[G(Y, X)]<\infty\)。
\(\Theta\) 是紧凑的。
然后\(\sup _{\theta \in \Theta}\left|S_{n}(\theta)-S(\theta)\right| \underset{p}{\longrightarrow} 0\)
定理\(22.2\)是在《经济学家概率论与数理统计》定理\(18.2\)中成立的。
如果 \(\rho(y, x, \theta)\) 在 \(\theta\) 中连续,或者不连续点出现在零概率点,则假设 2 成立。这允许计量经济学中最相关的应用。经济学家概率与统计定理 \(18.2\) 还提供了基于有限括号或覆盖数字的条件,从而具有更多的通用性。假设 3 是有限期望条件 \(\mathbb{E}[\rho(Y, X, \theta)]<\infty\) 的轻微强化。函数 \(G(Y, X)\) 称为包络。 ULLN 扩展到时间序列和聚类样本。有关聚类样本,请参阅 B. E. Hansen 和 S. Lee (2019)。
结合定理 \(22.1\) 和 \(22.2\),我们获得了一组一致估计的条件。
定理 \(22.3 \hat{\theta} \underset{p}{\longrightarrow} \theta_{0}\) 等于 \(n \rightarrow \infty\) 如果
\(\left(Y_{i}, X_{i}\right)\) 是独立同分布的。
\(\rho(Y, X, \theta)\) 在 \(\theta \in \Theta\) 中连续,概率为 1。
\(|\rho(Y, X, \theta)| \leq G(Y, X)\) 其中 \(\mathbb{E}[G(Y, X)]<\infty\)。
\(\Theta\) 是紧凑的。
\(\theta_{0}\) 唯一地最小化\(S(\theta)\)。
22.6 渐近分布
我们现在建立渐近分布理论。我们从非正式的演示开始,在高水平条件下呈现一般结果,然后讨论假设和条件。定义
\[ \begin{aligned} \psi(Y, X, \theta) &=\frac{\partial}{\partial \theta} \rho(Y, X, \theta) \\ \bar{\psi}_{n}(\theta) &=\frac{\partial}{\partial \theta} S_{n}(\theta) \\ \psi(\theta) &=\frac{\partial}{\partial \theta} S(\theta) . \end{aligned} \]
还定义 \(\psi_{i}(\theta)=\psi\left(Y_{i}, X_{i}, \theta\right)\) 和 \(\psi_{i}=\psi_{i}\left(\theta_{0}\right)\)。
由于 m 估计器 \(\widehat{\theta}\) 最小化了 \(S_{n}(\theta)\),因此它满足 \({ }^{2}\) 一阶条件 \(0=\bar{\psi}_{n}(\widehat{\theta})\)。将右侧展开为关于 \(\theta_{0}\) 的一阶泰勒展开式。当 \(\widehat{\theta}\) 位于 \(\theta_{0}\) 的邻域时,这是有效的,根据定理 22.1,这对于 \(n\) 来说足够大。这产生
\[ 0=\bar{\psi}_{n}(\widehat{\theta}) \simeq \bar{\psi}_{n}\left(\theta_{0}\right)+\frac{\partial^{2}}{\partial \theta \partial \theta^{\prime}} S_{n}\left(\theta_{0}\right)\left(\widehat{\theta}-\theta_{0}\right) . \]
重写,我们得到
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right) \simeq-\left(\frac{\partial^{2}}{\partial \theta \partial \theta^{\prime}} S_{n}\left(\theta_{0}\right)\right)^{-1}\left(\sqrt{n} \bar{\psi}_{n}\left(\theta_{0}\right)\right) . \]
考虑这两个组成部分。首先,由WLLN
\[ \frac{\partial^{2}}{\partial \theta \partial \theta^{\prime}} S_{n}\left(\theta_{0}\right)=\frac{1}{n} \sum_{i=1}^{n} \frac{\partial^{2}}{\partial \theta \partial \theta^{\prime}} \rho\left(Y_{i}, X_{i}, \theta_{0}\right) \underset{p}{\longrightarrow} \mathbb{E}\left[\frac{\partial^{2}}{\partial \theta \partial \theta^{\prime}} \rho_{i}\left(Y, X, \theta_{0}\right)\right] \stackrel{\text { def }}{=} \boldsymbol{Q} \]
\({ }^{2}\) 如果\(\widehat{\theta}\) 是一个内部解。由于 \(\widehat{\theta}\) 是一致的,如果 \(\theta_{0}\) 位于参数空间 \(\Theta\) 的内部,则出现这种情况的概率接近 1。第二,
\[ \sqrt{n} \bar{\psi}_{n}\left(\theta_{0}\right)=\frac{1}{\sqrt{n}} \sum_{i=1}^{n} \psi_{i} . \]
由于 \(\theta_{0}\) 最小化 \(S(\theta)=\mathbb{E}\left[\rho_{i}(\theta)\right]\) 它满足一阶条件
\[ 0=\psi\left(\theta_{0}\right)=\mathbb{E}\left[\psi\left(Y, X, \theta_{0}\right)\right] . \]
因此(22.2)中的被加数均值为零。应用 CLT,该总和在分布中收敛到 \(\mathrm{N}(0, \Omega)\),其中 \(\Omega=\mathbb{E}\left[\psi_{i} \psi_{i}^{\prime}\right]\)。我们推断
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right) \underset{d}{\longrightarrow} \boldsymbol{Q}^{-1} \mathrm{~N}(0, \Omega)=\mathrm{N}\left(0, \boldsymbol{Q}^{-1} \Omega \boldsymbol{Q}^{-1}\right) . \]
使这一推导变得严格的技术障碍是证明泰勒展开式 (22.1) 的合理性。这可以通过 \(\rho_{i}\left(\theta_{0}\right)\) 的二阶导数的平滑度来完成。基于经验过程理论的替代(更高级)论证使用较弱的假设。放
\[ \begin{aligned} \boldsymbol{Q}(\theta) &=\frac{\partial^{2}}{\partial \theta \partial \theta^{\prime}} S(\theta) \\ \boldsymbol{Q} &=\boldsymbol{Q}\left(\theta_{0}\right) \end{aligned} \]
令 \(\mathscr{N}\) 为 \(\theta_{0}\) 的某个邻域。
定理 22.4 假设定理 \(22.1\) 的条件成立,加上
1.\(\mathbb{E}\left\|\psi\left(Y, X, \theta_{0}\right)\right\|^{2}<\infty\)
2.\(Q>0\)。
\(\boldsymbol{Q}(\theta)\) 在 \(\theta \in \mathscr{N}\) 中连续。
对于所有 \(\theta_{1}, \theta_{2} \in \mathcal{N},\left\|\psi\left(Y, X, \theta_{1}\right)-\psi\left(Y, X, \theta_{2}\right)\right\| \leq B(Y, X)\left\|\theta_{1}-\theta_{2}\right\|\) 其中 \(\mathbb{E}\left[B(Y, X)^{2}\right]<\infty\)
\(\theta_{0}\) 位于 \(\Theta\) 的内部。
然后作为 \(n \rightarrow \infty, \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right) \underset{d}{\longrightarrow} \mathrm{N}(0, \boldsymbol{V})\) 其中 \(\boldsymbol{V}=\boldsymbol{Q}^{-1} \Omega \boldsymbol{Q}^{-1}\)。
定理 \(22.4\) 的证明在 \(22.9\) 节中给出。
在某些情况下,渐近协方差矩阵会简化。主要情况是正确指定的最大似然估计,其中 \(\boldsymbol{Q}=\Omega\) 和 \(\boldsymbol{V}=\boldsymbol{Q}^{-1}=\Omega^{-1}\)。
假设 1 表明分数 \(\psi\left(Y, X, \theta_{0}\right)\) 具有有限的二阶矩。这是应用 CLT 所必需的。假设2是满秩条件,与识别相关。假设 3 的充分条件是分数 \(\psi(Y, X, \theta)\) 连续可微,但这不是必要的。假设 3 更广泛,允许不连续的 \(\psi(Y, X, \theta)\),只要它的期望是连续且可微的。假设 4 表明 \(\psi(Y, X, \theta)\) 对于 \(\theta\) 在 \(\theta_{0}\) 附近是 Lipschitz 连续的。为了证明均值展开的应用是合理的,需要假设 5。
22.7 更广泛条件下的渐近分布*
定理 \(22.4\) 中的假设 4 要求 \(\psi(Y, X, \theta)\) 是 Lipschitz 连续的。虽然这在大多数应用中都适用,但在包括分位数回归在内的一些重要应用中却违反了这一点。在这种情况下,我们可以诉诸替代的正则条件。这些更灵活,但不太直观。
以下结果是 Lipschitz 连续性的简单概括。
定理 22.5 如果将假设 4 替换为以下条件,则定理 \(22.4\) 的结果成立: 对于所有 \(\delta>0\) 和所有 \(\theta_{1} \in \mathcal{N}\),
\[ \left(\mathbb{E}\left[\sup _{\left\|\theta-\theta_{1}\right\|<\delta}\left\|\psi(Y, X, \theta)-\psi\left(Y, X, \theta_{1}\right)\right\|^{2}\right]\right)^{1 / 2} \leq C \delta^{\psi} \]
对于一些 \(C<\infty\) 和 \(0<\psi<\infty\)。
请参阅《经济学家概率与统计》定理 \(18.5\) 或 Andrews (1994) 的定理 5。
当不连续性以零概率出现时,界限 (22.4) 对于许多不连续 \(\psi(Y, X, \theta)\) 的例子都成立。
接下来我们将展示一组灵活的结果。
定理 22.6 如果将假设 4 替换为以下内容,则定理 \(22.4\) 的结果成立。首先,对于 \(\theta \in \mathcal{N},\|\psi(Y, X, \theta)\| \leq G(Y, X)\) 和 \(\mathbb{E}\left[G(Y, X)^{2}\right]<\) \(\infty\)。其次,下列条件之一成立。
\(\psi(y, x, \theta)\) 是 Lipschitz 连续的。
\(\psi(y, x, \theta)=h\left(\theta^{\prime} \psi(x)\right)\) 其中 \(h(u)\) 具有有限的总变差。
\(\psi(y, x, \theta)\) 是通过加法、乘法、最小值、最大值和复合获得的第 1 部分和第 2 部分中形式的函数的组合。
\(\psi(y, x, \theta)\) 是 Vapnik-Červonenkis (VC) 类。
参见《经济学家的概率与统计》定理 18.6 或 Andrews (1994) 的定理 2 和定理 3。
第 2 部分中的函数 \(h\) 允许使用不连续函数,包括指示符和符号函数。第 3 部分表明,满足第 2 部分的条件的平滑(Lipschitz)函数和不连续函数的组合是允许的。这涵盖了许多相关应用,包括分位数回归。第 4 部分规定了一个一般条件,即 \(\psi(y, x, \theta)\) 是一个 VC 类。由于我们不会在本教科书中使用这个属性,因此我们不会进一步讨论这一点,而是请感兴趣的读者参考任何有关经验过程的教科书。
定理 \(22.5\) 和 \(22.6\) 提供了 \(\psi(y, x, \theta)\) 的替代条件(Lipschitz 连续性除外),可用于建立 m 估计量的渐近正态性。
22.8 协方差矩阵估计
\(\boldsymbol{V}\) 的标准估计量采用三明治形式。我们通过以下方式估计 \(\Omega\)
\[ \widehat{\Omega}=\frac{1}{n} \sum_{i=1}^{n} \widehat{\psi}_{i} \widehat{\psi}_{i}^{\prime} \]
其中 \(\widehat{\psi}_{i}=\frac{\partial}{\partial \theta} \rho_{i}(\widehat{\theta})\).当 \(\rho_{i}(\theta)\) 二次可微时,\(\boldsymbol{Q}\) 的估计量为
\[ \widehat{\boldsymbol{Q}}=\frac{1}{n} \sum_{i=1}^{n} \frac{\partial^{2}}{\partial \theta \partial \theta^{\prime}} \rho_{i}(\widehat{\theta}) . \]
当 \(\rho_{i}(\theta)\) 不可二阶微分时,则根据具体情况构建 \(\boldsymbol{Q}\) 的估计器。
给定 \(\widehat{\Omega}\) 和 \(\widehat{\boldsymbol{Q}}\),\(\boldsymbol{V}\) 的估计量为
\[ \widehat{\boldsymbol{V}}=\widehat{\boldsymbol{Q}}^{-1} \widehat{\Omega} \widehat{\boldsymbol{Q}}^{-1} . \]
可以通过乘以自由度缩放来调整 \(\widehat{\boldsymbol{V}}\),例如 \(n /(n-k)\),其中 \(k=\) \(\operatorname{dim}(\theta)\)。没有正式的指导。
对于最大似然估计器,标准协方差矩阵估计器是 \(\widehat{\boldsymbol{V}}=\widehat{\boldsymbol{Q}}^{-1}\)。这种选择对于错误指定来说并不稳健。因此,建议使用稳健版本(22.5),例如使用 Stata 中的“, \(r\)”选项。不幸的是,这在实践中并没有统一执行。
对于聚类和时间序列观测,估计器 \(\widehat{\boldsymbol{Q}}\) 不变,但估计器 \(\widehat{\Omega}\) 发生变化。对于聚类样本来说是
\[ \widehat{\Omega}=\frac{1}{n} \sum_{g=1}^{G}\left(\sum_{\ell=1}^{n_{g}} \widehat{\psi}_{\ell g}\right)\left(\sum_{\ell=1}^{n_{g}} \widehat{\psi} \widehat{\psi}_{\ell g}\right)^{\prime} . \]
对于时间序列数据,如果分数 \(\psi_{i}\) 连续不相关(当动态正确指定模型时会发生这种情况),则估计器 \(\widehat{\Omega}\) 不会改变。否则,可以使用 Newey-West 协方差矩阵估计器,并且等于
\[ \widehat{\Omega}=\sum_{\ell=-M}^{M}\left(1-\frac{|\ell|}{M+1}\right) \frac{1}{n} \sum_{1 \leq t-\ell \leq n} \widehat{\psi}_{t-\ell} \widehat{\psi}_{t}^{\prime} . \]
参数估计的标准误差是通过对 \(n^{-1} \widehat{\boldsymbol{V}}\) 的对角线元素求平方根来形成的。
22.9 技术证明*
定理22.1 的证明 证明分两步进行。首先,我们展示 \(S(\widehat{\theta}) \underset{p}{\longrightarrow} S(\theta)\)。其次,我们证明这意味着 \(\widehat{\theta} \underset{p}{\longrightarrow} \theta\)。
由于 \(\theta_{0}\) 最小化了 \(S(\theta), S\left(\theta_{0}\right) \leq S(\widehat{\theta})\)。因此
\[ \begin{aligned} 0 & \leq S(\widehat{\theta})-S\left(\theta_{0}\right) \\ &=S(\widehat{\theta})-S_{n}(\widehat{\theta})+S_{n}\left(\theta_{0}\right)-S\left(\theta_{0}\right)+S_{n}(\widehat{\theta})-S_{n}\left(\theta_{0}\right) \\ & \leq 2 \sup _{\theta \in \Theta}\left\|S_{n}(\theta)-S(\theta)\right\| \underset{p}{\longrightarrow} . \end{aligned} \]
第二个不等式利用 \(\hat{\theta}\) 最小化 \(S_{n}(\theta)\) 和 \(S_{n}(\widehat{\theta}) \leq S_{n}\left(\theta_{0}\right)\) 的事实,并用上确值替换其他两个成对比较。最终的收敛是假设的概率一致收敛。
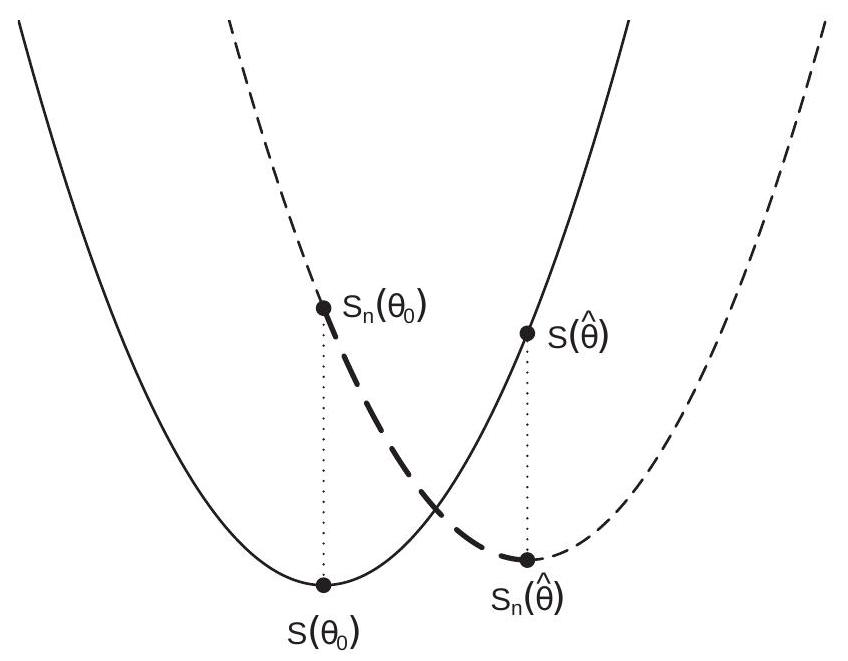
图 22.2:M 估计器的一致性
前面的论证如图 22.2 所示。该图用实线显示预期标准 \(S(\theta)\),用虚线显示样本标准 \(S_{n}(\theta)\)。两个函数在真值 \(\theta_{0}\) 和估计器 \(\hat{\theta}\) 之间的距离由两条点划线标记。这两个长度之和大于 \(S(\widehat{\theta})\) 和 \(S\left(\theta_{0}\right)\) 之间的垂直距离,因为后者距离等于两条点划线的总和加上虚线粗部分的垂直高度(\(S_{n}\left(\theta_{0}\right)\) 和 \(S_{n}(\widehat{\theta})\) )这是正数,因为 \(S_{n}(\widehat{\theta}) \leq S_{n}\left(\theta_{0}\right)\) 。在一致收敛的假设下,虚线的长度收敛到零。因此 \(S(\theta)\) 收敛于 \(S(\theta)\)。这样就完成了第一步。
在证明的第二步中,我们显示 \(\widehat{\theta} \underset{p}{\rightarrow} \theta\)。修复 \(\epsilon>0\)。唯一的最小假设意味着存在 \(\delta>0\),使得 \(\left\|\theta_{0}-\theta\right\|>\epsilon\) 意味着 \(S(\theta)-S\left(\theta_{0}\right) \geq \delta\)。这意味着 \(\left\|\theta_{0}-\widehat{\theta}\right\|>\epsilon\) 隐含 \(S(\widehat{\theta})-S\left(\theta_{0}\right) \geq \delta\)。因此
\[ \mathbb{P}\left[\left\|\theta_{0}-\widehat{\theta}\right\|>\epsilon\right] \leq \mathbb{P}\left[S(\widehat{\theta})-S\left(\theta_{0}\right) \geq \delta\right] . \]
因为\(S(\widehat{\theta}) \underset{p}{\rightarrow} S(\theta)\),右边收敛到零。因此左侧也收敛到零。由于 \(\epsilon\) 是任意的,这意味着 \(\hat{\theta} \underset{p}{\rightarrow} \theta\) 如上所述。
为了说明这一点,请再次检查图 22.2。我们看到 \(S(\widehat{\theta})\) 标记在 \(S(\theta)\) 的图表上。由于 \(S(\widehat{\theta})\) 收敛于 \(S\left(\theta_{0}\right)\),这意味着 \(S(\hat{\theta})\) 在 \(S(\theta)\) 的图形中向最小值滑动。 \(\widehat{\theta}\) 不收敛于 \(\theta_{0}\) 的唯一方法是函数 \(S(\theta)\) 在最小值处平坦。这是通过唯一最小值的假设排除的。定理证明 22.4 使用我们找到的均值定理将总体一阶条件 \(S(\widehat{\theta})\) 扩展到 \(S(\widehat{\theta})\) 附近
\[ 0=\psi(\widehat{\theta})+\boldsymbol{Q}\left(\theta_{n}^{*}\right)\left(\theta_{0}-\widehat{\theta}\right) \]
其中 \(\theta_{n}^{*}\) 是 \(\theta_{0}\) 和 \(\widehat{\theta}\) 之间的中间 \({ }^{3}\)。求解,我们发现
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right)=\boldsymbol{Q}\left(\theta_{n}^{*}\right)^{-1} \sqrt{n} \psi(\widehat{\theta}) . \]
\(\psi(\theta)\) 连续可微的假设意味着 \(\boldsymbol{Q}(\theta)\) 在 \(\mathscr{N}\) 中连续。由于 \(\theta_{n}^{*}\) 介于 \(\theta_{0}\) 和 \(\widehat{\theta}\) 之间,并且后者在概率上收敛于 \(\theta_{0}\),因此 \(\theta_{n}^{*}\) 在概率上也收敛于 \(\theta_{0}\)。因此根据连续映射定理\(\psi(\theta)\)。
接下来我们检查 \(\sqrt{n} \psi(\widehat{\theta})\) 的渐近分布。定义
\[ v_{n}(\theta)=\sqrt{n}\left(\bar{\psi}_{n}(\theta)-\psi(\theta)\right) . \]
样本一阶条件 \(\psi_{n}(\widehat{\theta})=0\) 的含义是
\[ \sqrt{n} \psi(\widehat{\theta})=\sqrt{n}\left(\psi(\widehat{\theta})-\psi_{n}(\widehat{\theta})\right)=-v_{n}(\widehat{\theta})=-v_{n}\left(\theta_{0}\right)+r_{n} \]
其中 \(r_{n}=v_{n}\left(\theta_{0}\right)-v_{n}(\widehat{\theta})\)
由于 \(\psi_{i}\) 均值为零(参见(22.3)),并且假设它满足多元中心极限定理,因此具有有限协方差矩阵 \(\Omega\)。因此
\[ \sqrt{n} \psi_{n}(\theta)=\frac{1}{\sqrt{n}} \sum_{i=1}^{n} \psi_{i} \underset{d}{\longrightarrow} \mathrm{N}(0, \Omega) . \]
最后一步是证明 \(r_{n}=o_{p}\) (1)。选择任意 \(\eta>0\) 和 \(\epsilon>0\)。正如《经济学家概率与统计》定理 \(18.5\) 所示,假设 4 意味着 \(v_{n}(\theta)\) 渐近等连续,这意味着(参见《经济学家概率与统计》中的定义 \(18.7\))给定 \(\epsilon\) 和 \(\eta\)是一个 \(\delta>0\) 这样
定理 \(22.1\) 意味着 \(\widehat{\theta} \underset{p}{\rightarrow} \theta_{0}\) 或
\[ \limsup _{n \rightarrow \infty} \mathbb{P}\left[\sup _{\left\|\theta-\theta_{0}\right\| \leq \delta}\left\|v_{n}\left(\theta_{0}\right)-v_{n}(\theta)\right\|>\eta\right] \leq \epsilon . \]
\[ \limsup _{n \rightarrow \infty} \mathbb{P}\left[\left\|\widehat{\theta}-\theta_{0}\right\|>\delta\right] \leq \epsilon . \]
我们计算出
\[ \begin{aligned} \limsup _{n \rightarrow \infty} \mathbb{P}\left[r_{n}>\eta\right] & \leq \limsup _{n \rightarrow \infty} \mathbb{P}\left[\left\|v_{n}\left(\theta_{0}\right)-v_{n}(\widehat{\theta})\right\|>\eta,\left\|\widehat{\theta}-\theta_{0}\right\| \leq \delta\right]+\limsup _{n \rightarrow \infty} \mathbb{P}\left[\left\|\widehat{\theta}-\theta_{0}\right\|>\delta\right] \\ & \leq \limsup _{n \rightarrow \infty} \mathbb{P}\left[\sup _{\left\|\theta-\theta_{0}\right\| \leq \delta}\left\|v_{n}\left(\theta_{0}\right)-v_{n}(\theta)\right\|>\eta\right]+\epsilon \leq 2 \epsilon . \end{aligned} \]
第二个不等式是(22.7),最终的不等式是(22.6)。由于 \(\eta\) 和 \(\epsilon\) 是任意的,我们推断出 \(r_{n}=o_{p}(1)\)。我们的结论是
\[ \sqrt{n} \psi(\widehat{\theta})=-v_{n}\left(\theta_{0}\right)+r_{n} \underset{d}{\longrightarrow} \mathrm{N}(0, \Omega) . \]
我们共同证明了
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right)=\boldsymbol{Q}\left(\theta_{n}^{*}\right)^{-1} \sqrt{n} \psi(\widehat{\theta}) \underset{d}{\longrightarrow} \boldsymbol{Q}^{-1} \mathrm{~N}(0, \Omega) \sim \mathrm{N}\left(0, \boldsymbol{Q}^{-1} \Omega \boldsymbol{Q}^{-1}\right) \]
正如所声称的那样。
\({ }^{3}\) 从技术上讲,由于 \(\psi(\widehat{\theta})\) 是一个向量,因此对向量的每个元素分别进行扩展,因此中间值因 \(\boldsymbol{Q}\left(\theta_{n}^{*}\right)\) 的行而异。这并不影响结论。
22.10 练习
练习 22.1 采用模型 \(Y=X^{\prime} \theta+e\),其中 \(e\) 独立于 \(X\),并且具有已知的连续可微的密度函数 \(f(e)\)。
证明给定 \(X=x\) 时 \(Y\) 的条件密度为 \(f\left(y-x^{\prime} \theta\right)\)。
找到函数 \(\rho(Y, X, \theta)\) 和 \(\psi(Y, X, \theta)\)。
计算渐近协方差矩阵。
练习22.2 采用模型\(Y=X^{\prime} \theta+e\)。考虑 \(\theta\) 与 \(\rho(Y, X, \theta)=g\left(Y-X^{\prime} \theta\right)\) 的 m 估计量,其中 \(g(u)\) 是已知函数。
找到函数 \(\rho(Y, X, \theta)\) 和 \(\psi(Y, X, \theta)\)。
计算渐近协方差矩阵。
练习 22.3 对于练习 \(22.2\) 中描述的估计器,设置 \(g(u)=\frac{1}{4} u^{4}\)。
绘制 \(g(u)\) 草图。 \(g(u)\) 连续吗?可微分?第二可微分?
找到函数 \(\rho(Y, X, \theta)\) 和 \(\psi(Y, X, \theta)\)。
计算渐近协方差矩阵。
练习 22.4 对于练习 \(22.2\) 中描述的估计器,设置 \(g(u)=1-\cos (u)\)。
绘制 \(g(u)\) 草图。 \(g(u)\) 连续吗?可微分?第二可微分?
找到函数 \(\rho(Y, X, \theta)\) 和 \(\psi(Y, X, \theta)\)。
计算渐近协方差矩阵。