第9章: 假设检验
9 假设检验
在第五章中,我们简要介绍了正态回归模型中的假设检验。在本章中,我们将更详细地探讨假设检验,特别强调渐近推理。有关基础的更多详细信息,请参阅《经济学家的概率与统计》第 13 章。
9.1 假设
在第8章中,我们讨论了受限制的估计,包括线性限制(8.1)、非线性限制(8.44)和不等式限制(8.49)。在本章中,我们将讨论此类限制的测试。
假设检验试图评估是否有证据与提议的限制相反。令 \(\theta=r(\beta)\) 为感兴趣的 \(q \times 1\) 参数,其中 \(r: \mathbb{R}^{k} \rightarrow \Theta \subset \mathbb{R}^{q}\) 是某种变换。例如,\(\theta\) 可以是单个系数,例如\(\theta=\beta_{j}\),两个系数之间的差异,例如\(\theta=\beta_{j}-\beta_{\ell}\),或两个系数的比率,例如\(\theta=\beta_{j} / \beta_{\ell}\)。
关于 \(\theta\) 的点假设是提议的限制,例如
\[ \theta=\theta_{0} \]
其中 \(\theta_{0}\) 是假设(已知)值。
更一般地,让 \(\beta \in B \subset \mathbb{R}^{k}\) 为参数空间,假设是 \(\beta \in B_{0}\) 的限制,其中 \(B_{0}\) 是 \(B\) 的真子集。通过设置 \(B_{0}=\left\{\beta \in B: r(\beta)=\theta_{0}\right\}\) 专门针对 (9.1)。
在本章中,我们将专门关注(9.1)形式的点假设,因为它们是最常见且相对容易处理的。
要检验的假设称为原假设。
定义 9.1 原假设 \(\mathbb{M}_{0}\) 是限制 \(\theta=\theta_{0}\) 或 \(\beta \in B_{0}\)。
我们经常将零假设写为 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 或 \(\mathbb{M}_{0}: r(\beta)=\theta_{0}\)。
原假设的补集(不满足原假设的参数值的集合)称为备择假设。
定义 9.2 备择假设 \(\mathbb{M}_{1}\) 是集合 \(\left\{\theta \in \Theta: \theta \neq \theta_{0}\right\}\) 或 \(\left\{\beta \in B: \beta \notin B_{0}\right\}\) 我们经常将备择假设写为 \(\mathbb{M}_{1}: \theta \neq \theta_{0}\) 或 \(\mathbb{M}_{1}: r(\beta) \neq \theta_{0}\)。为简单起见,我们通常将假设称为“原假设”和“替代假设”。图 9.1(a) 说明了将参数空间划分为原假设和备择假设。
- 无效假设和备择假设
.jpg)
- 接受和拒绝区域
图 9.1:假设检验
在假设检验中,我们假设 \(\theta\) 存在一个真实(但未知)的值,并且该值要么满足 \(\mathbb{M}_{0}\),要么不满足 \(\mathbb{M}_{0}\)。假设检验的目标是通过询问 \(\mathbb{M}_{0}\) 是否与观察到的数据一致来评估 \(\mathbb{H}_{0}\) 是否正确。
具体来说,以我们的工资决定为例,并考虑以下问题:工会会员资格会影响工资吗?我们可以通过将零值指定为工资回归中工会成员系数为零的限制,将其转变为假设检验。例如,请考虑表 4.1 中报告的估计值。 “男性工会成员”的系数为 \(0.095\) (工资溢价为 \(9.5 %\) ),“女性工会成员”的系数为 \(0.022\) (工资溢价为 \(2.2 %\) )。这些是估计值,而不是真实值。问题是:真实系数为零吗?为了回答这个问题,检验方法提出这样的问题:观察到的估计是否与假设相一致,即与假设的偏差可以通过随机变化合理地解释吗?或者观察到的估计是否与假设不相容,即如果假设为真,观察到的估计的可能性极小?
9.2 接受和拒绝
假设检验要么接受原假设,要么拒绝原假设并支持备择假设。我们可以将这两个决定描述为“接受 \(\mathbb{H}_{0}\) ”和“拒绝 \(\mathbb{H}_{0}\) ”。在上一节给出的示例中,决策要么接受工会成员身份不影响工资的假设,要么拒绝工会成员身份确实影响工资的假设。
决策基于数据,因此也是基于样本空间到决策集的映射。这将样本空间分为两个区域 \(S_{0}\) 和 \(S_{1}\),这样,如果观察到的样本落入 \(S_{0}\),我们接受 \(\mathbb{M}_{0}\),而如果样本落入 \(S_{1}\),我们拒绝 \(\mathbb{M}_{0}\)。集合 \(S_{0}\) 称为接受区域,集合 \(S_{1}\) 称为拒绝区域或临界区域。
可以方便地将这种映射表示为称为检验统计量的实值函数
\[ T=T\left(\left(Y_{1}, X_{1}\right), \ldots,\left(Y_{n}, X_{n}\right)\right) \]
相对于临界值 \(c\)。假设检验由决策规则组成:
如果 \(T \leq c\) 则接受 \(\mathbb{H}_{0}\)。
如果 \(T>c\),则拒绝 \(\mathbb{M}_{0}\)。
图 9.1(b) 说明了将样本空间划分为接受区域和拒绝区域。
应设计检验统计量 \(T\),以便当 \(\mathbb{H}_{0}\) 为真时可能出现小值,而当 \(\mathbb{M}_{1}\) 为真时可能出现大值。关于最优测试的设计有一套完善的统计理论。我们不会在这里回顾该理论,而是请读者参考 Lehmann 和 Romano (2005)。在本章中,我们将总结检验统计量设计的主要方法。
最常用的检验统计量是 t 统计量的绝对值
\[ T=\left|T\left(\theta_{0}\right)\right| \]
在哪里
\[ T(\theta)=\frac{\widehat{\theta}-\theta}{s(\widehat{\theta})} \]
是 (7.33) 的 t 统计量,\(\widehat{\theta}\) 是点估计器,\(s(\widehat{\theta})\) 是标准误差。当测试单个系数或实值参数 \(\theta=h(\beta)\) 的假设时,\(T\) 是一个合适的统计量,\(\theta_{0}\) 是假设值。非常典型的是 \(\theta_{0}=0\),因为人们的兴趣集中在系数是否为零,但这并不是唯一的可能性。例如,兴趣可能集中在弹性 \(\theta\) 是否等于 1 ,在这种情况下我们可能希望测试 \(\mathbb{H}_{0}: \theta=1\)。
9.3 I 类错误
对原假设 \(\mathbb{H}_{0}\) 的错误拒绝(当 \(\mathbb{H}_{0}\) 为真时拒绝 \(\mathbb{M}_{0}\))称为 I 类错误。发生 I 类错误的概率称为测试的大小。
\[ \mathbb{P}\left[\text { Reject } \mathbb{H}_{0} \mid \mathbb{H}_{0} \text { true }\right]=\mathbb{P}\left[T>c \mid \mathbb{H}_{0} \text { true }\right] . \]
测试的统一大小是满足 \(\mathbb{H}_{0}\) 的所有数据分布的 (9.4) 的上界。测试构建的主要目标是通过限制测试的规模来限制 I 类错误的发生率。
由于第 7 章中讨论的原因,在典型的计量经济学模型中,估计量和检验统计量的精确抽样分布是未知的,因此我们无法明确计算(9.4)。相反,我们通常依赖渐近近似。假设检验统计量在 \(\mathbb{H}_{0}\) 下呈渐近分布。也就是说,当 \(\mathbb{H}_{0}\) 为 true 时
\[ T \longrightarrow \underset{d}{\xi} \]
作为某些连续分布随机变量 \(\xi\) 的 \(n \rightarrow \infty\)。这并不是一个实质性的限制,因为大多数传统的计量经济学检验都满足(9.5)。让 \(G(u)=\mathbb{P}[\xi \leq u]\) 表示 \(\xi\) 的分布。我们将 \(\xi\) (或 \(G\) )称为渐近零分布。最好设计检验统计量 \(T\),其渐近零分布 \(G\) 已知并且不依赖于未知参数。在这种情况下,我们说 \(T\) 是渐近关键的。
例如,如果检验统计量等于 (9.2) 中的绝对 \(t\)-统计量,那么我们从定理 \(7.11\) 知道,如果 \(\theta=\theta_{0}\) (即零假设成立),则 \(T \underset{d}{\rightarrow}|Z|\) 为 \(n \rightarrow \infty\) 其中 \(Z \sim \mathrm{N}(0,1)\).这意味着\(G(u)=\mathbb{P}[|Z| \leq u]=2 \Phi(u)-1\),标准正态绝对值的分布如(7.34)所示。这种分布不依赖于未知数并且是关键的。
我们将检验的渐近大小定义为 I 类错误的渐近概率:
\[ \lim _{n \rightarrow \infty} \mathbb{P}\left[T>c \mid \mathbb{M}_{0} \text { true }\right]=\mathbb{P}[\xi>c]=1-G(c) . \]
我们看到检验的渐近大小是渐近零分布 \(G\) 和临界值 \(c\) 的简单函数。例如,基于临界值为 \(c\) 的绝对 t 统计量的检验的渐近大小为 \(2(1-\Phi(c))\)。
在假设检验的主流方法中,研究人员预先选择显着性水平 \(\alpha \epsilon\) \((0,1)\),然后选择 \(c\),因此渐近大小不大于 \(\alpha\)。当渐近零分布 \(G\) 至关重要时,我们通过将 \(c\) 设置为等于分布 \(G\) 的 \(1-\alpha\) 分位数来实现这一点。 (如果分布 \(G\) 不是关键分布,则必须使用更复杂的方法。)我们将 \(\alpha \epsilon\) 称为渐近临界值,因为它是从渐近零分布中选择的。例如,由于 \(\alpha \epsilon\),绝对 t 统计量的 \(\alpha \epsilon\) 渐近临界值为 \(\alpha \epsilon\)。正常临界值的计算是在统计软件中以数字方式完成的。例如,在 MATLAB 中,命令为norminv \(\alpha \epsilon\)。
9.4 t 检验
正如我们之前提到的,一维假设 \(\mathbb{H}_{0}: \theta=\theta_{0} \in \mathbb{R}\) 与替代 \(\mathbb{M}_{1}: \theta \neq \theta_{0}\) 的最常见检验是 \(\mathrm{t}\) 统计量的绝对值 (9.3)。我们现在正式陈述它的渐近零分布,这是定理 7.11 的简单应用。
定理 9.1 根据假设 7.2、7.3 和 \(\mathbb{H}_{0}: \theta=\theta_{0} \in \mathbb{R}, T\left(\theta_{0}\right) \underset{d}{\longrightarrow} Z \sim\) \(\mathrm{N}(0,1)\)。对于满足 \(\alpha=2(1-\Phi(c)), \mathbb{P}\left[\left|T\left(\theta_{0}\right)\right|>c \mid \mathbb{H}_{0}\right] \rightarrow \alpha\) 的 \(c\),并且测试“Reject \(\mathbb{H}_{0}\) if \(\left|T\left(\theta_{0}\right)\right|>c\)”具有渐近大小 \(\alpha\)。
定理 9.1 表明渐近临界值可以从正态分布中获取。正如我们对渐近置信区间的讨论(第 7.13 节)一样,临界值也可以从学生 \(t\) 分布中获取,这将是正态回归模型中的精确检验(第 5.12 节)。事实上,\(t\) 临界值是 Stata 等软件包中的默认值。由于学生 \(t\) 分布的临界值(稍微)大于正态分布的临界值,因此学生 \(t\) 临界值会略微降低测试的拒绝概率。在实际应用中,除非样本量非常小,否则差异通常并不重要(在这种情况下,渐近近似也应该受到质疑)。
备择假设 \(\theta \neq \theta_{0}\) 有时被称为“双面”备择。相反,有时我们有兴趣测试片面的替代方案,例如 \(\mathbb{M}_{1}: \theta>\theta_{0}\) 或 \(\mathbb{H}_{1}: \theta<\theta_{0}\)。 \(\theta=\theta_{0}\) 与 \(\theta>\theta_{0}\) 或 \(\theta<\theta_{0}\) 的测试基于带符号的 t 统计量 \(T=T\left(\theta_{0}\right)\)。如果 \(\theta \neq \theta_{0}\)(其中 \(\theta \neq \theta_{0}\) 满足 \(\theta \neq \theta_{0}\)),则拒绝假设 \(\theta=\theta_{0}\),而支持 \(\theta>\theta_{0}\)。 \(\theta \neq \theta_{0}\) 的负值不会被视为反对 \(\theta \neq \theta_{0}\) 的证据,因为小于 \(\theta \neq \theta_{0}\) 的点估计 \(\theta \neq \theta_{0}\) 并不指向 \(\theta \neq \theta_{0}\)。由于临界值取自正态分布的单尾,因此它们小于两侧检验的值。具体来说,渐近 \(\theta \neq \theta_{0}\) 临界值为 \(\theta \neq \theta_{0}\)。因此,如果 \(\mathbb{M}_{1}: \theta>\theta_{0}\),我们拒绝 \(\mathbb{M}_{1}: \theta>\theta_{0}\),而支持 \(\mathbb{M}_{1}: \theta>\theta_{0}\)。
相反,\(\theta=\theta_{0}\) 与 \(\theta<\theta_{0}\) 的测试会拒绝 \(\mathbb{M}_{0}\) 的负 t 统计量,例如如果 \(T<-c\). \(T\) 的大正值并不是 \(\mathbb{H}_{1}: \theta<\theta_{0}\) 的证据。渐近 \(5 %\) 检验会拒绝 \(T<-1.645\)。
似乎有歧义。我们应该使用两侧临界值 \(1.96\) 还是单侧临界值 1.645?答案是大多数情况下双边临界值是合适的。仅当已知参数空间满足单方面限制(例如 \(\theta \geq \theta_{0}\))时,我们才应使用单方面临界值。此时,\(\theta=\theta_{0}\) 与 \(\theta>\theta_{0}\) 的测试才有意义。如果限制 \(\theta \geq \theta_{0}\) 事先未知,那么强加此限制来测试 \(\theta=\theta_{0}\) 与 \(\theta>\theta_{0}\) 是没有意义的。由于线性回归系数通常没有先验符号限制,因此标准惯例是使用两侧临界值。
这似乎与统计教科书中呈现测试的方式相反,统计教科书通常侧重于片面的替代假设。后者主要针对教育学,因为片面的理论问题更清晰、更容易理解。
9.5 II 类错误和功率
对原假设 \(\mathbb{H}_{0}\) 的错误接受(当 \(\mathbb{H}_{1}\) 为真时接受 \(\mathbb{M}_{0}\))称为 II 类错误。备择假设下的拒绝概率称为检验功效,等于 1 减去 II 类错误的概率:
\[ \pi(\theta)=\mathbb{P}\left[\text { Reject } \mathbb{H}_{0} \mid \mathbb{H}_{1} \text { true }\right]=\mathbb{P}\left[T>c \mid \mathbb{M}_{1} \text { true }\right] . \]
我们将 \(\pi(\theta)\) 称为幂函数,并将其写为 \(\theta\) 的函数,以表明其对参数 \(\theta\) 真实值的依赖性。
在假设检验的主要方法中,检验构建的目标是在检验规模低于预先指定的显着性水平的约束下获得高功效。一般来说,检验的功效取决于参数 \(\theta\) 的真实值,对于表现良好的检验,检验功效会随着 \(\theta\) 远离原假设 \(\theta_{0}\) 以及样本大小 $ matheq4$ 增加。
给定世界 \(\left(\mathbb{M}_{0}\right.\) 或 \(\left.\mathbb{H}_{1}\right)\) 的两种可能状态以及两个可能的决策(接受 \(\mathbb{M}_{0}\) 或拒绝 \(\mathbb{M}_{0}\) ),有四种可能的状态和决策配对,如表 9.1 所示。
表 9.1:假设检验决策
| {Accept \(\mathbb{H}_{0}\) | {Reject \(\mathbb{M}_{0}\) | |
|---|---|---|
| \(\mathbb{M}_{0}\) true | Correct Decision | Type I Error |
| \(\mathbb{H}_{1}\) true | Type II Error | Correct Decision |
给定检验统计量 \(T\),增加临界值 \(c\) 会增加接受区域 \(S_{0}\),同时会减少拒绝区域 \(S_{1}\)。这会降低发生 I 类错误的可能性(减小大小),但会增加发生 II 类错误的可能性(降低功效)。因此,\(c\) 的选择涉及大小和功能之间的权衡。这就是为什么检验的显着性水平 \(\alpha\) 不能设置任意小。否则测试将没有有意义的力量。
在解释假设检验时,重要的是要考虑检验的功效,因为过于狭隘地关注规模可能会导致错误的决策。例如,设计一个具有完美尺寸但功能微不足道的测试很容易。具体来说,对于任何假设,我们都可以使用以下测试:生成随机变量 \(U \sim U[0,1]\),如果 \(U<\alpha\),则拒绝 \(\mathbb{M}_{0}\)。该测试的精确大小为 \(\alpha\)。然而,该测试的功效也恰好等于 \(\alpha\)。当测试的功效等于大小时,我们说该测试具有微不足道的功效。从这样的测试中什么也学不到。
9.6 统计学意义
测试需要预先选择显着性水平 \(\alpha\),但选择 \(\alpha\) 没有客观的科学依据。尽管如此,常见的做法是设置 \(\alpha=0.05\) (5%)。替代通用值是 \(\alpha=0.10(10 %)\) 和 \(\alpha=0.01(1 %)\)。这些选择在某种程度上是传统临界值表和统计软件的副产品。
\(5 %\) 临界值背后的非正式推理是为了确保 I 类错误相对不太可能 - “拒绝 \(\mathbb{H}_{0}\)”的决定具有科学实力 - 但测试保留了针对合理替代方案的力量。 “拒绝 \(\mathbb{M}_{0}\)”决策意味着证据与原假设不一致,因为原假设生成的数据产生观察到的检验结果的可能性相对较小(二十分之一)。
相比之下,决定“接受 \(\mathbb{H}_{0}\) ”并不是一个强有力的声明。这并不意味着证据支持\(\mathbb{M}_{0}\),只是说没有足够的证据来拒绝\(\mathbb{M}_{0}\)。因此,使用标签“Do not Reject \(\mathbb{M}_{0}\)”而不是“Accept \(\mathbb{H}_{0}\)”更为准确。
当测试在 \(5 %\) 显着性水平上拒绝 \(\mathbb{M}_{0}\) 时,通常会说该统计量具有统计显着性;如果测试接受 \(\mathbb{M}_{0}\),则通常会说该统计量不具有统计显着性或具有统计显着性微不足道。记住这只是一种简洁的表达方式,“使用统计量 \(T\),假设 \(\mathbb{H}_{0}\) 可以[不能]在渐近 \(5 %\) 水平上被拒绝”,这是有帮助的。此外,当原假设 \(\mathbb{M}_{0}: \theta=0\) 被拒绝时,通常会说系数 \(\theta\) 具有统计显着性,因为检验拒绝了系数等于 0 的假设。
让我们回到表 4.1 中衡量的工会工资溢价的例子。 “男性工会成员”系数的绝对 \(\mathrm{t}\) 统计量为 \(0.095 / 0.020=4.7\),它大于 \(1.96\) 的 \(5 %\) 渐近临界值。因此,我们拒绝工会会员身份不影响男性工资的假设。在这种情况下,我们可以说工会会员资格对于男性来说具有统计意义。然而,“女性工会成员”系数的绝对 t 统计量为 \(0.023 / 0.020=1.2\),小于 \(1.96\),因此我们不拒绝工会成员身份不影响女性工资的假设。在这种情况下,我们发现女性成员资格在统计上并不显着。
当检验接受零假设(当检验不具有统计显着性时)时,常见的误解是,这是零假设为真的证据。这是不正确的。未能拒绝本身并不是证据。如果不进行功效分析,我们不知道犯第二类错误的可能性,因此是不确定的。在我们的工资示例中,如果写成“回归发现女性工会会员资格对工资没有影响”,那是错误的。这是一个不正确且最不幸的解释。该检验未能拒绝系数为零的假设,但这并不意味着系数实际上为零。
当检验拒绝零假设时(当检验具有统计显着性时),它是反对假设的有力证据(因为如果假设为真,则拒绝是不可能发生的事件)。拒绝应被视为反对原假设的证据。然而,我们永远不能得出零假设确实是错误的结论,因为我们不能排除犯第一类错误的可能性。
也许更重要的是,统计意义和经济意义之间存在重要区别。如果我们正确地拒绝假设 \(\mathbb{M}_{0}: \theta=0\),则意味着 \(\theta\) 的真实值不为零。这包括 \(\theta\) 可能不为零但幅度接近于零的可能性。只有当我们在相关模型的上下文中解释参数时,这才有意义。在我们的工资回归示例中,我们可能会将 \(1 %\) 幅度或以下的工资影响视为“接近于零”。在对数工资回归中,这对应于系数小于 \(0.01\) 的虚拟变量。如果标准误差足够小(小于 \(0.005\) ),则 \(0.01\) 的系数估计将具有统计显着性,但在经济上并不显着。这种情况经常发生在样本量非常大且标准误差可能非常小的应用中。
解决方案是尽可能关注置信区间和系数的经济意义。例如,如果系数估计值为 \(0.005\),标准误差为 \(0.002\),则 \(95 %\) 置信区间将为 \([0.001,0.009]\),表明真实效果可能在 \(0 %\) 和 \(1 %\) 之间,因此为稍微积极但很小。这比“效果在统计上是积极的”这一误导性陈述提供了更多信息。
9.7 P 值
继续表 4.1 中报告的工资回归估计,考虑另一个问题:婚姻状况是否影响工资?为了检验婚姻状况对工资没有影响的假设,我们检查表 4.1 中“已婚男性”和“已婚女性”系数的 t 统计量,分别为 \(0.211 / 0.010=22\) 和 \(0.016 / 0.010=1.7\)。第一个超过了 \(1.96\) 的渐近 \(5 %\) 临界值,因此我们拒绝针对男性的假设。第二个比 \(1.96\) 小,所以我们无法拒绝女性的假设。再看一下统计数据,我们发现男性的统计数据 (22) 非常高,而女性的统计数据 (1.7) 仅略低于临界值。假设女性的 \(\mathrm{t}\) 统计数据稍微增加到 2.0。这大于临界值,因此会导致决策“拒绝 \(\mathbb{M}_{0}\) ”而不是“接受 \(\mathbb{M}_{0}\) ”。如果 \(\mathrm{t}\) 统计量是 \(0.211 / 0.010=22\) 而不是 1.7,我们真的应该做出不同的决定吗?价值观的差异很小,决策的差异不应该也很小吗?通过这些例子思考,简单地报告“接受 \(0.211 / 0.010=22\) ”或“拒绝 \(0.211 / 0.010=22\) ”似乎并不令人满意。这两项判决并未总结证据。相反,统计数据 \(0.211 / 0.010=22\) 的大小表明了针对 \(0.211 / 0.010=22\) 的“证据程度”。我们如何考虑这一点?
答案是报告所谓的渐近 p 值
\[ p=1-G(T) . \]
由于分布函数 \(G\) 是单调递增的,因此 p 值是 \(T\) 的单调递减函数,并且是等效的检验统计量。我们可以拒绝 \(\mathbb{M}_{0}\) if \(p<\alpha\),而不是在显着性水平 \(\alpha\) if \(T>c\) 上拒绝 \(\mathbb{R}_{0}\)。因此,报告 \(p\) 就足够了,让读者决定。实际上,p 值是通过数值计算的。例如,在 MATLAB 中,命令为 \(2 *(1-\operatorname{normal} c d f(\mathrm{abs}(\mathrm{t})))\)。
将 \(p\) 解释为边际显着性水平是有启发性的:\(\alpha\) 的最小值,检验 \(T\) 会“拒绝”原假设。也就是说,\(p=0.11\) 意味着 \(T\) 对于大于 \(0.11\) 的所有显着性水平拒绝 \(\mathbb{H}_{0}\),但对于小于 \(0.11\) 的显着性水平则无法拒绝 \(\mathbb{M}_{0}\)。
此外,渐近 p 值具有非常方便的渐近零分布。由于 \(T-\vec{d}\) \(\xi\) 在 \(\mathbb{M}_{0}\) 下,因此 \(p=1-G(T) \underset{d}{\longrightarrow} 1-G(\xi)\) 具有分布
\[ \begin{aligned} \mathbb{P}[1-G(\xi) \leq u] &=\mathbb{P}[1-u \leq G(\xi)] \\ &=1-\mathbb{P}\left[\xi \leq G^{-1}(1-u)\right] \\ &=1-G\left(G^{-1}(1-u)\right) \\ &=1-(1-u) \\ &=u, \end{aligned} \]
这是 \([0,1]\) 上的均匀分布。 (此计算假设 \(G(u)\) 严格递增,这对于常规渐近分布(例如正态分布)来说是正确的。)因此 \(p \underset{d}{\longrightarrow} U[0,1]\)。这意味着 \(p\) 的“异常”比 \(T\) 的“异常”更容易解释。
一个重要的警告是,\(\mathrm{p}\) 值 \(p\) 不应被解释为任一假设为真的概率。一个常见的误解是 \(p\) 是“原假设为真”的概率。这是不正确的。相反,\(p\) 是边际显着性水平 - 针对原假设的信息强度的度量。对于 t 统计量,p 值可以使用正态分布或学生 \(t\) 分布来计算,后者在第 5.12 节中介绍。使用学生 \(t\) 计算的 p 值会稍大,但当样本量较大时差异较小。
回到我们的实证示例,对于“已婚男性”的系数为零的检验,p 值为 \(0.000\)。这意味着当系数的真实值为零时,几乎不可能观察到大至 22 的 t 统计量。当提供此类证据时,我们可以说我们“强烈拒绝”原假设,检验“高度显着”,或者“检验拒绝任何传统的临界值”。相反,“已婚女性”系数的 p 值为 \(0.094\)。在这种情况下,通常会说检验“接近显着”,这意味着 p 值大于 \(0.05\),但不会大太多。
一种相关但较差的经验实践是将星号 \((*)\) 附加到系数估计或检验统计量以指示显着性水平。通常的做法是为超过 \(10 %\) 临界值(即在 \(10 %\) 水平上显着)的估计或检验统计量附加一个星号 (\textit{),为超过 \(5 %\) 临界值的测试,并为超过 \(1 %\) 临界值的测试附加三个星号 (**})。这种做法比原始测试统计表更好,因为星号可以快速解释显着性。另一方面,星号不如 p 值,后者也易于快速解释。目标本质上是相同的;明智的做法是尽可能报告 p 值并避免使用星号。
我们的建议是,最佳经验实践是计算并报告渐近 p 值 \(p\),而不是简单地测试统计量 \(T\)、二元决策接受/拒绝或附加星号。 p 值是一个简单的统计量,易于解释,并且比其他选择包含更多信息。
我们现在总结假设检验的主要特征。
选择显着性水平 \(\alpha\)。
选择 \(\mathbb{H}_{0}\) 下具有渐近分布 \(T \underset{d}{\rightarrow} \xi\) 的检验统计量 \(T\)。
设置渐近临界值\(c\),使得\(1-G(c)=\alpha\),其中\(G\) 是\(\xi\) 的分布函数。
计算渐近 p 值 \(p=1-G(T)\)。
如果 \(T>c\) 则拒绝 \(\mathbb{R}_{0}\),或者等效地 \(p<\alpha\)。
如果 \(T \leq c\) 则接受 \(\mathbb{H}_{0}\),或等效的 \(p \geq \alpha\)。
报告\(p\),总结有关\(\mathbb{M}_{0}\) 与\(\mathbb{M}_{1}\) 的证据。
9.8 t 比率和滥用测试
在 \(4.19\) 节中,我们认为一个好的应用实践是报告估计模型中所有感兴趣系数的系数估计值 \(\widehat{\theta}\) 和标准误差 \(s(\widehat{\theta})\)。通过 \(\widehat{\theta}\) 和 \(s(\widehat{\theta})\),读者可以轻松地为感兴趣的假设构建置信区间 \([\widehat{\theta} \pm 2 s(\widehat{\theta})]\) 和 t 统计量 \(\left(\widehat{\theta}-\theta_{0}\right) / s(\widehat{\theta})\)。
一些应用论文(尤其是较旧的论文)报告 t 比率 \(T=\widehat{\theta} / s(\widehat{\theta})\) 而不是标准误差。这是糟糕的计量经济学实践。虽然报告了相同的信息(您可以按除法返回标准误差,例如 \(s(\widehat{\theta})=\widehat{\theta} / T)\),但标准误差通常比 t 比率对读者更有帮助。标准误差帮助读者关注估计精度和置信区间,而t 比率将注意力集中在统计显着性上。虽然统计显着性很重要,但参数估计本身及其置信区间不太重要。重点应放在参数估计的含义、其大小及其解释上,而不是列出哪些变量具有显着(例如非零)系数。在许多现代应用中,样本量非常大,因此标准误差可能非常小。因此,即使系数估计值在经济上很小,t 比也可能很大。在这种情况下,宣布“系数非零!”可能并不有趣,相反,有趣的是宣布“系数估计在经济上很有趣!”
特别是,一些应用论文报告了系数估计值和 t 比率,并将结果讨论限制为描述哪些变量是“显着的”(意味着它们的 t 比率超过 2)以及系数估计值的符号。这是非常糟糕的实证工作,应该刻意避免。这也是导致你的作品被低级经济学期刊驱逐的原因之一。
从根本上说,共同 t 比率是对系数等于 0 的假设的检验。当这是一个有趣的经济假设时,应该报告和讨论这一点。但如果情况并非如此,那就会分散注意力。
一个问题是标准软件包(例如 Stata)默认报告每个估计系数的 t 统计量和 p 值。虽然这可能很有用(因为用户不需要明确要求测试所需的系数),但它可能会产生误导,因为它可能无意中表明 t 统计量和 p 值的整个列表很重要。相反,用户应该专注于对科学假设的测试。
一般来说,当对系数 \(\theta\) 感兴趣时,关注点估计、其标准误差及其置信区间是有建设性的。点估计给出了我们对该值的“最佳猜测”。标准误差是精度的衡量标准。置信区间为我们提供了与数据一致的值范围。如果标准误差很大,那么点估计就不是关于 \(\theta\) 的一个很好的总结。置信区间的端点描述了可能可能性的界限。如果置信区间包含的 \(\theta\) 值太宽泛,则数据集的信息不足以提供有关 \(\theta\) 的有用推论。另一方面,如果置信区间很紧,那么数据就产生了准确的估计,重点应该放在该估计的值和解释上。相比之下,“t 比率非常显着”这一说法几乎没有解释价值。
上述讨论要求研究人员知道系数 \(\theta\) 的含义(就经济问题而言),并且能够解释值和大小,而不仅仅是符号。这对于良好的应用计量经济学实践至关重要。
例如,考虑有关婚姻状况对平均对数工资的影响的问题。我们发现,这种影响对于男性来说“非常显着”,对于女性来说“接近显着”。现在,让我们为系数构建渐近 \(95 %\) 置信区间。男性的为 \([0.19,0.23]\),女性的为 \([-0.00,0.03]\)。这表明,已婚男性的平均工资比未婚男性高出约\(19-23 %\),这是相当大的,而女性的差异约为0-3%,这是很小的。这些幅度比假设检验的结果提供更多信息。
9.9 瓦尔德测试
当原假设是实值限制时,t 检验适用。更一般地,系数向量 \(\beta\) 可能有多个限制。假设我们有 \(q>1\) 限制,可以写成 (9.1) 的形式。通过插件估计器 \(\widehat{\theta}=r(\widehat{\beta})\) 来估计 \(\theta=r(\beta)\) 是很自然的。要测试 \(\mathbb{H}_{0}: \theta=\theta_{0}\) 与 \(\mathbb{H}_{1}: \theta \neq \theta_{0}\) 的一种方法是测量 \(\widehat{\theta}-\theta_{0}\) 差异的大小。由于这是一个向量,因此有不止一种长度度量。一种简单的测量方法是加权二次形式,称为 Wald 统计量。这是在原假设下评估的 (7.37)
\[ W=W\left(\theta_{0}\right)=\left(\widehat{\theta}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\theta}}^{-1}\left(\widehat{\theta}-\theta_{0}\right) \]
其中 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}=\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}} \widehat{\boldsymbol{R}}\) 是 \(\boldsymbol{V}_{\widehat{\theta}}\) 和 \(\widehat{\boldsymbol{R}}=\frac{\partial}{\partial \beta} r(\widehat{\beta})^{\prime}\) 的估计器。请注意,我们可以将 \(W\) 写为
\[ W=n\left(\widehat{\theta}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{V}}_{\theta}^{-1}\left(\widehat{\theta}-\theta_{0}\right) \]
使用渐近方差估计器 \(\widehat{\boldsymbol{V}}_{\theta}\),或者我们可以直接将其写为 \(\widehat{\beta}\) 的函数:
\[ W=\left(r(\widehat{\beta})-\theta_{0}\right)^{\prime}\left(\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}} \widehat{\boldsymbol{R}}\right)^{-1}\left(r(\widehat{\beta})-\theta_{0}\right) . \]
此外,当 \(r(\beta)=\boldsymbol{R}^{\prime} \beta\) 是 \(\beta\) 的线性函数时,Wald 统计量简化为
\[ W=\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right)^{\prime}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) . \]
Wald 统计量 \(W\) 是向量 \(\widehat{\theta}-\theta_{0}\) 长度的加权欧几里得度量。当 \(q=1\) 然后 \(W=T^{2}\) 时,即 t 统计量的平方,因此基于 \(W\) 和 \(|T|\) 的假设检验是等效的。 Wald 统计量 (9.6) 是 t 统计量对多重限制情况的推广。由于 Wald 统计量在参数 \(\widehat{\theta}-\theta_{0}\) 中是对称的,因此它对称地对待正和负替代项。因此,固有的选择总是有两面性的。
如定理 7.13 所示,当 \(\beta\) 满足 \(r(\beta)=\theta_{0}\) 时,则 \(W \underset{d}{\rightarrow} \chi_{q}^{2}\) 为具有 \(q\) 自由度的卡方随机变量。让 \(G_{q}(u)\) 表示 \(\chi_{q}^{2}\) 分布函数。对于给定的显着性水平 \(\alpha\),渐近临界值 \(c\) 满足 \(\alpha=1-G_{q}(c)\)。例如,\(\beta\) 和 \(\beta\) 的 \(\beta\) 临界值分别为 \(\beta\) 和 \(\beta\),一般来说,\(\beta\) 级别的临界值可以在 MATLAB 中计算为 chi2inv \(\beta\) 。如果 \(\beta\),则渐近检验会拒绝 \(\beta\) 而支持 \(\beta\)。与 t 检验一样,如果 \(r(\beta)=\theta_{0}\) 超过 \(r(\beta)=\theta_{0}\) 渐近临界值,则通常将 Wald 检验描述为“显着”。
定理 9.2 根据假设 7.2、7.3、7.4 和 \(\mathbb{M}_{0}: \theta=\theta_{0} \in \mathbb{R}^{q}\),然后 \(W \vec{d}\) \(\chi_{q}^{2}\)。对于 \(c\) 满足 \(\alpha=1-G_{q}(c), \mathbb{P}\left(W>c \mid \mathbb{H}_{0}\right) \longrightarrow \alpha\),因此测试“Reject \(\mathbb{H}_{0}\) if \(W>c\)”具有渐近大小 \(\alpha\)。
请注意,定理 \(9.2\) 中的渐近分布仅取决于 \(q\),即正在测试的限制数量。它不依赖于估计的参数数量 \(k\)。
\(W\) 的渐近 p 值为 \(p=1-G_{q}(W)\),这在测试多个限制时特别有用。例如,如果您编写对八个限制 ( \(q=8\) ) 的 Wald 检验的值为 \(W=\) \(11.2\) ,则读者很难评估此统计量的大小,除非他们可以快速访问统计表或软件。相反,如果您写 p 值为 \(p=0.19\) (与 \(W=11.2\) 和 \(q=8\) 的情况相同),那么读者很容易将其大小解释为“微不足道”。要在 MATLAB 中计算 Wald 统计量的渐近 p 值,请使用命令 \(1-\operatorname{ch} i 2 c d f(w, q)\)。
一些软件包(包括 Stata)和论文报告 Wald 统计数据的 \(F\) 版本。对于任何测试 \(q\) 维限制的 Wald 统计量 \(W\),测试的 \(F\) 版本为
\[ F=W / q . \]
当报告 \(F\) 时,通常使用 \(F_{q, n-k}\) 临界值和 \(\mathrm{p}\) 值,而不是 \(\chi_{q}^{2}\) 值。 Wald 和 F 统计量之间的联系在 \(9.14\) 节中进行了演示,其中我们表明,当使用同方差协方差矩阵计算 Wald 统计量时,\(F=W / q\) 与 (5.19) 的 F 统计量相同。虽然没有正式理由对非同方差协方差矩阵使用 \(F_{q, n-k}\) 分布,但 \(F_{q, n-k}\) 分布在正态性下提供了与精确分布理论的连续性,并且比 \(\chi_{q}^{2}\) 分布更为保守。 (此外,当 \(F\) 适度大时,差异很小。)
要在 Stata 中实现零限制检验,一种简单的方法是使用命令 test X1 X2,其中 X1 和 X2 是假设系数为零的变量的名称。 Wald 统计量的 \(F\) 版本是使用回归命令中指定的方法计算出的协方差矩阵来报告的。报告 p 值,使用 \(F_{q, n-k}\) 分布计算。
为了说明这一点,请考虑表 4.1 中给出的实证结果。 “工会会员身份不影响工资”的假设是“男性工会会员”和“女性工会会员”的系数均为零的联合限制。我们计算该联合假设的 Wald 统计量,并找到 p 值为 \(p=0.000\) 的 \(W=23\) (或 \(F=12.5\) )。因此,我们拒绝原假设,转而支持至少一个系数非零的替代方案。这并不意味着两个系数都不为零,只是两个系数之一不为零。因此,检查联合 Wald 统计量和个体 t 统计量对于解释很有用。
作为同一回归的第二个例子,假设婚姻状况对女性的平均工资没有影响。这就是“已婚女性”和“已婚女性”系数为零的联合限制。该假设的 Wald 统计量为 \(W=6.4(F=3.2)\),p 值为 \(0.04\)。这样的 p 值通常被称为“边际显着”,因为它略小于 \(0.05\)。
Wald 统计量由 Wald (1943) 提出。

9.10 同方差 Wald 检验
如果已知误差是同方差的,则适合使用同方差 Wald 统计量 (7.38),该统计量将 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}\) 替换为同方差估计量 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{0}\)。这个统计量等于
\[ \begin{aligned} W^{0} &=\left(\widehat{\theta}-\theta_{0}\right)^{\prime}\left(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{0}\right)^{-1}\left(\widehat{\theta}-\theta_{0}\right) \\ &=\left(r(\widehat{\beta})-\theta_{0}\right)^{\prime}\left(\boldsymbol{R}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \widehat{\boldsymbol{R}}\right)^{-1}\left(r(\widehat{\beta})-\theta_{0}\right) / s^{2} . \end{aligned} \]
在线性假设 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}\) 的情况下,我们可以将其写为
\[ W^{0}=\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right)^{\prime}\left(\boldsymbol{R}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) / s^{2} . \]
我们将 \(W^{0}\) 称为同方差 Wald 统计量,因为当误差是条件同方差时它是合适的。
当 \(q=1\) 然后 \(W^{0}=T^{2}\) 时,t 统计量的平方,其中后者是使用同方差标准误差计算的。定理 9.3 假设 \(7.2\) 和 7.3、\(\mathbb{E}\left[e^{2} \mid X\right]=\sigma^{2}>0\) 和 \(\mathbb{M}_{0}: \theta=\)、\(\theta_{0} \in \mathbb{R}^{q}\),然后是 \(W^{0} \underset{d}{\longrightarrow} \chi_{q}^{2}\)。对于 \(c\) 满足 \(\alpha=1-G_{q}(c), \mathbb{P}\left[W^{0}>c \mid \mathbb{H}_{0}\right] \longrightarrow \alpha\),因此测试“Reject \(q=1\) if \(q=1\)”具有渐近大小 \(q=1\)。
9.11 基于标准的测试
Wald 统计量基于向量 \(\widehat{\theta}-\theta_{0}\) 的长度:估计器 \(\widehat{\theta}=r(\widehat{\beta})\) 与假设值 \(\theta_{0}\) 之间的差异。另一类测试是基于在有限制和没有限制的情况下最小化准则函数之间的差异。
当我们有一个标准函数时,基于标准的测试适用,比如 \(J(\beta)\) 和 \(\beta \in B\),它被最小化以进行估计,并且目标是测试 \(\mathbb{M}_{0}: \beta \in B_{0}\) 与 \(\mathbb{M}_{1}: \beta \notin B_{0}\)(其中 \(B_{0} \subset \beta\))。最小化 \(B\) 和 \(B_{0}\) 上的准则函数,我们获得无限制和受限制的估计量
\[ \begin{aligned} &\widehat{\beta}=\underset{\beta \in B}{\operatorname{argmin}} J(\beta) \\ &\widetilde{\beta}=\underset{\beta \in B_{0}}{\operatorname{argmin}} J(\beta) . \end{aligned} \]
\(\mathbb{H}_{0}\) 与 \(\mathbb{H}_{1}\) 的基于标准的统计量与
\[ J=\min _{\beta \in B_{0}} J(\beta)-\min _{\beta \in B} J(\beta)=J(\widetilde{\beta})-J(\widehat{\beta}) . \]
基于标准的统计量 \(J\) 有时称为距离统计量、最小距离统计量或类似似然比的统计量。
由于 \(B_{0}\) 是 \(B, J(\widetilde{\beta}) \geq J(\widehat{\beta})\) 的子集,因此 \(J \geq 0\) 也是如此。统计量 \(J\) 根据施加空限制 \(\beta \in B_{0}\) 的标准来衡量成本。
9.12 最短距离测试
最小距离测试基于最小距离标准(8.19)
\[ J(\beta)=n(\widehat{\beta}-\beta)^{\prime} \widehat{\boldsymbol{W}}(\widehat{\beta}-\beta) \]
使用 \(\widehat{\beta}\) 无限制最小二乘估计器。受限估计器 \(\widetilde{\beta}_{\text {md }}\) 在 \(\beta \in B_{0}\) 的约束下最小化 (9.8)。观察 \(J(\widehat{\beta})=0\),最小距离统计量简化为
\[ J=J\left(\widetilde{\beta}_{\mathrm{md}}\right)=n\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{md}}\right)^{\prime} \widehat{\boldsymbol{W}}\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{md}}\right) . \]
通过设置(9.8)和(9.9)中的\(\widehat{\boldsymbol{W}}=\widehat{\boldsymbol{V}}_{\beta}^{-1}\)获得有效的最小距离估计器\(\widetilde{\beta}_{\mathrm{emd}}\)。因此 \(\mathbb{H}_{0}: \beta \in B_{0}\) 的有效最小距离统计量为
\[ J^{*}=n\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{emd}}\right)^{\prime} \widehat{\boldsymbol{V}}_{\beta}^{-1}\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{emd}}\right) . \]
考虑线性假设 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}\) 类。在这种情况下,我们从(8.25)知道,受约束\(\boldsymbol{R}^{\prime} \beta=\theta_{0}\)的有效最小距离估计器\(\widetilde{\beta}_{\mathrm{emd}}\)是
\[ \widetilde{\beta}_{\mathrm{emd}}=\widehat{\beta}-\widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) \]
因此
\[ \widehat{\beta}-\widetilde{\beta}_{\mathrm{emd}}=\widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) . \]
代入(9.10)我们发现
\[ \begin{aligned} J^{*} &=n\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right)^{\prime}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\right)^{-1} \boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{V}}_{\boldsymbol{\beta}}^{-1} \widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) \\ &=n\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right)^{\prime}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) \\ &=W, \end{aligned} \]
这是 Wald 统计量 (9.6)。
因此,对于线性假设 \(\mathbb{H}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}\),有效最小距离统计量 \(J^{*}\) 与 Wald 统计量 (9.6) 相同。然而,对于非线性假设,Wald 和最小距离统计量是不同的。
Newey 和 West (1987a) 建立了 \(J^{*}\) 的渐近零分布。
定理 9.4 假设 \(7.2,7.3,7.4\) 和 \(\mathbb{H}_{0}: \theta=\theta_{0} \in \mathbb{R}^{q}, J^{*} \underset{d}{\longrightarrow} \chi_{q}^{2}\)。
使用最小距离统计量 \(J^{*}\) 进行的测试与使用 Wald 统计量 \(W\) 进行的测试类似。临界值和 p 值是使用 \(\chi_{q}^{2}\) 分布计算的。如果 \(J^{*}\) 超过 \(\alpha\) 临界值(可以在 MATLAB 中计算为 chi2inv \((1-\alpha, q)\)),则拒绝 \(\mathbb{H}_{0}\),而使用 \(\mathbb{H}_{1}\)。渐近 p 值为 \(p=1-G_{q}\left(J^{*}\right)\)。在 MATLAB 中,使用命令 \(J^{*}\)。
我们现在证明定理 9.4。定理 \(8.10\) 的条件成立,因为 \(\mathbb{H}_{0}\) 隐含假设 8.1。从 (8.54) 和 \(\widehat{\boldsymbol{W}}=\widehat{\boldsymbol{V}}_{\beta}\) 可以看出
\[ \begin{aligned} \sqrt{n}\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{emd}}\right) &=\widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\left(\boldsymbol{R}_{n}^{* \prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\right)^{-1} \boldsymbol{R}_{n}^{* \prime} \sqrt{n}(\widehat{\beta}-\beta) \\ & \underset{d}{\longrightarrow} \boldsymbol{V}_{\beta} \boldsymbol{R}\left(\boldsymbol{R}^{\prime} \boldsymbol{V}_{\beta} \boldsymbol{R}\right)^{-1} \boldsymbol{R}^{\prime} \mathrm{N}\left(0, \boldsymbol{V}_{\beta}\right)=\boldsymbol{V}_{\beta} \boldsymbol{R} Z \end{aligned} \]
其中 \(Z \sim \mathrm{N}\left(0,\left(\boldsymbol{R}^{\prime} \boldsymbol{V}_{\beta} \boldsymbol{R}\right)^{-1}\right)\).因此
\[ J^{*}=n\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{emd}}\right)^{\prime} \widehat{\boldsymbol{V}}_{\beta}^{-1}\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{emd}}\right) \underset{d}{\longrightarrow} Z^{\prime} \boldsymbol{R}^{\prime} \boldsymbol{V}_{\beta} \boldsymbol{V}_{\beta}^{-1} \boldsymbol{V}_{\beta} \boldsymbol{R} Z=Z^{\prime}\left(\boldsymbol{R}^{\prime} \boldsymbol{V}_{\beta} \boldsymbol{R}\right) Z=\chi_{q}^{2} \]
正如所声称的那样。
9.13 同方差下的最小距离检验
如果我们在(9.8)中设置\(\widehat{\boldsymbol{W}}=\widehat{\boldsymbol{Q}}_{X X} / s^{2}\),我们得到标准(8.20)
\[ J^{0}(\beta)=n(\widehat{\beta}-\beta)^{\prime} \widehat{\boldsymbol{Q}}_{X X}(\widehat{\beta}-\beta) / s^{2} . \]
\(\mathbb{\Perp}_{0}: \beta \in B_{0}\) 的最小距离统计量为
\[ J^{0}=\min _{\beta \in B_{0}} J^{0}(\beta) . \]
方程(8.21)表明\(\operatorname{SSE}(\beta)=n \widehat{\sigma}^{2}+s^{2} J^{0}(\beta)\)。因此 \(\operatorname{SSE}(\beta)\) 和 \(J^{0}(\beta)\) 的最小化器是相同的。因此 \(J^{0}(\beta)\) 的约束最小化器是约束最小二乘
\[ \widetilde{\beta}_{\text {cls }}=\underset{\beta \in B_{0}}{\operatorname{argmin}} J^{0}(\beta)=\underset{\beta \in B_{0}}{\operatorname{argmin}} \operatorname{SSE}(\beta) \]
因此
\[ J_{n}^{0}=J_{n}^{0}\left(\widetilde{\beta}_{\mathrm{cls}}\right)=n\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{cls}}\right)^{\prime} \widehat{\boldsymbol{Q}}_{X X}\left(\widehat{\beta}-\widetilde{\beta}_{\mathrm{cls}}\right) / s^{2} . \]
在线性假设 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}\) 的特殊情况下,受 \(\boldsymbol{R}^{\prime} \beta=\theta_{0}\) 约束的约束最小二乘估计器具有解 (8.9)
\[ \widetilde{\beta}_{\mathrm{cls}}=\widehat{\beta}-\widehat{\boldsymbol{Q}}_{X X}^{-1} \boldsymbol{R}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{Q}}_{X X}^{-1} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) \]
并解决我们发现
\[ J^{0}=n\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right)^{\prime}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{Q}}_{X X}^{-1} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\theta_{0}\right) / s^{2}=W^{0} . \]
这是同方差 Wald 统计量 (9.7)。因此,对于检验线性假设,同方差最小距离和 Wald 统计是一致的。
对于非线性假设,它们不一致,但具有相同的零渐近分布。
定理 9.5 假设 \(7.2\) 和 \(7.3, \mathbb{E}\left[e^{2} \mid X\right]=\sigma^{2}>0\),以及 \(\mathbb{M}_{0}: \theta=\) \(\theta_{0} \in \mathbb{R}^{q}\),然后 \(J^{0} \underset{d}{\longrightarrow} \chi_{q}^{2}\)
9.14 F 测试
在 \(5.13\) 节中,我们介绍了正态回归模型中排除限制的 \(F\) 检验。在本节中,我们将此测试推广到更广泛的限制。令 \(B_{0} \subset \mathbb{R}^{k}\) 为约束参数空间,它对 \(\beta\) 施加 \(q\) 限制。
令 \(\widehat{\beta}_{\text {ols }}\) 为无限制最小二乘估计量,让 \(\widehat{\sigma}^{2}=n^{-1} \sum_{i=1}^{n}\left(Y_{i}-X_{i}^{\prime} \widehat{\beta}_{\text {ols }}\right)^{2}\) 为 \(\sigma^{2}\) 的关联估计量。令 \(\widetilde{\beta}_{\text {cls }}\) 为满足 \(\widetilde{\beta}_{\text {cls }} \in B_{0}\) 的 CLS 估计器 (9.11),令 \(\widetilde{\sigma}^{2}=n^{-1} \sum_{i=1}^{n}\left(Y_{i}-X_{i}^{\prime} \widetilde{\beta}_{\text {cls }}\right)^{2}\) 为 \(\sigma^{2}\) 的关联估计器。用于测试 \(\mathbb{M}_{0}: \beta \in B_{0}\) 的 \(F\) 统计量为
\[ F=\frac{\left(\tilde{\sigma}^{2}-\widehat{\sigma}^{2}\right) / q}{\widehat{\sigma}^{2} /(n-k)} . \]
我们也可以写
\[ F=\frac{\operatorname{SSE}\left(\widetilde{\beta}_{\mathrm{cls}}\right)-\operatorname{SSE}\left(\widehat{\beta}_{\mathrm{ols}}\right)}{q s^{2}} \]
其中 \(\operatorname{SSE}(\beta)=\sum_{i=1}^{n}\left(Y_{i}-X_{i}^{\prime} \beta\right)^{2}\) 是误差平方和。
这表明 \(F\) 是基于标准的统计量。使用(8.21),我们还可以写成\(F=J^{0} / q\),因此\(F\)统计量与同方差最小距离统计量除以限制数\(q\)相同。
正如我们在上一节中讨论的,在线性假设 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}, J^{0}=\) \(W^{0}\) 的特殊情况下。由此可见,在本例中为 \(F=W^{0} / q\)。因此,对于线性限制,\(F\) 统计量等于同方差 Wald 统计量除以 \(q\)。由此可见,它们是 \(\mathbb{H}_{0}\) 与 \(\mathbb{H}_{1}\) 的等效测试。定理 9.6 对于线性假设 \(\mathbb{H}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0} \in \mathbb{R}^{q}\) 的检验,\(\mathrm{F}\) 统计量等于 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}, J^{0}=\),其中 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}, J^{0}=\) 是同方差 Wald 统计量。因此,在 7.2 下,\(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}, J^{0}=\) 和 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}, J^{0}=\),然后是 \(\mathbb{M}_{0}: \boldsymbol{R}^{\prime} \beta=\theta_{0}, J^{0}=\)。
使用 \(F\) 统计量时,通常使用 \(F_{q, n-k}\) 分布来表示临界值和 p 值。在 MATLAB 中,临界值由 \(f\) inv \((1-\alpha, q, n-k)\) 给出,\(p\) 值由 \(1-f c d f(F, q, n-k)\) 给出。或者,可以使用 \(\chi_{q}^{2} / q\) 分布,分别使用 chi2inv \((1-\alpha, q) / q\) 和 \(1-\operatorname{chi} 2 c d f(F * q, q)\)。使用 \(F\) 分布是一种谨慎的小样本调整,如果误差是正态的,则可以产生准确的答案,否则相对于渐近近似会稍微增加临界值和 p 值。再说一遍,如果样本量足够小,以至于选择会产生影响,那么我们可能无论如何都不应该相信渐近近似!
(9.12) 或 (9.13) 的一个优雅特征是它们可以直接从两个简单 OLS 回归的标准输出计算,因为平方误差之和(或回归方差)是统计包的典型打印输出,并且经常报告在应用表中。因此,即使您没有原始数据(或者如果您坐在研讨会上听演示!),也可以根据标准报告的统计数据手动计算 \(F\)。
如果您看到 \(F\) 统计量(或 Wald 统计量,因为您可以除以 \(q\) )但无法访问临界值,则一个有用的经验法则是知道对于较大的 \(n\) \(5 %\) 渐近临界值随着 \(q\) 的增加而减小,并且 \(q \geq 7\) 小于 2。
警告:在许多统计软件包中,当估计 OLS 回归时,即使没有要求假设检验,也会自动报告“F 统计量”。该包报告的是假设所有斜率系数 \({ }^{1}\) 为零的 \(F\) 统计数据。这是计量经济学报告早期流行的统计数据,当时样本量非常小,研究人员想知道他们的回归是否有“任何解释力”。如今,这很少成为问题,因为样本量通常足够大,因此 \(F\) 统计数据几乎总是非常显着。虽然在某些特殊情况下 \(F\) 统计数据很有用,但这些情况并不典型。作为一般规则,没有理由报告此 \(F\) 统计数据。
9.15 豪斯曼检验
Hausman (1978) 介绍了如何检验假设 \(\mathbb{M}_{0}\) 的一般想法。如果您有两个估计器,一个在 \(\mathbb{M}_{0}\) 下有效,但在 \(\mathbb{H}_{1}\) 下不一致,另一个在 \(\mathbb{H}_{1}\) 下一致,则将估计器的差异构造为二次形式的检验。在测试假设 \(\mathbb{M}_{0}: r(\beta)=\theta_{0}\) 的情况下,让 \(\widehat{\beta}_{\text {ols }}\) 表示无约束最小二乘估计器,让 \(\widetilde{\beta}_{\text {emd }}\) 表示施加 \(r(\beta)=\theta_{0}\) 的有效最小距离估计器。两个估计量在 \(\mathbb{M}_{0}\) 下是一致的,但 \(\mathbb{M}_{0}\) 是渐近有效的。在 \(\mathbb{M}_{0}\) 下与 \(\mathbb{M}_{0}\) 一致,但 \(\mathbb{M}_{0}\) 不一致。差异具有渐近分布
\[ \sqrt{n}\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right) \underset{d}{\longrightarrow} \mathrm{N}\left(0, \boldsymbol{V}_{\beta} \boldsymbol{R}\left(\boldsymbol{R}^{\prime} \boldsymbol{V}_{\beta} \boldsymbol{R}\right)^{-1} \boldsymbol{R}^{\prime} \boldsymbol{V}_{\beta}\right) . \]
让 \(\boldsymbol{A}^{-}\) 表示 Moore-Penrose 广义逆。 \(\mathbb{H}_{0}\) 的豪斯曼统计量为
\[ \begin{aligned} & H=\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right)^{\prime} \widehat{\operatorname{avar}}\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right)^{-}\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right) \\ & =n\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right)^{\prime}\left(\widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\left(\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\right)^{-1} \widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta}\right)^{-}\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right) . \end{aligned} \]
\({ }^{1}\) 除截距外的所有系数。矩阵 \(\widehat{\boldsymbol{V}}_{\beta}^{1 / 2} \widehat{\boldsymbol{R}}\left(\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\right)^{-1} \widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta}^{1 / 2}\) 幂等,因此它的广义逆是它本身。 (参见 A.11 节。)由此可见
\[ \begin{aligned} & =\widehat{\boldsymbol{V}}_{\beta}^{-1 / 2} \widehat{\boldsymbol{V}}_{\beta}^{1 / 2} \widehat{\boldsymbol{R}}\left(\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\right)^{-1} \widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta}^{1 / 2} \widehat{\boldsymbol{V}}_{\beta}^{-1 / 2} \\ & =\widehat{\boldsymbol{R}}\left(\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\right)^{-1} \widehat{\boldsymbol{R}}^{\prime} . \end{aligned} \]
因此豪斯曼统计量是
\[ H=n\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right)^{\prime} \widehat{\boldsymbol{R}}\left(\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\right)^{-1} \widehat{\boldsymbol{R}}^{\prime}\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right) . \]
在线性限制的情况下,\(\widehat{\boldsymbol{R}}=\boldsymbol{R}\) 和 \(\boldsymbol{R}^{\prime} \widetilde{\beta}=\theta_{0}\) 因此统计量采用以下形式
\[ H=n\left(\boldsymbol{R}^{\prime} \widehat{\beta}_{\mathrm{ols}}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{R}}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}_{\mathrm{ols}}-\theta_{0}\right), \]
这正是 Wald 统计量。由于非线性限制,\(W\) 和 \(H\) 可能不同。
在任何一种情况下,我们都看到豪斯曼统计量 \(H\) 的渐近零分布是 \(\chi_{q}^{2}\),因此适当的测试是拒绝 \(\mathbb{M}_{0}\) 而支持 \(\mathbb{H}_{1}\),如果 \(H>c\) 其中 \(c\) 是关键取自 \(\chi_{q}^{2}\) 分布的值。
定理 9.7 对于一般假设,Hausman 检验统计量为
\[ H=n\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right)^{\prime} \widehat{\boldsymbol{R}}\left(\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\beta} \widehat{\boldsymbol{R}}\right)^{-1} \widehat{\boldsymbol{R}}^{\prime}\left(\widehat{\beta}_{\mathrm{ols}}-\widetilde{\beta}_{\mathrm{emd}}\right) . \]
假设 \(7.2,7.3,7.4\) 和 \(\mathbb{M}_{0}: r(\beta)=\theta_{0} \in \mathbb{R}^{q}, H \underset{d}{\longrightarrow} \chi_{q}^{2}\)
9.16 分数测试
分数检验传统上是通过似然分析得出的,但更一般地可以根据在有限估计下评估的一阶条件构建。我们关注似然推导。
给定对数似然函数 \(\ell_{n}\left(\beta, \sigma^{2}\right)\)、限制 \(\mathbb{H}_{0}: r(\beta)=\theta_{0}\) 以及限制估计器 \(\widetilde{\beta}\) 和 \(\widetilde{\sigma}^{2}\),\(\mathbb{H}_{0}\) 的得分统计量定义为
\[ S=\left(\frac{\partial}{\partial \beta} \ell_{n}\left(\widetilde{\beta}, \widetilde{\sigma}^{2}\right)\right)^{\prime}\left(-\frac{\partial^{2}}{\partial \beta \partial \beta^{\prime}} \ell_{n}\left(\widetilde{\beta}, \widetilde{\sigma}^{2}\right)\right)^{-1}\left(\frac{\partial}{\partial \beta} \ell_{n}\left(\widetilde{\beta}, \widetilde{\sigma}^{2}\right)\right) . \]
这个想法是,如果限制为真,那么受限制的估计量应该接近导数为零的对数似然的最大值。然而,如果限制是假的,那么受限制的估计量应该远离最大值并且导数应该很大。因此,\(\mathbb{H}_{0}\) 下的 \(S\) 值较小,\(\mathbb{H}_{1}\) 下的值较大。 \(\mathbb{M}_{0}\) 的测试会拒绝 \(S\) 的大值。
我们在正态回归模型和线性假设 \(r(\beta)=\boldsymbol{R}^{\prime} \beta\) 的背景下探索分数统计。回想一下,在正常回归中,对数似然函数是
\[ \ell_{n}\left(\beta, \sigma^{2}\right)=-\frac{n}{2} \log \left(2 \pi \sigma^{2}\right)-\frac{1}{2 \sigma^{2}} \sum_{i=1}^{n}\left(Y_{i}-X_{i}^{\prime} \beta\right)^{2} . \]
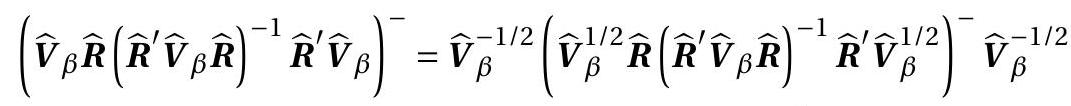
线性假设下的约束 MLE 是约束最小二乘
\[ \begin{aligned} \widetilde{\beta} &=\widehat{\beta}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{R}\left[\boldsymbol{R}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{R}\right]^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\boldsymbol{c}\right) \\ \widetilde{e}_{i} &=Y_{i}-X_{i}^{\prime} \widetilde{\beta} \\ \widetilde{\sigma}^{2} &=\frac{1}{n} \sum_{i=1}^{n} \widetilde{e}_{i}^{2} \end{aligned} \]
我们可以计算出导数和 Hessian 为
\[ \begin{aligned} \frac{\partial}{\partial \beta} \ell_{n}\left(\widetilde{\beta}, \widetilde{\sigma}^{2}\right) &=\frac{1}{\widetilde{\sigma}^{2}} \sum_{i=1}^{n} X_{i}\left(Y_{i}-X_{i}^{\prime} \widetilde{\beta}\right)=\frac{1}{\widetilde{\sigma}^{2}} \boldsymbol{X}^{\prime} \widetilde{\boldsymbol{e}} \\ -\frac{\partial^{2}}{\partial \beta \partial \beta^{\prime}} \ell_{n}\left(\widetilde{\beta}, \widetilde{\sigma}^{2}\right) &=\frac{1}{\widetilde{\sigma}^{2}} \sum_{i=1}^{n} X_{i} X_{i}^{\prime}=\frac{1}{\widetilde{\sigma}^{2}} \boldsymbol{X}^{\prime} \boldsymbol{X} \end{aligned} \]
由于 \(\widetilde{\boldsymbol{e}}=\boldsymbol{Y}-\boldsymbol{X} \widetilde{\beta}\) 我们可以进一步计算
\[ \begin{aligned} \frac{\partial}{\partial \beta} \ell_{n}\left(\widetilde{\beta}, \widetilde{\sigma}^{2}\right) &=\frac{1}{\widetilde{\sigma}^{2}}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)\left(\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{Y}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{X} \widetilde{\beta}\right) \\ &=\frac{1}{\widetilde{\sigma}^{2}}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)(\widehat{\beta}-\widetilde{\beta}) \\ &=\frac{1}{\widetilde{\sigma}^{2}} \boldsymbol{R}\left[\boldsymbol{R}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{R}\right]^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\beta}-\boldsymbol{c}\right) . \end{aligned} \]
我们一起发现
\[ S=\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{\beta}}-\boldsymbol{c}\right)^{\prime}\left(\boldsymbol{R}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{R}\right)^{-1}\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{\beta}}-\boldsymbol{c}\right) / \widetilde{\sigma}^{2} . \]
这与 \(s^{2}\) 替换为 \(\widetilde{\sigma}^{2}\) 的同方差 Wald 统计量相同。我们还可以将 \(S\) 写为 \(F\) 统计量的单调变换,如下
\[ S=n \frac{\left(\widetilde{\sigma}^{2}-\widehat{\sigma}^{2}\right)}{\widetilde{\sigma}^{2}}=n\left(1-\frac{\widehat{\sigma}^{2}}{\widetilde{\sigma}^{2}}\right)=n\left(1-\frac{1}{1+\frac{q}{n-k} F}\right) . \]
测试“针对 \(S\) 的大值拒绝 \(\mathbb{M}_{0}\)”与测试“针对 \(F\) 的大值拒绝 \(\mathbb{M}_{0}\)”相同,因此它们是相同的测试。由于对于正态回归模型,\(F\) 的精确分布是已知的,因此最好使用 \(F\) 统计量和 \(F\) p 值。
在更复杂的设置中,分数测试的潜在优势在于,它们是使用受限参数估计值 \(\widetilde{\beta}\) 而不是不受限制的估计值 \(\widehat{\beta}\) 来计算的。因此,当 \(\widetilde{\beta}\) 相对容易计算时,可能会优先考虑分数统计。这不是线性限制的问题。
更一般地,分数和类分数统计可以根据在受限参数估计下评估的一阶条件来构造。此外,当使用协方差矩阵估计构建测试统计量(使用受限参数估计(例如受限残差)计算)时,这些通常被描述为分数测试。
后者的一个例子是 Wald 型统计量
\[ W=\left(r(\widehat{\beta})-\theta_{0}\right)^{\prime}\left(\widehat{\boldsymbol{R}}^{\prime} \widetilde{\boldsymbol{V}}_{\widehat{\beta}} \widehat{\boldsymbol{R}}\right)^{-1}\left(r(\widehat{\beta})-\theta_{0}\right) \]
其中协方差矩阵估计 \(\widetilde{\boldsymbol{V}}_{\widehat{\beta}}\) 是使用限制残差 \(\widetilde{e}_{i}=Y_{i}-X_{i}^{\prime} \widetilde{\beta}\) 计算的。当 \(\beta\) 和 \(\theta\) 是高维时,这可能是一个不错的选择,因为在这种情况下,可能会担心估计器 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}\) 不精确。
9.17 非线性假设检验的问题
虽然当假设是对 \(\beta\) 的线性限制时,\(t\) 和 Wald 检验效果很好,但当限制是非线性时,它们的效果可能会很差。这可以通过 Lafontaine 和 White (1986) 介绍的一个简单例子看出。采用模型 \(Y \sim \mathrm{N}\left(\beta, \sigma^{2}\right.\) )并考虑假设 \(\mathbb{H}_{0}: \beta=1\)。令 \(\widehat{\beta}\) 和 \(\widehat{\sigma}^{2}\) 为 \(Y\) 的样本均值和方差。测试 \(\mathbb{H}_{0}\) 的标准 Wald 统计量是
\[ W=n \frac{(\widehat{\beta}-1)^{2}}{\widehat{\sigma}^{2}} . \]
请注意,对于任何正整数 \(s\),\(\mathbb{M}_{0}\) 等价于假设 \(\mathbb{M}_{0}(s): \beta^{s}=1\)。令 \(r(\beta)=\) \(\beta^{s}\) 并注意 \(\boldsymbol{R}=s \beta^{s-1}\),我们发现检验 \(\mathbb{M}_{0}(s)\) 的 Wald 统计量为
\[ W_{s}=n \frac{\left(\widehat{\beta}^{s}-1\right)^{2}}{\widehat{\sigma}^{2} s^{2} \widehat{\beta}^{2 s-2}} . \]
虽然假设 \(\beta^{s}=1\) 不受 \(s\) 选择的影响,但统计量 \(W_{s}\) 会随着 \(s\) 的变化而变化。这是沃尔德统计数据的一个不幸的特征。
为了演示这种效果,我们在图 \(9.2\) 中绘制了 Wald 统计量 \(W_{s}\) 作为 \(s\) 的函数,设置 \(n / \widehat{\sigma}^{2}=10\)。增加的线适用于 \(\widehat{\beta}=0.8\) 的情况。下降线适用于 \(\widehat{\beta}=1.6\) 的情况。很容易看出,在每种情况下,\(s\) 的某些值的检验统计量相对于渐近临界值而言显着,而 \(s\) 的其他值的检验统计量相对于渐近临界值而言不显着。这是令人痛苦的,因为 \(s\) 的选择是任意的并且与实际假设无关。
我们的一阶渐近理论对于帮助选择 \(s\) 没有用,因为对于任何 \(s\),\(\mathbb{H}_{0}\) 下的 \(W_{s} \underset{d}{\longrightarrow} \chi_{1}^{2}\) 都是有用的。在这种情况下,蒙特卡罗模拟作为研究和比较有限样本中统计过程的精确分布的工具非常有用。该方法使用随机模拟来创建人工数据集,我们在其中应用感兴趣的统计工具。这会根据统计数据的抽样分布进行随机抽取。通过重复,可以计算出该分布的特征。
在 Wald 统计的当前背景下,一个重要的特征是使用渐近 \(5 %\) 临界值 \(3.84\) 进行测试的 I 类错误 - 错误拒绝的概率 \(\mathbb{P}\left[W_{s}>3.84 \mid \beta=1\right]\)。鉴于模型的简单性,该概率仅取决于 \(s, n\) 和 \(\sigma^{2}\)。在表 \(9.2\) 中,我们报告了蒙特卡罗模拟的结果,其中我们改变了这三个参数。 \(s\) 的值在 1 到 \(10, n\) 之间变化,在 20,100 和 500 之间变化,\(\sigma\) 在 1 和 3 之间变化。该表报告了 50,000 个随机样本的 I 类错误概率的模拟估计。表的每一行对应于 \(5 %\) 的不同值 - 因此对应于检验统计量的特定选择。第二到第七列包含 \(5 %\) 和 \(5 %\) 不同组合的 I 类错误概率。这些概率计算为 50,000 个模拟 Wald 统计数据 \(5 %\) 的百分比,大于 3.84。原假设 \(5 %\) 为真,因此这些概率属于 I 类错误。
要解释该表,请记住理想的 I 类错误概率为 \(5 %(.05)\),偏差表明存在失真。 \(3 %\) 和 \(8 %\) 之间的 I 类错误率被认为是合理的。错误率高于 \(10 %\) 被视为过高。高于 \(20 %\) 的价格是不可接受的。在比较统计程序时,我们逐行比较比率,寻找拒绝率接近 \(5 %\) 并且很少超出 \(3 %-8 %\) 范围的测试。对于这个特定示例,满足此标准的唯一测试是传统的 \(W=W_{1}\) 测试。任何其他 \(s\) 都会导致具有不可接受的 I 类错误概率的测试。
在表 \(9.2\) 中,您还可以看到样本量变化的影响。在每种情况下,随着样本量 \(n\) 的增加,I 类错误概率向 \(5 %\) 提高。然而,没有什么神奇的选择 \(n\) 可以让所有测试都表现良好。测试性能随着 \(s\) 的增加而恶化,考虑到 \(W_{s}\) 对 \(s\) 的依赖性(如图 9.2 所示),这并不奇怪。
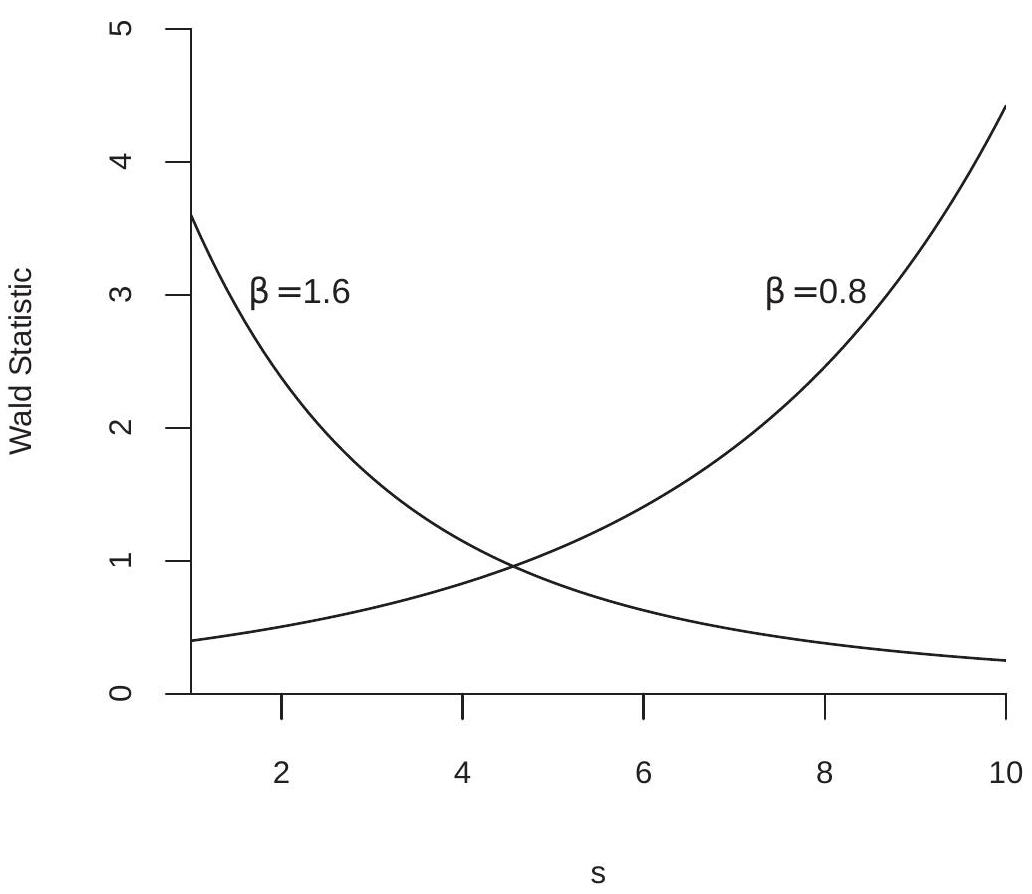
图 9.2:Wald 统计量作为 \(s\) 的函数
在此示例中,选择 \(s=1\) 产生最佳检验统计量并不奇怪。其他选择是任意的,不会在实践中使用。虽然这一点在这个特定示例中很明显,但在其他示例中,自然选择并不明显,并且最佳选择可能是反直觉的。
这一点可以通过 Gregory 和 Veall (1985) 的例子来说明。拿模型
\[ \begin{aligned} Y &=\beta_{0}+X_{1} \beta_{1}+X_{2} \beta_{2}+e \\ \mathbb{E}[X e] &=0 \end{aligned} \]
以及假设 \(\mathbb{M}_{0}: \frac{\beta_{1}}{\beta_{2}}=\theta_{0}\),其中 \(\theta_{0}\) 是已知常数。同样,定义 \(\theta=\beta_{1} / \beta_{2}\),这样假设就可以表述为 \(\mathbb{M}_{0}: \theta=\theta_{0}\)。
令\(\widehat{\beta}=\left(\widehat{\beta}_{0}, \widehat{\beta}_{1}, \widehat{\beta}_{2}\right)\) 为\((9.14)\) 的最小二乘估计量,令\(\widehat{\boldsymbol{V}}_{\widehat{\beta}}\) 为\(\widehat{\beta}\) 协方差矩阵的估计量并设置\(\widehat{\theta}=\widehat{\beta}_{1} / \widehat{\beta}_{2}\)。定义
\[ \widehat{\boldsymbol{R}}_{1}=\left(\begin{array}{c} 0 \\ \frac{1}{\widehat{\beta}_{2}} \\ -\frac{\widehat{\beta}_{1}}{\widehat{\beta}_{2}^{2}} \end{array}\right) \]
表 9.2:渐近 \(5 % W(s)\) 检验的 I 类错误概率
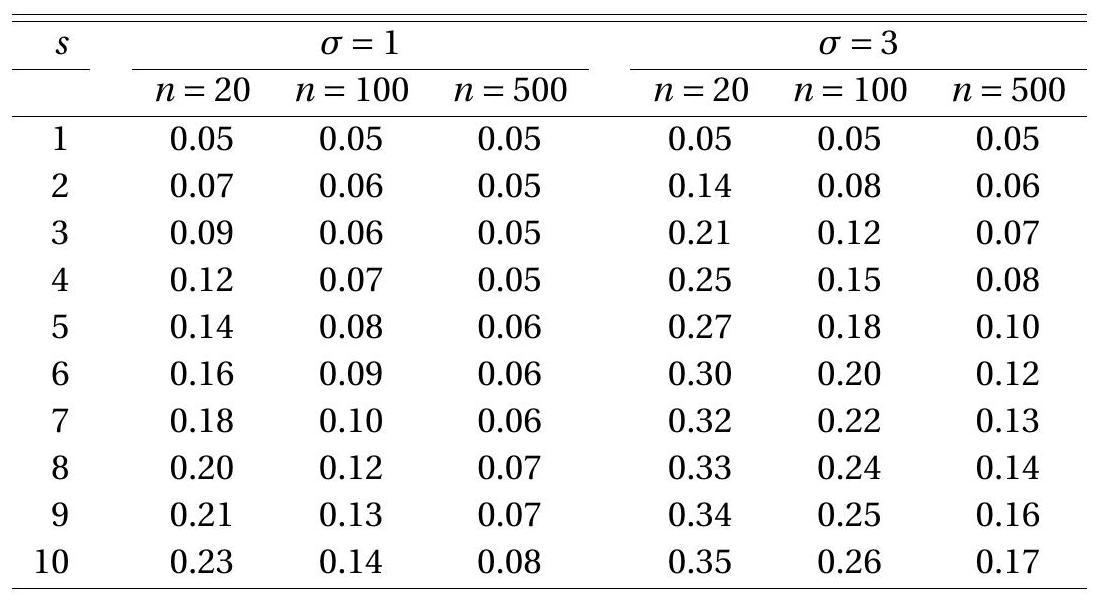
50,000 个模拟随机样本的拒绝频率。
因此 \(\widehat{\theta}\) 的标准错误是 \(s(\widehat{\theta})=\left(\widehat{\boldsymbol{R}}_{1}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}} \widehat{\boldsymbol{R}}_{1}\right)^{1 / 2}\)。在这种情况下,\(\mathbb{M}_{0}\) 的 t 统计量为
\[ T_{1}=\frac{\left(\frac{\widehat{\beta}_{1}}{\widehat{\beta}_{2}}-\theta_{0}\right)}{s(\widehat{\theta})} . \]
可以通过将零假设重新表述为来构建替代统计量
\[ \mathbb{M}_{0}: \beta_{1}-\theta_{0} \beta_{2}=0 . \]
基于该假设表述的 t 统计量为
\[ T_{2}=\frac{\widehat{\beta}_{1}-\theta_{0} \widehat{\beta}_{2}}{\left(\boldsymbol{R}_{2}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}} \boldsymbol{R}_{2}\right)^{1 / 2}} \]
在哪里
\[ \boldsymbol{R}_{2}=\left(\begin{array}{c} 0 \\ 1 \\ -\theta_{0} \end{array}\right) \text {. } \]
为了比较 \(T_{1}\) 和 \(T_{2}\),我们执行另一个简单的蒙特卡罗模拟。我们让\(X_{1}\)和\(X_{2}\)是相互独立的\(\mathrm{N}(0,1)\)变量,\(e\)是独立的\(\mathrm{N}\left(0, \sigma^{2}\right)\)与\(\sigma=3\)的平局,并标准化\(\beta_{0}=0\)和\(T_{1}\)。这使得 \(T_{1}\) 成为自由参数以及样本大小 \(T_{1}\)。我们在 \(T_{1}\)、\(T_{1}\) 和 \(T_{1}\) 和 \(T_{1}\) 之间改变 \(T_{1}\) 在 100 和 500 之间。
单边第一类错误概率 \(\mathbb{P}[T<-1.645]\) 和 \(\mathbb{P}[T>1.645]\) 是根据 50,000 个模拟样本计算得出的。结果如表 9.3 所示。理想情况下,表中的条目应为 \(0.05\)。然而,\(T_{1}\) 统计量的拒绝率与该值相差很大,特别是对于 \(\beta_{2}\) 的小值。左尾概率 \(\mathbb{P}\left[T_{1}<-1.645\right]\) 大大超过 \(5 %\),而右尾概率 \(\mathbb{P}\left[T_{1}>1.645\right]\) 在大多数情况下接近于零。相比之下,\(T_{2}\) 统计量的拒绝率对于 \(\mathbb{P}[T<-1.645]\) 的值是不变的,并且对于两种样本大小都等于 \(\mathbb{P}[T<-1.645]\)。表 \(\mathbb{P}[T<-1.645]\) 的含义是两个 t 比具有显着不同的采样行为。
这两个例子的共同信息是 Wald 统计量对原假设的代数表述很敏感。表 9.3:渐进 5% t 检验的 I 类错误概率
50,000 个模拟随机样本的拒绝频率。
一个简单的解决方案是使用最小距离统计量 \(J\),它等于第一个示例中的 \(W\) 和 \(r=1\),以及第二个示例中的 \(\left|T_{2}\right|\)。最小距离统计量对于原假设的代数表述是不变的,因此不受此问题的影响。只要有可能,Wald 统计量就不应用于检验非线性假设。
对这些问题的理论研究包括 Park 和 Phillips (1988) 以及 Dufour (1997)。
9.18 蒙特卡罗模拟
在\(9.17\)节中,我们介绍了蒙特卡罗模拟的方法,通过非线性假设检验来说明小样本问题。在本节中,我们将更详细地描述该方法。
回想一下,我们的数据由观察值 \(\left(Y_{i}, X_{i}\right)\) 组成,这些观察值是从总体分布 \(F\) 中随机抽取的。令 \(\theta\) 为参数,让 \(T=T\left(\left(Y_{1}, X_{1}\right), \ldots,\left(Y_{n}, X_{n}\right), \theta\right)\) 为感兴趣的统计量,例如估计器 \(\widehat{\theta}\) 或 t 统计量 \((\widehat{\theta}-\theta) / s(\widehat{\theta})\)。 \(T\) 的精确分布是
\[ G(u, F)=\mathbb{P}[T \leq u \mid F] . \]
虽然 \(T\) 的渐近分布可能是已知的,但确切的(有限样本)分布 \(G\) 通常是未知的。
蒙特卡罗模拟使用数值模拟来计算 \(F\) 的所选选项的 \(G(u, F)\)。这对于研究统计量 \(T\) 在合理情况和样本大小下的性能很有用。基本思想是,对于任何给定的 \(F\),分布函数 \(G(u, F)\) 可以通过模拟进行数值计算。蒙特卡洛这个名字源自地中海赌博胜地,那里进行机会游戏。
蒙特卡罗方法描述起来很简单。研究人员选择 \(F\) (伪数据的分布)和样本大小 \(n\)。此选择暗示了 \(\theta\) 的“真实”值,或者等效地,研究人员直接选择值 \(\theta\),这意味着对 \(F\) 的限制。
然后通过计算机模拟进行如下实验:
\(n\) 独立随机对 \(\left(Y_{i}^{*}, X_{i}^{*}\right), i=1, \ldots, n\) 是使用计算机的随机数生成器从分布 \(F\) 中抽取的。
统计量 \(T=T\left(\left(Y_{1}^{*}, X_{1}^{*}\right), \ldots,\left(Y_{n}^{*}, X_{n}^{*}\right), \theta\right)\) 是根据该伪数据计算的。
对于步骤 1,计算机软件包具有内置随机数程序,包括 \(U[0,1]\) 和 \(N(0,1)\)。从这些可以构建大多数随机变量。 (例如,卡方可以通过法线平方和生成。)对于步骤 2,重要的是根据与 \(F\) 的选择相对应的 \(\theta\) 的“真实”值来评估统计量。
上述实验从分布 \(G(u, F)\) 中随机抽取 \(T\)。这是来自未知分布的一项观察结果。显然,仅从一项观察来看,我们无法得出什么结论。因此,研究人员重复实验 \(B\) 次,其中 \(B\) 是一个很大的数字。通常,我们设置 \(B \geq 1000\)。我们稍后会讨论这个选择。
从符号上看,让 \(b^{t h}\) 实验的结果与 \(T_{b}, b=1, \ldots, B\) 平局。这些结果被存储。计算完所有 \(B\) 实验后,这些结果构成了 \(G(u, F)=\mathbb{P}\left[T_{b} \leq u\right]=\mathbb{P}[T \leq u \mid F]\) 分布中大小为 \(B\) 的随机样本。
从随机样本中,我们可以使用(通常)矩估计器的方法来估计任何感兴趣的特征。我们现在描述一些具体的例子。
假设我们对 \(\widehat{\theta}-\theta\) 分布的偏差、均方误差 (MSE) 和/或方差感兴趣。然后我们设置\(T=\widehat{\theta}-\theta\),运行上面的实验,并计算
\[ \begin{aligned} \widehat{\operatorname{bias}}[\widehat{\theta}] &=\frac{1}{B} \sum_{b=1}^{B} T_{b}=\frac{1}{B} \sum_{b=1}^{B} \widehat{\theta}_{b}-\theta \\ \widehat{\operatorname{mse}}[\widehat{\theta}] &=\frac{1}{B} \sum_{b=1}^{B}\left(T_{b}\right)^{2}=\frac{1}{B} \sum_{b=1}^{B}\left(\widehat{\theta}_{b}-\theta\right)^{2} \\ \widehat{\operatorname{var}}[\widehat{\theta}] &=\widehat{\operatorname{mse}}[\widehat{\theta}]-(\widehat{\operatorname{bias}}[\hat{\theta}])^{2} \end{aligned} \]
假设我们对与渐近 5% 双边 t 检验相关的 I 类错误感兴趣。然后我们设置 \(T=|\widehat{\theta}-\theta| / s(\widehat{\theta})\) 并计算
\[ \widehat{P}=\frac{1}{B} \sum_{b=1}^{B} \mathbb{1}\left\{T_{b} \geq 1.96\right\}, \]
超过渐近 \(5 %\) 临界值的模拟 t 比率的百分比。
假设我们对 \(T=\widehat{\theta}\) 或 \(T=(\widehat{\theta}-\theta) / s(\widehat{\theta})\) 的 \(5 %\) 和 \(95 %\) 分位数感兴趣。然后,我们计算样本 \(\left\{T_{b}\right\}\) 的 \(5 %\) 和 \(95 %\) 样本分位数。有关分位数估计的详细信息,请参阅《经济学家概率与统计》的 \(11.13\) 部分。
蒙特卡罗模拟的典型目的是研究统计过程在现实环境中的性能。一般来说,性能取决于 \(n\) 和 \(F\)。在许多情况下,估计器或测试对于某些值可能表现出色,而对于其他值则表现不佳。因此,针对 \(n\) 和 \(F\) 的选择进行各种实验是有用的。
如上所述,研究人员必须选择实验数量 \(B\)。通常这称为重复次数。很简单,较大的 \(B\) 可以更精确地估计 \(G\) 的感兴趣特征,但需要更多的计算时间。因此,在实践中,\(B\) 的选择通常以统计过程的计算需求为指导。由于蒙特卡罗实验的结果是根据大小为 \(B\) 的随机样本计算得出的估计值,因此可以直接计算任何感兴趣数量的标准误差。如果标准误差太大而无法做出可靠的推论,则必须增加 \(B\)。一个有用的经验法则是尽可能设置 \(B=10,000\)。
特别是,从统计测试中推断拒绝概率很简单,例如(9.15)中报告的百分比估计。随机变量 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 是独立同分布的。伯努利,等于 1,概率为 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\)。因此,平均值 (9.15) 是 \(p\) 的无偏估计量,具有标准误差 \(s(\widehat{p})=\sqrt{p(1-p) / B}\)。由于 \(p\) 未知,因此可以通过用 \(\widehat{p}\) 或假设值替换 \(p\) 来近似。例如,如果我们正在评估渐近 \(5 %\) 检验,那么我们可以设置 \(s(\widehat{p})=\sqrt{(.05)(.95) / B} \simeq .22 / \sqrt{B}\)。因此,\(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 和 5000 的标准误差分别为 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 和 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 大多数计量经济学方法论文和一些实证论文都包含蒙特卡罗模拟的结果,以说明其方法的性能。扩展现有结果时,最好从复制现有(已发布)结果开始。对于模拟结果来说,这可能并不完全可能,因为它们本质上是随机的。例如,假设一篇论文研究了一项统计测试,并基于 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 重复的模拟报告了 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 的模拟拒绝概率。假设您尝试复制此结果并找到 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 的拒绝概率(再次使用 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 模拟复制)。你是否应该得出结论说你的尝试失败了?绝对不!假设两个模拟相同,您对共同概率 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 有两个独立的估计:\(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\) 和 \(\mathbb{1}\left\{T_{b} \geq 1.96\right\}\)。它们差值的渐近分布(如 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\) )为 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\),因此使用估计值 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\),\(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\) 的标准误差为 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\)。由于 t 比率 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\) 在统计上不显着,因此拒绝两个模拟相同的零假设是不正确的。结果 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\) 和 \(p=\mathbb{E}\left[\mathbb{1}\left\{T_{b} \geq 1.96\right\}\right]\) 之间的差异与随机变化一致。
应该做什么?第一个错误是复制了之前论文中对 \(B=100\) 的选择。相反,假设您设置了 \(B=10,000\) 并且现在获得了 \(\widehat{p}_{2}=0.04\)。那么 \(\widehat{p}_{1}-\widehat{p}_{2}=0.03\) 和标准错误是 \(\widehat{s}=\) \(\sqrt{\bar{p}(1-\bar{p})(1 / 100+1 / 10000)} \simeq 0.02\)。但我们仍然不能拒绝两个模拟不同的假设。尽管估计值( \(0.07\) 和 \(0.04)\) 似乎有很大不同,但困难在于原始模拟使用了非常少量的重复 \((B=100)\),因此报告的估计值相当不精确。在这种情况下,适当的做法是得出结论,您的结果“复制”了先前的研究,因为没有统计证据可以拒绝它们是等效的假设。
大多数期刊都有政策要求作者提供实证结果所需的数据集和计算机程序。大多数没有关于模拟的类似政策。尽管如此,让您的模拟可用是良好的专业实践。最佳实践是将模拟代码发布到您的网页上。这会邀请其他人以您的成果为基础并使用您的成果,从而实现可能的合作、引用和/或进步。
9.19 检验反演的置信区间
假设检验和置信区间之间存在密切关系。我们在 \(7.13\) 节中观察到,参数 \(\theta\) 的标准 \(95 %\) 渐近置信区间是
\[ \widehat{C}=[\widehat{\theta}-1.96 \times s(\widehat{\theta}), \quad \widehat{\theta}+1.96 \times s(\widehat{\theta})]=\{\theta:|T(\theta)| \leq 1.96\} . \]
也就是说,我们可以将 \(\widehat{C}\) 描述为“点估计加或减 2 个标准误差”或“未被双边 t 检验拒绝的参数值集”。第二个定义称为检验统计量反演,是查找置信区间的通用方法,通常会产生具有优异特性的置信区间。
给定检验统计量 \(T(\theta)\) 和临界值 \(c\),接受区域“Accept if \(T(\theta) \leq c\)”与置信区间 \(\widehat{C}=\{\theta: T(\theta) \leq c\}\) 相同。由于区域相同,覆盖概率 \(\mathbb{P}[\theta \in \widehat{C}]\) 等于正确接受的概率 \(\mathbb{P}[\) 接受 \(\mid \theta]\),恰好是 1 减去 I 类错误概率。因此,对具有良好 I 类错误概率的测试进行反演会产生具有良好覆盖概率的置信区间。
现在假设感兴趣的参数 \(\theta=r(\beta)\) 是系数向量 \(\beta\) 的非线性函数。在这种情况下,\(\theta\) 的标准置信区间是 \(\widehat{C}\) 的集合,如 (9.16) 中所示,其中 \(\widehat{\theta}=r(\widehat{\beta})\) 是点估计器,\(s(\widehat{\theta})=\sqrt{\widehat{\boldsymbol{R}}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}} \widehat{\boldsymbol{R}}}\) 是 delta 方法标准误差。此置信区间是基于非线性假设 \(r(\beta)=\theta\) 的 t 检验的反转。问题在于,在 \(9.17\) 节中,我们了解到非线性假设检验没有唯一的 t 统计量,并且参数化的选择非常重要。例如,如果 \(\theta=\beta_{1} / \beta_{2}\) 则标准区间 (9.16) 的覆盖概率为 1 减去 I 类错误的概率,如表 \(\theta=r(\beta)\) 所示,该概率可能与名义 \(\theta=r(\beta)\) 相差甚远。
在这个例子中,一个好的解决方案与 \(9.17\) 节中讨论的相同 - 将假设重写为线性限制。假设 \(\theta=\beta_{1} / \beta_{2}\) 与 \(\theta \beta_{2}=\beta_{1}\) 相同。此限制的 t 统计量为
\[ T(\theta)=\frac{\widehat{\beta}_{1}-\widehat{\beta}_{2} \theta}{\left(\boldsymbol{R}^{\prime} \widehat{\boldsymbol{V}}_{\widehat{\beta}} \boldsymbol{R}\right)^{1 / 2}} \]
在哪里
\[ \boldsymbol{R}=\left(\begin{array}{c} 1 \\ -\theta \end{array}\right) \]
\(\widehat{V}_{\widehat{\beta}}\) 是 \(\left(\widehat{\beta}_{1} \widehat{\beta}_{2}\right)\) 的协方差矩阵。 \(\theta=\beta_{1} / \beta_{2}\) 的 95% 置信区间是 \(\theta\) 的值集合,使得 \(|T(\theta)| \leq 1.96\) 成立。由于 \(T(\theta)\) 是 \(\theta\) 的非线性函数,查找置信集的一种方法是在 \(\theta\) 上进行网格搜索。
例如,在工资方程中
\[ \log (\text { wage })=\beta_{1} \text { experience }+\beta_{2} \text { experience }^{2} / 100+\cdots \]
最高预期工资出现在经验 \(=-50 \beta_{1} / \beta_{2}\) 处。从表 \(4.1\) 中,我们得到点估计值 \(\widehat{\theta}=29.8\),并且可以计算 95% 置信区间 \([29.8,29.9]\) 的标准误差 \(s(\widehat{\theta})=0.022\)。然而,如果我们反转测试的线性形式,我们会在数值上发现区间 \([29.1,30.6]\) 要大得多。从 \(9.17\) 节中提供的证据中,我们知道第一个间隔可能非常不准确,而第二个间隔则更为可取。
9.20 多重测试和 Bonferroni 修正
在大多数应用中,经济学家都会检查大量的估计值、检验统计数据和 p 值。如果在检查大量统计数据后一项统计数据似乎“显着”,这意味着什么(或者有什么意义)?这称为多重测试或多重比较的问题。
具体来说,假设我们检查一组 \(k\) 系数、标准误差和 t 比率,并考虑每个统计量的“显着性”。根据传统推理,对于每个系数,如果绝对 t 统计量超过正态分布的 \(1-\alpha\) 临界值,或者等效地如果 \(\mathrm{p}\)- t 统计量的值小于 \(\alpha\)。如果我们观察到 \(k\) 统计数据之一基于此标准“显着”,则意味着其中一个 p 值小于 \(\alpha\),或者同等地,最小 p 值小于 \(\alpha\)。然后我们可以重新表述这个问题:在一组 \(k\) 假设全部成立的联合假设下,最小 \(k\) 值小于 \(k\) 的概率是多少?一般来说,我们无法为这个问题提供精确的答案,但 Bonferroni 修正将这个概率限制在 \(k\) 范围内。 Bonferroni 方法进一步表明,如果我们希望族系误差概率(其中一项测试错误拒绝的概率)限制在 \(k\) 以下,那么适当的规则是仅当最小 p 值小于 \(数学14\)。等效地,Bonferroni 系列 \(k\) 值是 \(k\)。
形式上,假设我们有 \(k\) 假设 \(\mathbb{M}_{j}, j=1, \ldots, k\)。对于每个,我们都有一个测试并将 pvalue \(p_{j}\) 与当 \(\mathbb{H}_{j}\) 为 true \(\lim _{n \rightarrow \infty} \mathbb{P}\left[p_{j}<\alpha\right]=\alpha\) 时的属性相关联。然后我们观察到,在 \(k\) 测试中,\(k\) 之一如果 \(\min _{j \leq k} p_{j}<\alpha\) 则“显着”。这个事件可以写成
\[ \left\{\min _{j \leq k} p_{j}<\alpha\right\}=\bigcup_{j=1}^{k}\left\{p_{j}<\alpha\right\} . \]
布尔不等式指出,对于任何 \(k\) 事件 \(A_{j}, \mathbb{P}\left[\bigcup_{j=1}^{k} A_{j}\right] \leq \sum_{j=1}^{k} \mathbb{P}\left[A_{k}\right]\)。因此
\[ \mathbb{P}\left[\min _{j \leq k} p_{j}<\alpha\right] \leq \sum_{j=1}^{k} \mathbb{P}\left[p_{j}<\alpha\right] \rightarrow k \alpha \]
就像声明的那样。这表明渐进家庭拒绝概率最多是个体拒绝概率的 \(k\) 倍。
此外,
\[ \mathbb{P}\left[\min _{j \leq k} p_{j}<\frac{\alpha}{k}\right] \leq \sum_{j=1}^{k} \mathbb{P}\left[p_{j}<\frac{\alpha}{k}\right] \rightarrow \alpha . \]
这表明,如果每个单独的测试都遵循更严格的标准,即 p 值必须小于 \(\alpha / k\) 才能被标记为“显着”,则可以控制渐进族拒绝概率(限制在 \(\alpha\) 之下)。
为了说明这一点,假设我们有两个系数估计,其各自的 p 值分别为 \(0.04\) 和 \(0.15\)。基于传统的 \(5 %\) 水平,标准单独测试表明第一个系数估计值是“显着的”,但第二个系数估计值不是“显着的”。然而,Bonferroni 5% 检验不会拒绝,因为它要求最小 p 值小于 \(0.025\),但本例中并非如此。或者,Bonferroni 系列 \(\mathrm{p}\) 值是 \(0.04 \times 2=0.08\),这在 \(5 %\) 级别并不显着。
相反,如果两个 p 值为 \(0.01\) 和 \(0.15\),则 Bonferroni 系列 p 值为 \(0.01 \times 2=0.02\),这在 \(5 %\) 水平上显着。
9.21 功率和测试一致性
检验的功效是当 \(\mathbb{M}_{1}\) 为真时拒绝 \(\mathbb{M}_{0}\) 的概率。
为简单起见,假设 \(Y_{i}\) 是 i.i.d。 \(\mathrm{N}\left(\theta, \sigma^{2}\right)\) 和 \(\sigma^{2}\) 已知,考虑 t 统计量 \(T(\theta)=\sqrt{n}(\bar{Y}-\theta) / \sigma\),并测试 \(\mathbb{M}_{0}: \theta=0\) 与 \(\mathbb{M}_{1}: \theta>0\)。如果 \(T=T(0)>c\),我们拒绝 \(\mathbb{H}_{0}\)。注意
\[ T=T(\theta)+\sqrt{n} \theta / \sigma \]
\(T(\theta)\) 具有精确的 \(\mathrm{N}(0,1)\) 分布。这是因为 \(T(\theta)\) 以真实均值 \(\theta\) 为中心,而检验统计量 \(T(0)\) 以(假)假设均值 0 为中心。
测试的功效为
\[ \mathbb{P}[T>c \mid \theta]=\mathbb{P}[\mathrm{Z}+\sqrt{n} \theta / \sigma>c]=1-\Phi(c-\sqrt{n} \theta / \sigma) . \]
该函数在 \(\mu\) 和 \(n\) 中单调递增,在 \(\sigma\) 和 \(c\) 中单调递减。
请注意,对于任何 \(c\) 和 \(\theta \neq 0\),\(n \rightarrow \infty\) 的幂都会增加到 1。这意味着,对于 \(\theta \in \mathbb{H}_{1}\),随着样本量变大,测试将以接近 1 的概率拒绝 \(\mathbb{M}_{0}\)。我们将此属性称为一致性测试。
定义 9.3 如果对于所有 \(\theta \in \Theta_{1}, \mathbb{P}\left[\right.\) 拒绝 \(\left.\mathbb{M}_{0} \mid \theta\right] \rightarrow 1\) 作为 \(n \rightarrow \infty\),则 \(\mathbb{H}_{0}: \theta \in \Theta_{0}\) 的测试与固定替代方案是一致的。
对于“如果 \(T>c\) 则拒绝 \(\mathbb{H}_{0}\)”形式的测试,测试一致性的充分条件是 \(T\) 发散到正无穷大,且所有 \(\theta \in \Theta_{1}\) 的概率为 1。定义 9.4 如果对于所有 \(M<\infty, \mathbb{P}[T \leq M] \rightarrow 0\) 来说,我们称 \(T \underset{p}{\rightarrow}\) 为 \(n \rightarrow \infty\)。同样,如果对于所有 \(\mathbb{H}_{0}\),\(\mathbb{H}_{0}\) 为 \(\mathbb{H}_{0}\),我们称 \(T \underset{p}{\rightarrow}-\infty\) 为 \(\mathbb{H}_{0}\)
一般来说,t 检验和 Wald 检验与固定替代方案是一致的。采用 t 统计量来检验 \(\mathbb{\sharp}_{0}: \theta=\theta_{0}, T=\left(\widehat{\theta}-\theta_{0}\right) / s(\widehat{\theta})\),其中 \(\theta_{0}\) 是已知值,\(s(\widehat{\theta})=\sqrt{n^{-1} \widehat{V}_{\theta}}\)。注意
\[ T=\frac{\widehat{\theta}-\theta}{s(\widehat{\theta})}+\frac{\sqrt{n}\left(\theta-\theta_{0}\right)}{\sqrt{\widehat{V}_{\theta}}} . \]
右侧第一项的分布收敛于 \(\mathrm{N}(0,1)\)。如果 \(\theta=\theta_{0}\),右侧第二项等于 0;如果 \(\theta>\theta_{0}\),则概率收敛到 \(+\infty\);如果 \(\theta<\theta_{0}\),则概率收敛到 \(-\infty\)。因此,双边 t 检验与 \(\mathbb{M}_{1}: \theta \neq \theta_{0}\) 是一致的,而单边 t 检验与它们设计的替代方案是一致的。
定理 9.8 在假设 7.2、7.3 和 7.4 下,对于 \(\theta=r(\beta) \neq \theta_{0}\) 和 \(q=1\),然后是 \(|T| \underset{p}{\longrightarrow}\)。对于任何 \(c<\infty\) 测试“如果 \(|T|>c\) 则拒绝 \(\mathbb{H}_{0}\)”与固定替代方案是一致的。
\(\mathbb{M}_{0}: \theta=r(\beta)=\theta_{0}\) 相对于 \(\mathbb{M}_{1}: \theta \neq \theta_{0}\) 的 Wald 统计量为 \(W=n\left(\widehat{\theta}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{V}}_{\theta}^{-1}\left(\widehat{\theta}-\theta_{0}\right)\)。在 \(\mathbb{H}_{1}\)、\(\widehat{\theta} \underset{p}{\longrightarrow} \theta \neq \theta_{0}\) 下。因此\(\left(\widehat{\theta}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{V}}_{\theta}^{-1}\left(\widehat{\theta}-\theta_{0}\right) \underset{p}{\longrightarrow}\left(\theta-\theta_{0}\right)^{\prime} \boldsymbol{V}_{\theta}^{-1}\left(\theta-\theta_{0}\right)>0\)。因此在 \(\mathbb{H}_{1}, W \underset{p}{\longrightarrow}\) 下。这再次表明 Wald 检验是一致的。
定理 9.9 在假设 7.2、7.3 和 7.4 下,对于 \(\theta=r(\beta) \neq \theta_{0}\),则对于 \(W \underset{p}{\longrightarrow}\)。对于任何 \(c<\infty\) 测试“如果 \(W>c\) 则拒绝 \(\mathbb{M}_{0}\)”与固定替代方案是一致的。
9.22 渐近局部幂
一致性对于测试来说是一个很好的属性,但没有提供计算测试功效的工具。为了近似幂函数,我们需要分布近似。
功效分析的标准渐近方法使用所谓的局部替代方法。这类似于我们对错误指定下的限制估计的分析(第 8.13 节)。该技术是通过样本大小对参数进行索引,以便统计量的渐近分布在局部参数中是连续的。在本节中,我们考虑对实值参数进行 t 检验,并在下一节中考虑 Wald 检验。具体来说,我们考虑参数向量 \(\beta_{n}\),它们按样本大小 \(n\) 索引并满足实值关系
\[ \theta_{n}=r\left(\beta_{n}\right)=\theta_{0}+n^{-1 / 2} h \]
其中标量 \(h\) 称为本地化参数。我们按样本大小对 \(\beta_{n}\) 和 \(\theta_{n}\) 进行索引,以表明它们对 \(n\) 的依赖性。思考(9.17)的方式是参数的真实值是\(\beta_{n}\)和\(\theta_{n}\)。参数 \(\theta_{n}\) 接近假设值 \(\theta_{0}\),但有偏差 \(n^{-1 / 2} h\)。
规范 (9.17) 指出,对于任何固定的 \(h, \theta_{n}\),当 \(n\) 变大时,它会逼近 \(\theta_{0}\)。因此,\(\theta_{n}\) 与 \(\theta_{0}\) 是“接近”或“本地”的。定位序列(9.17)的概念可能看起来很奇怪,因为在现实世界中样本大小不能机械地影响参数的值。因此(9.17)不应该按字面解释。相反,它应该被解释为一种允许渐近分布在备择假设中连续的技术手段。
为了评估检验统计量的渐近分布,我们首先检查以假设值 \(\theta_{0}\) 为中心的缩放估计量。将其分解为以真值 \(\theta_{n}\) 为中心的项以及我们找到的余数
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right)=\sqrt{n}\left(\widehat{\theta}-\theta_{n}\right)+\sqrt{n}\left(\theta_{n}-\theta_{0}\right)=\sqrt{n}\left(\widehat{\theta}-\theta_{n}\right)+h \]
其中第二个等式是 (9.17)。第一项是渐近正态的:
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{n}\right) \underset{d}{\longrightarrow} \sqrt{V_{\theta}} Z \]
其中 \(Z \sim \mathrm{N}(0,1)\).所以
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right) \underset{d}{\longrightarrow} \sqrt{V_{\theta}} Z+h \sim \mathrm{N}\left(h, V_{\theta}\right) . \]
这种渐近分布持续取决于局部参数 \(h\)。
应用于我们发现的 \(t\) 统计数据
\[ T=\frac{\widehat{\theta}-\theta_{0}}{s(\widehat{\theta})} \underset{d}{\longrightarrow} \frac{\sqrt{V_{\theta}} Z+h}{\sqrt{V_{\theta}}} \sim Z+\delta \]
其中 \(\delta=h / \sqrt{V_{\theta}}\).这概括了定理 \(9.1\) (假设 \(\mathbb{M}_{0}\) 为真)以允许形式 (9.17) 的局部替代。
考虑对 \(\mathbb{M}_{0}\) 与片面替代方案 \(\mathbb{M}_{1}: \theta>\theta_{0}\) 进行 t 检验,后者对于 \(T>c\) 拒绝 \(\mathbb{H}_{0}\),其中 \(\Phi(c)=1-\alpha\)。该检验的渐近局部功效是局部替代方案 (9.17) 下拒绝概率的极限(随着样本量的变化)
\[ \begin{aligned} \lim _{n \rightarrow \infty} \mathbb{P}\left[\text { Reject } \mathbb{M}_{0}\right] &=\lim _{n \rightarrow \infty} \mathbb{P}[T>c] \\ &=\mathbb{P}[Z+\delta>c] \\ &=1-\Phi(c-\delta) \\ &=\Phi(\delta-c) \\ & \stackrel{\text { def }}{=} \pi(\delta) . \end{aligned} \]
我们将 \(\pi(\delta)\) 称为渐近局部幂函数。
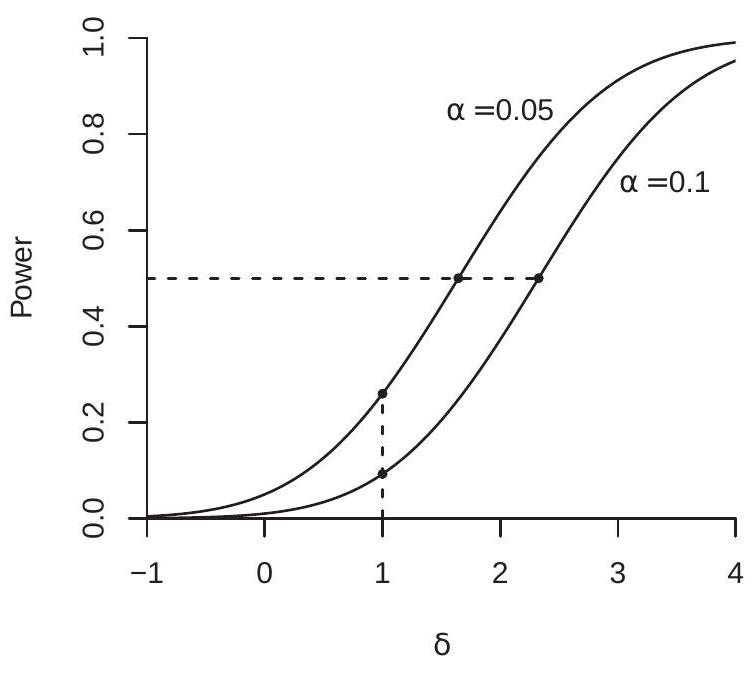
在图 9.3(a) 中,我们将局部幂函数 \(\pi(\delta)\) 绘制为 \(\delta \in[-1,4]\) 的函数,用于渐进大小 \(\alpha=0.05\) 和 \(\alpha=0.01 . \delta=0\) 的检验对应于原假设,因此 \(\pi(\delta)=\alpha\)。 \(\delta\) 中的幂函数单调递增。请注意,由于测试的单方面性质,\(\delta<0\) 的功效低于 \(\alpha\)。
我们可以看到幂函数按 \(\alpha\) 排序,因此使用 \(\alpha=0.05\) 进行的测试比使用 \(\alpha=0.01\) 进行的测试具有更高的功效。这是尺寸和功率之间固有的权衡。尺寸减小会导致功率减小,反之亦然。
- 单侧 t 检验
.jpg)
- 向量情况
图 9.3:渐近局部幂函数
系数 \(\delta\) 可以解释为以标准误差 \(s(\widehat{\theta})\) 的倍数测量的参数偏差。要看到这一点,请回忆 \(s(\widehat{\theta})=n^{-1 / 2} \sqrt{\widehat{V}_{\theta}} \simeq n^{-1 / 2} \sqrt{V_{\theta}}\),然后注意
\[ \delta=\frac{h}{\sqrt{V_{\theta}}} \simeq \frac{n^{-1 / 2} h}{s(\widehat{\theta})}=\frac{\theta_{n}-\theta_{0}}{s(\widehat{\theta})} . \]
因此 \(\delta\) 大约等于偏差 \(\theta_{n}-\theta_{0}\),表示为标准误差 \(s(\widehat{\theta})\) 的倍数。因此,当我们检查图 9.3(a) 时,我们可以将 \(\delta=1\) 处的幂函数(例如,用于 5% 大小测试的 \(26 %\))解释为当参数 \(\theta_{n}\) 比假设值高一个标准误差时的幂。例如,从表 \(4.2\) 中,“已婚女性”系数的标准误差为 \(0.010\)。因此,在本例中,\(\delta=1\) 对应于 \(\delta\) 或已婚女性的 \(\delta\) 工资溢价。我们的计算表明,针对这一替代方案的单边 \(\delta\) 检验的渐近功效约为 \(\delta\)。
幂函数之间的差异可以垂直或水平测量。例如,在图 9.3(a) 中,\(\delta=1\) 处有一条垂直虚线,表明渐近局部幂函数 \(\pi(\delta)\) 对于 \(\alpha=0.0\) 等于 \(26 %\),对于 \(\alpha=0.01\) 等于 \(9 %\)。这是不同规模的测试之间功效的差异,在替代方案中保持固定参数。
横向比较也可以具有启发性。为了说明这一点,在图 9.3(a) 中,在 \(50 %\) 次幂处有一条水平虚线。 \(50 %\) 功效是一个有用的基准,因为它是测试被拒绝和接受的几率相等的点。虚线在 \(\delta=1.65(\alpha=0.05)\) 和 \(\delta=2.33(\alpha=0.01)\) 处与两条功效曲线相交。这意味着参数 \(\theta\) 必须至少高于单边 \(5 %\) 检验的假设值 \(1.65\) 标准误差,才能具有 \(50 %\)(近似)功效,并且单边 \(2.33\) 检验的假设值必须高于 \(2.33\) 标准误差单边 \(50 %\) 测试。
这些值的比率(例如 2.33/1.65 = 1.41)衡量实现相同功率所需的相对参数大小。 (因此,对于 \(1 %\) 大小测试来实现 \(50 %\) 功效,参数必须比 \(5 %\) 大小测试大 \(41 %\) 。)更有趣的是,该比率的平方(例如 \(1.41^{2}=2\) )是在固定参数下达到相同功效所需的样本量的增加。也就是说,为了实现 \(50 %\) 功效,\(1 %\) 大小测试需要的观测值是 \(5 %\) 大小测试的两倍。这种解释遵循以下非正式论证。根据定义和 (9.17) \(\delta=h / \sqrt{V_{\theta}}=\sqrt{n}\left(\theta_{n}-\theta_{0}\right) / \sqrt{V_{\theta}}\)。因此,保持 \(1 %\) 和 \(1 %\) 固定,\(1 %\) 与 \(1 %\) 成正比。
双边 t 检验的分析类似。 (9.18) 意味着
\[ T=\left|\frac{\widehat{\theta}-\theta_{0}}{s(\widehat{\theta})}\right| \vec{d}|Z+\delta| \]
因此双边 t 检验的局部功效为
\[ \lim _{n \rightarrow \infty} \mathbb{P}\left[\text { Reject } \mathbb{H}_{0}\right]=\lim _{n \rightarrow \infty} \mathbb{P}[T>c]=\mathbb{P}[|Z+\delta|>c]=\Phi(\delta-c)+\Phi(-\delta-c) \]
它在 \(|\delta|\) 中单调递增。
定理 9.10 在假设 7.2、7.3、7.4 和 \(\theta_{n}=r\left(\beta_{n}\right)=r_{0}+n^{-1 / 2} h\) 下,则
\[ T\left(\theta_{0}\right)=\frac{\widehat{\theta}-\theta_{0}}{s(\widehat{\theta})} \underset{d}{\longrightarrow} Z+\delta \]
其中 \(Z \sim \mathrm{N}(0,1)\) 和 \(\delta=h / \sqrt{V_{\theta}}\)。对于 \(c\) 使得 \(\Phi(c)=1-\alpha\),
\[ \mathbb{P}\left[T\left(\theta_{0}\right)>c\right] \longrightarrow \Phi(\delta-c) . \]
此外,对于 \(c\) 使得 \(\Phi(c)=1-\alpha / 2\),
\[ \mathbb{P}\left[\left|T\left(\theta_{0}\right)\right|>c\right] \longrightarrow \Phi(\delta-c)+\Phi(-\delta-c) . \]
9.23 渐近局部幂,向量情况
在本节中,我们将上一节的局部功效分析扩展到向量值替代方案的情况。我们将 (9.17) 推广到向量值 \(\theta_{n}\)。局部参数化为
\[ \theta_{n}=r\left(\beta_{n}\right)=\theta_{0}+n^{-1 / 2} h \]
其中 \(h\) 是 \(q \times 1\)。
根据(9.19),
\[ \sqrt{n}\left(\widehat{\theta}-\theta_{0}\right)=\sqrt{n}\left(\widehat{\theta}-\theta_{n}\right)+h \underset{d}{\longrightarrow} Z_{h} \sim \mathrm{N}\left(h, \boldsymbol{V}_{\theta}\right), \]
具有均值 \(h\) 和协方差矩阵 \(\boldsymbol{V}_{\theta}\) 的正态随机向量。
应用于 Wald 统计我们发现
\[ W=n\left(\widehat{\theta}-\theta_{0}\right)^{\prime} \widehat{\boldsymbol{V}}_{\theta}^{-1}\left(\widehat{\theta}-\theta_{0}\right) \underset{d}{\longrightarrow} Z_{h}^{\prime} \boldsymbol{V}_{\theta}^{-1} Z_{h} \sim \chi_{q}^{2}(\lambda) \]
其中 \(\lambda=h^{\prime} \boldsymbol{V}^{-1} h . \chi_{q}^{2}(\lambda)\) 是具有非中心参数 \(\lambda\) 的非中心卡方随机变量。 (定理 5.3.6。)
收敛(9.20)表明,在局部替代方案(9.19)下,W \(\underset{d}{ } \chi_{q}^{2}(\lambda)\)。这概括了作为特殊情况 \(\lambda=0\) 获得的零渐近分布。我们可以使用这个结果来获得幂函数的连续渐近逼近。对于任何显着性水平 \(\alpha>0\),设置渐近临界值 \(c\),以便 \(\mathbb{P}\left[\chi_{q}^{2}>c\right]=\alpha\)。然后作为 \(n \rightarrow \infty\),
\[ \mathbb{P}[W>c] \longrightarrow \mathbb{P}\left[\chi_{q}^{2}(\lambda)>c\right] \stackrel{\text { def }}{=} \pi(\lambda) . \]
渐近局部幂函数 \(\pi(\lambda)\) 仅取决于 \(\alpha, q\) 和 \(\lambda\)。
定理 9.11 在假设 7.2、7.3、7.4 和 \(\theta_{n}=r\left(\beta_{n}\right)=\theta_{0}+n^{-1 / 2} h\) 下,则 \(W \underset{d}{\longrightarrow} \chi_{q}^{2}(\lambda)\) 其中 \(\lambda=h^{\prime} \boldsymbol{V}_{\theta}^{-1} h\)。此外,对于 \(c\) 使得 \(\mathbb{P}\left[\chi_{q}^{2}>c\right]=\) \(\alpha, \mathbb{P}[W>c] \longrightarrow \mathbb{P}\left[\chi_{q}^{2}(\lambda)>c\right]\)
图 9.3(b) 将 \(\pi(\lambda)\) 绘制为 \(q=1, q=2\)、\(q=3\) 和 \(\alpha=0.05\) 的 \(\lambda\) 的函数。渐近幂函数在 \(\lambda\) 中单调递增并渐近于 1。
图 9.3(b) 还显示了随着测试维数的增加,固定非中心参数 \(\lambda\) 的功耗。随着 \(q\) 的增加,功效曲线向右移动,导致功效下降。这由 \(50 %\) 次方的虚线表示。虚线在 \(\lambda=3.85(q=1), \lambda=4.96(q=2)\) 和 \(\lambda=5.77(q=3)\) 处与三个功效曲线相交。这些 \(\lambda\) 值的比率对应于获得相同功效所需的相对样本大小。因此,将测试维度从 \(q=1\) 增加到 \(q=2\) 需要增加 \(28 %\) 样本量,或者从 \(\lambda\) 增加到 \(\lambda\) 需要增加 \(\lambda\) 样本量,以维持 $
9.24 练习
练习 9.1 证明如果在 \(\boldsymbol{X}\) 中添加一个额外的回归量 \(\boldsymbol{X}_{k+1}\),当且仅当 \(\left|T_{k+1}\right|>1\) 时,Theil 的调整后的 \(\bar{R}^{2}\) 才会增加,其中 \(T_{k+1}=\widehat{\beta}_{k+1} / s\left(\widehat{\beta}_{k+1}\right)\) 是 \(\widehat{\beta}_{k+1}\) 的 t 比率,并且
\[ s\left(\widehat{\beta}_{k+1}\right)=\left(s^{2}\left[\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\right]_{k+1, k+1}\right)^{1 / 2} \]
是同方差公式标准误差。
练习 9.2 您有两个独立样本 \(\left(Y_{1 i}, X_{1 i}\right)\) 和 \(\left(Y_{2 i}, X_{2 i}\right)\),样本大小均为 \(n\),满足 \(Y_{1}=X_{1}^{\prime} \beta_{1}+e_{1}\) 和 \(Y_{2}=X_{2}^{\prime} \beta_{2}+e_{2}\),其中 \(\mathbb{E}\left[X_{1} e_{1}\right]=0\) 和 \(\mathbb{E}\left[X_{2} e_{2}\right]=0\)。令 \(\widehat{\beta}_{1}\) 和 \(\widehat{\beta}_{2}\) 为 \(\left(Y_{1 i}, X_{1 i}\right)\) 和 \(\left(Y_{1 i}, X_{1 i}\right)\) 的 OLS 估计量。
求 \(\sqrt{n}\left(\left(\widehat{\beta}_{2}-\widehat{\beta}_{1}\right)-\left(\beta_{2}-\beta_{1}\right)\right)\) 的渐近分布为 \(n \rightarrow \infty\)。
为 \(\mathbb{H}_{0}: \beta_{2}=\beta_{1}\) 找到适当的检验统计量。
求该统计量在 \(\mathbb{H}_{0}\) 下的渐近分布。
练习 9.3 令 \(T\) 为 \(\mathbb{H}_{0}: \theta=0\) 与 \(\mathbb{H}_{1}: \theta \neq 0\) 的 t 统计量。由于\(|T| \rightarrow{ }_{d}|Z|\)低于\(\mathbb{H}_{0}\),有人建议测试“如果\(|T|<c_{1}\)或\(|T|>c_{2}\)则拒绝\(\mathbb{M}_{0}\),其中\(c_{1}\)是\(T\)的\(T\)分位数,\(T\)是\(T\) \(T\) 的分位数。
- 显示检验的渐进大小为 \(\alpha\)。 (b) 这是 \(\mathbb{M}_{0}\) 与 \(\mathbb{M}_{1}\) 的良好测试吗?为什么或者为什么不?
练习 9.4 令 \(W\) 为 \(\mathbb{M}_{0}: \theta=0\) 与 \(\mathbb{M}_{1}: \theta \neq 0\) 的 Wald 统计量,其中 \(\theta\) 为 \(q \times 1\)。由于\(W \underset{d}{\rightarrow} \chi_{q}^{2}\)低于\(H_{0}\),有人建议测试“如果\(W<c_{1}\)或\(W\)则拒绝\(\mathbb{H}_{0}\),其中\(W\)是\(W\)的\(W\)分位数,\(W\)是\(W\) \(W\) 的分位数。
显示检验的渐进大小为 \(\alpha\)。
这是 \(\mathbb{M}_{0}\) 与 \(\mathbb{H}_{1}\) 的良好测试吗?为什么或者为什么不?
练习 9.5 采用线性模型 \(Y=X_{1}^{\prime} \beta_{1}+X_{2}^{\prime} \beta_{2}+e\) 和 \(\mathbb{E}[X e]=0\),其中 \(X_{1}\) 和 \(X_{2}\) 都是 \(q \times 1\)。展示如何针对 \(\mathbb{M}_{1}: \beta_{1} \neq \beta_{2}\) 检验假设 \(\mathbb{M}_{0}: \beta_{1}=\beta_{2}\)。
练习 9.6 假设研究人员想知道 20 个回归变量中的哪一个对变量测试分数有影响。他对 20 个回归量的测试分数进行回归并报告结果。 20 个回归量(研究时间)之一具有较大的 t 比(约 2.5),而其他 t 比则微不足道(绝对值小于 2)。他认为数据表明学习时间是考试成绩的关键预测因素。你同意这个结论吗?他的推理有缺陷吗?
练习 9.7 采用模型 \(Y=X \beta_{1}+X^{2} \beta_{2}+e\) 和 \(\mathbb{E}[e \mid X]=0\),其中 \(Y\) 是工资(每小时美元),\(X\) 是年龄。描述一下如何检验 40 岁工人的预期工资为每小时 \(\$ 20\) 的假设。
练习 9.8 您想要在模型 \(Y=X_{1}^{\prime} \beta_{1}+X_{2}^{\prime} \beta_{2}+e\) 和 \(\mathbb{E}[X e]=0\) 中测试 \(\mathbb{H}_{0}: \beta_{2}=0\) 与 \(\mathbb{H}_{1}: \beta_{2} \neq 0\)。您阅读了一篇估计模型的论文
\[ Y=X_{1}^{\prime} \widehat{\gamma}_{1}+\left(X_{2}-X_{1}\right)^{\prime} \widehat{\gamma}_{2}+u \]
并报告 \(\mathbb{M}_{0}: \gamma_{2}=0\) 与 \(\mathbb{M}_{1}: \gamma_{2} \neq 0\) 的测试。这与您想要进行的测试有关吗?
练习 9.9 假设一名研究人员使用一个数据集来检验特定假设 \(\mathbb{H}_{0}\) 与 \(\mathbb{H}_{1}\) 的关系,并发现他可以拒绝 \(\mathbb{H}_{0}\)。第二位研究人员收集了一个类似但独立的数据集,使用类似的方法,发现她无法拒绝 \(\mathbb{M}_{0}\)。我们(作为感兴趣的专业人士)应该如何解释这些混合结果?
练习 9.10 在练习 \(7.8\) 中,你证明了 \(\sqrt{n}\left(\widehat{\sigma}^{2}-\sigma^{2}\right) \underset{d}{\rightarrow} \mathrm{N}(0, V)\) 对于某些 \(V\) 来说是 \(n \rightarrow \infty\)。令 \(\widehat{V}\) 为 \(V\) 的估计器。
使用此结果构造 \(\mathbb{H}_{0}: \sigma^{2}=1\) 相对于 \(\mathbb{H}_{1}: \sigma^{2} \neq 1\) 的 t 统计量。
使用 Delta 方法求 \(\sqrt{n}(\widehat{\sigma}-\sigma)\) 的渐近分布。
使用之前的结果构建 \(\mathbb{M}_{0}: \sigma=1\) 相对于 \(\mathbb{H}_{1}: \sigma \neq 1\) 的 t 统计量。
- 和 (c) 中的原假设相同还是不同? (a) 和 (c) 中的测试相同还是不同?如果它们不同,请描述两个测试会给出矛盾结果的情况。
练习9.11 考虑一个回归,例如表\(4.1\),其中包含经验及其平方。研究人员想要检验经验不会影响平均工资的假设,并通过计算经验的 t 统计量来实现这一点。这是正确的方法吗?如果不是,合适的测试方法是什么?练习 9.12 研究人员估计回归并计算 \(\mathbb{H}_{0}\) 相对于 \(\mathbb{H}_{1}\) 的检验,并找到 \(p=0.08\) 的 p 值,即“不显着”。她说:“我需要更多数据。如果我有更大的样本,测试就会有更大的功效,然后测试就会被拒绝。”这个解释正确吗?
练习9.13 一个常见的观点是“如果样本量足够大,任何假设都会被拒绝”。这是什么意思?解读并评论。
练习 9.14 采用模型 \(Y=X^{\prime} \beta+e\) 和 \(\mathbb{E}[X e]=0\) 以及感兴趣的参数 \(\theta=\boldsymbol{R}^{\prime} \beta\) 和 \(\boldsymbol{R} k \times 1\)。令 \(\widehat{\beta}\) 为最小二乘估计器,\(\widehat{\boldsymbol{V}}_{\widehat{\beta}}\) 为方差估计器。
用 \(\widehat{\beta}, \widehat{\boldsymbol{V}} \widehat{\widehat{\beta}}\)、\(\boldsymbol{R}\) 和 \(z=1.96\)(\(N(0,1))\) 的 \(97.5 %\) 分位数)写下 \(\widehat{C}\)、\(\theta\) 的 \(95 %\) 渐近置信区间。
表明决策“如果 \(\theta_{0} \notin \widehat{C}\) 则拒绝 \(\mathbb{M}_{0}\)”是 \(\mathbb{M}_{0}: \theta=\theta_{0}\) 的渐近 \(5 %\) 检验。
练习 9.15 您正在参加一个研讨会,一位同事演示了对名义规模为 \(5 %\) 的假设 \(\mathbb{H}_{0}\) 进行检验的模拟研究。根据 \(\mathbb{H}_{0}\) 下的 \(B=100\) 模拟复制,估计大小为 \(7 %\)。你的同事说:“不幸的是,测试过度拒绝了。”
您同意还是不同意您同事的观点?解释。提示:使用渐近(大 B)近似。
假设模拟重复次数为 \(B=1000\),但估计大小仍为 \(7 %\)。你的答案有变化吗?
练习9.16 考虑两种替代回归模型
\[ \begin{aligned} Y &=X_{1}^{\prime} \beta_{1}+e_{1} \\ \mathbb{E}\left[X_{1} e_{1}\right] &=0 \\ Y &=X_{2}^{\prime} \beta_{2}+e_{2} \\ \mathbb{E}\left[X_{2} e_{2}\right] &=0 \end{aligned} \]
其中 \(X_{1}\) 和 \(X_{2}\) 至少有一些不同的回归量。 (例如,(9.21) 是地理变量的工资回归,(2) 是个人外表测量的工资回归。)您想知道模型 (9.21) 还是模型 (9.22) 是否更适合数据。定义 \(\sigma_{1}^{2}=\mathbb{E}\left[e_{1}^{2}\right]\) 和 \(\sigma_{2}^{2}=\mathbb{E}\left[e_{2}^{2}\right]\)。您决定方差拟合较小的模型(例如,如果 \(\sigma_{1}^{2}<\sigma_{2}^{2}\),则模型 (9.21) 拟合得更好。)您决定通过测试相等拟合 \(\mathbb{H}_{0}: \sigma_{1}^{2}=\sigma_{2}^{2}\) 的假设与不相等拟合 \(\mathbb{H}_{1}: \sigma_{1}^{2} \neq \sigma_{2}^{2}\) 的替代方案来测试这一点。为简单起见,假设观察到 \(e_{1 i}\) 和 \(e_{2 i}\)。
构造 \(\theta=\sigma_{1}^{2}-\sigma_{2}^{2}\) 的估计器 \(\widehat{\theta}\)。
求 \(\sqrt{n}(\widehat{\theta}-\theta)\) 的渐近分布为 \(n \rightarrow \infty\)。
求 \(\widehat{\theta}\) 渐近方差的估计量。
提出对 \(\mathbb{M}_{0}\) 的渐近大小 \(\alpha\) 与 \(\mathbb{M}_{1}\) 进行检验。
假设测试接受 \(\mathbb{M}_{0}\)。简单来说,你的解释是什么?练习 9.17 你有两个回归量 \(X_{1}\) 和 \(X_{2}\) 并估计包含所有二次项的回归
\[ Y=\alpha+\beta_{1} X_{1}+\beta_{2} X_{2}+\beta_{3} X_{1}^{2}+\beta_{4} X_{2}^{2}+\beta_{5} X_{1} X_{2}+e . \]
你的一位顾问问:我们可以从这个回归中排除变量 \(X_{2}\) 吗?
您如何将这个问题转化为统计测试?回答这些问题时,要具体,不要笼统。
相关的原假设和备择假设是什么?
什么是适当的检验统计量?
统计量的适当渐近分布是什么?
接受/拒绝原假设的规则是什么?
练习9.18 观察到的数据是\(\left\{Y_{i}, X_{i}, Z_{i}\right\} \in \mathbb{R} \times \mathbb{R}^{k} \times \mathbb{R}^{\ell}, k>1\)和\(\ell>1, i=1, \ldots, n\)。计量经济学家首先通过最小二乘法估计 \(Y_{i}=X_{i}^{\prime} \widehat{\beta}+\widehat{e}_{i}\)。接下来,计量经济学家将残差 \(\widehat{e}_{i}\) 回归到 \(Z_{i}\) 上,可以写为 \(\widehat{e}_{i}=Z_{i}^{\prime} \widetilde{\gamma}+\widetilde{u}_{i}\)。
定义在第二个回归中估计的总体参数 \(\gamma\)。
求 \(\widetilde{\gamma}\) 的概率极限。
假设计量经济学家根据第二次回归为 \(\mathbb{H}_{0}: \gamma=0\) 构造 Wald 统计量 \(W\),忽略两阶段估计过程。写下 \(W\) 的公式。
假设 \(\mathbb{E}\left[Z X^{\prime}\right]=0\)。求 \(W\) 在 \(\mathbb{M}_{0}: \gamma=0\) 下的渐近分布。
如果 \(\mathbb{E}\left[Z X^{\prime}\right] \neq 0\) 你对 (d) 的答案会改变吗?
练习 9.19 一位经济学家通过最小二乘法估计 \(Y=X_{1}^{\prime} \beta_{1}+X_{2} \beta_{2}+e\) 并对照 \(\mathbb{H}_{1}: \beta_{2} \neq 0\) 检验假设 \(\mathbb{H}_{0}: \beta_{2}=0\)。假设 \(\beta_{1} \in \mathbb{R}^{k}\) 和 \(\beta_{2} \in \mathbb{R}\)。她获得 Wald 统计量 \(W=0.34\)。样本大小为 \(n=500\)。
用于评估 Wald 统计量显着性的 \(\chi^{2}\) 分布的正确自由度是多少?
Wald 统计量 \(W\) 非常小。事实上,它是否小于适当的 \(\chi^{2}\) 分布的 \(1 %\) 分位数?如果是这样,您应该拒绝 \(\mathbb{H}_{0}\) 吗?解释你的推理。
练习 9.20 你正在阅读一篇论文,它报告了两个嵌套 OLS 回归的结果:
\[ \begin{aligned} &Y_{i}=X_{1 i}^{\prime} \widetilde{\beta}_{1}+\widetilde{e}_{i} \\ &Y_{i}=X_{1 i}^{\prime} \widehat{\beta}_{1}+X_{2 i}^{\prime} \widehat{\beta}_{2}+\widehat{e}_{i} . \end{aligned} \]
报告了一些汇总统计数据:
\[ \begin{array}{ll} \text { Short Regression } & \text { Long Regression } \\ R^{2}=.20 & R^{2}=.26 \\ \sum_{i=1}^{n} \widetilde{e}_{i}^{2}=106 & \sum_{i=1}^{n} \widehat{e}_{i}^{2}=100 \\ \# \text { of coefficients }=5 & \# \text { of coefficients }=8 \\ n=50 & n=50 \end{array} \]
您很好奇估计 \(\widehat{\beta}_{2}\) 是否在统计上与零向量不同。有没有办法从这些信息中确定答案?您是否必须做出任何假设(超出标准正则条件)才能证明您的答案是合理的?练习 9.21 采用模型 \(Y=X_{1} \beta_{1}+X_{2} \beta_{2}+X_{3} \beta_{3}+X_{4} \beta_{4}+e\) 和 \(\mathbb{E}[X e]=0\)。描述如何测试
\[ \mathbb{M}_{0}: \frac{\beta_{1}}{\beta_{2}}=\frac{\beta_{3}}{\beta_{4}} \]
反对
\[ \mathbb{M}_{1}: \frac{\beta_{1}}{\beta_{2}} \neq \frac{\beta_{3}}{\beta_{4}} . \]
练习 9.22 您从模型 \(Y=X \beta_{1}+X^{2} \beta_{2}+e\) 和 \(\mathbb{E}[e \mid X]=0\) 中获得了一个随机样本,其中 \(Y\) 是工资(每小时美元),\(X\) 是年龄。描述一下如何检验 40 岁工人的预期工资为每小时 \(\$ 20\) 的假设。
练习 9.23 令 \(T\) 为检验统计量,使得其在 \(\mathbb{M}_{0}, T \underset{d}{\longrightarrow} \chi_{3}^{2}\) 下。从 \(\mathbb{P}\left[\chi_{3}^{2}>7.815\right]=0.05\) 开始,\(\mathbb{H}_{0}\) 的渐近 \(5 %\) 检验在 \(T>7.815\) 时会被拒绝。当 \(n=100\) 和数据结构被明确指定时,计量经济学家对该测试的 I 类错误感兴趣。她进行了以下蒙特卡罗实验。
大小为 \(n=100\) 的 \(B=200\) 样本是根据满足 \(\mathbb{H}_{0}\) 的分布生成的。
对于每个样本,计算检验统计量 \(T_{b}\)。
她计算\(\hat{p}=B^{-1} \sum_{b=1}^{B} \mathbb{1}\left\{T_{b}>7.815\right\}=0.070\)。
计量经济学家得出结论,测试 \(T\) 在这种情况下过大 - 它在 \(\mathbb{M}_{0}\) 下过于频繁地拒绝。
她的结论是正确的、不正确的还是不完整的?回答要具体。
练习 9.24 进行蒙特卡罗模拟。采用模型 \(Y=\alpha+X \beta+e\) 和 \(\mathbb{E}[X e]=0\),其中感兴趣的参数是 \(\theta=\exp (\beta)\)。用于模拟的数据生成过程 (DGP) 是:\(X\) 是 \(U[0,1]\),\(e \sim \mathrm{N}(0,1)\) 独立于 \(X\),\(n=50\)。设置 \(\alpha=0\) 和 \(Y=\alpha+X \beta+e\)。使用 \(Y=\alpha+X \beta+e\) 生成 \(Y=\alpha+X \beta+e\) 独立样本。对于每一个,通过最小二乘估计回归,使用标准(异方差稳健)公式计算协方差矩阵,并类似地估计 \(Y=\alpha+X \beta+e\) 及其标准误差。对于每个复制,存储 \(Y=\alpha+X \beta+e\) 和 \(Y=\alpha+X \beta+e\)。
\(\alpha\) 的值重要吗?解释为什么所描述的统计数据对于 \(\alpha\) 是不变的,因此设置 \(\alpha=0\) 是无关紧要的。
从 1000 次重复中估计 \(\mathbb{E}[\widehat{\beta}]\) 和 \(\mathbb{E}[\widehat{\theta}]\)。讨论您是否看到证据表明任一估计量是有偏的还是无偏的。
从 1000 次重复中估计 \(\mathbb{P}\left[T_{\beta}>1.645\right]\) 和 \(\mathbb{P}\left[T_{\theta}>1.645\right]\)。渐近理论预测大样本中的这些概率应该是多少?你的模拟结果表明什么?
练习 9.25 教科书网站上的数据集 Invest1993 包含从 Compustat 中提取的 1962 年美国公司的数据,由 Bronwyn Hall 汇编,并在 Hall 和 Hall (1993) 中使用。
我们在本练习中使用的变量如下表所示。流量变量是年度总和。库存变量是年初的。
| year | year of the observation | |
|---|---|---|
| \(I\) | inva | Investment to Capital Ratio |
| \(Q\) | vala | Total Market Value to Asset Ratio (Tobin’s Q) |
| \(C\) | cfa | Cash Flow to Asset Ratio |
| \(D\) | debta | Long Term Debt to Asset Ratio |
提取 1987 年观测值的子样本。应该有 1028 个观测值。估计其他变量的 \(I\)(投资与资本比率)的线性回归。计算适当的标准误差。
计算系数的渐近置信区间。
这种回归与托宾的 \(q\) 投资理论相关,该理论表明投资应该仅由 \(Q\) (托宾的 \(Q\) )来预测。该理论预测 \(Q\) 的系数应为正,其他系数应为零。检验现金流量 \((C)\) 和债务 \((D)\) 的系数为零的联合假设。检验 \(Q\) 上的系数为零的假设。结果与理论预测一致吗?
现在尝试非线性(二次)规范。在 \(Q, C, D, Q^{2}, C^{2}, D^{2}, Q \times C, Q \times D, C \times D\) 上回归 \(I\)。检验六个交互作用和二次系数为零的联合假设。
练习 9.26 在 1963 年的一篇论文中,Marc Nerlove 分析了 145 家美国电力公司的成本函数。 Nerlov 对估计成本函数感兴趣:\(C=f(Q, P L, P F, P K)\),其中变量列于下表中。他的数据集Nerlove1963在教科书网站上。
| C | Total Cost |
|---|---|
| Q | Output |
| PL | Unit price of labor |
| PK | Unit price of capital |
| PF | Unit price of fuel |
- 首先,估计无限制的柯布-道格拉斯规范
\[ \log C=\beta_{1}+\beta_{2} \log Q+\beta_{3} \log P L+\beta_{4} \log P K+\beta_{5} \log P F+e . \]
报告参数估计值和标准误差。
限制 \(\mathbb{H}_{0}: \beta_{3}+\beta_{4}+\beta_{5}=1\) 的经济意义是什么?
通过施加 \(\beta_{3}+\beta_{4}+\beta_{5}=1\) 的约束最小二乘法估计 (9.23)。报告您的参数估计值和标准误差。
通过施加 \(\beta_{3}+\beta_{4}+\beta_{5}=1\) 的有效最小距离来估计 (9.23)。报告您的参数估计值和标准误差。
使用 Wald 统计量测试 \(\mathbb{H}_{0}: \beta_{3}+\beta_{4}+\beta_{5}=1\)。
使用最小距离统计量测试 \(\mathbb{H}_{0}: \beta_{3}+\beta_{4}+\beta_{5}=1\)。练习 9.27 在第 8.12 节中,我们报告了 Mankiw、Romer 和 Weil (1992) 的估计。我们报告了通过无限制最小二乘法和约束估计进行的估计,并施加索洛增长理论所暗示的三个系数( \(2^{n d}, 3^{r d}\) 和 \(4^{t h}\) 系数)总和为零的约束。使用相同的数据集 MRW1992 估计无限制模型并测试三个系数总和为零的假设。
练习 9.28 使用 cps09mar 数据集和非西班牙裔黑人的子样本(种族代码 \(=2\) )检验婚姻状况不影响平均工资的假设。
采用表 4.1 中报告的回归。需要忽略哪些变量来估计该子样本的回归?
提出假设“婚姻状况不影响平均工资”作为对系数的限制。这是多少限制?
求出该假设的 Wald(或 F)统计量。检验统计量的适当分布是什么?计算检验的 p 值。
你得出什么结论?
练习 9.29 使用 cps09mar 数据集以及非西班牙裔黑人个体(种族代码 \(=2\) )和白人个体(种族代码 \(=1\) )的子样本检验教育回报在各群体中普遍存在的假设。
通过虚拟变量与教育的相互作用,允许四个群体(白人男性、白人女性、黑人男性、黑人女性)的教育回报率有所不同。估计表 4.1 中报告的回归的适当版本。
求出该假设的 Wald(或 F)统计量。检验统计量的适当分布是什么?计算检验的 p 值。
(丙)你得出什么结论?