第10章: 重采样方法
10 重采样方法
10.1 介绍
到目前为止,在本教科书中,我们已经讨论了两种推理方法:精确推理和渐近推理。两者都有各自的优点和缺点。精确理论提供了有用的基准,但基于同方差正态回归模型的不切实际且严格的假设。渐近理论提供了一种更灵活的分布理论,但它是一种精度不确定的近似。
在本章中,我们介绍了一组基于重采样概念的替代推理方法,这意味着使用从数据的经验分布中提取的采样信息。这些方法功能强大,适用范围广泛,并且通常比精确方法和渐近近似更准确。然而,有两个缺点:(1)重采样方法通常需要更多的计算能力; (2)该理论更具挑战性。计算要求的结果是,大多数实证研究人员使用渐近近似进行常规计算,而重采样近似用于最终报告。
我们将讨论统计和计量经济学实践中使用的两类重采样方法:折刀法和引导法。我们的大部分注意力将集中在引导程序上,因为它是计量经济学实践中最常用的重采样方法。
Jackknife 是从 \(n\) 留一估计量获得的分布(参见第 3.20 节)。折刀法最常用于方差估计。
Bootstrap 是通过对 i.i.d. 创建的样本进行估计而获得的分布。从数据集中进行替换采样。 (引导抽样还有其他变体,包括参数抽样和残差抽样。)引导抽样通常用于方差估计、置信区间构建和假设检验。
第三类重采样方法称为二次采样,我们不会在本教科书中介绍。子采样是通过对数据集的子样本(无放回采样)进行估计而获得的分布。子采样可用于大多数与引导程序相同的目的。请参阅 Politis、Romano 和 Wolf (1999) 撰写的优秀专着。
10.2 例子
为了激发我们的讨论,我们重点关注第 3.7 节中提出的应用程序,这是一个二元回归,适用于具有 12 年潜在工作经验的已婚黑人女性工薪者的 CPS 子样本,并显示在表 3.1 中。回归方程为
\[ \log (\text { wage })=\beta_{1} \text { education }+\beta_{2}+e . \]
(4.44) 中报告的估计是
\[ \begin{aligned} & \log (\text { wage })=0.155 \text { education }+0.698+\widehat{e} \\ & \text { (0.031) } \quad(0.493) \\ & \widehat{\sigma}^{2}=0.144 \\ & \text { (0.043) } \\ & n=20 \text {. } \end{aligned} \]
我们重点关注根据该回归构建的四个估计值。前两个是系数估计值 \(\widehat{\beta}_{1}\) 和 \(\widehat{\beta}_{2}\)。第三个是方差估计 \(\widehat{\sigma}^{2}\)。第四个是对受过 16 年教育的个人(大学毕业生)的预期工资水平的估计,结果是参数的非线性函数。在误差 \(e\) 与教育水平无关且呈正态分布的简化假设下,我们发现预期工资水平为
\[ \begin{aligned} \mu &=\mathbb{E}[\text { wage } \mid \text { education }=16] \\ &=\mathbb{E}\left[\exp \left(16 \beta_{1}+\beta_{2}+e\right)\right] \\ &=\exp \left(16 \beta_{1}+\beta_{2}\right) \mathbb{E}[\exp (e)] \\ &=\exp \left(16 \beta_{1}+\beta_{2}+\sigma^{2} / 2\right) . \end{aligned} \]
最终的等式是\(\mathbb{E}[\exp (e)]=\exp \left(\sigma^{2} / 2\right)\),可以通过普通矩生成函数得到。参数 \(\mu\) 是系数的非线性函数。 \(\mu\) 的自然估计器用点估计器替换了未知数。因此
\[ \widehat{\mu}=\exp \left(16 \widehat{\beta}_{1}+\widehat{\beta}_{2}+\widehat{\sigma}^{2} / 2\right)=25.80 \]
\(\widehat{\mu}\) 的标准误差可以通过扩展练习 \(7.8\) 来找到 \(\widehat{\sigma}^{2}\) 的联合渐近分布和斜率估计,然后应用 Delta 方法来找到。
我们有兴趣计算上述四个估计的标准误差和置信区间。
10.3 方差的折刀估计
Jackknife 使用留一估计量的分布来估计估计量的矩。偏差和方差的折刀估计量分别由 Quenouille (1949) 和 Tukey (1958) 引入。这个想法在 Efron (1982) 以及 Shao 和 Tu (1995) 的专着中得到了进一步扩展。
令 \(\widehat{\theta}\) 为向量值参数 \(\theta\) 的任意估计量,该参数是大小为 \(n\) 的随机样本的函数。令 \(\boldsymbol{V}_{\widehat{\theta}}=\operatorname{var}[\widehat{\theta}]\) 为 \(\widehat{\theta}\) 的方差。定义留一估计量 \(\widehat{\theta}_{(-i)}\),该估计量使用 \(\widehat{\theta}\) 的公式计算,但删除了观测值 \(i\)。 \(\boldsymbol{V}_{\widehat{\theta}}\) 的 Tukey 折刀估计量被定义为留一估计量的样本方差的尺度:
\[ \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {jack }}=\frac{n-1}{n} \sum_{i=1}^{n}\left(\widehat{\theta}_{(-i)}-\bar{\theta}\right)\left(\widehat{\theta}_{(-i)}-\bar{\theta}\right)^{\prime} \]
其中 \(\bar{\theta}\) 是留一估计量 \(\bar{\theta}=n^{-1} \sum_{i=1}^{n} \widehat{\theta}_{(-i)}\) 的样本均值。对于标量估计量 \(\widehat{\theta}\),折刀标准误差是 (10.1) 的平方根:\(s_{\widehat{\theta}}^{\text {jack }}=\sqrt{\widehat{V}_{\widehat{\theta}}^{\text {jack }}}\)。
折刀估计器 \(\widehat{V}_{\widehat{\theta}}^{\text {jack }}\) 的一个便利特征是公式 (10.1) 非常通用,不需要任何技术(精确或渐近)计算。缺点是可能需要 \(n\) 单独估计,在某些情况下计算成本可能很高。
在大多数情况下,\(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {jack }}\) 将类似于稳健的渐近协方差矩阵估计器。 Jackknife 估计器的主要吸引力在于,它可以在显式渐近方差公式不可用时使用,并且可以用作渐近公式可靠性的检查。
公式(10.1)并不直观,因此可能会受益于一些动机。我们首先检查 \(Y \in \mathbb{R}^{m}\) 的样本均值 \(\bar{Y}=\frac{1}{n} \sum_{i=1}^{n} Y_{i}\)。留一估计量为
\[ \bar{Y}_{(-i)}=\frac{1}{n-1} \sum_{j \neq i} Y_{j}=\frac{n}{n-1} \bar{Y}-\frac{1}{n-1} Y_{i} . \]
留一估计量的样本均值是
\[ \frac{1}{n} \sum_{i=1}^{n} \bar{Y}_{(-i)}=\frac{n}{n-1} \bar{Y}-\frac{1}{n-1} \bar{Y}=\bar{Y} \]
区别在于
\[ \bar{Y}_{(-i)}-\bar{Y}=\frac{1}{n-1}\left(\bar{Y}-Y_{i}\right) . \]
方差的折刀估计 (10.1) 则为
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\bar{Y}}^{\text {jack }} &=\frac{n-1}{n} \sum_{i=1}^{n}\left(\frac{1}{n-1}\right)^{2}\left(\bar{Y}-Y_{i}\right)\left(\bar{Y}-Y_{i}\right)^{\prime} \\ &=\frac{1}{n}\left(\frac{1}{n-1}\right) \sum_{i=1}^{n}\left(\bar{Y}-Y_{i}\right)\left(\bar{Y}-Y_{i}\right)^{\prime} \end{aligned} \]
这与 \(\bar{Y}\) 方差的传统估计器相同。事实上,Tukey 在 (10.1) 中提出了 \((n-1) / n\) 缩放,以便 \(\widehat{V}_{\bar{Y}}^{\text {jack }}\) 精确等于传统的估计器。
接下来我们研究最小二乘回归系数估计器的情况。回想一下 (3.43),留一 OLS 估计量等于
\[ \widehat{\beta}_{(-i)}=\widehat{\beta}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} X_{i} \widetilde{e}_{i} \]
其中 \(\widetilde{e}_{i}=\left(1-h_{i i}\right)^{-1} \widehat{e}_{i}\) 和 \(h_{i i}=X_{i}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} X_{i}\)。留一估计量的样本平均值为 \(\bar{\beta}=\widehat{\beta}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \widetilde{\mu}\),其中 \(\widetilde{\mu}=n^{-1} \sum_{i=1}^{n} X_{i} \widetilde{e}_{i}\)。因此\(\widehat{\beta}_{(-i)}-\bar{\beta}=-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(X_{i} \widetilde{e}_{i}-\widetilde{\mu}\right)\)。 \(\widehat{\beta}\) 的方差折刀估计为
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\text {jack }} &=\frac{n-1}{n} \sum_{i=1}^{n}\left(\widehat{\beta}_{(-i)}-\bar{\beta}\right)\left(\widehat{\beta}_{(-i)}-\bar{\beta}\right)^{\prime} \\ &=\frac{n-1}{n}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \tilde{e}_{i}^{2}-n \widetilde{\mu} \widetilde{\mu}^{\prime}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\frac{n-1}{n} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 3}-(n-1)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \widetilde{\mu} \widetilde{\mu}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \end{aligned} \]
其中 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC}}\) 是基于预测误差的 HC3 协方差估计器 (4.39)。 (10.5) 中的第二项通常非常小,因为 \(\widetilde{\mu}\) 的大小通常很小。因此\(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\text {jack }} \simeq \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC}}\)。事实上,HC3 估计器最初是作为折刀估计器的简化而产生的。这表明对于回归系数,方差折刀估计器类似于传统的稳健估计器。这是在用户“不知道”渐近协方差矩阵的形式的情况下完成的。这进一步证实了折刀的计算是合理的。
第三,我们检查最小二乘估计器的函数 \(\widehat{\theta}=r(\widehat{\beta})\) 的折刀估计器。 \(\theta\) 的留一估计量为
\[ \begin{aligned} \widehat{\theta}_{(-i)} &=r\left(\widehat{\beta}_{(-i)}\right) \\ &=r\left(\widehat{\beta}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} X_{i} \widetilde{e}_{i}\right) \\ & \simeq \widehat{\theta}-\widehat{\boldsymbol{R}}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} X_{i} \widetilde{e}_{i} \end{aligned} \]
第二个等式是(10.4)。最终的近似值是通过使用 \(r(\widehat{\beta})=\widehat{\theta}\) 并设置 \(\widehat{\boldsymbol{R}}=(\partial / \partial \beta) r(\widehat{\beta})^{\prime}\) 进行平均值扩展获得的。该近似值在大样本中成立,因为 \(\widehat{\beta}_{(-i)}\) 与 \(\beta\) 一致一致。 \(\widehat{\theta}\) 的折刀方差估计器等于
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\mathrm{jack}} &=\frac{n-1}{n} \sum_{i=1}^{n}\left(\widehat{\theta}_{(-i)}-\bar{\theta}\right)\left(\widehat{\theta}_{(-i)}-\bar{\theta}\right)^{\prime} \\ & \simeq \frac{n-1}{n} \widehat{\boldsymbol{R}}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \widehat{e}_{i}^{2}-n \widetilde{\mu} \widetilde{\mu}^{\prime}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \widehat{\boldsymbol{R}} \\ &=\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{jack}} \widehat{\boldsymbol{R}} \\ & \simeq \widehat{\boldsymbol{R}}^{\prime} \widetilde{\boldsymbol{V}}_{\widehat{\beta}} \widehat{\boldsymbol{R}} . \end{aligned} \]
最后一行等于使用协方差估计器 (4.39) 构建的 \(\widehat{\theta}\) 方差的 delta 方法估计器。这表明 \(\widehat{\theta}\) 的方差折刀估计量近似为渐近 delta 方法估计量。虽然这是一种渐近近似,但它再次表明折刀法生成的估计量与渐近方法生成的估计量渐近相似。尽管折刀估计量的计算没有参考渐近理论,并且不需要计算 \(r(\beta)\) 的导数,但情况仍然如此。
这个论点直接扩展到任何“平滑函数”估计器。到目前为止,本教科书中讨论的大多数估计量都采用 \(\widehat{\theta}=g(\bar{W})\) 的形式,其中 \(\bar{W}=n^{-1} \sum_{i=1}^{n} W_{i}\) 和 \(W_{i}\) 是数据的某些向量值函数。对于任何此类估计量 \(\widehat{\theta}\),留一估计量等于 \(\widehat{\theta}_{(-i)}=g\left(\bar{W}_{(-i)}\right)\),其方差折刀估计量为 (10.1)。使用 (10.2) 和均值展开我们得到大样本近似
\[ \begin{aligned} \widehat{\theta}_{(-i)} &=g\left(\bar{W}_{(-i)}\right) \\ &=g\left(\frac{n}{n-1} \bar{W}-\frac{1}{n-1} W_{i}\right) \\ & \simeq g(\bar{W})-\frac{1}{n-1} \boldsymbol{G}(\bar{W})^{\prime} W_{i} \end{aligned} \]
其中 \(\boldsymbol{G}(x)=(\partial / \partial x) g(x)^{\prime}\).因此
\[ \widehat{\theta}_{(-i)}-\bar{\theta} \simeq-\frac{1}{n-1} \boldsymbol{G}(\bar{W})^{\prime}\left(W_{i}-\bar{W}\right) \]
\(\widehat{\theta}\) 方差的折刀估计量大约等于
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\mathrm{jack}} &=\frac{n-1}{n} \sum_{i=1}^{n}\left(\widehat{\theta}_{(-i)}-\widehat{\theta}_{(\cdot)}\right)\left(\widehat{\theta}_{(-i)}-\widehat{\theta}_{(\cdot)}\right)^{\prime} \\ & \simeq \frac{n-1}{n} \boldsymbol{G}(\bar{W})^{\prime}\left(\frac{1}{(n-1)^{2}} \sum_{i=1}^{n}\left(W_{i}-\bar{W}\right)\left(W_{i}-\bar{W}\right)^{\prime}\right) \boldsymbol{G}(\bar{W}) \\ &=\boldsymbol{G}(\bar{W})^{\prime} \widehat{\boldsymbol{V}}_{\bar{W}}^{\mathrm{jack}} \boldsymbol{G}(\bar{W}) \end{aligned} \]
其中(10.3)中定义的 \(\widehat{V}_{\bar{W}}^{\text {jack }}\) 是 \(\bar{W}\) 方差的传统(和折刀)估计器。因此 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {jack }}\) 近似为 delta 方法估计器。我们再次看到,折刀估计器自动计算有效的 delta 方法方差估计器,但不需要用户显式计算 \(g(x)\) 的导数。
10.4 例子
我们通过报告前面给出的四个参数估计的渐近和折刀标准误差来进行说明。在表 \(10.1\) 中,我们报告了样本中 20 个观测值中每个观测值的留一估计的实际值。折刀标准误差计算为这些留一估计的样本方差的缩放平方根,并在倒数第二行中报告。为了进行比较,最后一行报告了渐近标准误差。
对于所有估计,折刀误差和渐近标准误差都非常相似。这增强了两个标准误差估计的可信度。 \(\widehat{\beta}_{2}\) 和 \(\widehat{\mu}\) 存在最大差异,其折刀标准误差比渐近标准误差大约大 \(5 %\)。
我们的演示的要点是,折刀法是一种简单而灵活的方差和标准误差计算方法。绕过技术上的渐近和精确计算,折刀法产生的估计在许多情况下与渐近 delta 方法的对应物类似。在渐近标准误差不可用或难以计算的情况下,折刀法特别有吸引力。它们还可以用作渐近 delta 方法计算合理性的双重检查。
在 Stata 中,许多模型中系数估计的折刀标准误差是通过 vce(jackknife) 选项获得的。对于系数或其他估计器的非线性函数,jackkn ife 命令可以与任何其他命令组合以获得 jackknife 标准误差。
为了说明这一点,下面我们列出了计算上面列出的折刀标准误差的 Stata 命令。第一行是最小二乘估计,其中标准误差由折刀计算。第二行使用折刀标准误差计算误差方差估计 \(\widehat{\sigma}^{2}\)。第三行对 \(\widehat{\mu}\) 的估计执行相同的操作。

表 10.1:留一估计量和折刀标准误
| Observation | \(\widehat{\beta}_{1(-i)}\) | \(\widehat{\beta}_{2(-i)}\) | \(\widehat{\sigma}_{(-i)}^{2}\) | \(\widehat{\mu}_{(-i)}\) |
|---|---|---|---|---|
| 1 | \(0.150\) | \(0.764\) | \(0.150\) | \(25.63\) |
| 2 | \(0.148\) | \(0.798\) | \(0.149\) | \(25.48\) |
| 3 | \(0.153\) | \(0.739\) | \(0.151\) | \(25.97\) |
| 4 | \(0.156\) | \(0.695\) | \(0.144\) | \(26.31\) |
| 5 | \(0.154\) | \(0.701\) | \(0.146\) | \(25.38\) |
| 6 | \(0.158\) | \(0.655\) | \(0.151\) | \(26.05\) |
| 7 | \(0.152\) | \(0.705\) | \(0.114\) | \(24.32\) |
| 8 | \(0.146\) | \(0.822\) | \(0.147\) | \(25.37\) |
| 9 | \(0.162\) | \(0.588\) | \(0.151\) | \(25.75\) |
| 10 | \(0.157\) | \(0.693\) | \(0.139\) | \(26.40\) |
| 11 | \(0.168\) | \(0.510\) | \(0.141\) | \(26.40\) |
| 12 | \(0.158\) | \(0.691\) | \(0.118\) | \(26.48\) |
| 13 | \(0.139\) | \(0.974\) | \(0.141\) | \(26.56\) |
| 14 | \(0.169\) | \(0.451\) | \(0.131\) | \(26.26\) |
| 15 | \(0.146\) | \(0.852\) | \(0.150\) | \(24.93\) |
| 16 | \(0.156\) | \(0.696\) | \(0.148\) | \(26.06\) |
| 17 | \(0.165\) | \(0.513\) | \(0.140\) | \(25.22\) |
| 18 | \(0.155\) | \(0.698\) | \(0.151\) | \(25.90\) |
| 19 | \(0.152\) | \(0.742\) | \(0.151\) | \(25.73\) |
| 20 | \(0.155\) | \(0.697\) | \(0.151\) | \(25.95\) |
| \(s^{\text {jack }}\) | \(0.032\) | \(0.514\) | \(0.046\) | \(2.39\) |
| \(s^{\text {asy }}\) | \(0.031\) | \(0.493\) | \(0.043\) | \(2.29\) |
10.5 用于聚类观察的刀刀
在 \(4.21\) 节中,我们介绍了聚类回归模型、聚类稳健方差估计器和聚类稳健标准误差。折刀方差估计也可用于聚类样本,但需要进行一些自然修改。回想一下,聚类样本上下文中的最小二乘估计量可以写为
\[ \widehat{\beta}=\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{X}_{g}\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{Y}_{g}\right) \]
其中 \(g=1, \ldots, G\) 对集群进行索引。不使用留一法估计器,很自然地使用删除簇估计器,它一次删除一个簇。它们的形式为 (4.58):
\[ \widehat{\beta}_{(-g)}=\widehat{\beta}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}_{g}^{\prime} \widetilde{\boldsymbol{e}}_{g} \]
在哪里
\[ \begin{aligned} &\widetilde{\boldsymbol{e}}_{g}=\left(\boldsymbol{I}_{n_{g}}-\boldsymbol{X}_{g}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}_{g}^{\prime}\right)^{-1} \widehat{\boldsymbol{e}}_{g} \\ &\widehat{\boldsymbol{e}}_{g}=\boldsymbol{Y}_{g}-\boldsymbol{X}_{g} \widehat{\beta} \end{aligned} \]
\(\widehat{\beta}\) 方差的删除簇折刀估计量为
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{jack}} &=\frac{G-1}{G} \sum_{g=1}^{G}\left(\widehat{\beta}_{(-g)}-\bar{\beta}\right)\left(\widehat{\beta}_{(-g)}-\bar{\beta}\right)^{\prime} \\ \bar{\beta} &=\frac{1}{G} \sum_{g=1}^{G} \widehat{\beta}_{(-g)} . \end{aligned} \]
我们将 \(\widehat{V}_{\widehat{\beta}}^{\text {jack }}\) 称为集群稳健的刀切方差估计器。
使用与上一节相同的近似,我们可以证明删除簇折刀估计器渐近等效于使用删除簇预测误差计算的簇鲁棒协方差矩阵估计器(4.59)。这验证了删除集群刀刀法是适用于集群依赖的刀刀法方法。
对于作为最小二乘估计器的函数 \(\widehat{\theta}=r(\widehat{\beta})\) 的参数,\(\widehat{\theta}\) 方差的删除簇折刀估计器为
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {jack }} &=\frac{G-1}{G} \sum_{g=1}^{G}\left(\widehat{\theta}_{(-g)}-\bar{\theta}\right)\left(\widehat{\theta}_{(-g)}-\bar{\theta}\right)^{\prime} \\ \widehat{\theta}_{(-i)} &=r\left(\widehat{\beta}_{(-g)}\right) \\ \bar{\theta} &=\frac{1}{G} \sum_{g=1}^{G} \widehat{\theta}_{(-g)} . \end{aligned} \]
使用均值展开,我们可以证明该估计器渐近等价于 \(\widehat{\theta}\) 的 deltamethod 集群鲁棒协方差矩阵估计器。这表明折刀估计器适合协方差矩阵估计。
正如在 i.i.d. 的上下文中一样。对于样本,折刀协方差矩阵估计器的优点之一是它们不需要用户对渐近分布进行技术计算。缺点是计算成本增加,因为 \(G\) 单独的回归是有效估计的。
在 Stata 中,通过使用选项 cluster (id) vce(jackkn ife) 获得聚类观测值的系数估计的杰克刀标准误差,其中 id 表示聚类变量。
10.6 引导算法
Bootstrap 是一种强大的推理方法,归功于 Efron (1979) 的开创性工作。有许多关于引导程序的教科书和专着,包括 Efron (1982)、Hall (1992)、Efron 和 Tibshirani (1993)、Shao 和 Tu (1995) 以及 Davison 和 Hinkley (1997)。 Hall (1994) 和 Horowitz (2001) 为计量经济学家提供了评论
有多种方法来描述或定义引导程序,并且引导程序有多种形式。我们在本节中首先描述基本的非参数引导算法。在后续部分中,我们给出引导程序的更正式的定义以及理论依据。
简而言之,自举分布是通过对 i.i.d. 创建的独立样本进行估计来获得的。从原始数据集中采样(放回采样)。
为了理解这一点,从数据集中替换采样的概念开始是很有用的。为了继续本章前面使用的经验示例,我们重点关注表 3.1 中显示的数据集,其中包含 \(n=20\) 观测值。从此分布中采样意味着从该表中随机选择一行。从数学上讲,这与从集合 \(\{1,2, \ldots, 20\}\) 中随机选择一个整数相同。为了说明这一点,MATLAB 有一个随机整数生成器(函数 randi)。使用随机数种子 13 (任意选择),我们获得随机抽取 16 。这意味着我们从表 3.1 中得出第 16 号观察结果。检查该表,我们可以看到这是一个工资为 \(\$ 18.75\) 且受教育年限为 16 年的个人。我们通过在集合 \(\{1,2, \ldots, 20\}\) 上绘制另一个随机整数来重复,这次获得 5 。这意味着我们从表 3.1 中获取观察值 5,即工资为 \(\$ 33.17\) 且受教育年限为 16 年的个人。我们继续下去,直到我们有 \(n=20\) 这样的抽奖。这组随机观察值是 \(\{16,5,17,20,20,10,13,16,13,15,1,6,2,18,8,14,6,7,1,8\}\)。我们称之为引导样本。
请注意,观测值 \(1,6,8,13,16,20\) 在引导样本中各出现两次,而观测值 \(3,4,9,11,12,19\) 根本不出现。好的,可以。事实上,引导程序的工作是必需的。这是因为我们正在用替换来绘制。 (如果我们进行不放回抽签,那么构建的数据集将具有与表 3.1 中完全相同的观测值,只是顺序不同。)我们还可以问这样的问题“单个观测值至少出现一次的概率是多少”引导样本?”答案是
\[ \begin{aligned} \mathbb{P}[\text { Observation in Bootstrap Sample }] &=1-\left(1-\frac{1}{n}\right)^{n} \\ & \rightarrow 1-e^{-1} \simeq 0.632 . \end{aligned} \]
限制保持为 \(n \rightarrow \infty\)。即使对于较小的 \(n\),近似值 \(0.632\) 也非常出色。例如,当 \(n=20\) 时,概率 (10.6) 为 \(0.641\)。这些计算表明,引导样本中的单个观测值的概率接近 \(2 / 3\)。
同样,引导样本是构建的数据集,其中包含从原始样本中随机抽取的 20 个观察值。从符号上讲,我们将 \(i^{\text {th }}\) 引导观测值写为 \(\left(Y_{i}^{*}, X_{i}^{*}\right)\),将引导样本写为 \(\left\{\left(Y_{1}^{*}, X_{1}^{*}\right), \ldots,\left(Y_{n}^{*}, X_{n}^{*}\right)\right\}\)。在我们当前的示例中,\(Y\) 表示对数工资,引导样本是
\[ \left\{\left(Y_{1}^{*}, X_{1}^{*}\right), \ldots,\left(Y_{n}^{*}, X_{n}^{*}\right)\right\}=\{(2.93,16),(3.50,16) \ldots,(3.76,18)\} \]
引导估计 \(\widehat{\beta}^{*}\) 是通过将最小二乘估计公式应用于引导样本而获得的。因此我们在 \(X^{*}\) 上回归 \(Y^{*}\)。其他 bootstrap 估计(在我们的示例中 \(\widehat{\sigma}^{2 *}\) 和 \(\widehat{\mu}^{*}\))也是通过将其估计公式应用于 bootstrap 样本而获得的。编写 \(\widehat{\theta}^{*}=\) \(\left(\widehat{\beta}_{1}^{*}, \widehat{\beta}_{2}^{*}, \widehat{\sigma}^{* 2}, \widehat{\mu}^{*}\right)^{\prime}\) 我们得到参数向量 \(\theta=\left(\beta_{1}, \beta_{2}, \sigma^{2}, \mu\right)^{\prime}\) 的自举估计。在我们的示例中(上述引导示例)\(\widehat{\theta}^{*}=(0.195,0.113,0.107,26.7)^{\prime}\)。这是从估计值的引导分布中得出的一项结论。
所描述的估计值 \(\widehat{\theta}^{*}\) 是从 i.i.d. 获得的估计值分布中随机抽取的。从原始数据中采样。通过一场平局,我们能说的相对较少。但我们可以重复这个练习,从这个引导分布中获得多次抽取。为了区分这些抽签,我们通过 \(b=1, \ldots, B\) 对引导样本进行索引,并将引导估计写入 \(\widehat{\theta}_{b}^{*}\) 或 \(\widehat{\theta}^{*}(b)\)。
为了继续我们的说明,我们再抽取 20 个随机整数 \(\{19,5,7,19,1,2,13,18,1,15,17,2\)、\(14,11,10,20,1,5,15,7\}\) 并构建第二个引导样本。在此示例中,我们再次估计参数并获得 \(\widehat{\theta}^{*}(2)=(0.175,0.52,0.124,29.3)^{\prime}\)。这是从 \(\widehat{\theta}^{*}\) 分布中进行的第二次随机抽取。我们重复此 \(B\) 次,存储参数估计值 \(\widehat{\theta}^{*}(b)\)。因此,我们创建了一个新的 bootstrap 绘制数据集 \(\left\{\widehat{\theta}^{*}(b): b=1, \ldots, B\right\}\)。通过构造,抽奖在 \(b\) 上是独立的并且分布相同。
引导程序绘制次数 \(B\) 通常称为“引导程序复制次数”。 \(B\) 的典型选择是 1000、5000 和 10,000。我们稍后会讨论选择 \(B\),但粗略地说,较大的 \(B\) 会导致更精确的估计,但计算成本也会增加。对于我们的应用程序,我们设置 \(B=\) 10,000 。为了说明这一点,图 \(13.1\) 显示了 10,000 次抽奖中 bootstrap 估计值 \(\widehat{\beta}_{1}^{*}\) 和 \(\widehat{\mu}^{*}\) 的分布密度。虚线显示点估计。您可以注意到 \(\widehat{\beta}_{1}^{*}\) 的密度稍微向左倾斜。\
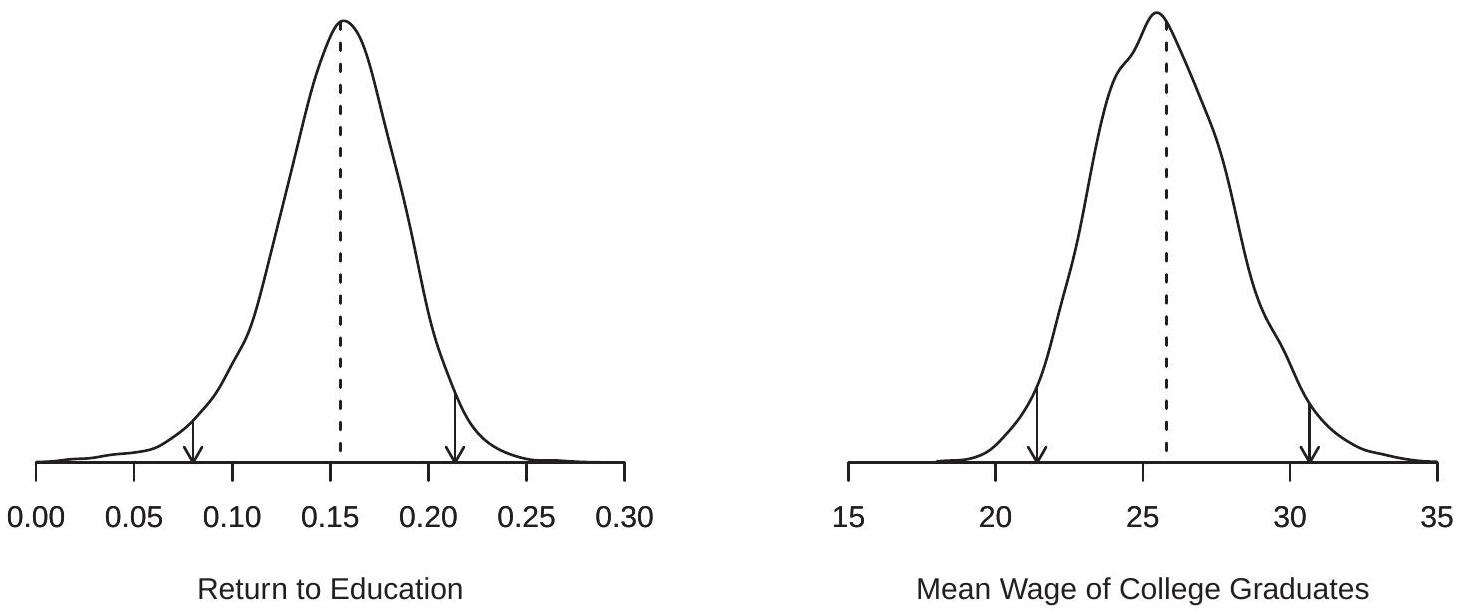
图 10.1:\(\widehat{\beta}_{1}^{*}\) 和 \(\widehat{\mu}^{*}\) 的自举分布
10.7 自举方差和标准误差
给定引导程序绘制,我们可以估计引导程序分布的特征。估计量 \(\widehat{\theta}\) 的方差引导估计量是引导绘制 \(\widehat{\theta}^{*}(b)\) 上的样本方差。它等于
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {boot }} &=\frac{1}{B-1} \sum_{b=1}^{B}\left(\widehat{\theta}^{*}(b)-\bar{\theta}^{*}\right)\left(\widehat{\theta}^{*}(b)-\bar{\theta}^{*}\right)^{\prime} \\ \bar{\theta}^{*} &=\frac{1}{B} \sum_{b=1}^{B} \widehat{\theta}^{*}(b) \end{aligned} \]
对于标量估计量 \(\hat{\theta}\),引导标准误差是方差引导估计量的平方根:
\[ s_{\widehat{\widehat{\theta}}}^{\text {boot }}=\sqrt{\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {boot }}} . \]
这是一个计算起来非常简单的统计数据,也是应用计量经济学实践中引导程序最常见的用途。需要注意的是(在第 10.15 节中更详细地讨论),在许多情况下最好使用修剪估计器。
通常报告标准误差来传达估计器的精度。它们也常用于构建置信区间。 Bootstrap 标准错误可用于此目的。正态近似自举置信区间为
\[ C^{\mathrm{nb}}=\left[\widehat{\theta}-z_{1-\alpha / 2} s_{\widehat{\theta}}^{\text {boot }}, \quad \widehat{\theta}+z_{1-\alpha / 2} s_{\widehat{\theta}}^{\text {boot }}\right] \]
其中 \(z_{1-\alpha / 2}\) 是 \(\mathrm{N}(0,1)\) 分布的 \(1-\alpha / 2\) 分位数。此区间 \(C^{\mathrm{nb}}\) 在格式上与渐近置信区间相同,但用自举标准误差替换了渐近标准误差。 \(C^{\mathrm{nb}}\) 是使用 bootstrap 计算标准误差时 Stata 报告的默认置信区间。然而,对于置信区间构建来说,正态近似区间通常是一个糟糕的选择,因为它依赖于 t 比的正态近似,而在有限样本中可能不准确。还有其他方法 - 例如将在 \(10.17\) 节中讨论的偏差校正百分位数方法 - 其计算同样简单,但具有更好的性能。一般来说,引导标准误差应用作精度估计,而不是用作构建置信区间的工具。
由于 \(B\) 是有限的,因此所有引导统计数据(例如 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {boot }}\))都是估计值,因此是随机的。它们的值将根据 \(B\) 和模拟运行的不同选择而变化(取决于模拟种子的设置方式)。因此,您不应期望在复制其他研究人员的结果时获得与其他研究人员完全相同的引导标准误差。它们应该相似(取决于模拟采样误差)但不完全相同。
在表 \(10.2\) 中,我们报告了 \(10.2\) 节中引入的四个参数估计值以及渐近、折刀和自举标准误差。我们还报告了四个引导置信区间,将在后续部分中介绍。
对于这四个估计量,我们可以看到引导标准误差与渐近标准误差和折刀标准误差非常相似。最显着的差异出现在 \(\widehat{\beta}_{2}\) 上,其中引导标准误差比渐近标准误差大约大 \(10 %\) 。
表 10.2:方法比较
| \(\widehat{\beta}_{1}\) | \(\widehat{\beta}_{2}\) | \(\widehat{\sigma}^{2}\) | \(\widehat{\mu}\) | |
|---|---|---|---|---|
| Estimate | \(0.155\) | \(0.698\) | \(0.144\) | \(25.80\) |
| Asymptotic s.e. | \((0.031)\) | \((0.493)\) | \((0.043)\) | \((2.29)\) |
| Jackknife s.e. | \((0.032)\) | \((0.514)\) | \((0.046)\) | \((2.39)\) |
| Bootstrap s.e. | \((0.034)\) | \((0.548)\) | \((0.041)\) | \((2.38)\) |
| \(95 %\) Percentile Interval | \([0.08,0.21]\) | \([-0.27,1.91]\) | \([0.06,0.22]\) | \([21.4,30.7]\) |
| \(95 %\) BC Percentile Interval | \([0.08,0.21]\) | \([-0.25,1.93]\) | \([0.09,0.28]\) | \([22.0,31.5]\) |
| \(95 %\) BC |
在 Stata 中,许多模型中系数估计的引导标准误差是通过 vce(bootstrap,reps(#)) 选项获得的,其中 # 是引导复制的数量。对于系数或其他估计器的非线性函数,引导程序命令可以与任何其他命令组合以获得引导程序标准误差。 bootstrap 的同义词是 bstrap 和 bs。
为了说明这一点,下面我们列出了 Stata 命令,这些命令将计算 \({ }^{1}\) 上面列出的引导程序标准误差。
\({ }^{1}\) 它们不会精确地复制标准误差,因为表 \(10.2\) 中的标准误差是在 Matlab 中生成的,它使用不同的随机数序列。
Stata命令 reg 工资教育如果 \(\operatorname{mbf} 12==1\), vce(bootstrap, 代表 \((10000))\)
bs (e(rss)/e(N)),reps(10000):正规工资教育 if \(\mathrm{mbf} 12==1\)
bs ( \(\exp \left(16^{*}\right.\) bb[教育]+_b[_cons] \(\left.\left.+\mathrm{e}(\mathrm{rss}) / \mathrm{e}(\mathrm{N}) / 2\right)\right)\), 代表(10000): ///
正规工资教育 if \(\operatorname{mbf} 12==1\)
10.8 百分位数区间
引导方法的第二个最常见用途是置信区间。有多种引导方法可以形成置信区间。一种流行且简单的方法称为百分位数区间。它基于引导分布的分位数。
在 \(10.6\) 节中,我们描述了创建独立同分布的引导算法。 bootstrap 估计 \(\left\{\widehat{\theta}_{1}^{*}, \widehat{\theta}_{2}^{*}, \ldots, \widehat{\theta}_{B}^{*}\right\}\) 的样本对应于参数 \(\theta\) 的估计器 \(\widehat{\theta}\)。我们关注标量参数 \(\theta\) 的情况。
对于任何 \(0<\alpha<1\),我们可以计算这些 bootstrap 估计的经验分位数 \(q_{\alpha}^{*}\)。该数字使得 \(n \alpha\) 引导估计值小于 \(q_{\alpha}^{*}\),并且通常通过采用 \(\widehat{\theta}_{b}^{*}\) 的 \(n \alpha^{t h}\) 阶统计量来计算。有关经验分位数和常见分位数估计量的精确讨论,请参阅《经济学家的概率与统计》的 \(11.13\) 部分。
百分位数引导 \(100(1-\alpha) %\) 置信区间为
\[ C^{\mathrm{pc}}=\left[q_{\alpha / 2}^{*}, q_{1-\alpha / 2}^{*}\right] . \]
例如,如果使用 \(B=1000, \alpha=0.05\) 并使用经验分位数估计量,则使用 \(C^{\mathrm{pc}}=\left[\widehat{\theta}_{(25)}^{*}, \widehat{\theta}_{(975)}^{*}\right]\)。
为了说明这一点,\(\widehat{\beta}_{1}^{*}\) 和 \(\widehat{\mu}^{*}\) 的引导分布的 \(0.025\) 和 \(0.975\) 分位数在图 \(13.1\) 中用箭头表示。箭头之间的间隔是 \(95 %\) 百分位间隔。
百分位数区间的优点是不需要计算标准误差。这在渐近标准误差计算复杂、繁琐或未知的情况下特别方便。 \(C^{\mathrm{pc}}\) 是引导算法的简单副产品,不需要高于计算引导标准误差所需的有意义的计算成本。
百分位数区间具有一个有用的属性,即它尊重变换。采用单调参数变换 \(m(\theta)\)。 \(m(\theta)\) 的百分位数区间只是由 \(m(\theta)\) 映射的 \(\theta\) 的百分位数区间。也就是说,如果 \(\left[q_{\alpha / 2}^{*}, q_{1-\alpha / 2}^{*}\right]\) 是 \(\theta\) 的百分位数区间,则 \(\left[m\left(q_{\alpha / 2}^{*}\right), m\left(q_{1-\alpha / 2}^{*}\right)\right]\) 是 \(m(\theta)\) 的百分位数区间。该属性直接源自样本分位数的等方差属性。许多置信区间方法(例如 delta 方法渐近区间和正态逼近区间 \(C^{\mathrm{nb}}\))不具有此属性。
为了说明变换相关属性的有用性,请考虑方差 \(\sigma^{2}\)。在某些情况下,报告方差 \(\sigma^{2}\) 很有用,而在其他情况下,报告标准差 \(\sigma\) 很有用。因此,我们可能对 \(\sigma^{2}\) 或 \(\sigma\) 的置信区间感兴趣。为了说明这一点,我们根据表 \(13.2\) 计算出的 \(\sigma^{2}\) 的渐近 \(95 %\) 正态置信区间是 \([0.060,0.228]\)。取平方根,我们得到 \(\sigma^{2}\) 的区间为 [0.244,0.477]。或者,\(\sigma^{2}\) 的 Delta 方法标准误差为 \(\sigma^{2}\),导致 \(\sigma^{2}\) 的 \(\sigma^{2}\) 的渐近 \(\sigma^{2}\) 置信区间不同。这表明 delta 方法不尊重变换。相反,\(\sigma^{2}\) 的 \(\sigma^{2}\) 百分位数区间为 \(\sigma^{2}\),\(\sigma^{2}\) 的 \(\sigma^{2}\) 百分位数区间为 \(\sigma^{2}\),这与 \(\sigma^{2}\) 区间的平方根相同。
表 13.2 报告了四个估计量的自举百分位数区间。在 Stata 中,可以使用命令 estat bootstrap、percentile 或命令 estat bootstrap 获得百分位数置信区间,所有这些都在通过 bootstrap 计算标准误差的估计命令之后。
10.9 Bootstrap 分布
对于应用程序来说,如果将引导程序理解为一种算法,通常就足够了。然而,对于理论来说,将引导程序视为抽样分布的特定估计量更有用。为此,引入一些附加符号很有用。
关键是任何估计量或统计量的分布都是由数据的分布决定的。虽然后者是未知的,但可以通过数据的经验分布来估计。这就是引导程序的作用。
为了固定符号,让 \(F\) 表示单个观测值 \(W\) 的分布。 (在回归中,\(W\) 是 \(\operatorname{pair}(Y, X)\)。)让 \(G_{n}(u, F)\) 表示估计量 \(\widehat{\theta}\) 的分布。那是,
\[ G_{n}(u, F)=\mathbb{P}[\widehat{\theta} \leq u \mid F] . \]
我们将分布 \(G_{n}\) 写为 \(n\) 和 \(F\) 的函数,因为后者(通常)影响 \(\widehat{\theta}\) 的分布。我们对分布 \(G_{n}\) 感兴趣。例如,我们想知道其方差以计算标准误差或其分位数以计算百分位数间隔。
原则上,如果我们知道分布 \(F\),我们应该能够确定分布 \(G_{n}\)。在实践中,实施存在两个障碍。第一个障碍是,除了某些特殊情况(例如正态回归模型)之外,\(G_{n}(u, F)\) 的计算通常是不可行的。第二个障碍是我们一般不知道 \(F\)。
引导程序通过两个巧妙的想法同时规避了这两个障碍。首先,引导程序建议通过经验分布函数 (EDF) \(F_{n}\) 来估计 \(F\),这是观测值联合分布的最简单的非参数估计器。 EDF 是 \(F_{n}(w)=n^{-1} \sum_{i=1}^{n} \mathbb{1}\left\{W_{i} \leq w\right\}\)。 (有关详细信息和属性,请参阅《经济学家概率与统计》的 \(11.2\) 部分。)将 \(F\) 替换为 \(F_{n}\),我们得到 \(\widehat{\theta}\) 分布的理想化引导估计量
\[ G_{n}^{*}(u)=G_{n}\left(u, F_{n}\right) . \]
bootstrap 的第二个聪明的想法是通过模拟来估计 \(G_{n}^{*}\)。这是前面几节中描述的引导算法。基本思想是 \(F_{n}\) 的模拟是从原始数据中进行替换采样,这在计算上很简单。应用 \(\hat{\theta}\) 的估计公式,我们获得独立同分布 (i.i.d)。从分布 \(G_{n}^{*}(u)\) 中得出。通过进行大量 \(B\) 这样的抽奖,我们可以估计 \(G_{n}^{*}\) 中感兴趣的任何特征。 bootstrap 结合了这两个想法:(1)通过 \(G_{n}\left(u, F_{n}\right)\) 估计 \(G_{n}(u, F)\); (2) 通过模拟估计\(G_{n}\left(u, F_{n}\right)\)。这些想法是相互交织的。只有综合考虑这些步骤,我们才能得到可行的方法。
思考 \(G_{n}\) 和 \(G_{n}^{*}\) 之间的联系的方法如下。 \(G_{n}\) 是对观测值进行 i.i.d 采样时获得的估计量 \(\widehat{\theta}\) 的分布。来自人口分布 \(F\)。 \(G_{n}^{*}\) 是相同统计量的分布,表示为 \(\widehat{\theta}^{*}\),是在对观测值进行 i.i.d 采样时获得的。来自经验分布 \(F_{n}\)。概念化单独生成数据集和引导样本的“宇宙”是有用的。 “抽样范围”是总体分布 \(F\)。在这个宇宙中,真正的参数是 \(G_{n}\)。 “引导宇宙”是经验分布 \(G_{n}\)。当从引导宇宙中提取时,我们将 \(G_{n}\) 视为真实分布。因此,关于 \(G_{n}\) 的任何真实情况都应该在 bootstrap 宇宙中被视为真实。在 bootstrap 宇宙中,参数 \(G_{n}\) 的“真实”值是由 EDF \(G_{n}\) 确定的值。在大多数情况下,这是估计值 \(G_{n}\)。当真实分布为 \(G_{n}\) 时,它是系数的真实值。我们现在仔细解释与前面描述的引导算法的连接。
首先,观察从样本 \(\left\{Y_{1}, \ldots, Y_{n}\right\}\) 进行放回采样与从 EDF \(F_{n}\) 进行采样相同。这是因为 EDF 是概率分布,它将概率质量 \(1 / n\) 放在每个观测值上。因此,从 \(F_{n}\) 采样意味着以 \(1 / n\) 概率对观测值进行采样,即放回采样。
其次,观察这里描述的引导估计器 \(\widehat{\theta}^{*}\) 与第 10.6 节中描述的引导算法相同。也就是说,\(\widehat{\theta}^{*}\) 是通过将估计公式 \(\widehat{\theta}\) 应用于从 \(F_{n}\) 随机采样获得的样本而生成的随机向量。
第三,观察这些自举估计量的分布是自举分布(10.9)。这是一个精确的平等。也就是说,引导算法生成 i.i.d。来自 \(F_{n}\) 的样本,当应用估计器时,我们获得分布为 \(G_{n}^{*}\) 的随机变量 \(\widehat{\theta}^{*}\)。
第四,观察前面描述的引导统计量 - 引导方差、标准误差和分位数 - 是引导分布 \(G_{n}^{*}\) 相应特征的估计量。
本讨论旨在仔细描述为什么符号 \(G_{n}^{*}(u)\) 对于帮助理解引导算法的属性很有用。由于 \(F_{n}\) 是未知分布的自然非参数估计器,因此 \(F, G_{n}^{*}(u)=G_{n}\left(u, F_{n}\right)\) 是未知分布 \(G_{n}(u, F)\) 的自然插件估计器。此外,由于根据 Glivenko-Cantelli 引理(《经济学家概率与统计》中的定理 \(18.8\)),\(F_{n}\) 对于 \(F\) 一致一致,我们也可以预期 \(G_{n}^{*}(u)\) 对于 \(G_{n}(u)\) 一致。由于 \(G_{n}^{*}(u)\) 和 \(G_{n}^{*}(u)\) 是函数,因此使其精确有点具有挑战性。在接下来的几节中,我们基于将渐近理论扩展到条件分布的情况,开发了自举分布的渐近分布理论。
10.10 Bootstrap 观测值的分布
令 \(Y^{*}\) 是从样本 \(\left\{Y_{1}, \ldots, Y_{n}\right\}\) 中随机抽取的。 \(Y^{*}\) 的分布是什么?
由于我们正在修正观测值,所以正确的问题是:以观测数据为条件的 \(Y^{*}\) 的条件分布是什么?经验分布函数 \(F_{n}\) 总结了样本中的信息,因此相当于我们正在讨论以 \(F_{n}\) 为条件的分布。因此,我们将引导概率函数和期望写为
\[ \begin{aligned} \mathbb{P}^{*}\left[Y^{*} \leq x\right] &=\mathbb{P}\left[Y^{*} \leq x \mid F_{n}\right] \\ \mathbb{E}^{*}\left[Y^{*}\right] &=\mathbb{E}\left[Y^{*} \mid F_{n}\right] . \end{aligned} \]
从符号上讲,加星号的分布和期望是有条件的给定数据。
\(Y^{*}\) 的(条件)分布是经验分布函数 \(F_{n}\),它是一个离散分布,每个观测值 \(Y_{i}\) 上都有质点 \(1 / n\)。因此,即使原始数据来自连续分布,引导数据分布也是离散的。
\(Y^{*}\) 的(条件)均值和方差是根据 EDF 计算的,等于数据的样本均值和方差。平均值是
\[ \mathbb{E}^{*}\left[Y^{*}\right]=\sum_{i=1}^{n} Y_{i} \mathbb{P}^{*}\left[Y^{*}=Y_{i}\right]=\sum_{i=1}^{n} Y_{i} \frac{1}{n}=\bar{Y} \]
方差是
\[ \begin{aligned} \operatorname{var}^{*}\left[Y^{*}\right] &=\mathbb{E}^{*}\left[Y^{*} Y^{* \prime}\right]-\left(\mathbb{E}^{*}\left[Y^{*}\right]\right)\left(\mathbb{E}^{*}\left[Y^{*}\right]\right)^{\prime} \\ &=\sum_{i=1}^{n} Y_{i} Y_{i}^{\prime} \mathbb{P}^{*}\left[Y^{*}=Y_{i}\right]-\bar{Y} \bar{Y}^{\prime} \\ &=\sum_{i=1}^{n} Y_{i} Y_{i}^{\prime} \frac{1}{n}-\bar{Y} \bar{Y}^{\prime} \\ &=\widehat{\Sigma} \end{aligned} \]
总而言之,给定 \(F_{n}\),\(Y^{*}\) 的条件分布是 \(\left\{Y_{1}, \ldots, Y_{n}\right\}\) 上的离散分布,平均值为 \(\bar{Y}\),协方差矩阵为 \(\widehat{\Sigma}\)。
我们可以将此分析扩展到任何整数矩 \(r\)。假设 \(Y\) 是标量。 \(Y^{*}\) 的 \(r^{t h}\) 矩是
\[ \mu_{r}^{* \prime}=\mathbb{E}^{*}\left[Y^{* r}\right]=\sum_{i=1}^{n} Y_{i}^{r} \mathbb{P}^{*}\left[Y^{*}=Y_{i}\right]=\frac{1}{n} \sum_{i=1}^{n} Y_{i}^{r}=\widehat{\mu}_{r}^{\prime}, \]
\(r^{t h}\) 样本时刻。 \(Y^{*}\) 的 \(r^{t h}\) 中心矩是
\[ \mu_{r}^{*}=\mathbb{E}^{*}\left[\left(Y^{*}-\bar{Y}\right)^{r}\right]=\frac{1}{n} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{r}=\widehat{\mu}_{r}, \]
\(r^{t h}\) 中心样本时刻。同样,\(Y^{*}\) 的 \(r^{t h}\) 累积量是 \(\kappa_{r}^{*}=\widehat{\kappa}_{r}\),即 \(r^{t h}\) 样本累积量。
10.11 Bootstrap 样本均值的分布
自举样本均值是
\[ \bar{Y}^{*}=\frac{1}{n} \sum_{i=1}^{n} Y_{i}^{*} . \]
我们可以计算它的(条件)均值和方差。平均值是
\[ \mathbb{E}^{*}\left[\bar{Y}^{*}\right]=\mathbb{E}^{*}\left[\frac{1}{n} \sum_{i=1}^{n} Y_{i}^{*}\right]=\frac{1}{n} \sum_{i=1}^{n} \mathbb{E}^{*}\left[Y_{i}^{*}\right]=\frac{1}{n} \sum_{i=1}^{n} \bar{Y}=\bar{Y} \]
使用(10.10)。因此,引导样本均值 \(\bar{Y}^{*}\) 的分布以样本均值 \(\bar{Y}\) 为中心。这是因为 bootstrap 观测值 \(Y_{i}^{*}\) 是从 bootstrap 宇宙中得出的,它将 EDF 视为真相,而后者分布的均值是 \(\bar{Y}\)。
自举样本均值的(条件)方差为
\[ \operatorname{var}^{*}\left[\bar{Y}^{*}\right]=\operatorname{var}^{*}\left[\frac{1}{n} \sum_{i=1}^{n} Y_{i}^{*}\right]=\frac{1}{n^{2}} \sum_{i=1}^{n} \operatorname{var}^{*}\left[Y_{i}^{*}\right]=\frac{1}{n^{2}} \sum_{i=1}^{n} \widehat{\Sigma}=\frac{1}{n} \widehat{\Sigma} \]
使用(10.11)。在标量情况下,\(\operatorname{var}^{*}\left[\bar{Y}^{*}\right]=\widehat{\sigma}^{2} / n\)。这表明 \(\bar{Y}^{*}\) 的自举方差是由原始观测值的样本方差精确描述的。同样,这是因为引导观测值 \(Y_{i}^{*}\) 是从引导宇宙中提取的。
我们可以将其扩展到任何整数矩 \(r\)。假设 \(Y\) 是标量。定义归一化引导样本均值 \(Z_{n}^{*}=\sqrt{n}\left(\bar{Y}^{*}-\bar{Y}\right)\)。使用《经济学家概率与统计》第 \(6.17\) 节中的表达式,\(Z_{n}^{*}\) 的 \(3^{r d}\) 到 \(6^{\text {th }}\) 条件矩为
\[ \begin{aligned} &\mathbb{E}^{*}\left[Z_{n}^{* 3}\right]=\widehat{\kappa}_{3} / n^{1 / 2} \\ &\mathbb{E}^{*}\left[Z_{n}^{* 4}\right]=\widehat{\kappa}_{4} / n+3 \widehat{\kappa}_{2}^{2} \\ &\mathbb{E}^{*}\left[Z_{n}^{* 5}\right]=\widehat{\kappa}_{5} / n^{3 / 2}+10 \widehat{\kappa}_{3} \widehat{\kappa}_{2} / n^{1 / 2} \\ &\mathbb{E}^{*}\left[Z_{n}^{* 6}\right]=\widehat{\kappa}_{6} / n^{2}+\left(15 \widehat{\kappa}_{4} \kappa_{2}+10 \widehat{\kappa}_{3}^{2}\right) / n+15 \widehat{\kappa}_{2}^{3} \end{aligned} \]
其中 \(\widehat{\kappa}_{r}\) 是 \(r^{t h}\) 样本累积量。对于更高的矩可以导出类似的表达式。矩 (10.14) 是精确的,而不是近似值。
10.12 自举渐进
引导均值 \(\bar{Y}^{*}\) 是 \(n\) i.i.d 上的样本平均值。随机变量,因此我们可能期望它以概率收敛到其期望。确实如此,但我们必须小心一点,因为引导均值具有条件分布(给定数据),因此我们需要定义条件分布的概率收敛。
定义 \(10.1\) 我们说随机向量 \(Z_{n}^{*}\) 以引导概率收敛到 \(Z\) 作为 \(n \rightarrow \infty\),表示为 \(Z_{n}^{*} \underset{p^{*}}{\longrightarrow} Z\),如果对于所有 \(\epsilon>0\)
\[ \mathbb{P}^{*}\left[\left\|Z_{n}^{*}-Z\right\|>\epsilon\right] \underset{p}{\longrightarrow} 0 \]
要理解这个定义,请回想一下概率 \(Z_{n} \underset{p}{\longrightarrow}\) 的传统收敛意味着,对于足够大的样本量 \(n\),\(Z_{n}\) 任意接近其极限 \(Z\) 的概率很高。相反,定义 \(10.1\) 表示 \(Z_{n}^{*} \underset{p^{*}}{ } Z\) 意味着对于足够大的 \(n\),\(Z_{n}^{*}\) 接近其极限 \(Z\) 的条件概率很高。请注意,概率有两种用途:无条件概率和有条件概率。
我们的标签“引导概率收敛”有点不寻常。许多统计文献中使用的标签是“概率收敛,概率”,但这似乎很拗口。该文献更多地关注“概率收敛,几乎肯定”的相关概念,如果我们用几乎肯定收敛替换“\(\underset{p}{\text { " }}\)收敛”,则该概念成立。我们在本章中不使用这个概念,因为它是不必要的复杂化。
虽然我们已经为特定的条件概率分布 \(\mathbb{P}^{*}\) 声明了定义 \(10.1\),但这个想法更通用,可以用于任何条件分布和任何随机向量序列。
以下内容可能看起来很明显,但为了清楚起见,进行说明很有用。它的证明在 \(10.31 .\) 节中给出
定理\(10.1\) 如果\(Z_{n} \underset{p}{\longrightarrow} Z\) 为\(n \rightarrow \infty\),则\(Z_{n} \underset{p^{*}}{ } Z\)。
给定定义 10.1,我们可以为引导样本均值建立大数定律。定理 \(10.2\) Bootstrap WLLN。如果 \(Y_{i}\) 独立且一致可积,则 \(\bar{Y}^{*}-\bar{Y} \underset{p^{*}}{\longrightarrow} 0\) 和 \(\bar{Y}^{*} \underset{p^{*}}{\longrightarrow} \mu=\mathbb{E}[Y]\) 与 \(n \rightarrow \infty\) 相同。
该证明(第 10.31 节中介绍)与经典案例有些不同,因为它基于 Marcinkiewicz WLLN(定理 10.20,第 10.31 节中介绍)。
请注意,引导 WLLN 的条件与传统 WLLN 的条件相同。另请注意,我们陈述了两个相关但略有不同的结果。第一个是,引导样本均值 \(\bar{Y}^{*}\) 和样本均值 \(\bar{Y}\) 之间的差异随着样本大小的变化而减小。第二个结果是引导样本均值收敛于总体均值 \(\mu\)。后者并不奇怪(因为样本均值 \(\bar{Y}\) 收敛到 \(\mu\) 的概率),但准确地说它是有建设性的,因为我们正在处理一个新的收敛概念。
定理10.3 Bootstrap连续映射定理。如果 \(Z_{n}^{*} \underset{p^{*}}{ } c\) 与 \(n \rightarrow\)、\(\infty\) 且 \(g(\cdot)\) 在 \(c\) 处连续,则 \(g\left(Z_{n}^{*}\right) \underset{p^{*}}{ } g(c)\) 与 \(n \rightarrow \infty\) 连续。
该证明与定理 \(6.6\) 的证明本质上相同,因此被省略。
接下来我们想证明自举样本均值是渐近正态分布的,但为此我们需要条件分布收敛的定义。
定义 \(10.2\) 令 \(Z_{n}^{*}\) 为具有条件分布 \(G_{n}^{*}(x)=\mathbb{P}^{*}\left[Z_{n}^{*} \leq x\right]\) 的随机向量序列。我们说 \(Z_{n}^{*}\) 在引导分布中收敛到 \(Z\) 作为 \(n \rightarrow \infty\),表示为 \(Z_{n}^{*} \underset{d^{*}}{\longrightarrow}\),如果对于 \(G(x)=\mathbb{P}[Z \leq x]\) 连续的所有 \(x\),则 \(10.2\) 作为 \(10.2\)。
与传统定义的区别在于,定义 \(10.2\) 将条件分布视为随机。定义 \(10.2\) 的另一个标签是“概率分布的收敛”。
现在,我们声明引导样本均值的 CLT,并在第 10.31 节中给出证明。
定理 10.4 Bootstrap CLT。如果 \(Y_{i}\) 是 i.i.d.、\(\mathbb{E}\|Y\|^{2}<\infty\) 和 \(\Sigma=\operatorname{var}[Y]>0\),则为 \(n \rightarrow \infty, \sqrt{n}\left(\bar{Y}^{*}-\bar{Y}\right) \underset{d^{*}}{\longrightarrow} \mathrm{N}(0, \Sigma)\)。
定理 \(10.4\) 表明归一化引导样本均值与样本均值具有相同的渐近分布。因此,自举分布与抽样分布渐近相同。然而,一个显着的区别是,引导样本均值通过以样本均值(而不是总体均值)为中心进行标准化。这是因为 \(\bar{Y}\) 是 bootstrap 宇宙中的真实平均值。
接下来我们阐述引导分布的连续映射定理的分布形式和引导 Delta 方法。定理10.5 Bootstrap连续映射定理
如果 \(Z_{n}^{*} \underset{d^{*}}{ } Z\) 作为 \(n \rightarrow \infty\) 且 \(g: \mathbb{R}^{m} \rightarrow \mathbb{R}^{k}\) 具有一组不连续点 \(D_{g}\),使得 \(\mathbb{P}^{*}\left[Z^{*} \in D_{g}\right]=0\),则 \(g\left(Z_{n}^{*}\right) \underset{d^{*}}{\rightarrow} g(Z)\) 作为 \(n \rightarrow \infty\)。
定理10.6 Bootstrap Delta方法: 如果 \(\widehat{\mu} \underset{p}{\longrightarrow} \mu, \sqrt{n}\left(\widehat{\mu}^{*}-\widehat{\mu}\right) \underset{d^{*}}{\longrightarrow} \xi\) 和 \(g(u)\) 在 \(\mu\) 的邻域内连续可微,则 \(n \rightarrow \infty\)
\[ \sqrt{n}\left(g\left(\widehat{\mu}^{*}\right)-g(\widehat{\mu})\right) \underset{d^{*}}{\longrightarrow} \boldsymbol{G}^{\prime} \xi \]
其中 \(\boldsymbol{G}(x)=\frac{\partial}{\partial x} g(x)^{\prime}\) 和 \(\boldsymbol{G}=\boldsymbol{G}(\mu)\)。特别是,如果 \(\xi \sim \mathrm{N}(0, \boldsymbol{V})\) 则为 \(n \rightarrow \infty\)
\[ \sqrt{n}\left(g\left(\widehat{\mu}^{*}\right)-g(\widehat{\mu})\right) \underset{d^{*}}{\longrightarrow} \mathrm{N}\left(0, \boldsymbol{G}^{\prime} \boldsymbol{V} \boldsymbol{G}\right) . \]
证明请参见练习 10.7。
我们对定理 6.10 进行了模拟,该定理提出了样本均值的一般平滑函数的渐近分布,涵盖了大多数计量经济学估计量。
定理 10.7 在定理 6.10 的假设下,即如果 \(Y_{i}\) 独立同分布,则 \(\mu=\mathbb{E}[h(Y)], \theta=g(\mu), \mathbb{E}\|h(Y)\|^{2}<\infty\) 和 \(\boldsymbol{G}(x)=\frac{\partial}{\partial x} g(x)^{\prime}\) 在 \(\mu\) 的邻域内连续,对于 \(\widehat{\theta}=g(\widehat{\mu})\) 和 \(\widehat{\mu}=\frac{1}{n} \sum_{i=1}^{n} h\left(Y_{i}\right)\) 以及 \(\widehat{\theta}^{*}=g\left(\widehat{\mu}^{*}\right)\) 来说\(\widehat{\mu}^{*}=\frac{1}{n} \sum_{i=1}^{n} h\left(Y_{i}^{*}\right)\),如 \(n \rightarrow \infty\)
\[ \sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) \underset{d^{*}}{\longrightarrow} \mathrm{N}\left(0, \boldsymbol{V}_{\theta}\right) \]
其中 \(\boldsymbol{V}_{\theta}=\boldsymbol{G}^{\prime} \boldsymbol{V} \boldsymbol{G}, \boldsymbol{V}=\mathbb{E}\left[(h(Y)-\mu)(h(Y)-\mu)^{\prime}\right]\) 和 \(\boldsymbol{G}=\boldsymbol{G}(\mu)\)。
证明请参见练习 10.8。
定理 \(10.7\) 表明自举估计器 \(\widehat{\theta}^{*}\) 的渐近分布与样本估计器 \(\widehat{\theta}\) 的渐近分布相同。这意味着我们可以从引导分布中学习 \(\widehat{\theta}\) 的分布,从而执行渐近正确的推理。
对于某些引导程序应用程序,我们使用引导程序方差估计。 \(\boldsymbol{V}_{\boldsymbol{\theta}}\) 的插件估计器是 \(\widehat{\boldsymbol{V}}_{\theta}=\widehat{\boldsymbol{G}}^{\prime} \widehat{\boldsymbol{V}} \widehat{\boldsymbol{G}}\),其中 \(\widehat{\boldsymbol{G}}=\boldsymbol{G}(\widehat{\mu})\) 和
\[ \widehat{\boldsymbol{V}}=\frac{1}{n} \sum_{i=1}^{n}\left(h\left(Y_{i}\right)-\widehat{\mu}\right)\left(h\left(Y_{i}\right)-\widehat{\mu}\right)^{\prime} . \]
引导版本是
\[ \begin{aligned} &\widehat{\boldsymbol{V}}_{\theta}^{*}=\widehat{\boldsymbol{G}}^{* \prime} \widehat{\boldsymbol{V}}^{*} \widehat{\boldsymbol{G}}^{*} \\ &\widehat{\boldsymbol{G}}^{*}=\boldsymbol{G}\left(\widehat{\mu}^{*}\right) \\ &\widehat{\boldsymbol{V}}^{*}=\frac{1}{n} \sum_{i=1}^{n}\left(h\left(Y_{i}^{*}\right)-\widehat{\mu}^{*}\right)\left(h\left(Y_{i}^{*}\right)-\widehat{\mu}^{*}\right)^{\prime} . \end{aligned} \]
bootstrap WLLN 和 bootstrap CMT 的应用表明 \(\widehat{\boldsymbol{V}}_{\theta}^{*}\) 与 \(\boldsymbol{V}_{\theta}\) 是一致的。
定理\(10.8\) 在定理10.7 的假设下,\(\widehat{\boldsymbol{V}}_{\theta}^{*} \underset{p^{*}}{\longrightarrow} \boldsymbol{V}_{\theta}\) 与\(n \rightarrow \infty\) 相同。
证明请参见练习 10.9。
10.13 Bootstrap 方差估计的一致性
回想一下估计器 \(\widehat{\theta}\) 的方差引导估计器 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {boot }}\) 的定义 (10.7)。在本节中,我们将探讨 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {boot }}\) 与 \(\widehat{\theta}\) 的渐近方差一致的条件。
为此,关注估计量的归一化版本很有用,这样渐近方差就不会退化。假设对于某个序列 \(a_{n}\) 我们有
\[ Z_{n}=a_{n}(\widehat{\theta}-\theta) \underset{d}{\longrightarrow} \xi \]
和
\[ Z_{n}^{*}=a_{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) \underset{d^{*}}{\longrightarrow} \xi \]
对于某些极限分布 \(\xi\)。也就是说,对于某些归一化,\(\hat{\theta}\) 和 \(\widehat{\theta}^{*}\) 都具有相同的渐近分布。这是非常普遍的,因为它包括平滑函数模型。 \(Z_{n}\) 方差的传统 bootstrap 估计器是 bootstrap 绘制 \(\left\{Z_{n}^{*}(b): b=1, \ldots, B\right\}\) 的样本方差。这等于估计量 (10.7) 乘以 \(a_{n}^{2}\)。因此,无论我们讨论估计 \(\widehat{\theta}\) 还是 \(Z_{n}\) 的方差,都是等效的(按比例)。
\(Z_{n}\) 方差的自举估计量为
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\theta}^{\text {boot,B }} &=\frac{1}{B-1} \sum_{b=1}^{B}\left(Z_{n}^{*}(b)-Z_{n}^{*}\right)\left(Z_{n}^{*}(b)-Z_{n}^{*}\right)^{\prime} \\ \bar{Z}_{n}^{*} &=\frac{1}{B} \sum_{b=1}^{B} Z_{n}^{*}(b) \end{aligned} \]
请注意,我们通过引导复制 \(B\) 的数量对估计器进行索引。
由于 \(Z_{n}^{*}\) 在自举分布中收敛到与 \(Z_{n}\) 相同的渐近分布,因此猜测 \(Z_{n}^{*}\) 的方差将收敛到 \(\xi\) 的方差似乎是合理的。然而,分布的收敛不足以实现矩的收敛。为了使方差收敛,序列 \(Z_{n}^{*}\) 也必须是一致平方可积的。定理 \(10.9\) 如果 (10.15) 和 (10.16) 对于某个序列 \(a_{n}\) 成立且 \(\left\|Z_{n}^{*}\right\|^{2}\) 一致可积,则 \(B \rightarrow \infty\)
\[ \widehat{\boldsymbol{V}}_{\theta}^{\mathrm{boot}, \mathrm{B}} \underset{p^{*}}{\longrightarrow} \widehat{\boldsymbol{V}}_{\theta}^{\text {boot }}=\operatorname{var}\left[Z_{n}^{*}\right] \text {, } \]
和 \(n \rightarrow \infty\)
\[ \widehat{\boldsymbol{V}}_{\theta}^{\text {boot }} \underset{p^{*}}{\longrightarrow} \boldsymbol{V}_{\theta}=\operatorname{var}[\xi] . \]
这就提出了一个问题:标准化序列 \(Z_{n}\) 是否一致可积?我们用本节的剩余部分来探讨这个问题,并在下一节中转向不需要统一可积性的修剪方差估计器。
对于具有有限方差的标量样本均值的情况,验证此条件相当简单。也就是说,假设 \(Z_{n}^{*}=\sqrt{n}\left(\bar{Y}^{*}-\bar{Y}\right)\) 和 \(\mathbb{E}\left[Y^{2}\right]<\infty\)。在(10.14)中,我们计算了 \(Z_{n}^{*}\) 的精确第四中心矩:
\[ \mathbb{E}^{*}\left[Z_{n}^{* 4}\right]=\frac{\widehat{\kappa}_{4}}{n}+3 \widehat{\sigma}^{4}=\frac{\widehat{\mu}_{4}-3 \widehat{\sigma}^{4}}{n}+3 \widehat{\sigma}^{4} \]
其中 \(\widehat{\sigma}^{2}=n^{-1} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}\) 和 \(\widehat{\mu}_{4}=n^{-1} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{4}\)。假设 \(\mathbb{E}\left[Y^{2}\right]<\infty\) 意味着 \(\mathbb{E}\left[\widehat{\sigma}^{2}\right]=O(1)\) 和 \(\widehat{\sigma}^{2}=O_{p}(1)\)。此外,Marcinkiewicz WLLN 的 \(n^{-1} \widehat{\mu}_{4}=n^{-2} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{4}=o_{p}(1)\)(定理 10.20)。它遵循
\[ \mathbb{E}^{*}\left[Z_{n}^{* 4}\right]=n^{2} \mathbb{E}^{*}\left[\left(\bar{Y}^{*}-\bar{Y}\right)^{4}\right]=O_{p}(1) . \]
定理 \(6.13\) 表明这意味着 \(Z_{n}^{* 2}\) 是一致可积的。因此,如果 \(Y\) 具有有限方差,则归一化引导样本均值可均匀平方可积,并且引导方差估计与定理 \(10.9\) 一致。
现在考虑定理 10.7 的平滑函数模型。我们可以得出以下结果。
定理 10.10 在定理 10.7 的平滑函数模型中,如果对于某些 \(p \geq 1\),\(g(x)\) 的 \(p^{t h}\) 阶导数是有界的,则 \(Z_{n}^{*}=\sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right)\) 是一致平方可积的,并且方差的自举估计量与定理中一致10.9。
证明参见 \(10.31\) 节。
这表明方差的引导估计对于相当广泛的估计量类别是一致的。此结果涵盖的函数类 \(g(x)\) 包括所有 \(p^{t h}\) 阶多项式。
10.14 Bootstrap 方差的修剪估计器
定理 \(10.10\) 表明方差自举估计量对于具有有界 \(p^{t h}\) 阶导数的平滑函数是一致的。这是一个相当广泛的类别,但排除了许多重要的应用程序。例如 \(\theta=\mu_{1} / \mu_{2}\),其中 \(\mu_{1}=\mathbb{E}\left[Y_{1}\right]\) 和 \(\mu_{2}=\mathbb{E}\left[Y_{2}\right]\)。该函数没有有界导数(除非 \(\mu_{2}\) 远离零),因此不包含在定理 10.10 中。这不仅仅是一个技术问题。当 \(\left(Y_{1}, Y_{2}\right)\) 服从联合正态分布时,就知道 \(\widehat{\theta}=\bar{Y}_{1} / \bar{Y}_{2}\) 不具有有限方差。因此,我们不能期望方差自举估计器表现良好。 (它试图估计 \(\widehat{\theta}\) 的方差,它是无穷大。)
在这些情况下,最好使用自举方差的修剪估计量。令 \(\tau_{n} \rightarrow \infty\) 为满足 \(\tau_{n}=O\left(e^{n / 8}\right)\) 的正修剪数序列。定义修剪统计量
\[ Z_{n}^{* *}=Z_{n}^{*} \mathbb{1}\left\{\left\|Z_{n}^{*}\right\| \leq \tau_{n}\right\} . \]
方差的修剪自举估计量为
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\theta}^{\text {boot, }, \tau} &=\frac{1}{B-1} \sum_{b=1}^{B}\left(Z_{n}^{* *}(b)-Z_{n}^{* *}\right)\left(Z_{n}^{* *}(b)-Z_{n}^{* *}\right)^{\prime} \\ Z_{n}^{* *} &=\frac{1}{B} \sum_{b=1}^{B} Z_{n}^{* *}(b) . \end{aligned} \]
我们首先检查 \(\widehat{\boldsymbol{V}}_{\theta}^{\text {boot, } \mathrm{B}}\) 随着引导复制 \(B\) 的数量增长到无穷大的行为。它是独立有界随机向量的样本方差。因此,通过引导 WLLN(定理 10.2),\(\widehat{\boldsymbol{V}}_{\theta}^{\mathrm{boot}, \mathrm{B}, \tau}\) 在引导概率中收敛于 \(Z_{n}^{* *}\) 的方差。
接下来我们检查当 \(n\) 增长到无穷大时引导估计器 \(\widehat{\boldsymbol{V}}_{\theta}^{\text {boot, } \tau}\) 的行为。我们关注定理 10.7 的平滑函数模型,它表明 \(Z_{n}^{*}=\sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) \underset{d^{*}}{\longrightarrow} \sim \mathrm{N}\left(0, \boldsymbol{V}_{\theta}\right)\).由于修剪是渐近可以忽略不计的,因此 \(Z_{n}^{* *} \underset{d^{*}}{\longrightarrow}\) 成立。如果我们可以证明 \(Z_{n}^{* *}\) 是一致平方可积的,则定理 \(10.9\) 表明 \(\operatorname{var}\left[Z_{n}^{* *}\right] \rightarrow \operatorname{var}[Z]=\boldsymbol{V}_{\theta}\) 与 \(n \rightarrow \infty\) 相同。这显示在下面的结果中,其证明在第 10.31 节中给出。
定理 \(10.12\) 在定理 10.7 的假设下,\(\widehat{\boldsymbol{V}}_{\theta}^{\mathrm{boot}, \tau} \underset{p^{*}}{\longrightarrow} \boldsymbol{V}_{\theta} .\)
定理 \(10.11\) 和 \(10.12\) 表明,方差的修剪自举估计量对于平滑函数模型(包括大多数计量经济学估计量)中的渐近方差是一致的。这证明了引导标准误差作为渐近分布的一致估计量是合理的。
一个重要的警告是,这些结果严重依赖于修剪方差估计器。这是一个重要的警告,因为传统统计软件包(例如 Stata)使用未修剪估计器(10.7)计算引导标准误差。因此,不能保证报告的标准误差是一致的。未修剪方差估计器在定理 \(10.10\) 的背景下工作,并且每当引导统计量均匀平方可积时,但不一定在一般应用中。
在实践中,可能很难知道如何选择修剪序列\(\tau_{n}\)。规则 \(\tau_{n}=O\left(e^{n / 8}\right)\) 不提供实际指导。相反,考虑根据引导抽签的百分比进行调整可能会很有用。因此,我们可以设置 \(\tau_{n}\),以便修剪给定的小百分比 \(\gamma_{n}\)。对于理论解释,我们将 \(\gamma_{n} \rightarrow 0\) 设置为 \(n \rightarrow \infty\)。实际上,我们可以设置 \(\gamma_{n}=1 %\)。
10.15 未修剪的引导标准误差的不可靠性
在上一节中,我们提出了一个修剪后的引导方差估计器,该估计器应用于形成非线性估计器的引导标准误差。否则,未修剪的估计器可能不可靠。
这是一种不幸的情况,因为引导标准误差的报告在当代应用计量经济学实践中很常见,并且标准应用程序(包括 Stata)使用未修剪的估计量。
为了说明问题的严重性,我们使用简单的工资回归(7.31),我们在这里重复一下。这是已婚黑人女性的子样本,有 982 个观察值。点估计值和标准误是
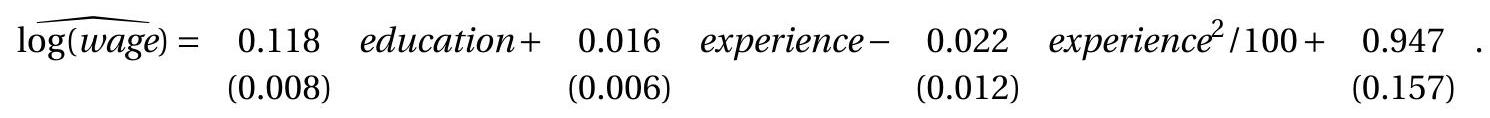
我们对最大化预期对数工资 \(\theta_{3}=-50 \beta_{2} / \beta_{3}\) 的经验水平感兴趣。下面的表 \(10.3\) 报告了使用不同方法计算的点估计和标准误差。
具有最大收入的经验水平的点估计为 \(\widehat{\theta}_{3}=35\)。渐近标准误和折刀标准误约为 7 。然而,引导程序标准错误是 825 !我们对这个不寻常的值感到困惑,重新运行引导程序并获得标准错误 544 。每个都是通过 10,000 次引导复制来计算的。重新计算时(使用不同的起始种子)两个引导程序标准错误有很大不同,这一事实表明存在瞬间失败。当渐近标准误差和自举标准误差之间以及自举运行之间存在如此巨大的差异时,这是一个信号,表明可能存在瞬间故障,因此自举标准误差是不可靠的。
使用 \(\tau=25\) 进行修剪的引导程序(设置为稍微超过三个渐近标准误差)会产生更合理的标准误差 \(10 .\)
该应用程序发出的一条消息是,当不同的方法产生截然不同的标准错误时,我们应该谨慎信任任何单一方法。巨大的差异表明渐近近似较差,导致所有方法都不准确。另一个消息是要谨慎报告传统的引导程序标准错误。修剪版本是首选,特别是对于估计系数的非线性函数。
表 10.3:使预期日志工资最大化的经验水平
| Estimate | \(35.2\) |
|---|---|
| Asymptotic s.e. | \((7.0)\) |
| Jackknife s.e. | \((7.0)\) |
| Bootstrap s.e. (standard) | \((825)\) |
| Bootstrap s.e. (repeat) | \((544)\) |
| Bootstrap s.e. (trimmed) | \((10.1)\) |
10.16 百分位数区间的一致性
回想一下百分位数区间 (10.8)。我们现在提供其具有渐近正确覆盖范围的条件。定理 \(10.13\) 假设对于某些序列 \(a_{n}\)
\[ a_{n}(\widehat{\theta}-\theta) \underset{d}{\longrightarrow} \xi \]
和
\[ a_{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) \underset{d^{*}}{\longrightarrow} \xi \]
其中 \(\xi\) 是连续分布的并且关于零对称。然后 \(\mathbb{P}\left[\theta \in C^{\mathrm{pc}}\right] \rightarrow 1-\alpha\) 为 \(n \rightarrow \infty\)
假设(10.18)-(10.19)对于定理10.7的光滑函数模型成立,因此该结果具有许多应用。定理 \(10.13\) 的美妙之处在于,简单的置信区间 \(C^{\mathrm{pc}}\) - 不需要渐近标准误差的技术计算 - 对于属于平滑函数类的任何估计量以及满足以下条件的任何其他估计量都具有渐近有效的覆盖范围\(\xi\) 的收敛结果 (10.18)-(10.19) 对称分布。这些条件比一致引导方差估计(和正态近似置信区间)所需的条件弱,因为不需要验证 \(\widehat{\theta}^{*}\) 是否一致可积,也不需要采用修剪。
定理\(10.7\)的证明并不困难。收敛假设 (10.19) 意味着 \(a_{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right)\) 的 \(\alpha^{t h}\) 分位数(按分位数等方差计算为 \(a_{n}\left(q_{\alpha}^{*}-\widehat{\theta}\right)\))在概率上收敛到 \(\xi\) 的 \(\alpha^{t h}\) 分位数,我们可以将其表示为 \(\bar{q}_{\alpha}\)。因此
\[ a_{n}\left(q_{\alpha}^{*}-\widehat{\theta}\right) \underset{p}{\longrightarrow} \bar{q}_{\alpha} . \]
令 \(H(x)=\mathbb{P}[\xi \leq x]\) 为 \(\xi\) 的分布函数。对称性假设意味着 \(H(-x)=\) \(1-H(x)\)。那么百分位数区间就有覆盖范围
\[ \begin{aligned} \mathbb{P}\left[\theta \in C^{\mathrm{pc}}\right] &=\mathbb{P}\left[q_{\alpha / 2}^{*} \leq \theta \leq q_{1-\alpha / 2}^{*}\right] \\ &=\mathbb{P}\left[-a_{n}\left(q_{\alpha / 2}^{*}-\widehat{\theta}\right) \geq a_{n}(\widehat{\theta}-\theta) \geq-a_{n}\left(q_{1-\alpha / 2}^{*}-\widehat{\theta}\right)\right] \\ & \rightarrow \mathbb{P}\left[-\bar{q}_{\alpha / 2} \geq \xi \geq-\bar{q}_{1-\alpha / 2}\right] \\ &=H\left(-\bar{q}_{\alpha / 2}\right)-H\left(-\bar{q}_{1-\alpha / 2}\right) \\ &=H\left(\bar{q}_{1-\alpha / 2}\right)-H\left(\bar{q}_{\alpha / 2}\right) \\ &=1-\alpha . \end{aligned} \]
(10.18) 和 (10.20) 收敛成立。以下等式使用 \(H\) 的定义,倒数第二个是 \(H\) 的对称性,最后一个等式是 \(\bar{q}_{\alpha}\) 的定义。这建立了定理 \(10.13 .\)
定理 \(10.13\) 看起来相当普遍,但它关键依赖于渐近分布 \(\xi\) 关于零对称分布的假设。这可能看起来无害,因为传统的渐近分布是正态的,因此是对称的,但它值得进一步审查。这不仅仅是一个技术假设 - 对前面论证中的步骤的检查非常清楚地表明,如果对称性假设被违反,那么渐近覆盖将不是 \(1-\alpha\)。虽然定理 \(10.13\) 确实表明百分位数区间对于传统的渐近正态估计量是渐近有效的,但论证中对对称性的依赖表明,当有限样本分布不对称时,百分位数方法的效果会很差。事实证明确实如此,并促使我们在以下各节中考虑替代方法。基于 Efron 的启发式类比,研究百分位区间的有限样本合理性也是值得的。
假设存在未知但严格递增的变换 \(\psi(\theta)\) ,使得 \(\psi(\widehat{\theta})-\) \(\psi(\theta)\) 具有关于零对称的关键分布 \(H(u)\) (不随 \(\theta\) 变化)。例如,如果 \(\widehat{\theta} \sim \mathrm{N}\left(\theta, \sigma^{2}\right)\) 我们可以设置 \(\psi(\theta)=\theta / \sigma\)。或者,如果 \(\widehat{\theta}=\exp (\widehat{\mu})\) 和 \(\widehat{\mu} \sim \mathrm{N}\left(\mu, \sigma^{2}\right)\) 那么我们可以设置 \(\psi(\theta)\) \(\psi(\theta)\)
要评估百分位区间的覆盖范围,请观察由于分布 \(H\) 是关键,引导分布 \(\psi\left(\widehat{\theta}^{*}\right)-\psi(\widehat{\theta})\) 也具有分布 \(H(u)\)。令 \(\bar{q}_{\alpha}\) 为分布 \(H\) 的 \(\alpha^{\text {th }}\) 分位数。由于 \(q_{\alpha}^{*}\) 是 \(\widehat{\theta}^{*}\) 分布的 \(\alpha^{t h}\) 分位数,而 \(H\) 是 \(H\) 的单调变换,通过分位数等方差性质,我们推导出 \(H\)。百分位区间有覆盖范围
\[ \begin{aligned} \mathbb{P}\left[\theta \in C^{\mathrm{pc}}\right] &=\mathbb{P}\left[q_{\alpha / 2}^{*} \leq \theta \leq q_{1-\alpha / 2}^{*}\right] \\ &=\mathbb{P}\left[\psi\left(q_{\alpha / 2}^{*}\right) \leq \psi(\theta) \leq \psi\left(q_{1-\alpha / 2}^{*}\right)\right] \\ &=\mathbb{P}\left[\psi(\widehat{\theta})-\psi\left(q_{\alpha / 2}^{*}\right) \geq \psi(\widehat{\theta})-\psi(\theta) \geq \psi(\widehat{\theta})-\psi\left(q_{1-\alpha / 2}^{*}\right)\right] \\ &=\mathbb{P}\left[-\bar{q}_{\alpha / 2} \geq \psi(\widehat{\theta})-\psi(\theta) \geq-\bar{q}_{1-\alpha / 2}\right] \\ &=H\left(-\bar{q}_{\alpha / 2}\right)-H\left(-\bar{q}_{1-\alpha / 2}\right) \\ &=H\left(\bar{q}_{1-\alpha / 2}\right)-H\left(\bar{q}_{\alpha / 2}\right) \\ &=1-\alpha . \end{aligned} \]
第二个等式将单调变换 \(\psi(u)\) 应用于所有元素。第四个使用关系 \(\bar{q}_{\alpha}+\psi(\widehat{\theta})=\psi\left(q_{\alpha}^{*}\right)\)。第五个使用 \(H\) 的定义。第六个使用 \(H\) 的对称性,最后一个是通过 \(\bar{q}_{\alpha}\) 定义为 \(H\) 的 \(\alpha^{t h}\) 分位数。
此计算表明,在这些假设下,百分位数区间具有精确的覆盖范围 \(1-\alpha\)。这个论点的好处是引入了未知变换 \(\psi(u)\),百分位数区间会自动适应该变换。令人不快的特征是对称性假设。与渐进论证类似,计算强烈依赖于分布 \(H(x)\) 的对称性。如果不对称,覆盖范围将不正确。
直观上,我们期望当假设近似正确时,百分位数区间将具有近似正确的覆盖范围。因此,只要有一个变换 \(\psi(u)\) 使得 \(\psi(\widehat{\theta})-\) \(\psi(\theta)\) 近似为关键且关于零对称,那么百分位数间隔应该可以很好地工作。
这个论点有以下应用。假设感兴趣的参数是 \(\theta=\exp (\mu)\),其中 \(\mu=\mathbb{E}[Y]\),并假设 \(Y\) 具有关于 \(\mu\) 的关键对称分布。那么,即使 \(\widehat{\theta}=\) \(\exp (\bar{Y})\) 不具有对称分布,应用于 \(\widehat{\theta}\) 的百分位数区间也将具有正确的覆盖范围,因为单调变换 \(\log (\widehat{\theta})\) 具有关键对称分布。
10.17 偏差校正百分位数区间
百分位数间隔的准确性主要取决于采样分布近似对称分布的假设。这排除了有限样本偏差,因为有偏差的估计量不能对称分布。我们想要应用引导方法(而不是渐近方法)的许多情况是当感兴趣的参数是模型参数的非线性函数时,并且非线性通常会引起估计偏差。因此,很难期望百分位数法通常具有准确的覆盖范围。
为了减少偏差问题,Efron (1982) 引入了偏差校正 (BC) 百分位数区间。其理由是启发式的,但有大量证据表明偏差校正方法是百分位数区间的重要改进。该构造基于以下假设:存在一个未知但严格递增的变换 \(\psi(\theta)\) 和未知常数 \(z_{0}\),使得
\[ Z=\psi(\widehat{\theta})-\psi(\theta)+z_{0} \sim \mathrm{N}(0,1) . \]
(假设 \(Z\) 是正态分布并不重要。它可以用任何已知的对称和可逆分布代替。)令 \(\Phi(x)\) 表示正态分布函数,\(\Phi^{-1}(p)\) 表示其分位数函数,\(z_{\alpha}=\Phi^{-1}(\alpha)\) 表示正态临界函数价值观。然后,BC 区间可以根据引导估计器 \(\widehat{\theta}_{b}^{*}\) 和引导分位数 \(q_{\alpha}^{*}\) 构建,如下所示。放
\[ p^{*}=\frac{1}{B} \sum_{b=1}^{B} \mathbb{1}\left\{\widehat{\theta}_{b}^{*} \leq \widehat{\theta}\right\} \]
和
\[ z_{0}=\Phi^{-1}\left(p^{*}\right) . \]
\(p^{*}\) 是中位数偏差的度量,\(z_{0}\) 是将 \(p^{*}\) 转换为正常单位。如果 \(\widehat{\theta}\) 的偏差为零,则 \(p^{*}=0.5\) 和 \(z_{0}=0\)。如果 \(\widehat{\theta}\) 向上偏置,则 \(p^{*}<0.5\) 和 \(z_{0}<0\) 向上偏置。相反,如果 \(p^{*}\) 向下偏置,则 \(p^{*}\) 和 \(p^{*}\) 向下偏置。为任何\(p^{*}\)定义一个调整后的版本
\[ x(\alpha)=\Phi\left(z_{\alpha}+2 z_{0}\right) . \]
如果 \(z_{0}=0\) 则 \(x(\alpha)=\alpha\)。如果 \(z_{0}>0\) 则 \(x(\alpha)>\alpha\),反之则 \(x(\alpha)<0\)。 BC 间隔为
\[ C^{\mathrm{bc}}=\left[q_{x(\alpha / 2)}^{*}, q_{x(1-\alpha / 2)}^{*}\right] . \]
本质上,BC 区间不是从 \(2.5 %\) 到 \(97.5 %\) 分位数,而是使用调整后的分位数,调整程度取决于偏差的程度。
BC 区间的构造并不直观。现在我们证明假设 (10.21) 意味着 BC 区间具有精确的覆盖范围。 (10.21) 意味着
\[ \mathbb{P}\left[\psi(\widehat{\theta})-\psi(\theta)+z_{0} \leq x\right]=\Phi(x) . \]
由于分布至关重要,因此结果会延续至引导分布
\[ \mathbb{P}^{*}\left[\psi\left(\widehat{\theta}^{*}\right)-\psi(\widehat{\theta})+z_{0} \leq x\right]=\Phi(x) . \]
在 \(x=z_{0}\) 处计算 (10.26),我们发现 \(\mathbb{P}^{*}\left[\psi\left(\widehat{\theta}^{*}\right)-\psi(\widehat{\theta}) \leq 0\right]=\Phi\left(z_{0}\right)\) 意味着 \(\mathbb{P}^{*}\left[\widehat{\theta}^{*} \leq \widehat{\theta}\right]=\Phi\left(z_{0}\right)\)。反转,我们得到
\[ z_{0}=\Phi^{-1}\left(\mathbb{P}^{*}\left[\widehat{\theta}^{*} \leq \widehat{\theta}\right]\right) \]
这是 \(B \rightarrow \infty\) 的 (10.23) 的概率极限。因此,未知的 \(z_{0}\) 由 (10.23) 恢复,并且我们可以将 \(z_{0}\) 视为已知的。
从 (10.26) 我们推出
\[ \begin{aligned} x(\alpha) &=\Phi\left(z_{\alpha}+2 z_{0}\right) \\ &\left.=\mathbb{P}^{*}\left[\psi\left(\widehat{\theta}^{*}\right)-\psi(\widehat{\theta}) \leq z_{\alpha}+z_{0}\right)\right] \\ &=\mathbb{P}^{*}\left[\widehat{\theta}^{*} \leq \psi^{-1}\left(\psi(\widehat{\theta})+z_{0}+z_{\alpha}\right)\right] . \end{aligned} \]
此方程表明 \(\psi^{-1}\left(\psi(\widehat{\theta})+z_{0}+z_{\alpha}\right)\) 等于 \(x(\alpha)^{t h}\) 自举分位数。即 \(q_{x(\alpha)}^{*}=\) \(\psi^{-1}\left(\psi(\widehat{\theta})+z_{0}+z_{\alpha}\right)\)。因此我们可以将 (10.25) 写为
\[ C^{\mathrm{bc}}=\left[\psi^{-1}\left(\psi(\widehat{\theta})+z_{0}+z_{\alpha / 2}\right), \psi^{-1}\left(\psi(\widehat{\theta})+z_{0}+z_{1-\alpha / 2}\right)\right] . \]
有覆盖概率
\[ \begin{aligned} \mathbb{P}\left[\theta \in C^{\mathrm{bc}}\right] &=\mathbb{P}\left[\psi^{-1}\left(\psi(\widehat{\theta})+z_{0}+z_{\alpha / 2}\right) \leq \theta \leq \psi^{-1}\left(\psi(\widehat{\theta})+z_{0}+z_{1-\alpha / 2}\right)\right] \\ &=\mathbb{P}\left[\psi(\widehat{\theta})+z_{0}+z_{\alpha / 2} \leq \psi(\theta) \leq \psi(\widehat{\theta})+z_{0}+z_{1-\alpha / 2}\right] \\ &=\mathbb{P}\left[-z_{\alpha / 2} \geq \psi(\widehat{\theta})-\psi(\theta)+z_{0} \geq-z_{1-\alpha / 2}\right] \\ &=\mathbb{P}\left[z_{1-\alpha / 2} \geq Z \geq z_{\alpha / 2}\right] \\ &=\Phi\left(z_{1-\alpha / 2}\right)-\Phi\left(z_{\alpha / 2}\right) \\ &=1-\alpha . \end{aligned} \]
第二个等式应用变换 \(\psi(\theta)\)。第四个等式使用模型 (10.21) 和事实 \(z_{\alpha}=-z_{1-\alpha}\)。这表明 BC 区间 (10.25) 在假设 (10.21) 下具有精确的覆盖范围。
此外,在定理 10.13 的假设下,\(\mathrm{BC}\) 区间具有渐近覆盖概率 \(1-\alpha\),因为偏差校正渐近可以忽略不计。
BC 百分位数区间的一个重要属性是它尊重变换(与百分位数区间一样)。要看到这一点,请观察 \(p^{*}\) 对于变换是不变的,因为它是概率,因此 \(z_{0}^{*}\) 和 \(x(\alpha)\) 是不变的。由于该区间是根据 \(x(\alpha / 2)\) 和 \(x(1-\alpha / 2)\) 分位数构建的,因此分位数等方差属性表明该区间是变换相关的。
表 13.2 报告了四个估计量的 Bootstrap BC 百分位数区间。它们通常与百分位间隔相似,尽管 \(\sigma^{2}\) 和 \(\mu\) 的间隔稍微向右移动。
在 Stata 中,BC 百分位数置信区间可以通过在通过 bootstrap 计算标准误差的估计命令之后使用命令 estat bootstrap 来获得。
10.18 \(\mathrm{BC}_{a}\) 百分位数区间
Efron (1987) 对 BC 区间进行了进一步改进,以考虑抽样分布中的偏度,可以通过指定估计量的方差取决于参数来建模。由此产生的引导加速偏差校正百分位数区间 \(\left(\mathrm{BC}_{a}\right)\) 提高了 BC 区间的性能,但需要更多的计算并且不太直观地理解。
该构造是 BC 区间构造的概括。假设存在一个未知但严格递增的变换 \(\psi(\theta)\) 以及未知常数 \(a\) 和 \(z_{0}\),使得
\[ Z=\frac{\psi(\widehat{\theta})-\psi(\theta)}{1+a \psi(\theta)}+z_{0} \sim \mathrm{N}(0,1) . \]
(和以前一样,\(Z\) 是正态分布的假设可以用任何已知的对称和可逆分布代替。)
常数 \(z_{0}\) 由 (10.23) 估计,就像 BC 区间一样。 \(a\) 有几种可能的估计器。 Efron 的建议是 \(\widehat{\theta}\) 偏度的缩放折刀估计器:
\[ \begin{aligned} &\widehat{a}=\frac{\sum_{i=1}^{n}\left(\bar{\theta}-\widehat{\theta}_{(-i)}\right)^{3}}{6\left(\sum_{i=1}^{n}\left(\bar{\theta}-\widehat{\theta}_{(-i)}\right)^{2}\right)^{3 / 2}} \\ &\bar{\theta}=\frac{1}{n} \sum_{i=1}^{n} \widehat{\theta}_{(-i)} . \end{aligned} \]
\(\widehat{a}\) 的折刀估计器使得 \(\mathrm{BC}_{a}\) 区间的计算成本比其他区间更高。
为任何 \(\alpha\) 定义调整后的版本
\[ x(\alpha)=\Phi\left(z_{0}+\frac{z_{\alpha}+z_{0}}{1-a\left(z_{\alpha}+z_{0}\right)}\right) . \]
\(\mathrm{BC}_{a}\) 百分位数区间是
\[ C^{\mathrm{bca}}=\left[q_{x(\alpha / 2)}^{*}, q_{x(1-\alpha / 2)}^{*}\right] . \]
请注意,当 \(a=0\) 时,\(x(\alpha)\) 简化为 (10.24),\(C^{\text {bca }}\) 简化为 \(C^{\text {bc }}\)。虽然 \(C^{\text {bc }}\) 通过修正中值偏差在 \(C^{\text {pc }}\) 的基础上进行了改进,但 \(C^{\text {bca }}\) 对偏度进行了进一步修正。
\(\mathrm{BC}_{a}\) 区间仅针对 \(\alpha\) 的值进行明确定义,以便 \(a\left(z_{\alpha}+z_{0}\right)<1\)。 (或者等效地,如果 \(\alpha<\Phi\left(a^{-1}-z_{0}\right)\) 对应 \(a>0\),\(\alpha>\Phi\left(a^{-1}-z_{0}\right)\) 对应 \(a<0\)。)
\(\mathrm{BC}_{a}\) 区间与 \(\mathrm{BC}\) 和百分位数区间一样,是尊重变换的。因此,如果 \(\left[q_{x(\alpha / 2)}^{*}, q_{x(1-\alpha / 2)}^{*}\right]\) 是 \(\theta\) 的 \(\mathrm{BC}_{a}\) 区间,则当 \(m(\theta)\) 单调时,\(\left[m\left(q_{x(\alpha / 2)}^{*}\right), m\left(q_{x(1-\alpha / 2)}^{*}\right)\right]\) 是 \(\phi=m(\theta)\) 的 \(\mathrm{BC}_{\alpha}\) 区间。
现在我们给出 \(\mathrm{BC}_{a}\) 区间的理由。最难理解的功能是 \(a\) 的估计器 \(\widehat{a}\)。这涉及到对我们的处理来说太高级的高阶近似,因此我们建议读者参考 Shao 和 Tu (1995) 的章节 \(4.1 .4\),并简单地假设 \(a\) 是已知的。
现在我们证明 \(a\) 已知的假设 (10.28) 意味着 \(C^{\text {bca }}\) 具有精确的覆盖范围。该论证与上一节中给出的论证本质上相同。假设 (10.28) 意味着自举分布满足
\[ \mathbb{P}^{*}\left[\frac{\psi\left(\widehat{\theta}^{*}\right)-\psi(\widehat{\theta})}{1+a \psi(\widehat{\theta})}+z_{0} \leq x\right]=\Phi(x) . \]
对 \(x=z_{0}\) 进行求值并求逆,我们得到 (10.27),这与 BC 区间相同。因此,估计量 (10.23) 与 \(B \rightarrow \infty\) 一致,我们可以将 \(z_{0}\) 视为已知。
从 (10.29) 我们推出
\[ \begin{aligned} x(\alpha) &=\mathbb{P}^{*}\left[\frac{\psi\left(\widehat{\theta}^{*}\right)-\psi(\widehat{\theta})}{1+a \psi(\widehat{\theta})} \leq \frac{z_{\alpha}+z_{0}}{1-a\left(z_{\alpha}+z_{0}\right)}\right] \\ &=\mathbb{P}^{*}\left[\widehat{\theta}^{*} \leq \psi^{-1}\left(\frac{\psi(\widehat{\theta})+z_{\alpha}+z_{0}}{1-a\left(z_{\alpha}+z_{0}\right)}\right)\right] . \end{aligned} \]
这表明 \(\psi^{-1}\left(\frac{\psi(\widehat{\theta})+z_{\alpha}+z_{0}}{1-a\left(z_{\alpha}+z_{0}\right)}\right)\) 等于 \(x(\alpha)^{t h}\) 引导分位数。因此我们可以将 \(C^{\text {bca }}\) 写为
\[ C^{\mathrm{bca}}=\left[\psi^{-1}\left(\frac{\psi(\widehat{\theta})+z_{\alpha / 2}+z_{0}}{1-a\left(z_{\alpha / 2}+z_{0}\right)}\right), \quad \psi^{-1}\left(\frac{\psi(\widehat{\theta})+z_{1-\alpha / 2}+z_{0}}{1-a\left(z_{1-\alpha / 2}+z_{0}\right)}\right)\right] . \]
有覆盖概率
\[ \begin{aligned} \mathbb{P}\left[\theta \in C^{\mathrm{bca}}\right] &=\mathbb{P}\left[\psi^{-1}\left(\frac{\psi(\widehat{\theta})+z_{\alpha / 2}+z_{0}}{1-a\left(z_{\alpha / 2}+z_{0}\right)}\right) \leq \theta \leq \psi^{-1}\left(\frac{\psi(\widehat{\theta})+z_{1-\alpha / 2}+z_{0}}{1-a\left(z_{1-\alpha / 2}+z_{0}\right)}\right)\right] \\ &=\mathbb{P}\left[\frac{\psi(\widehat{\theta})+z_{\alpha / 2}+z_{0}}{1-a\left(z_{\alpha / 2}+z_{0}\right)} \leq \psi(\theta) \leq \frac{\psi(\widehat{\theta})+z_{1-\alpha / 2}+z_{0}}{1-a\left(z_{1-\alpha / 2}+z_{0}\right)}\right] \\ &=\mathbb{P}\left[-z_{\alpha / 2} \geq \frac{\psi(\widehat{\theta})-\psi(\theta)}{1+a \psi(\theta)}+z_{0} \geq-z_{1-\alpha / 2}\right] \\ &=\mathbb{P}\left[z_{1-\alpha / 2} \geq Z \geq z_{\alpha / 2}\right] \\ &=1-\alpha . \end{aligned} \]
第二个等式应用变换 \(\psi(\theta)\)。第四个等式使用模型 (10.28) 和事实 \(z_{\alpha}=-z_{1-\alpha}\)。这表明 \(\mathrm{BC}_{a}\) 区间 \(C^{\text {bca }}\) 在已知 \(a\) 的假设 (10.28) 下具有精确覆盖范围。
表 13.2 报告了四个估计量的 bootstrap \(\mathrm{BC}_{a}\) 百分位数区间。它们通常与 BC 间隔相似,但 \(\sigma^{2}\) 和 \(\mu\) 的间隔稍微向右移动。
在 Stata 中,\(\mathrm{BC}_{a}\) 区间可以通过使用命令 estat bootstrap、bca 或命令 estat bootstrap 获得,所有这些都在使用 bca 选项通过 bootstrap 计算标准误差的估计命令之后。
10.19 百分位数t区间
在许多情况下,我们可以通过引导学生化统计数据(例如 t 比)来提高准确性。设 \(\widehat{\theta}\) 为标量参数 \(\theta\) 的估计器,\(s(\widehat{\theta})\) 为标准误差。样本 t 比为
\[ T=\frac{\widehat{\theta}-\theta}{s(\widehat{\theta})} . \]
自举 t 比为
\[ T^{*}=\frac{\widehat{\theta}^{*}-\widehat{\theta}}{s\left(\widehat{\theta}^{*}\right)} \]
其中 \(s\left(\widehat{\theta}^{*}\right)\) 是在引导样本上计算的标准误差。请注意,引导 t 比以参数估计器 \(\widehat{\theta}\) 为中心。这是因为 \(\widehat{\theta}\) 是 bootstrap 宇宙中的“真实值”。
百分位数-t 区间是使用 \(T^{*}\) 的分布形成的。这可以通过引导算法来计算。在每个引导样本上,计算估计器 \(\widehat{\theta}^{*}\) 及其标准误差 \(s\left(\widehat{\theta}^{*}\right)\),并计算并存储 t 比率 \(T^{*}=\left(\widehat{\theta}^{*}-\widehat{\theta}\right) / s\left(\widehat{\theta}^{*}\right)\)。这会重复 \(B\) 次。 \(\alpha^{t h}\) 分位数 \(q_{\alpha}^{*}\) 由 \(\alpha^{t h}\) 经验分位数(或任何分位数估计器)从 \(T^{*}\) 的 \(B\) 引导程序绘制来估计。
自举百分位数-t 置信区间定义为
\[ C^{\mathrm{pt}}=\left[\widehat{\theta}-s(\widehat{\theta}) q_{1-\alpha / 2}^{*}, \widehat{\theta}-s(\widehat{\theta}) q_{\alpha / 2}^{*}\right] . \]
与百分位间隔相比,该形式可能显得不寻常。左端点由 \(T^{*}\) 分布的上分位数确定,右端点由下分位数确定。如下所示,当分布不对称时,这种结构对于区间具有正确的覆盖范围非常重要。
当估计量渐近正态且标准误差是分布标准差的可靠估计量时,我们期望 t 比率 \(T\) 大致近似于正态分布。在这种情况下,我们期望 \(q_{0.975}^{*} \approx-q_{0.025}^{*} \approx 2\)。当分布变得倾斜或肥尾时,就会偏离该基线。如果自举分位数大幅偏离该基线,则表明大幅偏离正态性。 (它也可能表明存在编程错误,因此在这些情况下,明智的做法是进行三次检查!)
百分位数-t 具有以下优点。首先,当标准错误 \(s(\widehat{\theta})\) 相当可靠时,percentile-t 引导程序会利用标准错误中的信息,从而减少引导程序的作用。相对于其他方法,这可以提高该方法的精度。其次,正如我们稍后所展示的,百分位数-t 区间比百分位数和 BC 百分位数区间实现了更高的精度。第三,百分位数 t 区间对应于使用引导临界值(引导测试在第 10.21 节中介绍)的单侧 t 测试“未拒绝”的一组参数值。
百分位数-t 区间具有以下缺点。首先,当标准误差公式未知时,它们可能不可行。其次,当标准误差计算的计算成本很高时,它们实际上可能是不可行的(因为需要对每个引导样本执行标准误差计算)。第三,如果标准误差 \(s(\widehat{\theta})\) 不可靠,则百分位数 t 可能不可靠,从而增加的噪音多于清晰度。第四,与百分位数、\(\mathrm{BC}\) 百分位数和 \(\mathrm{BC}_{a}\) 百分位数区间不同,百分位数-t 区间不保留翻译。
通常使用传统渐近标准误差构建的 t 比率来计算百分位数 t 区间。但这并不是唯一可能的实施方式。百分位数-t 区间可以用任何依赖于数据的尺度度量来构建。例如,如果 \(\widehat{\theta}\) 是一个两步估计量,不清楚如何构建正确的渐近标准误差,但我们知道如何计算适合第二步的标准误差 \(s(\widehat{\theta})\),则 \(s(\widehat{\theta})\)可用于如上所述的百分位数 t 型区间。它不会具有以下部分的高阶精度属性,但它将满足一阶有效性的条件。
此外,可以使用 bootstrap 标准误差构建百分位数 t 区间。也就是说,统计数据 \(T\) 和 \(T^{*}\) 可以使用引导标准错误 \(s_{\widehat{\theta}}^{\text {boot }}\) 来计算。这在计算上是昂贵的,因为它需要我们所谓的“嵌套引导程序”。具体来说,对于每个引导程序复制,都会抽取一个随机样本,计算引导程序估计 \(\widehat{\theta}^{*}\),然后从引导程序样本中抽取 \(B\) 额外的引导程序子样本,以计算引导程序估计 \(\widehat{\theta}^{*}\) 的引导程序标准误差。实际上,\(B^{2}\) bootstrap 样本被绘制和估计,这将计算要求增加了一个数量级。
我们现在描述百分位-t bootstrap 的一阶有效性的分布理论。
首先,考虑平滑函数模型,其中 \(\widehat{\theta}=g(\widehat{\mu})\) 和 \(s(\widehat{\theta})=\sqrt{\frac{1}{n} \widehat{\boldsymbol{G}}^{\prime} \widehat{\boldsymbol{V}} \widehat{\boldsymbol{G}}}\) 以及引导程序类似物 \(\widehat{\theta}^{*}=g\left(\widehat{\mu}^{*}\right)\) 和 \(s\left(\widehat{\theta}^{*}\right)=\sqrt{\frac{1}{n} \widehat{\boldsymbol{G}}^{* \prime} \widehat{\boldsymbol{V}}^{*} \widehat{\boldsymbol{G}}^{*}}\)。来自定理 \(6.10,10.7\) 和 \(10.8\)
\[ T=\frac{\sqrt{n}(\widehat{\theta}-\theta)}{\sqrt{\widehat{\boldsymbol{G}}^{\prime} \widehat{\boldsymbol{V}} \widehat{\boldsymbol{G}}}} \underset{d}{\longrightarrow} \]
和
\[ T^{*}=\frac{\sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right)}{\sqrt{\widehat{\boldsymbol{G}}^{* \prime} \widehat{\boldsymbol{V}}^{*} \widehat{\boldsymbol{G}}^{*}}} \overrightarrow{d^{*}} Z \]
其中 \(Z \sim \mathrm{N}(0,1)\).这表明样本 t 比和自举 t 比具有相同的渐近分布。
这促使我们考虑更广泛的情况,即样本和自举 t 比率具有相同的渐近分布,但不一定是正态分布。因此假设
\[ \begin{gathered} T \underset{d}{\longrightarrow} \xi \\ T^{*} \underset{d^{*}}{\longrightarrow} \xi \end{gathered} \]
对于一些连续分布 \(\xi\)。 (10.31) 意味着 \(T^{*}\) 的分位数在概率上收敛于 \(\xi\) 的分位数,即 \(q_{\alpha}^{*} \longrightarrow \underset{p}{\longrightarrow} q_{\alpha}\),其中 \(q_{\alpha}\) 是 \(\xi\) 的 \(\alpha^{t h}\) 分位数。这和 (10.30) 意味着
\[ \begin{aligned} \mathbb{P}\left[\theta \in C^{\mathrm{pt}}\right] &=\mathbb{P}\left[\widehat{\theta}-s(\widehat{\theta}) q_{1-\alpha / 2}^{*} \leq \theta \leq \hat{\theta}-s(\widehat{\theta}) q_{\alpha / 2}^{*}\right] \\ &=\mathbb{P}\left[q_{\alpha / 2}^{*} \leq T \leq q_{1-\alpha / 2}^{*}\right] \\ & \rightarrow \mathbb{P}\left[q_{\alpha / 2} \leq \xi \leq q_{1-\alpha / 2}\right] \\ &=1-\alpha . \end{aligned} \]
因此百分位数-t 是渐近有效的。定理 \(10.14\) 如果 (10.30) 和 (10.31) 成立,其中 \(\xi\) 连续分布,则 \(\mathbb{P}\left[\theta \in C^{\mathrm{pt}}\right] \rightarrow 1-\alpha\) 等于 \(n \rightarrow \infty\)
表 13.2 报告了四个估计量的 bootstrap 百分位数 t 区间。它们与百分位型区间相似但有些不同,并且通常更宽。最大的差异出现在 \(\sigma^{2}\) 的区间上,它明显比其他区间宽。
10.20 百分位-t渐近细化
本节使用《经济学家的概率与统计》第 9.8-9.10 章中介绍的埃奇沃斯和康沃尔-费舍尔展开理论。这个理论对于大多数学生来说并不熟悉。如果您对以下精化理论感兴趣,建议您首先阅读《经济学家的概率与统计》的这些部分。
百分位数-t 区间可以视为两个单侧置信区间的交集。在我们对单边渐近置信区间覆盖概率的埃奇沃斯展开的讨论中(在回归系数函数的背景下遵循定理 \(7.15\)),我们发现单边渐近置信区间具有排序 \(O\left(n^{-1 / 2}\right)\) 的准确性。我们现在表明百分位数-t 区间提高了准确性。
《经济学家概率与统计》定理 \(9.13\) 表明,平滑函数模型中 t 比率 \(T\) 的分位数 \(q_{\alpha}\) 的 Cornish-Fisher 展开式采用以下形式
\[ q_{\alpha}=z_{\alpha}+n^{-1 / 2} p_{11}\left(z_{\alpha}\right)+O\left(n^{-1}\right) \]
其中 \(p_{11}(x)\) 是 2 阶偶多项式,其系数取决于高达 8 阶的矩。自举分位数 \(q_{\alpha}^{*}\) 具有类似的 Cornish-Fisher 展开式
\[ q_{\alpha}^{*}=z_{\alpha}+n^{-1 / 2} p_{11}^{*}\left(z_{\alpha}\right)+O_{p}\left(n^{-1}\right) \]
其中 \(p_{11}^{*}(x)\) 与 \(p_{11}(x)\) 相同,只是将总体矩替换为相应的样本矩。样本矩以 \(n^{-1 / 2}\) 的速率估计。因此我们可以用 \(p_{11}\) 替换 \(p_{11}^{*}\) 而不会影响此扩展的顺序:
\[ q_{\alpha}^{*}=z_{\alpha}+n^{-1 / 2} p_{11}\left(z_{\alpha}\right)+O_{p}\left(n^{-1}\right)=q_{\alpha}+O_{p}\left(n^{-1}\right) . \]
这表明学生化 t 比率的引导分位数 \(q_{\alpha}^{*}\) 位于精确分位数 \(q_{\alpha}\) 的 \(O_{p}\left(n^{-1}\right)\) 范围内。
通过埃奇沃斯展开式 Delta 法(《经济学家概率与统计》定理 \(9.12\)),\(T\) 和 \(T+\left(q_{\alpha}-q_{\alpha}^{*}\right)=T+O_{p}\left(n^{-1}\right)\) 具有相同的埃奇沃斯展开式以订购 \(O\left(n^{-1}\right)\)。因此
\[ \begin{aligned} \mathbb{P}\left[T \leq q_{\alpha}^{*}\right] &=\mathbb{P}\left[T+\left(q_{\alpha}-q_{\alpha}^{*}\right) \leq q_{\alpha}\right] \\ &=\mathbb{P}\left[T \leq q_{\alpha}\right]+O\left(n^{-1}\right) \\ &=\alpha+O\left(n^{-1}\right) . \end{aligned} \]
因此百分位数-t 区间的覆盖范围是
\[ \begin{aligned} \mathbb{P}\left[\theta \in C^{\mathrm{pt}}\right] &=\mathbb{P}\left[q_{\alpha / 2}^{*} \leq T \leq q_{1-\alpha / 2}^{*}\right] \\ &=\mathbb{P}\left[q_{\alpha / 2} \leq T \leq q_{1-\alpha / 2}\right]+O\left(n^{-1}\right) \\ &=1-\alpha+O\left(n^{-1}\right) . \end{aligned} \]
相对于单边渐进置信区间,这是一种改进的收敛速度。定理\(10.15\) 在《经济学家概率论与数理统计》定理\(9.11\)的假设下,\(\mathbb{P}\left[\theta \in C^{\mathrm{pt}}\right]=1-\alpha+O\left(n^{-1}\right)\)。
以下置信区间准确性的定义很有用。
定义 10.3 \(\theta\) 的置信集 \(C\) 是 \(k^{t h}\) 阶准确的,如果
\[ \mathbb{P}[\theta \in C]=1-\alpha+O\left(n^{-k / 2}\right) . \]
检查我们的结果,我们发现单边渐近置信区间是一阶准确的,但百分位数 t 区间是二阶准确的。当自举置信区间(或检验)比类似的渐近区间(或检验)实现高阶精度时,我们说自举方法实现了渐近细化。在这里,我们证明了百分位数-t 区间实现了渐近细化。
为了实现这种渐近细化,重要的是 t 比率 \(T\) (及其引导对应部分 \(T^{*}\) )是用渐近有效的标准误差构造的。这是因为埃奇沃斯展开式中的第一项是标准正态分布,这要求 t 比率是渐近正态的。这也具有实际的有限样本含义,即实践中百分位数 t 区间的准确性取决于用于构建 t 比率的标准误差的准确性。
我们不详细介绍,但正态逼近自举区间、百分位自举区间和偏差校正百分位自举区间都是一阶精确的,并且没有实现渐近细化。
然而,\(\mathrm{BC}_{a}\) 区间可以证明渐近等价于百分位数-t 区间,从而实现渐近细化。我们不在这里进行演示,因为它是高级的。参见 Hall (1992) 第 3.10.4 节。
| Peter Hall |
|---|
| Peter Gavin Hall (1951-2016) of Australia was one of the most influential and |
| prolific theoretical statisticians in history. He made wide-ranging contributions. |
| Some of the most relevant for econometrics are theoretical investigations of |
| bootstrap methods and nonparametric kernel methods. |
10.21 自举假设检验
要检验假设 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 与 \(\mathbb{M}_{1}: \theta \neq \theta_{0}\),最常见的方法是 t 检验。对于 t 统计量 \(T=\left(\widehat{\theta}-\theta_{0}\right) / s(\hat{\theta})\) 的大绝对值,我们拒绝 \(\mathbb{H}_{0}\) 而支持 \(\mathbb{H}_{1}\),其中 \(\widehat{\theta}\) 是 \(\theta\) 的估计量,\(s(\widehat{\theta})\) 是 \(\widehat{\theta}\) 的标准误差。对于引导测试,我们使用引导算法来计算临界值。引导算法从数据集中进行替换采样。给定一个引导样本,计算引导估计器 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 和标准误差 \(\mathbb{M}_{0}: \theta=\theta_{0}\)。给定这些值,引导 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 统计量为 \(\mathbb{M}_{0}: \theta=\theta_{0}\)。 bootstrap t 统计量有两个重要特征。首先,\(\mathbb{M}_{0}: \theta=\theta_{0}\) 以样本估计值 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 为中心,而不是假设值 \(\mathbb{M}_{0}: \theta=\theta_{0}\)。这样做是因为 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 是 bootstrap 宇宙中的真实值,并且 t 统计量的分布必须以 bootstrap 抽样框架内的真实值为中心。其次,\(\mathbb{M}_{0}: \theta=\theta_{0}\) 是使用引导标准误差\(\mathbb{M}_{0}: \theta=\theta_{0}\) 计算的。这允许引导程序将随机性纳入标准误差估计中。
未能将引导统计数据正确居中于 \(\widehat{\theta}\) 是应用程序中的常见错误。通常这是因为要检验的假设是 \(\mathbb{H}_{0}: \theta=0\),因此检验统计量是 \(T=\widehat{\theta} / s(\widehat{\theta})\)。这直观地暗示了引导统计量 \(T^{*}=\widehat{\theta}^{*} / s\left(\widehat{\theta}^{*}\right)\),但这是错误的。正确的引导统计量是 \(T^{*}=\) \(\left(\widehat{\theta}^{*}-\widehat{\theta}\right) / s\left(\widehat{\theta}^{*}\right)\)
引导算法创建 \(B\) 绘制 \(T^{*}(b)=\left(\widehat{\theta}^{*}(b)-\widehat{\theta}\right) / s\left(\widehat{\theta}^{*}(b)\right), b=1, \ldots, B\)。自举 \(100 \alpha %\) 临界值为 \(q_{1-\alpha}^{*}\),其中 \(q_{\alpha}^{*}\) 是自举 t 比率 \(\left|T^{*}(b)\right|\) 绝对值的 \(\alpha^{\text {th }}\) 分位数。对于 \(100 \alpha %\) 测试,如果 \(B\),我们拒绝 \(\mathbb{M}_{0}: \theta=\theta_{0}\),而支持 \(B\),如果 \(B\),则无法拒绝 \(B\)。
通常报告 p 值比报告临界值更好。回想一下,p 值为 \(p=1-\) \(G_{n}(|T|)\),其中 \(G_{n}(u)\) 是统计量 \(|T|\) 的零分布。自举 p 值定义为 \(p^{*}=1-G_{n}^{*}(|T|)\),其中 \(G_{n}^{*}(u)\) 是 \(\left|T^{*}\right|\) 的自举分布。这是根据引导算法估计的
\[ p^{*}=\frac{1}{B} \sum_{b=1}^{B} \mathbb{1}\left\{\left|T^{*}(b)\right|>|T|\right\}, \]
大于观察到的 t 统计量的 bootstrap t 统计量的百分比。直观上,我们想知道当零假设为真时,观察到的统计量 \(T\) 有多么“不寻常”。引导算法根据分布 \(T^{*}\) (这是 \(T\) 的未知分布的近似值)生成大量独立绘图。如果 \(\left|T^{*}\right|\) 超过 \(|T|\) 的百分比非常小(例如 \(1 %\) ),这告诉我们 \(|T|\) 是一个异常大的值。但是,如果百分比较大,例如 \(15 %\),那么我们就不能将 \(|T|\) 解释为异常大。
如果需要,引导测试可以作为单方面测试来实现。在这种情况下,统计量是 t 比率的有符号版本,自举临界值是根据替代 \(\mathbb{H}_{1}: \theta>\theta_{0}\) 的分布上尾部和替代 \(\mathbb{H}_{1}: \theta<\theta_{0}\) 的下尾部计算的。单边检验和百分位数 t 置信区间之间存在联系。后者是一组参数值 \(\theta\),不会被任一单边 \(100 \alpha / 2 %\) bootstrap t 检验拒绝。
引导测试也可以与其他统计数据一起进行。当标准误差不可用或不可靠时,我们可以使用非学生化统计量 \(T=\widehat{\theta}-\theta_{0}\)。引导程序版本是 \(T^{*}=\widehat{\theta}^{*}-\widehat{\theta}\)。令 \(q_{\alpha}^{*}\) 为引导统计数据 \(\left|\widehat{\theta}^{*}(b)-\widehat{\theta}\right|\) 的 \(\alpha^{\text {th }}\) 分位数。如果 \(\left|\widehat{\theta}-\theta_{0}\right|>q_{1-\alpha}^{*}\),则引导 \(100 \alpha %\) 测试会拒绝 \(\mathbb{H}_{0}: \theta=\theta_{0}\)。自举 p 值为
\[ p^{*}=\frac{1}{B} \sum_{b=1}^{B} \mathbb{1}\left\{\left|\widehat{\theta}^{*}(b)-\widehat{\theta}\right|>\left|\widehat{\theta}-\theta_{0}\right|\right\} . \]
定理 \(10.16\) 如果 (10.30) 和 (10.31) 成立,其中 \(\xi\) 连续分布,则自举临界值满足 \(q_{1-\alpha}^{*} \underset{p}{\longrightarrow} q_{1-\alpha}\),其中 \(q_{1-\alpha}\) 是 \(|\xi|\) 的 \(1-\alpha^{t h}\) 分位数。引导测试“如果 \(|T|>q_{1-\alpha}^{*}\) 则拒绝 \(\mathbb{M}_{0}\) 而支持 \(\mathbb{M}_{1}\)”的渐近大小 \(10.16\) 为 \(10.16\)。在平滑函数模型中,t 检验(具有正确的标准误差)具有以下性能。
定理 \(10.17\) 在《经济学家概率论与数理统计》定理 \(9.11\) 的假设下,
\[ q_{1-\alpha}^{*}=\bar{z}_{1-\alpha}+o_{p}\left(n^{-1}\right) \]
其中 \(\bar{z}_{\alpha}=\Phi^{-1}((1+\alpha) / 2)\) 是 \(|Z|\) 的 \(\alpha^{t h}\) 分位数。渐近测试“如果 \(|T|>\bar{z}_{1-\alpha}\) 则拒绝 \(\mathbb{M}_{0}\) 而支持 \(\mathbb{M}_{1}\)”具有准确性
\[ \mathbb{P}\left[|T|>\bar{z}_{1-\alpha} \mid \mathbb{H}_{0}\right]=1-\alpha+O\left(n^{-1}\right) \]
并且引导测试“如果 \(|T|>q_{1-\alpha}^{*}\) 则拒绝 \(\mathbb{M}_{0}\) 而支持 \(\mathbb{M}_{1}\)”具有准确性
\[ \mathbb{P}\left[|T|>q_{1-\alpha}^{*} \mid \mathbb{M}_{0}\right]=1-\alpha+o\left(n^{-1}\right) . \]
这表明自举检验相对于渐近检验实现了细化。
推理如下。我们已经证明绝对 t 比的埃奇沃斯展开式采用以下形式
\[ \mathbb{P}[|T| \leq x]=2 \Phi(x)-1+n^{-1} 2 p_{2}(x)+o\left(n^{-1}\right) . \]
这意味着渐近检验的精度为\(O\left(n^{-1}\right)\)。
给定埃奇沃斯展开式,\(|T|\) 分布的 \(\alpha^{t h}\) 分位数 \(q_{\alpha}\) 的 Cornish-Fisher 展开式采用以下形式
\[ q_{\alpha}=\bar{z}_{\alpha}+n^{-1} p_{21}\left(\bar{z}_{\alpha}\right)+o\left(n^{-1}\right) . \]
自举分位数 \(q_{\alpha}^{*}\) 具有 Cornish-Fisher 展开式
\[ \begin{aligned} q_{\alpha}^{*} &=\bar{z}_{\alpha}+n^{-1} p_{21}^{*}\left(\bar{z}_{\alpha}\right)+o\left(n^{-1}\right) \\ &=\bar{z}_{\alpha}+n^{-1} p_{21}\left(\bar{z}_{\alpha}\right)+o_{p}\left(n^{-1}\right) \\ &=q_{\alpha}+o_{p}\left(n^{-1}\right) \end{aligned} \]
其中 \(p_{21}^{*}(x)\) 与 \(p_{21}(x)\) 相同,只是将总体矩替换为相应的样本矩。 bootstrap 检验具有拒绝概率,使用 Edgeworth 展开 Delta 方法(《经济学家概率与统计》的定理 \(11.12\))
\[ \begin{aligned} \mathbb{P}\left[|T|>q_{1-\alpha}^{*} \mid \mathbb{B}_{0}\right] &=\mathbb{P}\left[|T|+\left(q_{1-\alpha}-q_{1-\alpha}^{*}\right)>q_{1-\alpha}\right] \\ &=\mathbb{P}\left[|T|>q_{1-\alpha}\right]+o\left(n^{-1}\right) \\ &=1-\alpha+o\left(n^{-1}\right) \end{aligned} \]
正如所声称的那样。
10.22 Wald 型引导测试
如果 \(\theta\) 是向量,则要在大小 \(\alpha\) 上针对 \(\mathbb{M}_{1}: \theta \neq \theta_{0}\) 测试 \(\mathbb{M}_{0}: \theta=\theta_{0}\),常见测试基于 Wald 统计量 \(W=\left(\widehat{\theta}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{-1}\left(\widehat{\theta}-\theta_{0}\right)\),其中 \(\widehat{\theta}\) 是 \(\theta\) 和 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}\) 的估计量是协方差矩阵估计器。对于引导测试,我们使用引导算法来计算临界值。引导算法从数据集中进行替换采样。给定一个引导样本,计算引导估计器 \(\widehat{\theta}^{*}\) 和协方差矩阵估计器 \(\theta\)。给定这些值,引导 Wald 统计量为
\[ W^{*}=\left(\widehat{\theta}^{*}-\widehat{\theta}\right)^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{*-1}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) . \]
对于 t 检验,引导 Wald 统计量 \(W^{*}\) 必须以样本估计量 \(\widehat{\theta}\) 为中心,而不是假设值 \(\theta_{0}\)。这是因为 \(\widehat{\theta}\) 是 bootstrap 宇宙中的真实值。
基于 \(B\) 引导复制,我们计算引导 Wald 统计数据 \(W^{*}\) 分布的 \(\alpha^{t h}\) 分位数 \(q_{\alpha}^{*}\)。如果 \(W>q_{1-\alpha}^{*}\),引导测试会拒绝 \(\mathbb{M}_{0}\),而支持 \(\mathbb{H}_{1}\)。更常见的是,我们计算 bootstrap p 值。这是
\[ p^{*}=\frac{1}{B} \sum_{b=1}^{B} \mathbb{1}\left\{W^{*}(b)>W\right\} . \]
Wald 检验的渐近性能模仿 t 检验的渐近性能。一般来说,自举 Wald 检验是一阶正确的(渐进地达到正确的大小),并且在存在埃奇沃斯展开的条件下,具有准确性
\[ \mathbb{P}\left[W>q_{1-\alpha}^{*} \mid \mathbb{H}_{0}\right]=1-\alpha+o\left(n^{-1}\right) \]
从而实现了相对于渐近 Wald 检验的改进。
如果可靠的协方差矩阵估计器 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}\) 不可用,则可以使用任何正定权重矩阵而不是 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}\) 来实现 Wald 型检验。这包括简单的选择,例如单位矩阵。引导算法可用于计算测试的临界值和 \(\mathrm{p}\) 值。只要估计量 \(\hat{\theta}\) 具有渐近分布,此引导测试将是渐近一阶有效的。该检验不会实现渐近细化,但提供了一种简单的方法来在协方差矩阵估计不可用时检验假设。
10.23 基于标准的引导测试
基于标准的估计量采用以下形式
\[ \widehat{\beta}=\underset{\beta}{\operatorname{argmin}} J(\beta) \]
对于某些标准函数 \(J(\beta)\)。这包括最小二乘法、最大似然法和最小距离。给定假设 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 其中 \(\theta=r(\beta)\),满足 \(\mathbb{H}_{0}\) 的限制估计量为
\[ \widetilde{\beta}=\underset{r(\beta)=\theta_{0}}{\operatorname{argmin}} J(\beta) . \]
用于测试 \(\mathbb{H}_{0}\) 的基于标准的统计数据是
\[ J=\min _{r(\beta)=\theta_{0}} J(\beta)-\min _{\beta} J(\beta)=J(\widetilde{\beta})-J(\widehat{\beta}) . \]
基于标准的测试会因 \(J\) 的较大值而拒绝 \(\mathbb{H}_{0}\)。引导测试使用引导算法来计算临界值。
在这种情况下,我们需要仔细考虑如何构建 \(J\) 的引导版本。在引导样本上构建与原始样本完全相同的统计量似乎很自然,但这是不正确的。它会产生与计算以假设值为中心的 t 比或 Wald 统计量相同的错误。在 bootstrap 宇宙中,\(\theta\) 的真实值不是 \(\theta_{0}\),而是 \(\widehat{\theta}=r(\widehat{\beta})\)。因此,当使用非参数引导程序时,我们希望施加约束 \(r(\beta)=r(\widehat{\beta})=\widehat{\theta}\) 以获得 \(J\) 的引导程序版本。
因此,计算 \(J\) 的 bootstrap 版本的正确方法如下。通过从数据集中随机采样生成引导样本。令 \(J^{*}(\beta)\) 为标准的引导版本。在引导样本上计算无限制估计器 \(\widehat{\beta}^{*}=\underset{\beta}{\operatorname{argmin}} J^{*}(\beta)\) 和受限制版本 \(\widetilde{\beta}^{*}=\) \(\operatorname{argmin} J^{*}(\beta)\),其中 \(\widehat{\theta}=r(\widehat{\beta})\)。自举统计量为 \(r(\beta)=\hat{\theta}\)
\[ J^{*}=\min _{r(\beta)=\widehat{\theta}} J^{*}(\beta)-\min _{\beta} J^{*}(\beta)=J^{*}\left(\widetilde{\beta}^{*}\right)-J^{*}\left(\widehat{\beta}^{*}\right) . \]
在每个引导样本上计算 \(J^{*}\)。取 \(1-\alpha^{\text {th }}\) 分位数 \(q_{1-\alpha}^{*}\)。如果 \(J>q_{1-\alpha}^{*}\),引导测试会拒绝 \(\mathbb{H}_{0}\),而支持 \(\mathbb{H}_{1}\)。自举 p 值为
\[ p^{*}=\frac{1}{B} \sum_{b=1}^{B} \mathbb{1}\left\{J^{*}(b)>J\right\} . \]
基于标准的测试的特殊情况是最小距离测试、\(F\) 测试和似然比测试。对线性假设 \(\boldsymbol{R}^{\prime} \beta=\theta_{0}\) 进行 F 检验。 \(F\) 统计量是
\[ \mathrm{F}=\frac{\left(\widetilde{\sigma}^{2}-\widehat{\sigma}^{2}\right) / q}{\widehat{\sigma}^{2} /(n-k)} \]
其中 \(\widehat{\sigma}^{2}\) 是误差方差的无限制估计量,\(\widetilde{\sigma}^{2}\) 是受限制估计量,\(q\) 是限制数量,\(k\) 是估计系数数量。 \(F\) 统计量的引导版本是
\[ \mathrm{F}^{*}=\frac{\left(\widetilde{\sigma}^{* 2}-\widehat{\sigma}^{* 2}\right) / q}{\widehat{\sigma}^{* 2} /(n-k)} \]
其中 \(\widehat{\sigma}^{* 2}\) 是引导样本上的无限制估计器,\(\widetilde{\sigma}^{* 2}\) 是施加限制 \(\widehat{\theta}=\boldsymbol{R}^{\prime} \widehat{\beta}\) 的受限制估计器。
对假设 \(r(\beta)=\theta_{0}\) 进行似然比 (LR) 检验。 LR检验统计量为
\[ \mathrm{LR}=2\left(\ell_{n}(\widehat{\beta})-\ell_{n}(\widetilde{\beta})\right) \]
其中 \(\widehat{\beta}\) 是无限制的 MLE,\(\widetilde{\beta}\) 是受限制的 MLE(强制 \(r(\beta)=\theta_{0}\) )。引导版本是
\[ \operatorname{LR}^{*}=2\left(\ell_{n}^{*}\left(\widehat{\beta}^{*}\right)-\ell_{n}^{*}\left(\widetilde{\beta}^{*}\right)\right) \]
其中 \(\ell_{n}^{*}(\beta)\) 是在引导样本上计算的对数似然函数,\(\widehat{\beta}^{*}\) 是无限制最大化器,\(\widetilde{\beta}^{*}\) 是施加限制 \(r(\beta)=r(\widehat{\beta})\) 的受限最大化器。
10.24 参数引导程序
在本章中,我们描述了最流行的引导程序形式,称为非参数引导程序。然而,还有其他形式的引导算法,包括参数引导。当存在完整的分布参数模型(如似然估计)时,这是合适的。
首先,考虑模型指定随机向量 \(Y\) 的完整分布的上下文,例如\(Y \sim F(y \mid \beta)\),其中分布函数 \(F\) 已知,但参数 \(\beta\) 未知。令 \(\widehat{\beta}\) 为 \(\beta\) 的估计器,例如最大似然估计器。参数引导算法通过从分布函数 \(F(y \mid \widehat{\beta})\) 中抽取随机向量来生成引导观测值 \(Y_{i}^{*}\)。完成此操作后,引导程序宇宙中 \(\beta\) 的真实值为 \(Y\)。本章中讨论的所有内容都可以使用此引导算法来应用。
其次,考虑模型在给定随机向量 \(X\) 的情况下指定随机向量 \(Y\) 的条件分布的上下文,例如\(Y \mid X \sim F(y \mid X, \beta)\)。一个例子是正态线性回归模型,其中 \(Y \mid X \sim \mathrm{N}\left(X^{\prime} \beta, \sigma^{2}\right)\).在这种情况下,我们可以保持回归量 \(X_{i}\) 固定,然后从条件分布 \(F\left(y \mid X_{i}, \widehat{\beta}\right)\) 中绘制引导观测值 \(Y_{i}^{*}\)。在正态回归模型的示例中,这相当于绘制正态误差 \(e_{i}^{*} \sim \mathrm{N}\left(0, \widehat{\sigma}^{2}\right)\),然后设置 \(Y_{i}^{*}=X_{i}^{\prime} \widehat{\beta}+\) \(Y\)。同样,在此算法中,\(Y\) 的真实值为 \(Y\),本章中讨论的所有内容都可以像以前一样应用。
第三,考虑假设 \(r(\beta)=\theta_{0}\) 的检验。在这种情况下,我们还可以构造一个满足假设 \(r(\widetilde{\beta})=\theta_{0}\) 的受限估计器 \(\widetilde{\beta}\) (例如受限 MLE)。然后我们可以通过从分布 \(Y_{i}^{*} \sim F(y \mid \widetilde{\beta})\) 进行模拟来生成引导样本,或者在条件上下文中从 \(Y_{i}^{*} \sim F\left(y \mid X_{i}, \widetilde{\beta}\right)\) 进行模拟。完成此操作后,引导程序中 \(\beta\) 的真实值为 \(\widetilde{\beta}\) ,它满足假设。因此,在这种情况下,引导统计数据的正确值是
\[ \begin{gathered} T^{*}=\frac{\widehat{\theta}^{*}-\theta_{0}}{s\left(\widehat{\theta}^{*}\right)} \\ W^{*}=\left(\widehat{\theta}^{*}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{*-1}\left(\widehat{\theta}^{*}-\theta_{0}\right) \\ J^{*}=\min _{r(\beta)=\theta_{0}} J^{*}(\beta)-\min _{\beta} J^{*}(\beta) \\ \mathrm{LR}^{*}=2\left(\max _{\beta} \ell_{n}^{*}(\beta)-\max _{r(\beta)=\theta_{0}} \ell_{n}^{*}(\beta)\right) \end{gathered} \]
和
\[ \mathrm{F}^{*}=\frac{\left(\widetilde{\sigma}^{* 2}-\widehat{\sigma}^{* 2}\right) / q}{\widehat{\sigma}^{* 2} /(n-k)} \]
其中 \(\widehat{\sigma}^{* 2}\) 是引导样本上的无限制估计器,\(\widetilde{\sigma}^{* 2}\) 是施加限制 \(\boldsymbol{R}^{\prime} \beta=\theta_{0}\) 的受限制估计器。
参数引导程序(相对于非参数引导程序)的主要优点是,当参数模型正确时,它会更准确。这对于小样本来说可能相当重要。参数引导程序的主要缺点是当参数模型不正确时它可能不准确。
10.25 有多少引导复制?
应使用多少个引导复制?没有普遍正确的答案,因为准确性和计算成本之间需要权衡。计算成本在 \(B\) 中基本上是线性的。准确性(标准误差或 \(p\) 值)与 \(B^{-1 / 2}\) 成正比。可以获得更高的准确性,但需要更高的计算成本。
在大多数实证研究中,大多数计算都是快速且调查性的,不需要完全准确。但最终结果(进入论文最终版本的结果)应该是准确的。因此,使用渐近和/或引导方法以及适度的复制次数进行日常计算似乎是合理的,但对于最终版本使用更大的 \(B\) 。
特别是,对于最终计算,需要 \(B=10,000\),而 \(B=1000\) 是最低选择。相反,对于日常快速计算,低至 \(B=100\) 的值可能足以进行粗略估计。考虑 bootstrap 方法准确性的一个有用方法源于 pvalue 的计算。引导 p 值 \(p^{*}\) 是伯努利绘制的 \(B\) 的平均值。 \(p^{*}\) 的模拟估计量的方差为 \(p^{*}\left(1-p^{*}\right) / B\),其上方以 \(1 / 4 B\) 为界。要以 \(B=10,000\) 概率计算真实值(例如 \(B=10,000\) 内的 \(\mathrm{p}\) 值)需要低于 \(B=10,000\) 的标准误差。如果 \(B=10,000\) 就可以确保这一点。
Stata 默认设置 \(B=50\)。这对于验证程序运行很有用,但对于实证报告来说却是一个糟糕的选择。确保将 \(B\) 设置为您想要的值。
10.26 设置引导种子
计算机不会生成真正的随机数,而是由确定性算法生成的伪随机数。该算法生成的序列与随机序列无法区分,因此引导应用程序不必担心这一点。
然而,这些方法必然需要称为“种子”的起始值。一些软件包(包括 Stata 和 MATLAB)使用默认种子来实现此功能,每次启动统计软件包时都会重置默认种子。这意味着如果您重新启动软件包,运行引导程序(例如 Stata 中的“do”文件),退出软件包,重新启动软件包,然后重新运行引导程序,您应该获得完全相同的结果。如果您连续运行引导程序(例如“do”文件)两次而不重新启动程序包,则种子不会重置,因此将生成一组不同的伪随机数,并且两次运行的结果将不同。
R 包有不同的实现。当加载 \(\mathrm{R}\) 时,会根据计算机的时钟生成随机数种子(这会产生本质上随机的起始种子)。因此,如果您在 R 中运行引导程序,退出,重新启动,然后重新运行,您将获得一组不同的随机抽取,从而获得不同的引导结果。
包允许用户设置自己的种子。 (在 Stata 中,命令为 set Seed #。在 MATLAB 中,命令为 \(r n g(\#)\)。在 \(R\) 中,命令为 set.seed (#)。)如果种子在开始处设置为特定数字一个文件,那么每次运行程序时都会生成完全相同的伪随机数。如果是这种情况,引导计算的结果(标准错误或测试)在计算机运行中将是相同的。
事实上,可以通过在复制文件中设置种子来修复引导结果,这一事实促使许多研究人员遵循这一选择。他们将种子设置在复制文件的开头,以便重复执行会产生相同的数值结果。
然而,固定种子应谨慎进行。对于最终计算(当论文完成时)来说,这可能是一个明智的选择,但对于日常计算来说,这是一个不明智的选择。如果您在初步工作中使用少量复制,例如 \(B=100\),则引导计算将不准确。但是,当您一次又一次地运行结果时(这在实证项目中很常见),您将获得相同的数值标准误差和测试结果,从而给您带来稳定性和准确性的错误感觉。相反,如果每次运行程序时使用不同的种子,则引导程序结果将在每次运行中有所不同,并且您将观察到结果在这些运行中有所不同,从而为您提供有关结果(缺乏)准确性的重要且有意义的信息。确保这一点的一种方法是根据当前时钟设置种子。在 MATLAB 中使用命令 rng(‘shuffle’)。在 R 中使用集合。种子(种子=NULL)。 Stata没有这个选项。
这些考虑因素导致了推荐的混合方法。对于日常实证研究,不要修复程序中的引导种子,除非您已按时钟设置了它。对于最终计算,将种子设置为特定的任意选择,并设置 \(B=10,000\) 以使结果对种子不敏感。
10.27 引导回归
本教科书的主要焦点是投影模型中的最小二乘估计器 \(\widehat{\beta}\)。自举程序可用于计算系数估计的平滑函数的标准误差和置信区间。
如前所述,非参数引导算法从数据集中随机替换观测值,创建引导样本 \(\left\{\left(Y_{1}^{*}, X_{1}^{*}\right), \ldots,\left(Y_{n}^{*}, X_{n}^{*}\right)\right\}\),或以矩阵表示法 \(\left(\boldsymbol{Y}^{*}, \boldsymbol{X}^{*}\right)\) 重要的是要认识到整个观测值(成对的 \(Y_{i}\) 和 \(X_{i}\) ) 进行采样。这通常称为配对引导程序。
给定这个引导样本,我们计算回归估计量
\[ \widehat{\beta}^{*}=\left(\boldsymbol{X}^{* \prime} \boldsymbol{X}^{*}\right)^{-1}\left(\boldsymbol{X}^{* \prime} \boldsymbol{Y}^{*}\right) . \]
这会重复 \(B\) 次。引导标准误差是各次抽签的标准偏差,置信区间是根据各次抽签的经验分位数构建的。
\(\widehat{\beta}^{*}\) 的引导分布的本质是什么?从引导观测值 \(\left(Y_{i}^{*}, X_{i}^{*}\right)\) 的分布开始很有用,它是离散分布,它将质量 \(1 / n\) 放在每个观测对 \(\left(Y_{i}, X_{i}\right)\) 上。自举宇宙可以被认为是观测结果的经验散点图。该 bootstrap 宇宙中投影系数的真实值为
\[ \left(\mathbb{E}^{*}\left[X_{i}^{*} X_{i}^{* \prime}\right]\right)^{-1}\left(\mathbb{E}^{*}\left[X_{i}^{*} Y_{i}^{*}\right]\right)=\left(\frac{1}{n} \sum_{i=1}^{n} X_{i} X_{i}^{\prime}\right)^{-1}\left(\frac{1}{n} \sum_{i=1}^{n} X_{i} Y_{i}\right)=\widehat{\beta} \]
我们看到引导分布中的真实值是最小二乘估计量 \(\widehat{\beta}\)。
自举观测值满足投影方程
\[ \begin{aligned} Y_{i}^{*} &=X_{i}^{* \prime} \widehat{\beta}+e_{i}^{*} \\ \mathbb{E}^{*}\left[X_{i}^{*} e_{i}^{*}\right] &=0 . \end{aligned} \]
对于每个引导对 \(\left(Y_{i}^{*}, X_{i}^{*}\right)=\left(Y_{j}, X_{j}\right)\),真实误差 \(e_{i}^{*}=\widehat{e}_{j}\) 等于原始数据集的最小二乘残差。这是因为每个引导对都对应于一个实际观察。
一个技术问题(通常被忽略)是,\(\boldsymbol{X}^{* \prime} \boldsymbol{X}^{*}\) 在模拟引导样本中可能是奇异的,在这种情况下,最小二乘估计器 \(\widehat{\beta}^{*}\) 不是唯一定义的。事实上,\(\boldsymbol{X}^{* \prime} \boldsymbol{X}^{*}\) 是奇异的概率是正的。例如,引导样本完全由重复 \(n\) 次的一个观察值组成的概率为 \(n^{-(n-1)}\)。这是一个很小的概率,但是是积极的。一个更重要的例子是稀疏虚拟变量设计,其中可以仅使用虚拟变量的一个观察值来绘制整个样本。例如,如果样本具有 \(n=20\) 观测值,且虚拟变量仅对 20 个观测值中的 3 个进行了处理(等于 1),则引导样本包含完全未处理的值(全部为 0)的概率为 \(4 %\)。 \(4 %\) 相当高!
规避此问题的标准方法是仅当 \(\boldsymbol{X}^{* \prime} \boldsymbol{X}^{*}\) 是由传统数值公差定义的非奇异值时才计算 \(\widehat{\beta}^{*}\),否则将其视为缺失。更好的解决方案是定义一个容差,使 \(\boldsymbol{X}^{* \prime} \boldsymbol{X}^{*}\) 远离非奇异性。定义引导设计矩阵的最小特征值与数据设计矩阵的最小特征值之比
\[ \lambda^{*}=\frac{\lambda_{\min }\left(\boldsymbol{X}^{* \prime} \boldsymbol{X}^{*}\right)}{\lambda_{\min }\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)} . \]
如果在给定的引导复制中, \(\lambda^{*}<\tau\) 小于给定的容差(Shao 和 Tu \((1995, \mathrm{p} .291)\) 推荐 \(\tau=1 / 2\) ),那么估计器可以被视为缺失,或者我们可以定义修剪规则
\[ \widehat{\beta}^{*}=\left\{\begin{array}{cc} \widehat{\beta}^{*} & \text { if } \lambda^{*} \geq \tau \\ \widehat{\beta} & \text { if } \lambda^{*}<\tau \end{array}\right. \]
这确保了引导估计器 \(\widehat{\beta}^{*}\) 表现良好。
10.28 自举回归渐近理论
定义最小二乘估计器 \(\widehat{\beta}\),其引导版本 \(\widehat{\beta}^{*}\) 如 (10.32) 中所示,以及用于平滑变换 \(r\) 的变换 \(\widehat{\theta}=g(\widehat{\beta})\) 和 \(\widehat{\theta}^{*}=r\left(\widehat{\beta}^{*}\right)\)。令 \(\widehat{\boldsymbol{V}}_{\beta}\) 和 \(\widehat{\boldsymbol{V}}_{\theta}\) 表示 \(\widehat{\beta}\) 和 \(\widehat{\theta}\) 的异方差鲁棒协方差矩阵估计器,并让 \(\widehat{\beta}\) 和 \(\widehat{\beta}\) 为其引导版本。当 \(\widehat{\beta}\) 为标量时,定义标准错误 \(\widehat{\beta}\) 和 \(\widehat{\beta}\)。定义 t 比率 \(\widehat{\beta}\) \(\widehat{\beta}\) 和引导程序版本 \(\widehat{\beta}\)。我们对 \(\widehat{\beta}\) 和 \(\widehat{\beta}\) 的渐近分布感兴趣
由于自举观测值满足模型 (10.33),我们通过标准计算看到:
\[ \sqrt{n}\left(\widehat{\beta}^{*}-\widehat{\beta}\right)=\left(\frac{1}{n} \sum_{i=1}^{n} X_{i}^{*} X_{i}^{* \prime}\right)^{-1}\left(\frac{1}{\sqrt{n}} \sum_{i=1}^{n} X_{i}^{*} e_{i}^{*}\right) \]
通过引导 WLLN
\[ \frac{1}{n} \sum_{i=1}^{n} X_{i}^{*} X_{i}^{* \prime} \underset{p^{*}}{\longrightarrow} \mathbb{E}\left[X_{i} X_{i}^{\prime}\right]=\boldsymbol{Q} \]
并通过引导 CLT
\[ \frac{1}{\sqrt{n}} \sum_{i=1}^{n} X_{i}^{*} e_{i}^{*} \underset{d^{*}}{\longrightarrow} \mathrm{N}(0, \Omega) \]
其中 \(\Omega=\mathbb{E}\left[X X^{\prime} e^{2}\right]\).再次应用引导程序 WLLN,我们得到
\[ \widehat{\boldsymbol{V}}_{\beta} \underset{p^{*}}{ } \boldsymbol{V}_{\beta}=\boldsymbol{Q}^{-1} \Omega \boldsymbol{Q}^{-1} \]
和
\[ \widehat{\boldsymbol{V}}_{\theta} \underset{p^{*}}{\longrightarrow} \boldsymbol{V}_{\theta}=\boldsymbol{R}^{\prime} \boldsymbol{V}_{\beta} \boldsymbol{R} \]
其中 \(\boldsymbol{R}=\boldsymbol{R}(\beta)\).
结合bootstrap CMT和delta方法我们建立了bootstrap回归估计量的渐近分布。
假设 7.2 下的定理 \(10.18\),如 \(n \rightarrow \infty\)
\[ \sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) \underset{d^{*}}{\longrightarrow} \mathrm{N}\left(0, \boldsymbol{V}_{\beta}\right) . \]
如果假设 \(7.3\) 也成立,那么
\[ \sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) \underset{d^{*}}{\longrightarrow} \mathrm{N}\left(0, \boldsymbol{V}_{\theta}\right) . \]
如果假设 \(7.4\) 也成立,那么
\[ T^{*} \underset{d^{*}}{\longrightarrow} \mathrm{N}(0,1) . \]
这意味着引导置信区间和测试方法都适用于 \(\beta\) 和 \(\theta\) 的推理。这包括百分位数、\(\mathrm{BC}\) 百分位数、\(\mathrm{BC}_{a}\) 和百分位数 t 区间,以及基于 t 检验、Wald 检验、MD 检验、LR 检验和 F 检验的假设检验。
为了证明引导标准误差的合理性,我们还需要验证 \(\widehat{\beta}^{*}\) 和 \(\widehat{\theta}^{*}\) 的均匀平方可积性。这在技术上具有挑战性,因为最小二乘估计器涉及不是全局连续的矩阵求逆。部分解决方案是使用修剪估计器 (10.34)。这将 \(\widehat{\beta}^{*}\) 的矩限制为 \(n^{-1} \sum_{i=1}^{n} X_{i}^{*} e_{i}^{*}\) 的矩。由于这是样本均值,因此定理 \(10.10\) 适用,并且 \(\widehat{\boldsymbol{V}}_{\beta}^{*}\) 对于 \(\boldsymbol{V}_{\beta}\) 是自举一致的。然而,这并不能确保 \(\widehat{\boldsymbol{V}}_{\theta}^{*}\) 对于 \(\widehat{\boldsymbol{V}}_{\theta}\) 是一致的,除非函数 \(\widehat{\beta}^{*}\) 满足定理 10.10 的条件。对于一般应用,请使用自举方差的修剪估计器。对于某些 \(\widehat{\beta}^{*}\) 定义
\[ \begin{aligned} Z_{n}^{*} &=\sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right) \\ Z^{* *} &=z^{*} \mathbb{1}\left\{\left\|Z_{n}^{*}\right\| \leq \tau_{n}\right\} \\ Z^{* *} &=\frac{1}{B} \sum_{b=1}^{B} Z^{* *}(b) \\ \widehat{\mathbf{V}}_{\theta}^{\text {boot }, \tau} &=\frac{1}{B-1} \sum_{b=1}^{B}\left(Z^{* *}(b)-Z^{* *}\right)\left(Z^{* *}(b)-Z^{* *}\right)^{\prime} . \end{aligned} \]
矩阵 \(\widehat{\boldsymbol{V}}_{\theta}^{\text {boot }}\) 是 \(Z_{n}=\sqrt{n}(\widehat{\theta}-\theta)\) 方差的修剪引导估计器。 \(\widehat{\theta}\) 的相关引导标准错误(在标量情况下)是 \(s(\widehat{\theta})=\sqrt{n^{-1} \widehat{\boldsymbol{V}}_{\theta}^{\text {boot }}}\)。
通过应用定理 \(10.11\) 和 10.12,我们发现这个估计量 \(\widehat{\boldsymbol{V}}_{\theta}^{\text {boot }}\) 对于渐近方差是一致的。
定理 10.19 假设 \(7.2\) 和 \(7.3\),如 \(n \rightarrow \infty, \widehat{\boldsymbol{V}}_{\theta}^{\mathrm{boot}, \tau} \underset{p^{*}}{\longrightarrow} \boldsymbol{V}_{\theta}\)
Stata 等程序使用未修剪的估计器 \(\widehat{\boldsymbol{V}}_{\theta}^{\text {boot }}\) 而不是修剪后的估计器 \(\widehat{\boldsymbol{V}}_{\theta}^{\text {boot }, \tau}\)。这意味着我们应该谨慎解释报告的引导标准误差,尤其是对于比率等非线性函数。
10.29 狂野引导
采取线性回归模型
\[ \begin{aligned} Y &=X^{\prime} \beta+e \\ \mathbb{E}[e \mid X] &=0 . \end{aligned} \]
该模型的特殊之处在于条件均值限制。非参数引导程序(从原始观测值中对 \(\left(Y_{i}^{*}, X_{i}^{*}\right)\) i.i.d. 进行采样)不利用此限制。因此,\(\left(Y^{*}, X^{*}\right)\) 的引导分布不满足条件均值限制,因此不满足线性回归假设。为了提高精度,对引导分布施加条件均值限制似乎是合理的。
一种自然的方法是保持回归量 \(X_{i}\) 固定,然后以某种方式绘制误差 \(e_{i}^{*}\),从而将条件平均值强加为零。最简单的方法是绘制与回归量无关的误差,也许与残差的经验分布无关。此过程称为剩余引导程序。然而,这使得误差与回归量的独立性比条件均值假设强得多。这通常是不希望的。
一种施加条件均值限制同时允许一般异方差的方法是野引导法。它由Liu(1988)提出并由Mammon(1993)扩展。该方法使用辅助随机变量 \(\xi^{*}\) ,它们是 i.i.d.、均值 0 和方差 1 。然后将引导观测值生成为 \(Y_{i}^{*}=X_{i}^{\prime} \widehat{\beta}+e_{i}^{*}\) 和 \(e_{i}^{*}=\widehat{e}_{i} \xi_{i}^{*}\),其中回归器 \(X_{i}\) 固定在其样本值,\(\widehat{\beta}\) 是样本最小二乘估计器,\(\widehat{e}_{i}\) 是最小二乘残差,其中也固定在它们的样本值。
该算法生成引导错误 \(e_{i}^{*}\),其条件均值为零。因此,引导对 \(\left(Y_{i}^{*}, X_{i}\right)\) 满足与 \(\widehat{\beta}\) 的“真实”系数的线性回归。野生引导错误 \(e_{i}^{*}\) 的条件方差是 \(\mathbb{E}^{*}\left[e_{i}^{* 2} \mid X_{i}\right]=\widehat{e}_{i}^{2}\)。这意味着自举估计器 \(\widehat{\beta}^{*}\) 的条件方差为
\[ \mathbb{E}^{*}\left[\left(\widehat{\beta}^{*}-\widehat{\beta}\right)\left(\widehat{\beta}^{*}-\widehat{\beta}\right)^{\prime} \mid \boldsymbol{X}\right]=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \widehat{e}_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \]
这是 \(\widehat{\beta}\) 方差的怀特估计量。因此,狂野引导复制了分布的适当的一阶矩和二阶矩。
辅助变量 \(\xi_{i}^{*}\) 被提出了两种分布,它们都是两点离散分布。第一个是满足 \(\mathbb{P}\left[\xi^{*}=1\right]=\frac{1}{2}\) 和 \(\mathbb{P}\left[\xi^{*}=-1\right]=\) \(\frac{1}{2}\) 的 Rademacher 随机变量。第二个是 Mammen (1993) 两点分布
\[ \begin{aligned} &\mathbb{P}\left[\xi^{*}=\frac{1+\sqrt{5}}{2}\right]=\frac{\sqrt{5}-1}{2 \sqrt{5}} \\ &\mathbb{P}\left[\xi^{*}=\frac{1-\sqrt{5}}{2}\right]=\frac{\sqrt{5}+1}{2 \sqrt{5}} \end{aligned} \]
Mammen 分布背后的推理是,此选择意味着 \(\mathbb{E}\left[\xi^{* 3}\right]=1\),这意味着 \(\widehat{\beta}^{*}\) 的第三中心矩与 \(\widehat{\beta}\) 的第三中心矩的自然非参数估计量相匹配。由于狂野引导与前三个矩匹配,因此可以证明百分位数 t 区间和单侧 t 检验可以实现渐近细化。
Rademacher 分布背后的推理是,此选择意味着 \(\mathbb{E}\left[\xi^{* 4}\right]=1\),这意味着 \(\widehat{\beta}^{*}\) 的第四中心矩与 \(\widehat{\beta}\) 的第四中心矩的自然非参数估计量相匹配。如果回归误差 \(e\) 对称分布(因此第三个矩为零),则前四个矩匹配。在这种情况下,狂野引导应该具有更好的性能,并且另外可以显示两侧 t 检验以实现渐近细化。当回归误差不对称分布时,无法实现这些渐近细化。 Davidson 和 Flachaire (2008) 中提出的单边 t 检验的有限模拟证据表明,Rademacher 分布(与受限野生引导程序一起使用)具有更好的性能,并且是他们的推荐。
对于假设检验,可以通过限制野生引导来获得更高的精度。考虑假设 \(\mathbb{H}_{0}: r(\beta)=0\) 的检验。令 \(\widetilde{\beta}\) 为 \(\beta\) 的 CLS 或 EMD 估计量,并受到 \(r(\widetilde{\beta})=0\) 的限制。令 \(\widetilde{e}_{i}=Y_{i}-X_{i}^{\prime} \widetilde{\beta}\) 为约束残差。受限野生引导算法将观测值生成为 \(Y_{i}^{*}=X_{i}^{\prime} \widetilde{\beta}+e_{i}^{*}\) 和 \(e_{i}^{*}=\widetilde{e}_{i} \xi_{i}^{*}\)。经过此修改,\(\widetilde{\beta}\) 是引导宇宙中的真实值,因此原假设 \(\mathbb{M}_{0}\) 成立。因此,引导程序测试的构造与使用受限参数估计器的参数引导程序相同。
10.30 集群观察的引导程序
尽管方法论文献相对较少,但 Bootstrap 方法也可以应用于聚类样本。在这里,我们回顾一下 Cameron、Gelbach 和 Miller (2008) 中讨论的方法。
令 \(\boldsymbol{Y}_{g}=\left(Y_{1 g}, \ldots, Y_{n_{g} g}\right)^{\prime}\) 和 \(\boldsymbol{X}_{g}=\left(X_{1 g}, \ldots, X_{n_{g} g}\right)^{\prime}\) 表示 \(g^{t h}\) 簇的因变量 \(n_{g} \times 1\) 向量和回归量 \(n_{g} \times k\) 矩阵。使用聚类符号的线性回归模型为 \(\boldsymbol{Y}_{g}=\) \(\boldsymbol{X}_{g} \beta+\boldsymbol{e}_{g}\),其中 \(\boldsymbol{e}_{g}=\left(e_{1 g}, \ldots, e_{n_{g} g}\right)^{\prime}\) 是 \(n_{g} \times 1\) 误差向量。该样本具有 \(\boldsymbol{Y}_{g}=\left(Y_{1 g}, \ldots, Y_{n_{g} g}\right)^{\prime}\) 聚类对 \(\boldsymbol{Y}_{g}=\left(Y_{1 g}, \ldots, Y_{n_{g} g}\right)^{\prime}\)。
集群引导样本对 \(G\) 集群对 \(\left(\boldsymbol{Y}_{g}, \boldsymbol{X}_{g}\right)\) 来创建引导样本。将最小二乘法应用于引导样本以获得系数估计量。通过重复 \(B\) 次,可以计算系数估计的引导标准误差或系数估计的函数。可以计算百分位数、\(\mathrm{BC}\) 百分位数和 \(\mathrm{BC}_{a}\) 置信区间。
\(\mathrm{BC}_{a}\) 区间需要一个加速度系数 \(a\) 的估计器,它是估计器三阶矩的缩放折刀估计。在聚类观察的背景下,应使用删除聚类折刀来估计 \(a\)。
此外,在每个 bootstrap 样本上,可以计算集群稳健标准误差,并将其用于计算 bootstrap t 比率,从中可以计算百分位数 t 置信区间。系统蒸发散作为
野生簇引导修复簇和回归量,并生成引导观测值
\[ \begin{aligned} \boldsymbol{Y}_{g}^{*} &=\boldsymbol{X}_{g} \widehat{\beta}+\boldsymbol{e}_{g}^{*} \\ \boldsymbol{e}_{g}^{*} &=\widehat{\boldsymbol{e}}_{i} \xi_{g}^{*} \end{aligned} \]
其中 \(\xi_{g}^{*}\) 是标量辅助随机变量,如上一节所述。请注意,\(\xi_{g}^{*}\) 与簇 \(g\) 中的整个残差向量相互作用。 Cameron、Gelbach 和 Miller (2008) 遵循 Davidson 和 Flachaire (2008) 的建议,对 \(\xi_{g}^{*}\) 使用 Rademacher 随机变量。
对于假设检验,Cameron、Gelbach 和 Miller (2008) 建议使用受限野生簇引导程序。对于 \(\mathbb{M}_{0}: r(\beta)=0\) 的测试,令 \(\widetilde{\beta}\) 为 \(\beta\) 的 CLS 或 EMD 估计量,并受到 \(r(\widetilde{\beta})=\) 0 的限制。令 \(\widetilde{\boldsymbol{e}}_{g}=\boldsymbol{Y}_{g}-\boldsymbol{X}_{g} \widetilde{\beta}\) 为受约束的簇级残差。受限野生簇引导算法生成的观察结果为
\[ \begin{aligned} \boldsymbol{Y}_{g}^{*} &=\boldsymbol{X}_{g} \widetilde{\beta}+\boldsymbol{e}_{g}^{*} \\ \boldsymbol{e}_{g}^{*} &=\widetilde{\boldsymbol{e}}_{i} \xi_{g}^{*} \end{aligned} \]
在每个 bootstrap 样本上,应用 \(\mathbb{M}_{0}\)(t 比、Wald、LR 或 F)的检验统计量。由于引导算法满足 \(\mathbb{M}_{0}\),这些统计数据以假设值为中心。然后按常规计算 p 值并用于评估检验统计量的显着性。
传统的渐近近似对于聚类观测效果不佳的原因有多种。首先,虽然样本量 \(n\) 可能很大,但有效样本量是聚类 \(G\) 的数量。这是因为当每个簇内的依赖结构不受约束时,中心极限定理有效地将每个簇视为单个观测值。因此,如果 \(G\) 很小,我们应该将推理视为小样本问题。其次,聚类鲁棒协方差矩阵估计明确地将每个聚类视为单个观测值。因此,tratios 和 Wald 统计的正态近似的准确性可以更准确地视为小样本分布问题。第三,当簇大小 \(n_{g}\) 是异质的时,这意味着刚刚描述的估计问题也涉及异质方差。具体来说,异构簇大小会导致高度的有效异方差(因为簇内总和的方差与 \(n_{g}\) 成正比)。当 \(G\) 很小时,这意味着集群鲁棒推理类似于具有小异方差样本的有限样本推理。第四,兴趣通常涉及在集群级别应用的处理(例如第 4.21 节中讨论的跟踪效果)。如果处理的簇的数量很小,这相当于使用高度稀疏的虚拟变量设计进行估计,在这种情况下,簇鲁棒的协方差矩阵估计可能不可靠。
这些担忧表明,在少数组 \(G\) 的聚类观察的背景下,传统的正态近似可能很差,从而激发了引导方法的使用。然而,这些问题也可能对引导近似的准确性造成挑战。当簇数量 \(G\) 较小、簇大小 \(n_{g}\) 异构或处理的簇数量较小时,引导方法可能不准确。在这种情况下,应该谨慎进行推理。
为了说明对集群引导程序的使用,表 \(10.4\) 报告了对来自 Duflo、Dupas 和 Kremer (2011) 的测试分数跟踪效果的 \(4.21\) 部分示例的估计。除了渐近聚类标准误差之外,我们还报告聚类折刀和聚类自举标准误差以及三个百分位数类型的置信区间。我们使用 10,000 次引导复制。在此示例中,渐近、折刀和集群引导标准误差是相同的,这反映了该特定回归设计的良好平衡。
表 10.4:跟踪效果估计方法的比较
| Coefficient on Tracking | \(0.138\) |
|---|---|
| Asymptotic cluster s.e. | \((0.078)\) |
| Jackknife cluster s.e. | \((0.078)\) |
| Cluster Bootstrap s.e. | \((0.078)\) |
| \(95 %\) Percentile Interval | \([-0.013,0.291]\) |
| \(95 % \mathrm{BC}\) Percentile Interval | \([-0.015,0.289]\) |
| \(95 % \mathrm{BC}_{a}\) Percentile Interval | \([-0.018,0.286]\) |
在 Stata 中,要获取集群引导标准误差和置信区间,请使用选项 cluster (id) vce(bootstrap,reps \(\#\) )) ,其中 id 是集群变量,# 是复制次数。
10.31 技术证明*
以下收敛结果促进了一些渐近结果。
定理 10.20 Marcinkiewicz WLLN 如果 \(u_{i}\) 独立且一致可积,则对于任何 \(r>\) 1 ,作为 \(n \rightarrow \infty, n^{-r} \sum_{i=1}^{n}\left|u_{i}\right|^{r} \underset{p}{\longrightarrow} 0\)。
定理证明\(10.20\)
\[ n^{-r} \sum_{i=1}^{n}\left|u_{i}\right|^{r} \leq\left(n^{-1} \max _{1 \leq i \leq n}\left|u_{i}\right|\right)^{r-1} \frac{1}{n} \sum_{i=1}^{n}\left|u_{i}\right| \underset{p}{\longrightarrow} 0 \]
由 WLLN、定理 \(6.15\) 和 \(r>1\) 得出。
定理证明 10.1 修复 \(\epsilon>0\)。由于 \(Z_{n} \underset{p}{\longrightarrow} Z\) 有一个足够大的 \(n\) 使得
\[ \mathbb{P}\left[\left\|Z_{n}-Z\right\|>\epsilon\right]<\epsilon . \]
由于事件 \(\left\|Z_{n}-Z\right\|>\epsilon\) 在条件概率 \(\mathbb{P}^{*}\) 下是非随机的,对于这样的 \(n\),
\[ \mathbb{P}^{*}\left[\left\|Z_{n}-Z\right\|>\epsilon\right]=\left\{\begin{array}{cc} 0 & \text { with probability exceeding } 1-\epsilon \\ 1 & \text { with probability less than } \epsilon . \end{array}\right. \]
由于 \(\varepsilon\) 是任意的,我们根据需要得出 \(\mathbb{P}^{*}\left[\left\|Z_{n}-Z\right\|>\epsilon\right] \underset{p}{\longrightarrow} 0\) 的结论。
定理证明 10.2 修复 \(\epsilon>0\)。根据马尔可夫不等式 (B.36)、事实 (10.12) 和 (10.13),以及最后的 Marcinkiewicz WLLN(定理 10.20)以及 \(r=2\) 和 \(u_{i}=\left\|Y_{i}\right\|\),
\[ \begin{aligned} \mathbb{P}^{*}\left[\left\|\bar{Y}^{*}-\bar{Y}\right\|>\epsilon\right] & \leq \epsilon^{-2} \mathbb{E}^{*}\left\|\bar{Y}^{*}-\bar{Y}\right\|^{2} \\ &=\epsilon^{-2} \operatorname{tr}\left(\operatorname{var}^{*}\left[\bar{Y}^{*}\right]\right) \\ &=\epsilon^{-2} \operatorname{tr}\left(\frac{1}{n} \widehat{\Sigma}\right) \\ & \leq \epsilon^{-2} n^{-2} \sum_{i=1}^{n} Y_{i}^{\prime} Y_{i} \\ & \underset{p}{ } 0 \end{aligned} \]
这确定了\(\bar{Y}^{*}-\bar{Y} \underset{p^{*}}{\longrightarrow} 0\)。
由于 \(\bar{Y}-\mu \underset{p}{\longrightarrow} 0\) 由 WLLN 确定,\(\bar{Y}-\mu \underset{p^{*}}{\longrightarrow} 0\) 由定理 10.1 确定。从 \(\bar{Y}^{*}-\mu=\bar{Y}^{*}-\bar{Y}+\bar{Y}-\mu\) 开始,我们推导出 \(\bar{Y}^{*}-\mu \underset{p^{*}}{ } 0\)。
定理 10.4 的证明 我们验证多元 Lindeberg CLT 的条件(定理 6.4)。 (我们不能使用 Lindeberg-Lévy CLT,因为条件分布取决于 \(n\)。)以 \(F_{n}\) 为条件,引导程序得出 \(Y_{i}^{*}-\bar{Y}\) 是独立同分布的。均值 0 和协方差矩阵 \(\widehat{\Sigma}\)。设置 \(v_{n}^{2}=\lambda_{\min }(\widehat{\Sigma})\)。请注意,根据 WLLN,\(v_{n}^{2} \underset{p}{\rightarrow} v^{2}=\lambda_{\min }(\Sigma)>0\)。因此,对于 \(n\) 足够大的情况,\(v_{n}^{2}>0\) 的概率很高。修复 \(\epsilon>0\)。方程(6.2)等于
\[ \begin{aligned} \frac{1}{n v_{n}^{2}} \sum_{i=1}^{n} \mathbb{E}^{*}\left[\left\|Y_{i}^{*}-\bar{Y}\right\|^{2} \mathbb{1}\left\{\left\|Y_{i}^{*}-\bar{Y}\right\|^{2} \geq \epsilon n v_{n}^{2}\right\}\right] &=\frac{1}{v_{n}^{2}} \mathbb{E}^{*}\left[\left\|Y_{i}^{*}-\bar{Y}\right\|^{2} \mathbb{1}\left\{\left\|Y_{i}^{*}-\bar{Y}\right\|^{2} \geq \epsilon n v_{n}^{2}\right\}\right] \\ & \leq \frac{1}{\epsilon n v_{n}^{4}} \mathbb{E}^{*}\left\|Y_{i}^{*}-\bar{Y}\right\|^{4} \\ & \leq \frac{2^{4}}{\epsilon n v_{n}^{4}} \mathbb{E}^{*}\left\|Y_{i}^{*}\right\|^{4} \\ &=\frac{2^{4}}{\epsilon n^{2} v_{n}^{4}} \sum_{i=1}^{n}\left\|Y_{i}\right\|^{4} \\ & \longrightarrow 0 . \end{aligned} \]
第二个不等式使用 Minkowski 不等式 (B.34)、Liapunov 不等式 (B.35) 和 \(c_{r}\) 不等式 (B.6)。下面的等式是\(\mathbb{E}^{*}\left\|Y_{i}^{*}\right\|^{4}=n^{-1} \sum_{i=1}^{n}\left\|Y_{i}\right\|^{4}\),它类似于(10.10)。 Marcinkiewicz WLLN(定理 10.20)与 \(r=2\) 和 \(u_{i}=\left\|Y_{i}\right\|^{2}\) 的最终收敛成立。定理 \(6.4\) 的条件成立,我们得出结论
\[ \widehat{\Sigma}^{-1 / 2} \sqrt{n}\left(\bar{Y}^{*}-\bar{Y}\right) \underset{d^{*}}{\longrightarrow} \mathrm{N}(0, \boldsymbol{I}) . \]
从 \(\widehat{\Sigma} \underset{p^{*}}{\longrightarrow} \Sigma\) 开始,我们推断出 \(\sqrt{n}\left(\bar{Y}^{*}-\bar{Y}\right) \underset{d^{*}}{\longrightarrow} \mathrm{N}(0, \Sigma)\) 正如所声称的那样。
定理证明 \(10.10\) 为了符号简单起见,假设 \(\theta\) 和 \(\mu\) 是标量。设置 \(h_{i}=h\left(Y_{i}\right)\)。 \(g(u)\) 的 \(p^{t h}\) 导数有界的假设意味着 \(\left|g^{(p)}(u)\right| \leq C\) 对于某些 \(C<\infty\) 而言。采用 \(p^{\text {th }}\) 阶泰勒级数展开式
\[ \widehat{\theta}^{*}-\widehat{\theta}=g\left(\bar{h}^{*}\right)-g(\bar{h})=\sum_{j=1}^{p-1} \frac{g^{(j)}(\bar{h})}{j !}\left(\bar{h}^{*}-\bar{h}\right)^{j}+\frac{g^{(p)}\left(\zeta_{n}^{*}\right)}{p !}\left(\bar{h}^{*}-\bar{h}\right)^{p} \]
其中 \(\zeta_{n}^{*}\) 位于 \(\bar{h}^{*}\) 和 \(\bar{h}\) 之间。这意味着
\[ \left|z_{n}^{*}\right|=\sqrt{n}\left|\widehat{\theta}^{*}-\widehat{\theta}\right| \leq \sqrt{n} \sum_{j=1}^{p} c_{j} \mid \bar{h}^{*}-\bar{h}^{j} \]
其中 \(c_{j}=\left|g^{(j)}(\bar{h})\right| / j\) !对于 \(j<p\) 和 \(c_{p}=C / p\)!。我们发现归一化自举估计量 \(Z_{n}^{*}=\sqrt{n}\left(\widehat{\theta}^{*}-\widehat{\theta}\right)\) 的第四中心矩满足边界
\[ \mathbb{E}^{*}\left[Z_{n}^{* 4}\right] \leq \sum_{r=4}^{4 p} a_{r} n^{2} \mathbb{E}^{*}\left|\bar{h}^{*}-\bar{h}\right|^{r} \]
其中系数 \(a_{r}\) 是系数 \(c_{j}\) 的乘积,因此也是每个 \(O_{p}(1)\) 的乘积。我们看到\(\mathbb{E}^{*}\left[Z_{n}^{* 4}\right]=\) \(O_{p}(1)\) if \(n^{2} \mathbb{E}^{*}\left|\bar{h}^{*}-\bar{h}\right|^{r}=O_{p}(1)\) for \(r=4, \ldots, 4 p\)。
我们使用罗森塔尔不等式 (B.50) 证明这对于任何 \(r \geq 4\) 都成立,该不等式指出对于每个 \(r\) 都有一个常数 \(R_{r}<\infty\) 使得
\[ \begin{aligned} n^{2} \mathbb{E}^{*}\left|\bar{h}^{*}-\bar{h}\right|^{r} &=n^{2-r_{\mathbb{E}}}\left|\sum_{i=1}^{n}\left(h_{i}^{*}-\bar{h}\right)\right|^{r} \\ & \leq n^{2-r} R_{r}\left\{\left(n \mathbb{E}^{*}\left(h_{i}^{*}-\bar{h}\right)^{2}\right)^{r / 2}+n \mathbb{E}^{*}\left|h_{i}^{*}-\bar{h}\right|^{r}\right\} \\ &=R_{r}\left\{n^{2-r / 2} \widehat{\sigma}^{r}+\frac{1}{n^{r-2}} \sum_{i=1}^{n}\left|h_{i}-\bar{h}\right|^{r}\right\} \end{aligned} \]
由于 \(\mathbb{E}\left[h_{i}^{2}\right]<\infty, \widehat{\sigma}^{2}=O_{p}(1)\),所以 (10.36) 中的第一项是 \(O_{p}(1)\)。另外,根据 Marcinkiewicz WLLN(定理 10.20),\(n^{-r / 2} \sum_{i=1}^{n}\left|h_{i}-\bar{h}\right|^{r}=o_{p}\) (1) 对于任何 \(r \geq 1\),因此 (10.36) 中的第二项对于 \(r \geq 4\) 是 \(o_{p}(1)\)。因此,对于所有 \(r \geq 4,(10.36)\) 都是 \(O_{p}(1)\),因此 (10.35) 是 \(O_{p}(1)\)。我们推断 \(\mathbb{E}\left[h_{i}^{2}\right]<\infty, \widehat{\sigma}^{2}=O_{p}(1)\) 是一致平方可积的,并且方差的 bootstrap 估计是一致的。
这个论点可以扩展到向量值均值和估计。
定理 10.12 的证明 我们证明\(\mathbb{E}^{*}\left\|Z_{n}^{* *}\right\|^{4}=O_{p}(1)\)。定理 \(6.13\) 表明 \(Z_{n}^{* *}\) 是一致平方可积的。由于 \(Z_{n}^{* *} \underset{d^{*}}{\longrightarrow} Z\),定理 \(6.14\) 意味着 \(\operatorname{var}\left[Z_{n}^{* *}\right] \rightarrow \operatorname{var}[Z]=V_{\beta}\) 如所述。
设置 \(h_{i}=h\left(Y_{i}\right)\)。由于 \(\boldsymbol{G}(x)=\frac{\partial}{\partial x} g(x)^{\prime}\) 在 \(\mu\) 的邻域内连续,因此存在 \(\eta>0\) 和 \(M<\infty\),使得 \(\|x-\mu\| \leq 2 \eta\) 蕴含 \(\operatorname{tr}\left(\boldsymbol{G}(x)^{\prime} \boldsymbol{G}(x)\right) \leq M\)。通过 WLLN 和 bootstrap WLLN,\(n\) 足够大,使得 \(\left\|\bar{h}_{n}-\mu\right\| \leq \eta\) 和 \(h_{i}=h\left(Y_{i}\right)\) 的概率超过 \(h_{i}=h\left(Y_{i}\right)\)。在此事件中,\(h_{i}=h\left(Y_{i}\right)\) 意味着 \(h_{i}=h\left(Y_{i}\right)\)。在\(h_{i}=h\left(Y_{i}\right)\)和\(h_{i}=h\left(Y_{i}\right)\)之间的\(h_{i}=h\left(Y_{i}\right)\)中间点使用均值定理
\[ \begin{aligned} \left\|Z_{n}^{* *}\right\|^{4} \mathbb{1}\left\{\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\| \leq \eta\right\} & \leq n^{2}\left\|g\left(\bar{h}_{n}^{*}\right)-g\left(\bar{h}_{n}\right)\right\|^{4} \mathbb{1}\left\{\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\| \leq \eta\right\} \\ & \leq n^{2}\left\|\boldsymbol{G}\left(\zeta_{n}^{*}\right)^{\prime}\left(\bar{h}_{n}^{*}-\bar{h}_{n}\right)\right\|^{4} \\ & \leq M^{2} n^{2}\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\|^{4} . \end{aligned} \]
然后
\[ \begin{aligned} \mathbb{E}^{*}\left\|Z_{n}^{* *}\right\|^{4} & \leq \mathbb{E}^{*}\left[\left\|Z_{n}^{* *}\right\|^{4} \mathbb{1}\left\{\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\| \leq \eta\right\}\right]+\tau_{n}^{4} \mathbb{E}^{*}\left[\mathbb{1}\left\{\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\|>\eta\right\}\right] \\ & \leq M^{2} n^{2} \mathbb{E}^{*}\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\|^{4}+\tau_{n}^{4} \mathbb{P}^{*}\left(\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\|>\eta\right) . \end{aligned} \]
在(10.17)中,我们证明了(10.37)中的第一项在标量情况下是\(O_{p}(1)\)。向量情况遵循逐元素扩展。
现在取 (10.37) 中的第二项。我们将伯恩斯坦不等式应用于向量(B.41)。请注意 \(\bar{h}_{n}^{*}-\bar{h}_{n}=n^{-1} \sum_{i=1}^{n} u_{i}^{*}\) 与 \(u_{i}^{*}=h_{i}^{*}-\bar{h}_{n}\) 和 \(j^{t h}\) 元素 \(u_{j i}^{*}=h_{j i}^{*}-\bar{h}_{j n}\)。 \(u_{i}^{*}\) 是 i.i.d.,均值为零,\(\mathbb{E}^{*}\left[u_{j i}^{* 2}\right]=\widehat{\sigma}_{j}^{2}=O_{p}(1)\),并且满足边界 \(\left|u_{j i}^{*}\right| \leq 2 \max _{i, j}\left|h_{j i}\right|=B_{n}\)。伯恩斯坦不等式指出
\[ \mathbb{P}^{*}\left[\left\|\bar{h}_{n}^{*}-\bar{h}_{n}\right\|>\eta\right] \leq 2 m \exp \left(-n^{1 / 2} \frac{\eta^{2}}{2 m^{2} n^{-1 / 2} \max _{j} \widehat{\sigma}_{j}^{2}+2 m n^{-1 / 2} B_{n} \eta / 3}\right) . \]
定理\(6.15\)表明\(n^{-1 / 2} B_{n}=o_{p}(1)\)。因此 (10.38) 中括号分母的表达式为 \(o_{p}\) (1) as \(n \rightarrow \infty\), 。由此可见,对于足够大的 \(n\) (10.38),\(O_{p}\left(\exp \left(-n^{1 / 2}\right)\right)\) 是足够大的。因此,根据 \(\tau_{n}\) 的假设,(10.37) 中的第二项是 \(O_{p}\left(\exp \left(-n^{1 / 2}\right)\right) o_{p}\left(\exp \left(-n^{1 / 2}\right)\right)=o_{p}(1)\)。
我们已经证明 (10.37) 中的两项均为 \(O_{p}(1)\)。这样就完成了证明。
10.32 练习
练习 10.1 求 \(\mu_{r}=\mathbb{E}\left[Y_{i}^{r}\right]\) 的估计量 \(\widehat{\mu}_{r}=n^{-1} \sum_{i=1}^{n} Y_{i}^{r}\) 的方差折刀估计量。
练习10.2 证明如果\(\widehat{\beta}\) 的方差折刀估计量为\(\widehat{V}_{\widehat{\beta}}^{\text {jack }}\),则\(\widehat{\theta}=\boldsymbol{a}+\boldsymbol{C} \widehat{\beta}\) 的方差折刀估计量为\(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\mathrm{jack}}=\boldsymbol{C} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{jack}} \boldsymbol{C}^{\prime}\)。
练习 10.3 两步估计量(如 (12.49))是 \(\widehat{\beta}=\left(\sum_{i=1}^{n} \widehat{W}_{i} \widehat{W}_{i}^{\prime}\right)^{-1}\left(\sum_{i=1}^{n} \widehat{W}_{i} Y_{i}\right)\),其中 \(\widehat{W}_{i}=\widehat{A}^{\prime} Z_{i}\) 和 \(\widehat{\boldsymbol{A}}=\left(\boldsymbol{Z}^{\prime} \boldsymbol{Z}\right)^{-1} \boldsymbol{Z}^{\prime} \boldsymbol{X}\)。描述如何构造 \(\widehat{\beta}\) 方差的折刀估计器。
练习10.4 证明如果\(\widehat{\beta}\) 的方差自举估计量是\(\widehat{V}_{\widehat{\beta}}^{\text {boot }}\),那么\(\widehat{\theta}=\boldsymbol{a}+\boldsymbol{C} \widehat{\beta}\) 的方差自举估计量是\(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\text {boot }}=\boldsymbol{C} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\text {boot }} \boldsymbol{C}^{\prime}\)。
练习 \(10.5\) 表明,如果 \(\beta\) 的百分位数区间为 \([L, U]\),则 \(a+c \beta\) 的百分位数区间为 \([a+c L, a+c U]\)。
练习 \(10.6\) 考虑以下引导程序。使用非参数引导程序,生成引导程序样本,计算这些样本的估计 \(\widehat{\theta}^{*}\),然后计算
\[ T^{*}=\left(\widehat{\theta}^{*}-\widehat{\theta}\right) / s(\widehat{\theta}), \]
其中 \(s(\hat{\theta})\) 是原始数据中的标准误差。令\(q_{\alpha / 2}^{*}\)和\(q_{1-\alpha / 2}^{*}\)表示\(T^{*}\)的\(\alpha / 2^{t h}\)和\(1-\alpha / 2^{t h}\)分位数,并定义自举置信区间
\[ C=\left[\widehat{\theta}+s(\widehat{\theta}) q_{\alpha / 2}^{*}, \quad \widehat{\theta}+s(\widehat{\theta}) q_{1-\alpha / 2}^{*}\right] . \]
证明 \(C\) 完全等于百分位间隔。练习 \(10.7\) 证明定理 10.6。
练习 \(10.8\) 证明定理 10.7。
练习 \(10.9\) 证明定理 10.8。
练习 \(10.10\) 令 \(Y_{i}\) 为独立同分布,\(\mu=\mathbb{E}[Y]>0\) 和 \(\theta=\mu^{-1}\)。令 \(\widehat{\mu}=\bar{Y}_{n}\) 为样本平均值,\(\widehat{\theta}=\widehat{\mu}^{-1}\) 为样本平均值。
\(\hat{\theta}\) 对于 \(\theta\) 是无偏的吗?
如果 \(\widehat{\theta}\) 有偏差,你能确定 \(\mathbb{E}[\widehat{\theta}-\theta]\) 偏差的方向(向上或向下)吗?
在这种情况下,百分位区间是否适合构建置信区间?
练习 \(10.11\) 考虑以下引导程序,用于 \(Y\) 在 \(X\) 上的回归。让 \(\widehat{\beta}\) 表示 OLS 估计器,\(\widehat{e}_{i}=Y_{i}-X_{i}^{\prime} \widehat{\beta}\) 表示 OLS 残差。
从 \(\left\{\left(X_{i}, \widehat{e}_{i}\right): i=1, \ldots, n\right\}\) 对中抽取一个随机向量 \(\left(X^{*}, e^{*}\right)\)。即从\([1,2, \ldots, n]\)中抽取一个随机整数\(i^{\prime}\),并设置\(X^{*}=X_{i^{\prime}}\)和\(e^{*}=\widehat{e}_{i^{\prime}}\)。设置 \(Y^{*}=X^{* \prime} \widehat{\beta}+e^{*}\)。绘制(带替换)\(n\) 这样的向量,创建随机引导数据集 \(\left(\boldsymbol{Y}^{*}, \boldsymbol{X}^{*}\right)\)。
在 \(\boldsymbol{X}^{*}\) 上回归 \(\boldsymbol{Y}^{*}\),产生 OLS 估计器 \(\widehat{\beta}^{*}\) 和任何其他感兴趣的统计量。
证明此引导程序(在数字上)与非参数引导程序相同。
练习 \(10.12\) 采用 (10.22) 中定义的 \(p^{*}\) 作为 BC 百分位数区间。证明对于任何严格单调递增变换 \(g(\theta)\),用 \(g(\theta)\) 替换 \(\theta\) 是不变的。这是否扩展到(10.23)中定义的 \(z_{0}^{*}\)?
练习 \(10.13\) 表明,如果 \(\beta\) 的百分位数 t 区间为 \([L, U]\),则 \(a+c \beta\) 的百分位数 t 区间为 \([a+b L, a+b U]\)。
练习 10.14 你想要针对 \(\mathbb{M}_{1}: \theta>0\) 测试 \(\mathbb{M}_{0}: \theta=0\)。 \(\mathbb{M}_{0}\) 的测试是拒绝 \(T_{n}=\widehat{\theta} / s(\widehat{\theta})>c\)(其中选择 \(c\)),以便类型 I 错误为 \(\alpha\)。您按如下方式执行此操作。使用非参数引导程序,您可以生成引导程序样本,计算这些样本的估计值 \(\widehat{\theta}^{*}\),然后计算 \(T^{*}=\) \(\widehat{\theta}^{*} / s\left(\widehat{\theta}^{*}\right)\)。令 \(\mathbb{M}_{0}: \theta=0\) 表示 \(\mathbb{M}_{0}: \theta=0\) 的 \(\mathbb{M}_{0}: \theta=0\) 分位数。您将 \(\mathbb{M}_{0}: \theta=0\) 替换为 \(\mathbb{M}_{0}: \theta=0\),因此如果 \(\mathbb{M}_{0}: \theta=0\) 则拒绝 \(\mathbb{M}_{0}: \theta=0\)。这个程序有什么问题吗?
练习10.15 假设在一个应用程序中,\(\widehat{\theta}=1.2\) 和\(s(\widehat{\theta})=0.2\)。使用非参数引导程序,从引导程序分布中生成 1000 个样本,并对每个样本计算 \(\widehat{\theta}^{*}\)。 \(\widehat{\theta}^{*}\) 已排序,\(\widehat{\theta}^{*}\) 的 \(0.025^{t h}\) 和 \(0.975^{t h}\) 分位数分别为 \(.75\) 和 \(1.3\)。
报告 \(\theta\) 的 \(95 %\) 百分位数区间。
根据给定的信息,您可以计算 \(\theta\) 的 95% BC 百分位数区间或百分位数-t 区间吗?
练习10.16 采用正态回归模型\(Y=X^{\prime} \beta+e\)和\(e \mid X \sim \mathrm{N}\left(0, \sigma^{2}\right)\),其中我们知道MLE等于最小二乘估计量\(\widehat{\beta}\)和\(\widehat{\sigma}^{2}\)。
描述该模型的参数回归引导程序。显示 bootstrap 观测值的条件分布为 \(Y_{i}^{*} \mid F_{n} \sim \mathrm{N}\left(X_{i}^{\prime} \widehat{\beta}, \widehat{\sigma}^{2}\right)\)。 (b) 显示引导最小二乘估计量的分布为 \(\widehat{\beta}^{*} \mid F_{n} \sim \mathrm{N}\left(\widehat{\beta},\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \widehat{\sigma}^{2}\right)\)。
显示具有同方差标准误的自举 t 比的分布为 \(T^{*} \sim\) \(t_{n-k}\)。
练习 \(10.17\) 考虑模型 \(Y=X^{\prime} \beta+e\),其中 \(\mathbb{E}[e \mid X]=0, Y\) 为标量,\(X\) 为 \(k\) 向量。您有一个随机样本 \(\left(Y_{i}, X_{i}: i=1, \ldots, n\right)\)。您有兴趣估计固定向量 \(x\) 处的回归函数 \(m(x)=\) \(\mathbb{E}[Y \mid X=x]\) 并构建 \(10.17\) 置信区间。
写出 \(m(x)\) 的标准估计量和渐近置信区间。
描述 \(m(x)\) 的百分位数引导置信区间。
描述 \(m(x)\) 的百分位数-t 自举置信区间。
练习10.18 观察到的数据是\(\left\{Y_{i}, X_{i}\right\} \in \mathbb{R} \times \mathbb{R}^{k}, k>1, i=1, \ldots, n\)。采用模型 \(Y=X^{\prime} \beta+e\) 和 \(\mathbb{E}[X e]=0 .\)
写下 \(\mu_{3}=\mathbb{E}\left[e^{3}\right]\) 的估计量。
解释如何使用百分位数方法在此特定模型中为 \(\mu_{3}\) 构建 90% 置信区间。
练习 \(10.19\) 采用模型 \(Y=X^{\prime} \beta+e\) 和 \(\mathbb{E}[X e]=0\)。描述 \(\sigma^{2}=\mathbb{E}\left[e^{2}\right]\) 的引导百分位数置信区间。
练习10.20 模型是\(Y=X_{1}^{\prime} \beta_{1}+X_{2}^{\prime} \beta_{2}+e\),带有\(\mathbb{E}[X e]=0\) 和\(X_{2}\) 标量。描述如何使用非参数引导程序针对 \(\mathbb{H}_{1}: \beta_{2} \neq 0\) 测试 \(\mathbb{H}_{0}: \beta_{2}=0\)。
练习10.21 模型是\(Y=X_{1}^{\prime} \beta_{1}+X_{2}^{\prime} \beta_{2}+e\) 和\(\mathbb{E}[X e]=0\),以及\(X_{1}\) 和\(X_{2} k \times 1\)。描述如何使用非参数引导程序测试 \(\mathbb{M}_{0}: \beta_{1}=\beta_{2}\) 与 \(\mathbb{M}_{1}: \beta_{1} \neq \beta_{2}\)。
练习 10.22 假设一个博士。学生有一个样本 \(\left(Y_{i}, X_{i}, Z_{i}: i=1, \ldots, n\right)\),并通过 OLS 估计方程 \(Y=Z \alpha+X^{\prime} \beta+e\),其中 \(\alpha\) 是感兴趣的系数。她有兴趣针对 \(\mathbb{H}_{1}: \alpha \neq 0\) 测试 \(\mathbb{H}_{0}: \alpha=0\)。她获得 \(\widehat{\alpha}=2.0\) 和标准错误 \(s(\widehat{\alpha})=1.0\),因此 \(\mathbb{H}_{0}\) 的 t 比率值为 \(T=\widehat{\alpha} / s(\widehat{\alpha})=2.0\)。为了评估重要性,学生决定使用引导程序。她使用以下算法
从观察结果中随机抽取 \(\left(Y_{i}^{*}, X_{i}^{*}, Z_{i}^{*}\right)\) 样本。 (随机抽样并放回)。使用 \(n\) 观察值创建随机样本。
在此伪样本上,通过 OLS 估计方程 \(Y_{i}^{*}=Z_{i}^{*} \alpha+X_{i}^{* \prime} \beta+e_{i}^{*}\) 并计算标准误差,包括 \(s\left(\widehat{\alpha}^{*}\right)\)。计算并存储 \(\mathbb{H}_{0}, T^{*}=\widehat{\alpha}^{*} / s\left(\widehat{\alpha}^{*}\right)\) 的 t 比率。
重复 \(B=10,000\) 次。
计算自举绝对 t 比率 \(\left|T^{*}\right|\) 的 \(0.95^{t h}\) 经验分位数 \(q_{.95}^{*}=3.5\)。
学生注意到,虽然 \(|T|=2>1.96\) (因此渐近 \(5 %\) 大小测试会拒绝 \(\mathbb{M}_{0}\) ),但 \(|T|=\) \(2<q_{.95}^{*}=3.5\) 和引导测试不会拒绝 \(\mathbb{M}_{0}\) 。由于引导程序更可靠,学生得出结论,不能拒绝 \(\mathbb{M}_{0}\) 而选择 \(\mathbb{H}_{1}\)。问:您同意学生的方法和推理吗?你发现她的方法有错误吗?
练习10.23 采用模型\(Y=X_{1} \beta_{1}+X_{2} \beta_{2}+e\)、\(\mathbb{E}[X e]=0\)以及标量\(X_{1}\)和\(X_{2}\)。感兴趣的参数是 \(\theta=\beta_{1} \beta_{2}\)。展示如何使用以下三种方法构建 \(\theta\) 的置信区间。
渐近理论。
百分位引导法。
百分位-t Bootstrap。
你的答案应该针对这个问题,而不是笼统的。
练习 10.24 采用具有 i.i.d 观测值、\(\mathbb{E}[X e]=0\) 以及标量 \(X_{1}\) 和 \(X_{2}\) 的模型 \(Y=X_{1} \beta_{1}+X_{2} \beta_{2}+e\)。描述如何构建 \(\theta=\beta_{1} / \beta_{2}\) 的百分位数-t 自举置信区间。
练习 10.25 该模型是 i.i.d.数据,\(i=1, \ldots, n, Y=X^{\prime} \beta+e\) 和 \(\mathbb{E}[e \mid X]=0\)。条件异方差的存在是否会使非参数引导的应用无效?解释。
练习 10.26 随机样本中非线性的 RESET 规范测试(源自 Ramsey (1969))如下。原假设是 \(Y=X^{\prime} \beta+e\) 与 \(\mathbb{E}[e \mid X]=0\) 的线性回归。参数 \(\beta\) 通过 OLS 估计,产生预测值 \(\widehat{Y}_{i}\)。然后估计第二阶段最小二乘回归,包括 \(X_{i}\) 和 \(\widehat{Y}_{i}\)
\[ Y_{i}=X_{i}^{\prime} \widetilde{\beta}+\left(\widehat{Y}_{i}\right)^{2} \widetilde{\gamma}+\widetilde{e}_{i} \]
RESET 检验统计量 \(R\) 是 \(\widetilde{\gamma}\) 上的 t 比平方。
一位同事建议使用引导程序获取测试的临界值。他提出了以下引导程序实施方案。
从观察到的样本对 \(\left(Y_{i}, X_{i}\right)\) 中随机抽取 \(n\) 观察值 \(\left(Y_{i}^{*}, X_{i}^{*}\right)\) 以创建引导样本。
如上所述计算此 bootstrap 样本的统计数据 \(R^{*}\)。
重复此\(B\)次。对引导统计数据 \(R^{*}\) 进行排序,获取 \(0.95^{t h}\) 分位数并将其用作临界值。
如果 \(R\) 超过此临界值,则拒绝原假设,否则不拒绝。
在这种情况下,此过程是否是引导程序的正确实现?如果没有,请提出修改建议。
练习10.27 模型是\(Y=X^{\prime} \beta+e\) 和\(\mathbb{E}[X e] \neq 0\)。我们知道,在这种情况下,最小二乘估计器可能会对参数 \(\beta\) 产生偏差。我们还知道,非参数 BC 百分位区间(通常)是存在偏差时构建置信区间的好方法。解释您是否期望应用于最小二乘估计量的 BC 百分位区间在此上下文中具有准确的覆盖范围。
练习 10.28 在练习 9.26 中,您估计了 145 家电力公司的成本函数并测试了限制 \(\theta=\beta_{3}+\beta_{4}+\beta_{5}=1\)。 (a) 通过无限制最小二乘法估计回归,并报告通过渐近法、折刀法和自举法计算的标准误差。
估计 \(\theta=\beta_{3}+\beta_{4}+\beta_{5}\) 并报告通过渐近法、折刀法和自举法计算的标准误差。
使用百分位数和 \(\mathrm{BC}_{a}\) 方法报告 \(\theta\) 的置信区间。
练习 10.29 在练习 9.27 中,您估计了 Mankiw、Romer 和 Weil (1992) 无限制回归。令 \(\theta\) 为第二个、第三个和第四个系数的总和。
通过无限制最小二乘法估计回归,并报告通过渐近法、折刀法和自举法计算的标准误差。
估计 \(\theta\) 并报告通过渐近法、折刀法和自举法计算的标准误差。
使用百分位数和 BC 方法报告 \(\theta\) 的置信区间。
练习 10.30 在练习 \(7.28\) 中,您使用 cps09mar 数据集和西班牙裔白人男性子样本估计了工资回归。进一步将样本限制为居住在中西部地区的未婚人士。 (该样本有 99 个观察值。)如子问题 (b) 所示,令 \(\theta\) 为一年教育回报与一年经验回报的比率。
估计 \(\theta\) 并报告通过渐近法、折刀法和自举法计算的标准误差。
解释标准误差之间的差异。
使用 BC 百分位数方法报告 \(\theta\) 的置信区间。
练习 10.31 在练习 \(4.26\) 中,你扩展了 Duflo、Dupas 和 Kremer (2011) 的工作。重复该回归,现在通过集群引导程序计算标准误差。报告每个系数的 \(\mathrm{BC}_{a}\) 置信区间。