第19章: 非参数回归
19 非参数回归
19.1 介绍
我们现在转向条件期望函数(CEF)的非参数估计
\[ \mathbb{E}[Y \mid X=x]=m(x) . \]
除非经济模型将 \(m(x)\) 的形式限制为参数函数,否则 \(m(x)\) 可以采用任何非线性形状,因此是非参数的。在本章中,我们讨论 \(m(x)\) 的非参数核平滑估计器。这些与《经济学家概率与统计》第 17 章的非参数密度估计相关。在本教科书的第 20 章中,我们探讨了级数方法的估计。
关于非参数回归估计有许多优秀的专着,包括 Härdle (1990)、Fan 和 Gijbels (1996)、Pagan 和 Ullah (1999) 以及 Li 和 Racine (2007)。
首先,假设有一个实值回归量 \(X\)。我们稍后考虑向量值回归量的情况。非参数回归模型是
\[ \begin{aligned} Y &=m(X)+e \\ \mathbb{E}[e \mid X] &=0 \\ \mathbb{E}\left[e^{2} \mid X\right] &=\sigma^{2}(X) . \end{aligned} \]
我们假设我们对 \((Y, X)\) 对有 \(n\) 观测值。目标是在单个点 \(x\) 或一组点处估计 \(m(x)\)。对于我们的大部分理论,我们重点关注单个点 \(x\) 的估计,该点位于 \(X\) 支撑的内部。
除了传统的回归假设之外,我们还假设 \(m(x)\) 和 \(f(x)\) (\(X\) 的边际密度)在 \(x\) 中是连续的。对于我们的理论处理,我们假设观察结果是独立同分布的。这些方法扩展到相关观察,但理论更先进。参见 Fan 和 Yao (2003)。我们在 19.20 节中讨论聚类观察。
19.2 分箱均值估计器
为了清楚起见,固定点 \(x\) 并考虑 \(m(x)\) 的估计。这是\(Y\) 对随机对\((Y, X)\) 的期望,使得\(X=x\)。如果 \(X\) 的分布是离散的,那么我们可以通过对 \(X_{i}=x\) 的观测值 \(Y_{i}\) 的子样本取平均值来估计 \(m(x)\)。但当 \(x\) 连续时,\(x\) 完全等于 \(x\) 的概率为零。因此,\(x\) 不存在观测值的子样本,这种估计想法是不可行的。然而,如果 \(x\) 是连续的,那么应该可以通过取 \(x\) 接近 \(x\) 的观测值的平均值来获得良好的近似值,也许对于某些小的 \(x\) 的观测值数学18$。对于密度估计的情况,我们将 \(x\) 称为带宽。这个分箱均值估计器可以写成
\[ \widehat{m}(x)=\frac{\sum_{i=1}^{n} \mathbb{1}\left\{\left|X_{i}-x\right| \leq h\right\} Y_{i}}{\sum_{i=1}^{n} \mathbb{1}\left\{\left|X_{i}-x\right| \leq h\right\}} . \]
这是回归函数 \(m(x)\) 的阶跃函数估计器。
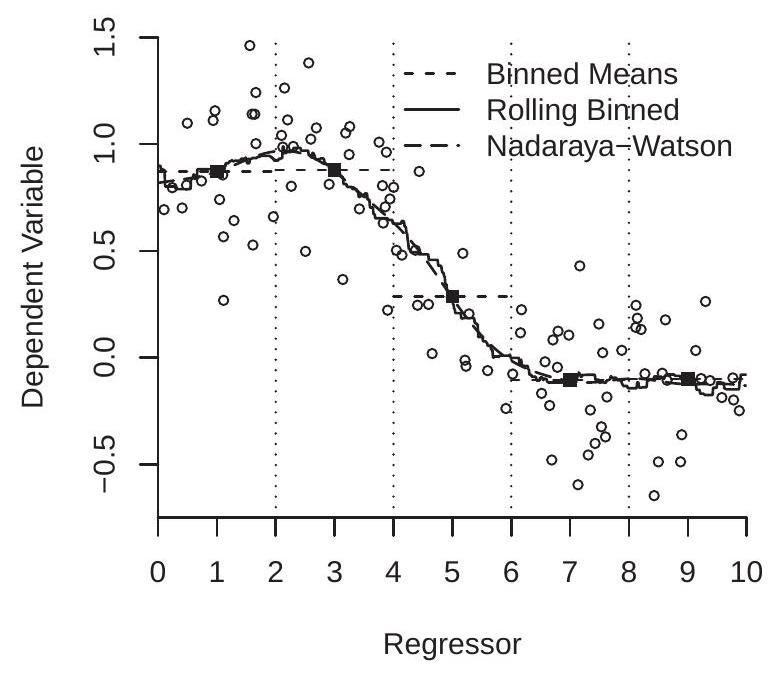
- 纳达拉亚-沃森
.jpg)
- 局部线性
图 19.1:Nadaraya-Watson 和局部线性回归
为了可视化,图 19.1(a) 显示了模拟生成的 100 个随机对 \(\left(Y_{i}, X_{i}\right)\) 的散点图。观察结果显示为空心圆圈。 \(x=1\) 和 \(h=1\) 处的 \(m(x)\) 的估计量 (19.1) 是 \(Y_{i}\) 观测值的平均值,使得 \(X_{i}\) 落在区间 [ \(\left.0 \leq X_{i} \leq 2\right]\) 中。该估计量为 \(\widehat{m}(1)\),如图 19.1(a) 中的第一个实心方块所示。我们对 \(x=3\)、5,7 和 9 重复计算 (19.1),这相当于将 \(\left(Y_{i}, X_{i}\right)\) 的支持度划分为 \(\left(Y_{i}, X_{i}\right)\)、[2,4]、\(\left(Y_{i}, X_{i}\right)\) 和 \(\left(Y_{i}, X_{i}\right)\)。这些箱如图 19.1(a) 中的垂直虚线所示,估计值 \(\left(Y_{i}, X_{i}\right)\) 由五个实心方块所示。
分箱估计量 \(\widehat{m}(x)\) 是阶跃函数,它在每个分箱内都是恒定的,并且等于分箱均值。在图 19.1(a) 中,它由穿过实心方块的水平虚线显示。该估计大致跟踪了观测值 \(\left(Y_{i}, X_{i}\right)\) 分散的集中趋势。然而,分区边缘的巨大跳跃令人不安、违反直觉,并且显然是离散分箱的产物。
如果我们再看一下估计公式(19.1),就没有理由只在路线网格上评估(19.1)。我们可以针对 \(x\) 的任意一组值来评估 \(\widehat{m}(x)\)。特别是,我们可以在 \(x\) 值的精细网格上评估(19.1),从而获得 CEF 的更平滑估计。该估计量如图 19.1(a) 中的实线所示。我们将此估计量称为“滚动分级均值”。这是分箱估计器的概括,并且通过实心方块进行构建。事实证明,这是下一节中考虑的 Nadaraya-Watson 估计器的特例。该估计量虽然不如 Binned Means 估计量那么突然,但仍然相当锯齿状。
19.3 核回归
估计器 (19.1) 的一个缺陷是,即使在精细网格上评估,它也是 \(x\) 中的阶跃函数。这就是为什么图 \(19.1\) 中的图是锯齿状的。不连续性的根源在于权重是不连续的指标函数。如果权重是连续函数,那么 \(\widehat{m}(x)\) 在 \(x\) 中也将是连续的。适当的权重函数称为核函数。
定义 19.1 (二阶)核函数 \(K(u)\) 满足
1.\(0 \leq K(u) \leq \bar{K}<\infty\)
- \(K(u)=K(-u)\),
3.\(\int_{-\infty}^{\infty} K(u) d u=1\),
- \(\int_{-\infty}^{\infty}|u|^{r} K(u) d u<\infty\) 表示所有正整数 \(r\)。
本质上,核函数是关于零对称的有界概率密度函数。假设 19.1.4 对于大多数结果来说并不是必需的,但它是一种方便的简化,并且不排除标准经验实践中使用的任何核函数。如果我们将注意力限制在方差归一化为单位的核上,一些数学表达式就会被简化。
定义 19.2 归一化核函数满足 \(\int_{-\infty}^{\infty} u^{2} K(u) d u=1\)。
有大量函数满足定义 19.1,并且许多函数被编程为统计包中的选项。我们在下面的表 \(19.1\) 中列出了最重要的:矩形、高斯、Epanechnikov、三角形和双权核。实际上,没有必要考虑这五个之外的内核。对于非参数回归,我们建议使用高斯核或 Epanechnikov 核,两者都会给出类似的结果。在表 \(19.1\) 中,我们以标准化形式表示内核。
有关核函数的更多讨论,请参阅《经济学家的概率与统计》第 17 章。 (19.1) 的推广是通过用核函数替换指示函数来获得的:
\[ \widehat{m}_{\mathrm{nw}}(x)=\frac{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) Y_{i}}{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)} . \]
估计器 (19.2) 被称为 Nadaraya-Watson 估计器、核回归估计器或局部常数估计器,由 Nadaraya (1964) 和 Watson (1964) 独立引入。
滚动分箱均值估计器 (19.1) 是具有矩形核的 Nadarya-Watson 估计器。 Nadaraya-Watson 估计器 (19.2) 可与任何标准内核一起使用,并且通常使用高斯或 Epanechnikov 内核进行估计。一般来说,我们推荐使用高斯核,因为它产生一个估计器 \(\widehat{m}_{\mathrm{nw}}(x)\) ,它拥有所有阶数的导数。
带宽 \(h\) 在核回归中的作用与在核密度估计中的作用类似。也就是说,较大的 \(h\) 值将导致估计值 \(\widehat{m}_{\mathrm{nw}}(x)\) 在 \(x\) 中更加平滑,而较小的 \(h\) 值将导致估计值更加不稳定。考虑两种极端情况可能会有所帮助 \(h \rightarrow 0\) 表 19.1:常见的归一化二阶核

和 \(h \rightarrow \infty\)。作为 \(h \rightarrow 0\),我们可以看到 \(\widehat{m}_{\mathrm{nw}}\left(X_{i}\right) \rightarrow Y_{i}\)(如果 \(X_{i}\) 的值是唯一的),因此 \(\widehat{m}_{\mathrm{nw}}(x)\) 只是 \(Y_{i}\) 在 \(X_{i}\) 上的散点。相反,\(h \rightarrow \infty\) 然后 \(\widehat{m}_{\mathrm{nw}}(x) \rightarrow \bar{Y}\),即样本平均值。对于 \(h \rightarrow \infty\) 的中间值将在这两种极端情况之间平滑。
使用高斯核和 \(h=1 / \sqrt{3}\) 的估计器 (19.2) 也显示在图 19.1(a) 中,并带有长破折号。正如您所看到的,该估计器似乎比分箱估计器平滑得多,但跟踪完全相同的路径。高斯核的带宽 \(h=1 / \sqrt{3}\) 相当于分箱估计器的带宽 \(h=1\),因为后者是使用缩放为标准差 \(1 / 3\) 的矩形核的核估计器。
19.4 局部线性估计器
Nadaraya-Watson (NW) 估计器通常称为局部常数估计器,因为它局部(大约 \(x\) )将 \(m(x)\) 近似为常数函数。看到这一点的一种方法是观察 \(\widehat{m}_{\mathrm{nw}}(x)\) 解决了最小化问题
\[ \widehat{m}_{\mathrm{nw}}(x)=\underset{m}{\operatorname{argmin}} \sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)\left(Y_{i}-m\right)^{2} . \]
这是 \(Y\) 仅在截距上的加权回归。
这意味着 NW 估计器正在对 \(X \simeq x\) 进行局部近似 \(m(X) \simeq m(x)\),这意味着它正在进行近似
\[ Y=m(X)+e \simeq m(x)+e . \]
NW 估计器是使用加权最小二乘法的该近似模型的局部估计器。
这种解释表明我们可以通过替代局部近似来构造 \(m(x)\) 的替代非参数估计量。许多这样的局部近似是可能的。一种流行的选择是局部线性 (LL) 近似。 LL 使用线性近似 \(m(X) \simeq m(x)+m^{\prime}(x)(X-x)\) 代替近似 \(m(X) \simeq m(x)\)。因此
\[ Y=m(X)+e \simeq m(x)+m^{\prime}(x)(X-x)+e . \]
然后,LL 估计器应用与 NW 估计类似的加权最小二乘法。
表示 LL 估计器的一种方法是作为最小化问题的解决方案
\[ \left\{\widehat{m}_{\mathrm{LL}}(x), \widehat{m}_{\mathrm{LL}}^{\prime}(x)\right\}=\underset{\alpha, \beta}{\operatorname{argmin}} \sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)\left(Y_{i}-\alpha-\beta\left(X_{i}-x\right)\right)^{2} . \]
另一种方法是将近似模型写为
\[ Y \simeq Z(X, x)^{\prime} \beta(x)+e \]
其中 \(\beta(x)=\left(m(x), m^{\prime}(x)\right)^{\prime}\) 和
\[ Z(X, x)=\left(\begin{array}{c} 1 \\ X-x \end{array}\right) . \]
这是一个带有回归向量 \(Z_{i}(x)=Z\left(X_{i}, x\right)\) 和系数向量 \(\beta(x)\) 的线性回归。应用加权最小二乘法和核权重,我们得到 LL 估计器
\[ \begin{aligned} \widehat{\beta}_{\mathrm{LL}}(x) &=\left(\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) Z_{i}(x) Z_{i}(x)^{\prime}\right)^{-1} \sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) Z_{i}(x) Y_{i} \\ &=\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1} \boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Y} \end{aligned} \]
其中 \(\boldsymbol{K}=\operatorname{diag}\left\{K\left(\left(X_{1}-x\right) / h\right), \ldots, K\left(\left(X_{n}-x\right) / h\right)\right\}, \boldsymbol{Z}\) 是堆叠的 \(Z_{i}(x)^{\prime}\),\(\boldsymbol{Y}\) 是堆叠的 \(Y_{i}\)。该表达式概括了 Nadaraya-Watson 估计器,因为后者是通过设置 \(Z_{i}(x)=1\) 或约束 \(\beta=0\) 获得的。请注意,矩阵 \(\boldsymbol{Z}\) 和 \(\boldsymbol{K}\) 取决于 \(x\) 和 \(\boldsymbol{K}=\operatorname{diag}\left\{K\left(\left(X_{1}-x\right) / h\right), \ldots, K\left(\left(X_{n}-x\right) / h\right)\right\}, \boldsymbol{Z}\)。
局部线性估计器首先由 Stone (1977) 提出,并通过 Fan (1992, 1993) 的工作而受到重视。
为了可视化,图 19.1(b) 显示了面板 (a) 中相同 100 个观测值的散点图,这些观测值被划分为相同的 5 个箱。线性回归适合每个箱中的观察结果。这五个拟合回归线由短虚线显示。这种“分箱回归估计器”为 CEF 生成灵活的近似值,但在分区边缘有较大的跳跃。这五个回归线中每一个的中点均由实心方块显示,并且可以被视为分箱回归估计器的目标估计。分箱回归估计器的滚动版本在 \(X\) 的支持上连续移动这些估计窗口,并通过实线显示。这对应于具有矩形内核和 \(h=1 / \sqrt{3}\) 带宽的局部线性估计器。通过构造,这条线穿过实心正方形。为了获得更平滑的估计器,我们用高斯核替换矩形(使用相同的带宽 \(h=1 / \sqrt{3}\) )。我们用长破折号显示这些估计值。它与矩形核估计(滚动分箱回归)具有相同的形状,但视觉上更平滑。我们将其标记为“局部线性”估计器,因为它是标准实现。一个有趣的特性是,当 \(h \rightarrow \infty\) 时,LL 估计器接近全样本最小二乘估计器 \(\widehat{m}_{\mathrm{LL}}(x) \rightarrow \widehat{\alpha}+\widehat{\beta} x\)。这是因为作为 \(h \rightarrow \infty\),所有观察结果都具有相同的权重。从这个意义上说,LL 估计器是线性 OLS 估计器的灵活推广。
LL 估计器的另一个有用属性是,它同时提供回归函数 \(m(x)\) 及其在 \(x\) 处的斜率 \(m^{\prime}(x)\) 的估计。
19.5 局部多项式估计器
NW 和 LL 估计器都是局部多项式估计器的特例。这个想法是通过固定次数 \(p\) 的多项式来近似回归函数 \(m(x)\),然后使用核权重进行本地估计。
近似模型是 \(p^{\text {th }}\) 阶泰勒级数近似
\[ \begin{aligned} Y &=m(X)+e \\ & \simeq m(x)+m^{\prime}(x)(X-x)+\cdots+m^{(p)}(x) \frac{(X-x)^{p}}{p !}+e \\ &=Z(X, x)^{\prime} \beta(x)+e_{i} \end{aligned} \]
在哪里
\[ Z(X, x)=\left(\begin{array}{c} 1 \\ X-x \\ \vdots \\ \frac{(X-x)^{p}}{p !} \end{array}\right) \quad \beta(x)=\left(\begin{array}{c} m(x) \\ m^{\prime}(x) \\ \vdots \\ m^{(p)}(x) \end{array}\right) \]
估计量是
\[ \begin{aligned} \widehat{\beta}_{\mathrm{LP}}(x) &=\left(\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) Z_{i}(x) Z_{i}(x)^{\prime}\right)^{-1}\left(\sum_{i=1}^{n} K\left(\frac{Y_{i}-x}{h}\right) Z_{i}(x) Y_{i}\right) \\ &=\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1} \boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Y} \end{aligned} \]
其中 \(Z_{i}(x)=Z\left(X_{i}, x\right)\) 请注意,此表达式包括 Nadaraya-Watson 和局部线性估计器,分别作为 \(p=0\) 和 \(p=1\) 的特殊情况。
多项式阶数 \(p\) 和局部平滑带宽 \(h\) 之间存在权衡。通过增加 \(p\),我们改进了模型近似,从而可以使用更大的带宽 \(h\)。另一方面,增加 \(p\) 会增加估计方差。
19.6 渐近偏差
自 \(\mathbb{E}[Y \mid X=x]=m(x)\) 起,Nadaraya-Watson 估计量的条件期望为
\[ \mathbb{E}\left[\widehat{m}_{\mathrm{nw}}(x) \mid \boldsymbol{X}\right]=\frac{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) \mathbb{E}\left[Y_{i} \mid X_{i}\right]}{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)}=\frac{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) m\left(X_{i}\right)}{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)} . \]
我们可以将此表达式简化为 \(n \rightarrow \infty\)。
本章将保持以下规律性条件。令 \(f(x)\) 表示 \(X\) 的边际密度,让 \(\sigma^{2}(x)=\mathbb{E}\left[e^{2} \mid X=x\right]\) 表示 \(e=Y-m(X)\) 的条件方差。
假设 $19.1
1.\(h \rightarrow 0\)。
2.\(n h \rightarrow \infty\)。
- \(m(x), f(x)\) 和 \(\sigma^{2}(x)\) 在 \(x\) 的某个邻域 \(\mathscr{N}\) 中连续。
4.\(f(x)>0\)。
这些条件类似于用于核密度估计的渐近理论的条件。假设 \(h \rightarrow 0\) 和 \(n h \rightarrow \infty\) 意味着带宽变小,但估计窗口中的观测值数量却趋于无穷大。假设 19.1.3 是条件期望 \(m(x)\)、边际密度 \(f(x)\) 和条件方差 \(\sigma^{2}(x)\) 的最小平滑条件。假设 19.1.4 指定边际密度不为零。这是必需的,因为我们正在估计 \(x\) 的条件期望,因此 \(X_{i}\) 需要在 \(x\) 附近有大量的观测值。
定理 19.1 假设假设 \(19.1\) 成立且 \(m^{\prime \prime}(x)\) 和 \(f^{\prime}(x)\) 在 \(\mathscr{N}\) 中连续。然后作为 \(n n \rightarrow \infty\) 和 \(h \rightarrow 0\)
1.\(\mathbb{E}\left[\widehat{m}_{\mathrm{nw}}(x) \mid \boldsymbol{X}\right]=m(x)+h^{2} B_{\mathrm{nw}}(x)+o_{p}\left(h^{2}\right)+O_{p}\left(\sqrt{\frac{h}{n}}\right)\)
在哪里
\[ B_{\mathrm{nw}}(x)=\frac{1}{2} m^{\prime \prime}(x)+f(x)^{-1} f^{\prime}(x) m^{\prime}(x) . \]
1.\(\mathbb{E}\left[\widehat{m}_{\mathrm{LL}}(x) \mid \boldsymbol{X}\right]=m(x)+h^{2} B_{\mathrm{LL}}(x)+o_{p}\left(h^{2}\right)+O_{p}\left(\sqrt{\frac{h}{n}}\right)\)
在哪里
\[ B_{\mathrm{LL}}(x)=\frac{1}{2} m^{\prime \prime}(x) . \]
Nadaraya-Watson 估计器的证明在第 19.26 节中给出。有关局部线性估计器的证明,请参阅 Fan 和 Gijbels (1996)。
我们将 \(h^{2} B_{\mathrm{nw}}(x)\) 和 \(h^{2} B_{\mathrm{LL}}(x)\) 称为估计量的渐近偏差。
定理 19.1 显示 Nadaraya-Watson 和局部线性估计器的渐近偏差与平方带宽 \(h^{2}\)(平滑程度)以及函数 \(B_{\mathrm{nw}}(x)\) 和 \(B_{\mathrm{LL}}(x)\) 成正比。局部线性估计量的渐近偏差取决于 CEF 函数 \(m(x)\) 的曲率(二阶导数),类似于《经济学家概率与统计》定理 \(17.1\) 中核密度估计量的渐近偏差。当 \(m^{\prime \prime}(x)<0\) 时,\(\hat{m}_{\mathrm{LL}}(x)\) 向下偏置。当 \(m^{\prime \prime}(x)>0\) 时,\(\widehat{m}_{\mathrm{LL}}(x)\) 向上偏置。局部平均平滑 \(h^{2}\),从而产生偏差,并且这种偏差在 \(h^{2}\) 的曲率水平上不断增加。这称为平滑偏差。
Nadaraya-Watson 估计量的渐近偏差添加了第二项,该项取决于 \(m(x)\) 和 \(f(x)\) 的一阶导数。这是因为 Nadaraya-Watson 估计量是局部平均值。如果密度在 \(x\) 处向上倾斜(如果 \(f^{\prime}(x)>0\) ),则(平均而言)\(x\) 右侧的观测值多于左侧,因此如果 \(m(x)\) 具有非- 零斜率。相反,局部线性估计器的偏差不依赖于局部斜率 \(m^{\prime}(x)\),因为它局部拟合线性回归。局部线性估计器的偏差比 Nadaraya-Watson 估计器的偏差具有更少的项(并且对斜率 \(m^{\prime}(x)\) 不变)这一事实证明了局部线性估计器相对于 Nadaraya-Watson 普遍减少了偏差的说法。
我们在图 19.2 中说明了渐近平滑偏差。实线是图 19.1 中显示的数据的真实 CEF。虚线是带宽 \(h=1 / 2, h=1\) 和 \(h=3 / 2\) 的期望 \(m(x)+\)、\(h^{2} B(x)\) 的渐近近似值。 (NW 和 LL 估计量的渐近偏差是相同的,因为 \(X\) 具有均匀分布。)您可以看到,最小带宽的偏差最小,但最大带宽的偏差相当大。虚线是 CEF 的平滑版本,减弱了峰值和谷值。
平滑偏差是非线性函数非参数估计的自然副产品。只能通过使用较小的带宽来减少。正如我们在下一节中看到的,这将导致较高的估计方差。
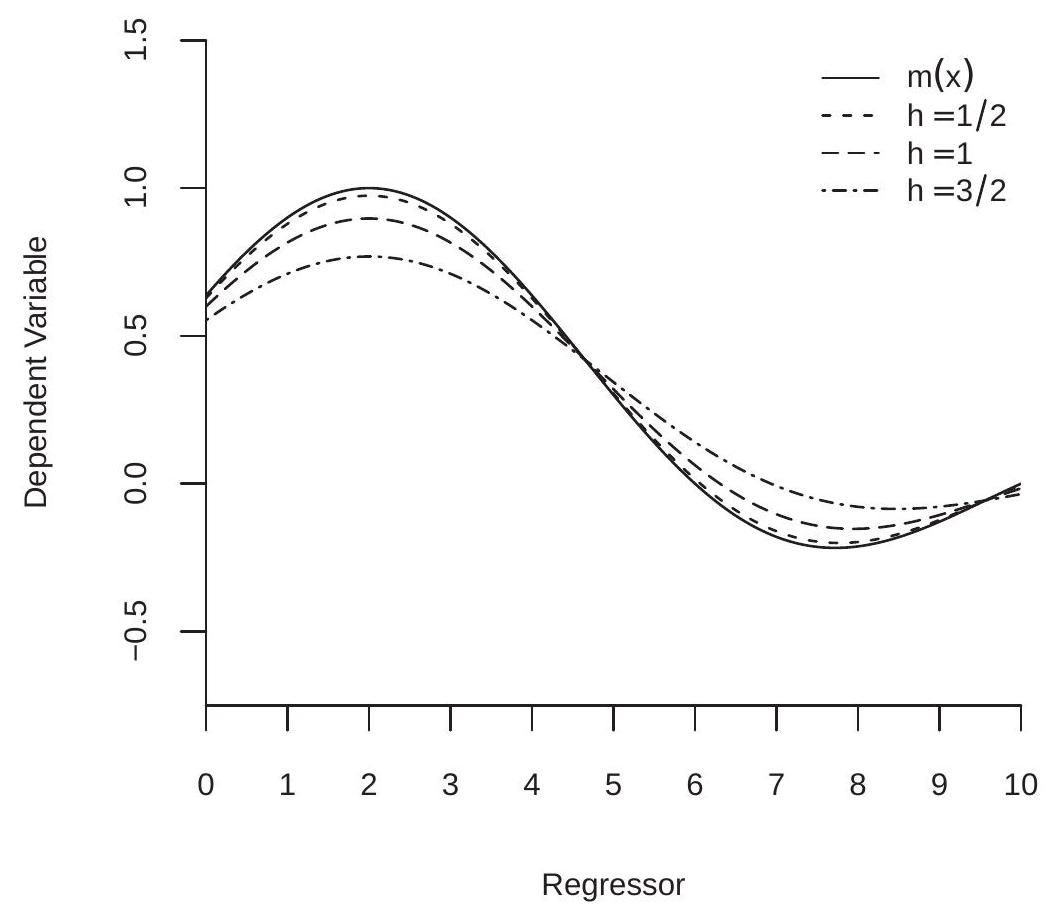
图 19.2:平滑偏差
19.7 渐近方差
从(19.3)我们推断出
\[ \widehat{m}_{\mathrm{nw}}(x)-\mathbb{E}\left[\widehat{m}_{\mathrm{nw}}(x) \mid \boldsymbol{X}\right]=\frac{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) e_{i}}{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)} . \]
由于分母仅是 \(X_{i}\) 的函数,而分子在 \(e_{i}\) 中是线性的,我们可以计算出 \(\widehat{m}_{\mathrm{nw}}(x)\) 的有限样本方差为
\[ \operatorname{var}\left[\widehat{m}_{\mathrm{nw}}(x) \mid \boldsymbol{X}\right]=\frac{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)^{2} \sigma^{2}\left(X_{i}\right)}{\left(\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)\right)^{2}} . \]
我们可以将此表达式简化为 \(n \rightarrow \infty\)。让 \(\sigma^{2}(x)=\mathbb{E}\left[e^{2} \mid X=x\right]\) 表示 \(e=Y-m(X)\) 的条件方差。
定理 19.2 在假设 19.1 下,
1.\(\operatorname{var}\left[\widehat{m}_{\mathrm{nw}}(x) \mid \boldsymbol{X}\right]=\frac{R_{K} \sigma^{2}(x)}{f(x) n h}+o_{p}\left(\frac{1}{n h}\right)\)。
2.\(\operatorname{var}\left[\hat{m}_{\mathrm{LL}}(x) \mid \boldsymbol{X}\right]=\frac{R_{K} \sigma^{2}(x)}{f(x) n h}+o_{p}\left(\frac{1}{n h}\right)\)。
在这些表达方式中
\[ R_{K}=\int_{-\infty}^{\infty} K(u)^{2} d u \]
是内核 \(K(u)\) 的粗糙度。
Nadaraya-Watson 估计器的证明在第 19.26 节中给出。对于局部线性估计,请参见 Fan 和 Gijbels (1996)。
我们将定理 \(19.2\) 中的主要项称为估计量的渐近方差。定理 \(19.2\) 表明两个估计量的渐近方差是相同的。渐近方差与核 \(K(u)\) 的粗糙度 \(R_{K}\) 以及回归误差的条件方差 \(\sigma^{2}(x)\) 成正比。它与有效观测数 \(n h\) 和边际密度 \(f(x)\) 成反比。该表达式反映了估计量是局部估计量的事实。对于 \(e\) 条件方差较大和/或 \(19.2\) 密度较低(观测值相对较少)的区域,\(\widehat{m}(x)\) 的精度较低。
19.8 目的
我们将估计器 \(\widehat{m}(x)\) 的渐近 MSE (AMSE) 定义为其渐近偏差平方和渐近方差之和。对 Nadaraya-Watson 和局部线性估计器使用定理 \(19.1\) 和 \(19.2\),我们得到
\[ \operatorname{AMSE}(x) \stackrel{\text { def }}{=} h^{4} B(x)^{2}+\frac{R_{K} \sigma^{2}(x)}{n h f(x)} \]
其中 \(B(x)=B_{\mathrm{nw}}(x)\) 表示 Nadaraya-Watson 估计器,\(B(x)=B_{\mathrm{LL}}(x)\) 表示局部线性估计器。这是单点 \(x\) 估计器 \(\widehat{m}(x)\) 的渐近 MSE。
通过整合 AMSE \((x)\) 可以获得全局拟合度。对于某些可积权重函数 \(w(x)\),标准做法是通过 \(f(x) w(x)\) 对 AMSE 进行加权。这称为渐近积分 MSE (AIMSE)。令 \(S\) 为 \(X\) 的支持度(\(f(x)>0\) 所在的区域)。
\[ \operatorname{AIMSE} \stackrel{\text { def }}{=} \int_{S} \operatorname{AMSE}(x) f(x) w(x) d x=\int_{S}\left(h^{4} B(x)^{2}+\frac{R_{K} \sigma^{2}(x)}{n h f(x)}\right) f(x) w(x) d x=h^{4} \bar{B}+\frac{R_{K}}{n h} \bar{\sigma}^{2} \]
在哪里
\[ \begin{aligned} \bar{B} &=\int_{S} B(x)^{2} f(x) w(x) d x \\ \bar{\sigma}^{2} &=\int_{S} \sigma^{2}(x) w(x) d x . \end{aligned} \]
如果 \(S\) 有界,则权重函数 \(w(x)\) 可以省略。否则,常见的选择是 \(w(x)=\) \(\mathbb{1}\left\{\xi_{1} \leq x \leq \xi_{2}\right\}\)。当 \(X\) 具有无界支持时,需要可积权重函数以确保 \(\bar{\sigma}^{2}<\infty\)
AIMSE 的形式类似于核密度估计(经济学家概率与统计定理 \(17.3\))。它有两项(偏差平方和方差)。第一个是 \(h\) 带宽增加,第二个是 \(h\) 带宽减少。因此,\(h\) 的选择会影响 AIMSE,并在这两个组件之间进行权衡。与密度估计类似,我们可以计算最小化 AIMSE 的带宽。 (参见练习 19.2。)下面的定理给出了解。
定理 19.3 最小化 AIMSE (19.5) 的带宽为
\[ h_{0}=\left(\frac{R_{K} \bar{\sigma}^{2}}{4 \bar{B}}\right)^{1 / 5} n^{-1 / 5} . \]
使用 \(h \sim n^{-1 / 5}\),然后使用 AIMSE \([\widehat{m}(x)]=O\left(n^{-4 / 5}\right)\)。
该结果表征了 AIMSE 最佳带宽。该带宽满足速率 \(h=\mathrm{cn}^{-1 / 5}\),该速率与核密度估计的速率相同。最优常数 \(c\) 取决于核 \(K(x)\)、加权平均平方偏差 \(\bar{B}\) 和加权平均方差 \(\bar{\sigma}^{2}\)。然而,常数 \(c\) 与密度估计的常数不同。
将(19.6)代入(19.5)加上一些代数,我们发现使用最佳带宽的AIMSE是
\[ \operatorname{AIMSE}_{0} \simeq 1.65\left(R_{K}^{4} \bar{B} \bar{\sigma}^{8}\right)^{1 / 5} n^{-4 / 5} . \]
这仅通过常量 \(R_{K}\) 取决于内核 \(K(u)\)。由于 Epanechnikov 内核具有 \({ }^{1}\) 和 \(R_{K}\) 的最小值,因此它也是产生最小 AIMSE 的内核。对于 NW 和 LL 估计器都是如此。
\({ }^{1}\) 请参阅《经济学家概率与统计》定理 \(17.4\)。定理 19.4 Nadaraya-Watson 和局部线性回归估计器的 AIMSE (19.5) 通过 Epanechnikov 核最小化。
然而,使用其他标准内核的效率损失很小。使用另一个内核进行估计的相对效率 \({ }^{2}\) 是 \(\left(R_{K} / R_{K} \text { (Epanechnikov) }\right)^{2 / 5}\)。使用表 \(19.1\) 中的 \(R_{K}\) 值,我们计算出使用三角形、高斯和矩形核的效率损失分别为 \(1 %, 2 %\) 和 \(3 %\),这是最小的。由于高斯核产生最平滑的估计,这对于边际效应的估计很重要,因此我们总体推荐是高斯核。
19.9 参考带宽
NW、LL 和 LP 估计器取决于带宽,并且如果没有选择 \(h\) 的经验规则,这些方法是不完整的。拥有一个参考带宽非常有用,它可以在简化的设置中模拟最佳带宽,并为进一步研究提供基线。
定理 \(19.3\) 和一点点重写表明最佳带宽等于
\[ h_{0}=\left(\frac{R_{K}}{4}\right)^{1 / 5}\left(\frac{\bar{\sigma}^{2}}{n \bar{B}}\right)^{1 / 5} \simeq 0.58\left(\frac{\bar{\sigma}^{2}}{n \bar{B}}\right)^{1 / 5} \]
其中,通过类似《经济学家概率与统计》部分 \(17.9\) 中的 \({ }^{3}\) 计算,近似值适用于所有单峰核。
参考方法可用于制定回归估计的经验法则。特别是,Fan 和 Gijbels(1996 年,第 4.2 节)为局部线性估计器开发了他们所谓的 ROT(经验法则)带宽。我们现在描述它们的推导。
首先,设置\(w(x)=\mathbb{1}\left\{\xi_{1} \leq x \leq \xi_{2}\right\}\)。其次,使用 \(q^{t h}\) 阶多项式回归形成回归函数 \(m(x)\) 的试点或初步估计器
\[ m(x)=\beta_{0}+\beta_{1} x+\beta_{2} x^{2}+\cdots+\beta_{q} x^{q} \]
为 \(q \geq 2\)。 (Fan 和 Gijbels (1996) 建议 \(q=4\),但这不是必需的。)通过最小二乘,我们获得系数估计值 \(\widehat{\beta}_{0}, \ldots, \widehat{\beta}_{\underline{q}}\) 和隐含的二阶导数 \(\widehat{m}^{\prime \prime}(x)=2 \widehat{\beta}_{2}+6 \widehat{\beta}_{3} x+12 \widehat{\beta}_{4} x^{2}+\cdots+q(q-\) 1) \(\widehat{\beta}_{q} x^{q-2}\)。第三,注意 \(\frac{q}{B}\) 可以写成期望
\[ \bar{B}=\mathbb{E}\left[B(X)^{2} w(X)\right]=\mathbb{E}\left[\left(\frac{1}{2} m^{\prime \prime}(X)\right)^{2} \mathbb{1}\left\{\xi_{1} \leq X \leq \xi_{2}\right\}\right] . \]
矩估计器是
\[ \widehat{B}=\frac{1}{n} \sum_{i=1}^{n}\left(\frac{1}{2} \widehat{m}^{\prime \prime}\left(X_{i}\right)\right)^{2} \mathbb{1}\left\{\xi_{1} \leq X_{i} \leq \xi_{2}\right\} . \]
第四,假设回归误差是同方差\(\mathbb{E}\left[e^{2} \mid X\right]=\sigma^{2}\),因此\(\bar{\sigma}^{2}=\sigma^{2}\left(\xi_{2}-\xi_{1}\right)\)。通过初步回归的误差方差估计 \(\widehat{\sigma}^{2}\) 来估计 \(\sigma^{2}\)。将它们代入(19.7)我们获得参考带宽
\[ h_{\mathrm{rot}}=0.58\left(\frac{\widehat{\sigma}^{2}\left(\xi_{2}-\xi_{1}\right)}{n \widehat{B}}\right)^{1 / 5} . \]
\({ }^{2}\) 通过根 AIMSE 测量。
\({ }^{3}\) 常量 \(\left(R_{K} / 4\right)^{1 / 5}\) 介于 \(0.58\) 和 \(0.59\) 之间。 Fan 和 Gijbels (1996) 将其称为经验法则 (ROT) 带宽。
Fan 和 Gijbels 为高阶奇局部多项式估计器开发了类似的规则,但没有为局部常数 (Nadaraya-Watson) 估计器开发了类似的规则。然而,我们也可以通过使用边际密度 \(f(x)\) 的参考模型来导出 NW 的 ROT。一个方便的选择是 \(f^{\prime}(x)=0\) 与 NW 和 LL 的最佳带宽一致的均匀密度。这促使使用 (19.9) 作为 LL 和 NW 估计器的 ROT 带宽。
正如我们上面提到的,Fan 和 Gijbels 建议使用 \(4^{t h}\) 阶多项式作为导频估计器,但这种特定选择并不是必需的。在应用中,谨慎的做法可能是评估 ROT 带宽对 \(q\) 选择的敏感性,并检查估计的导频回归以确定估计的高阶多项式项的精度。
我们现在评论权重区域 \(\left[\xi_{1}, \xi_{2}\right]\) 的选择。当 \(X\) 具有有界支持时,则可以将 \(\left[\xi_{1}, \xi_{2}\right]\) 设置为等于该支持。否则, \(\left[\xi_{1}, \xi_{2}\right]\) 可以设置为等于 \(\widehat{m}(x)\) 的感兴趣区域,或者端点可以设置为等于 \(X\) 分布的固定分位数(例如 \(0.05\) 和 \(0.95\) )。
为了说明这一点,请采用图 19.1 中所示的数据。如果我们拟合 \(4^{\text {th }}\) 阶多项式,我们会发现 \(\widehat{m}(x)=\) \(.49+.70 x-.28 x^{2}-.033 x^{3}-.0012 x^{4}\) 意味着 \(\widehat{m}^{\prime \prime}(x)=-.56-.20 x-.014 x^{2}\)。根据 \(X\) 的支持设置 \(\left[\xi_{1}, \xi_{2}\right]=[0,10]\),我们找到 \(\widehat{B}=0.00889\)。多项式回归的残差具有方差 \(\widehat{\sigma}^{2}=0.0687\)。将它们代入 (19.9),我们发现 \(h_{\mathrm{rot}}=0.551\) 与图 19.1 中使用的类似。
19.10 边界处的估计
与 Nadaraya-Watson 估计器相比,局部线性估计器的优点之一是 LL 在 \(X\) 支持的边界上具有更好的性能。 NW 估计器在边界附近有过多的平滑偏差。在计量经济学的许多背景下,边界非常令人感兴趣。在这种情况下,强烈建议使用局部线性估计器(或带有 \(p \geq 1\) 的局部多项式估计器)。
为了理解这个问题,查看图 19.3 可能会有所帮助。这显示了生成为 \(X \sim U[0,10]\) 和 \(Y \sim \mathrm{N}(X, 1)\) 的 100 个观测值的散点图,以便 \(m(x)=x\)。假设我们对下边界 \(x=0\) 处的 CEF \(m(0)\) 感兴趣。 Nadaraya-Watson 估计量等于 \(|X|\) 小值的 \(Y\) 观测值的加权平均值。从 \(X \geq 0\) 开始,这些都是 \(m(X) \geq m(0)\) 的观测值,因此 \(X \sim U[0,10]\) 向上偏差。对称地,上边界 \(X \sim U[0,10]\) 处的 Nadaraya-Watson 估计量是 \(X \sim U[0,10]\) 和 \(X \sim U[0,10]\) 向下偏置的观测值的加权平均值。
相反,局部线性估计器 \(\widehat{m}_{\mathrm{LL}}(0)\) 和 \(\widehat{m}_{\mathrm{LL}}(10)\) 在此示例中是无偏的,因为 \(m(x)\) 在 \(x\) 中是线性的。局部线性估计器拟合线性回归线。由于期望被正确指定,因此不存在估计偏差。
NW 估计器的精确偏差 \({ }^{4}\) 如图 \(19.3\) 中的虚线所示。长破折号是 \(h=1\) 的期望 \(\mathbb{E}\left[\widehat{m}_{\mathrm{nw}}(x)\right]\),短破折号是 \(h=2\) 的期望 \(\mathbb{E}\left[\widehat{m}_{\mathrm{nw}}(x)\right]\)。我们可以看到,偏差是很大的。对于 \(h=2\),\(x\) 的所有值的偏差都是可见的。对于较小的带宽 \(h=1\),在支撑位的中心范围内 \({ }^{4}\) 的偏差最小,但在边界附近的 \({ }^{4}\) 的偏差仍然相当大。
为了计算渐近平滑偏差,我们可以重新审视定理 19.1.1 的证明,该定理计算了内点处的渐近偏差。方程(19.29)计算估计量的分子偏差,表示为边际密度的积分。在下边界处计算,密度仅对于 \(u \geq 0\) 为正,因此积分位于正区域 \([0, \infty)\) 上。这也适用于方程(19.31)和后面的方程。在这种情况下,该展开式的主导项是第一项 (19.32),它与 \(h\) 成比例,而不是与 \(h^{2}\) 成比例。完成计算后,我们发现以下结果。定义 \(m(x+)=\lim _{z \downarrow x} m(z)\) 和 \(m(x-)=\lim _{z \uparrow x} m(z)\)。
\({ }^{4}\) 通过 10,000 次模拟重复的模拟计算得出。
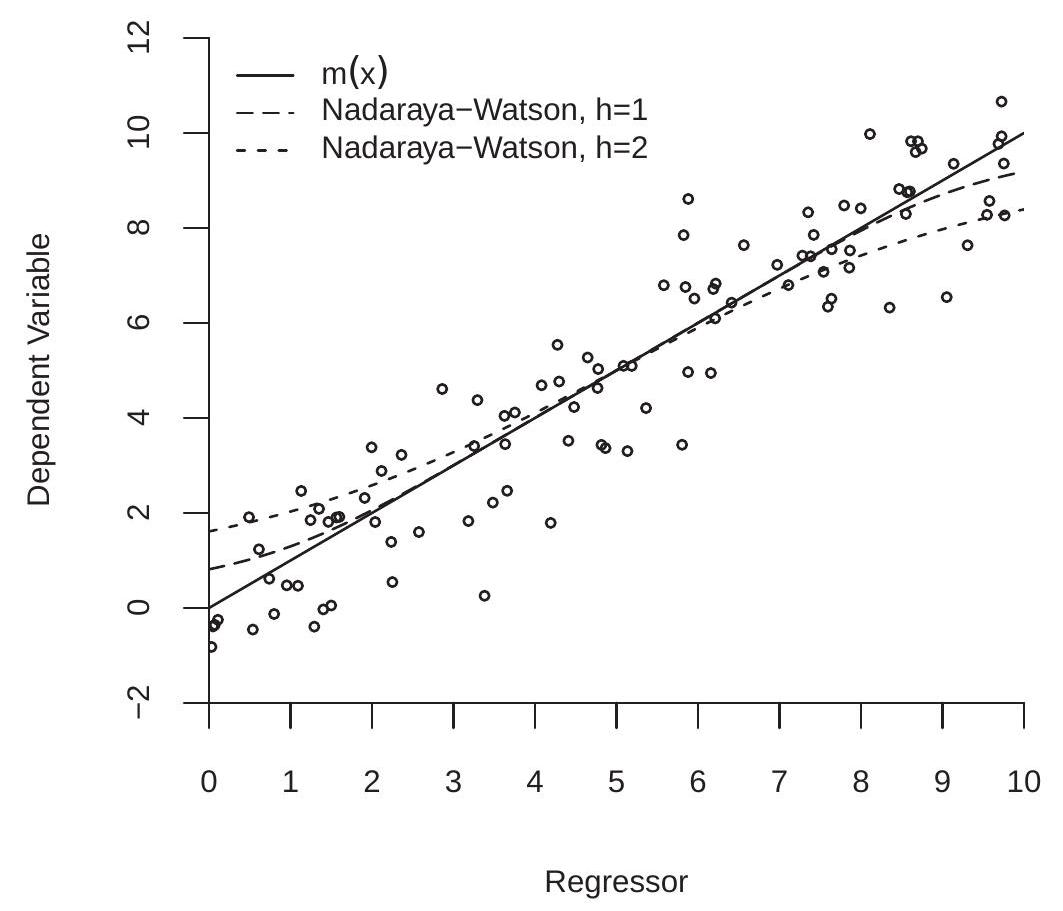
图 19.3:边界偏差
定理 19.5 假设假设 \(19.1\) 成立。设置 \(\mu_{K}=2 \int_{0}^{\infty} K(u) d u\)。令\(X\) 的支持度为\(S=[\underline{x}, \bar{x}]\)。
如果 \(m^{\prime \prime}(\underline{x}+), \sigma^{2}(\underline{x}+)\) 和 \(f^{\prime}(\underline{x}+)\) 存在,并且 \(f(\underline{x}+)>0\) 存在,则
\[ \mathbb{E}\left[\hat{m}_{\mathrm{nw}}(\underline{x}) \mid \boldsymbol{X}\right]=m(\underline{x})+h m^{\prime}(\underline{x}) \mu_{K}+o_{p}(h)+O_{p}\left(\sqrt{\frac{h}{n}}\right) . \]
如果 \(m^{\prime \prime}(\bar{x}-), \sigma^{2}(\bar{x}-)\) 和 \(f^{\prime}(\bar{x}-)\) 存在,并且 \(f(\bar{x}-)>0\) 存在,则
\[ \mathbb{E}\left[\widehat{m}_{\mathrm{nw}}(\bar{x}) \mid \boldsymbol{X}\right]=m(\bar{x})-h m^{\prime}(\bar{x}) \mu_{K}+o_{p}(h)+O_{p}\left(\sqrt{\frac{h}{n}}\right) . \]
定理 \(19.5\) 显示边界处 NW 估计量的渐近偏差为 \(O(h)\),并且取决于边界处 \(m(x)\) 的斜率。当斜率为正时,NW 估计器在下边界处向上偏置,在上边界处向下偏置。定理 \(19.5\) 的标准解释是 NW 估计器在边界点附近具有高偏差。
类似地,我们可以评估 LL 估计器的性能。我们总结了结果,但没有推导(因为它们在技术上更具挑战性),而是建议感兴趣的读者参考 Cheng、Fan 和 Marron (1997) 以及 Imbens 和 Kalyahnaraman (2012)。
定义核矩 \(v_{j}=\int_{0}^{\infty} u^{j} K(u) d u, \pi_{j}=\int_{0}^{\infty} u^{j} K(u)^{2} d u\) 和投影核
\[ K^{*}(u)=\left[\begin{array}{ll} 1 & 0 \end{array}\right]\left[\begin{array}{ll} v_{0} & v_{1} \\ v_{1} & v_{2} \end{array}\right]^{-1}\left[\begin{array}{c} 1 \\ u \end{array}\right] K(u)=\frac{v_{2}-v_{1} u}{v_{0} v_{2}-v_{1}^{2}} K(u) . \]
定义其二阶矩
\[ \sigma_{K^{*}}^{2}=\int_{0}^{\infty} u^{2} K^{*}(u) d u=\frac{v_{2}^{2}-v_{1} v_{3}}{v_{0} v_{2}-v_{1}^{2}} \]
和粗糙度
\[ R_{K}^{*}=\int_{0}^{\infty} K^{*}(u)^{2} d u=\frac{v_{2}^{2} \pi_{0}-2 v_{1} v_{2} \pi_{1}+v_{1}^{2} \pi_{2}}{\left(v_{0} v_{2}-v_{1}^{2}\right)^{2}} \]
定理19.6 在定理19.5的假设下,在边界点\(\underline{x}\)
1.\(\mathbb{E}\left[\hat{m}_{\mathrm{LL}}(\underline{x}) \mid \boldsymbol{X}\right]=m(\underline{x})+\frac{h^{2} m^{\prime \prime}(\underline{x}) \sigma_{K^{*}}^{2}}{2}+o_{p}\left(h^{2}\right)+O_{p}\left(\sqrt{\frac{h}{n}}\right)\)
2.\(\operatorname{var}\left[\widehat{m}_{\mathrm{LL}}(\underline{x}) \mid \boldsymbol{X}\right]=\frac{R_{K}^{*} \sigma^{2}(\underline{x})}{f(\underline{x}) n h}+o_{p}\left(\frac{1}{n h}\right)\)
定理 19.6 表明 LL 估计器在边界处的渐近偏差为 \(O\left(h^{2}\right.\) ),与内部点处的渐近偏差相同,并且对于 \(m(x)\) 的斜率不变。该定理还表明,渐进方差与内点处的渐近方差具有相同的比率。
将定理 19.1、19.2、19.5 和 \(19.6\) 结合起来,我们得出结论:局部线性估计器相对于 NW 估计器具有优越的渐近特性。在内点处,两个估计量具有相同的渐近方差。 LL 估计器的偏差对于 \(m(x)\) 的斜率是不变的,其渐近偏差仅取决于二阶导数,而 NW 估计器的偏差取决于一阶和二阶导数。在边界点,NW 估计器的渐近偏差为 \(O(h)\),其阶数高于 LL 估计器的 \(O\left(h^{2}\right)\) 偏差。由于这些原因,我们建议使用局部线性估计器而不是 Nadaraya-Watson 估计器。可以提出类似的论点来推荐局部三次估计器,但这并没有被广泛使用。
边界处 LL 估计器的渐近偏差和方差与内部略有不同。不同之处在于,偏差和方差取决于类核函数 \(K^{*}(u)\) 的矩,而不是原始核 \(K(u)\) 的矩。
一个有趣的问题是找到边界估计的最佳核函数。通过与定理 \(19.4\) 相同的计算,我们发现最优内核 \(K^{*}(u)\) 最小化了给定二阶矩 \(\sigma_{K^{*}}^{2}\) 的粗糙度 \(R_{K}^{*}\),并且正如定理 \(19.4\) 所论证的那样,当 \(K^{*}(u)\) 等于二次方时,可以实现这一点\(u\) 中的函数。由于 \(K^{*}(u)\) 是 \(K(u)\) 和线性函数的乘积,这意味着 \(19.4\) 在 \(19.4\) 中必须是线性的,这意味着最佳内核 \(19.4\) 是三角内核。参见 Cheng、Fan 和 Marron (1997)。与定理 \(19.4\) 类似的计算表明,使用 Epanechnikov、高斯和矩形核进行估计的效率损失 \(19.4\) 分别为 1%、1% 和 3%。
\({ }^{5}\) 通过根 AIMSE 测量。
19.11 非参数残差和预测误差
给定任何非参数回归估计器 \(\widehat{m}(x)\),\(x=X_{i}\) 处的拟合回归为 \(\widehat{m}\left(X_{i}\right)\),拟合残差为 \(\widehat{e}_{i}=Y_{i}-\widehat{m}\left(X_{i}\right)\)。作为一般规则,尤其是当带宽 \(h\) 很小时,很难将 \(\widehat{e}_{i}\) 视为回归拟合的良好度量。对于 NW 和 LL 估计器,分别为 \(h \rightarrow 0\)、\(\widehat{m}\left(X_{i}\right) \rightarrow Y_{i}\) 和 \(\widehat{e}_{i} \rightarrow 0\)。这显然是过度拟合,因为真实误差 \(\widehat{m}(x)\) 不为零。一般来说,由于 \(\widehat{m}(x)\) 是包含 \(\widehat{m}(x)\) 在内的局部平均值,因此拟合值必然会接近 \(\widehat{m}(x)\),而残差 \(\widehat{m}(x)\) 较小,并且这种过度拟合的程度随着 \(\widehat{m}(x)\) 的减小而增大。
标准解决方案是通过重新估计模型(排除 \(i^{t h}\) 观测值)来测量 \(x=X_{i}\) 处回归的拟合度。令 \(\widetilde{m}_{-i}(x)\) 为在没有观察 \(i\) 的情况下计算的留一非参数估计量。例如,对于 Nadaraya-Watson 回归,这是
\[ \widetilde{Y}_{i}=\widetilde{m}_{-i}(x)=\frac{\sum_{j \neq i} K\left(\frac{X_{j}-x}{h}\right) Y_{j}}{\sum_{j \neq i} K\left(\frac{X_{j}-x}{h}\right)} . \]
从符号上讲,“-i”下标用于指示省略 \(i^{t h}\) 观测值。
\(Y_{i}\) 在 \(x=X_{i}\) 处的留一预测值为 \(\widetilde{Y}_{i}=\widetilde{m}_{-i}\left(X_{i}\right)\),留一预测误差为
\[ \widetilde{e}_{i}=Y_{i}-\widetilde{Y}_{i} . \]
由于 \(\widetilde{Y}_{i}\) 不是 \(Y_{i}\) 的函数,因此 \(\widetilde{Y}_{i}\) 不会过度拟合较小的 \(h\)。因此,\(\widetilde{e}_{i}\) 可以很好地衡量估计的非参数回归的拟合度。
如果可能,应使用留一预测误差而不是残差 \(\widehat{e}_{i}\)。
19.12 交叉验证带宽选择
应用统计学中选择带宽最流行的方法是交叉验证。总体思路是基于留一估计来估计模型拟合度。在这里,我们描述了通常应用于回归估计的方法。该方法适用于 NW、LL 和 LP 估计以及其他非参数估计。
为了明确估计器对带宽的依赖性,让我们将给定带宽 \(h\) 的 \(m(x)\) 的估计器编写为 \(\widehat{m}(x, h)\)。
理想情况下,我们希望选择 \(h\) 来最小化 \(\widehat{m}(x, h)\) 的积分均方误差 (IMSE) 作为 \(m(x)\) 的估计量:
\[ \operatorname{IMSE}_{n}(h)=\int_{S} \mathbb{E}\left[(\widehat{m}(x, h)-m(x))^{2}\right] f(x) w(x) d x \]
其中 \(f(x)\) 是 \(X\) 的边际密度,\(w(x)\) 是可积权重函数。权重 \(w(x)\) 与 (19.5) 中使用的相同,并且当 \(X\) 具有有界支持时可以省略。
\(x=X_{i}\) 处的 \(\widehat{m}(x, h)-m(x)\) 差异可以通过留一预测误差 \((19.10)\) 来估计
\[ \widetilde{e}_{i}(h)=Y_{i}-\widetilde{m}_{-i}\left(X_{i}, h\right) \]
我们明确了对带宽 \(h\) 的依赖。 IMSE \({ }_{n}(h)\) 的合理估计量是加权平均均方预测误差
\[ \mathrm{CV}(h)=\frac{1}{n} \sum_{i=1}^{n} \widetilde{e}_{i}(h)^{2} w\left(X_{i}\right) . \]
\(h\) 的这个函数称为交叉验证标准。再次强调,如果 \(X\) 具有有限支持,则可以省略权重 \(w\left(X_{i}\right)\),这在实践中通常是这样做的。
事实证明,交叉验证标准是 IMSE 的无偏估计量加上具有 \(n-1\) 观测值的样本的常数。
定理$19.7
\[ \mathbb{E}[\mathrm{CV}(h)]=\bar{\sigma}^{2}+\operatorname{IMSE}_{n-1}(h) \]
其中 \(\bar{\sigma}^{2}=\mathbb{E}\left[e^{2} w(X)\right]\)
定理 \(19.7\) 的证明在第 19.26 节中给出。
由于 \(\bar{\sigma}^{2}\) 是一个与带宽无关的常数,\(h, \mathbb{E}[\mathrm{CV}(h)]\) 是 \(\operatorname{IMSE}_{n-1}(h)\) 的移位版本。特别是,最小化 \(\mathbb{E}[\mathrm{CV}(h)]\) 的 \(h\) 和 \(\operatorname{IMSE}_{n-1}(h)\) 是相同的。当 \(n\) 很大时,最小化 \(\operatorname{IMSE}_{n-1}(h)\) 和 \(\operatorname{IMSE}_{n}(h)\) 的带宽几乎相同,因此 \(\bar{\sigma}^{2}\) 作为 \(\bar{\sigma}^{2}\) 的估计器本质上是无偏的。鉴于此,建议选择 \(\bar{\sigma}^{2}\) 作为最小化 \(\bar{\sigma}^{2}\) 的值。
交叉验证带宽 \(h_{\mathrm{cv}}\) 是最小化 \(\mathrm{CV}(h)\) 的值
\[ h_{\mathrm{cv}}=\underset{h \geq h_{\ell}}{\operatorname{argmin}} \mathrm{CV}(h) \]
对于一些 \(h_{\ell}>0\)。可以施加限制 \(h \geq h_{\ell}\) ,以便 \(\mathrm{CV}(h)\) 不会在不合理的小带宽上进行评估。
最小化问题(19.13)没有明确的解,因此必须通过数值求解。一种方法是网格搜索。为 \(h\) 创建值网格,例如[ \(\left.h_{1}, h_{2}, \ldots, h_{J}\right]\),评估 \(C V\left(h_{j}\right)\) 的 \(j=1, \ldots, J\),并设置
\[ h_{\mathrm{cv}}=\underset{h \in\left[h_{1}, h_{2}, \ldots, h_{J}\right]}{\operatorname{argmin}} \mathrm{CV}(h) . \]
使用粗网格进行评估通常足以满足实际应用的需要。 CV( \(h)\) 与 \(h\) 的关系图是一个有用的诊断工具,可验证是否已获得 \(\mathrm{CV}(h)\) 的最小值。获得解 (19.13) 的计算效率更高的方法是黄金分割搜索。请参阅 $ 节matheq4$ 经济学家的概率与统计。
解 (19.13) 可能是无界的,也就是说,\(\mathrm{CV}(h)\) 对于较大的 \(h\) 来说是递减的,因此 \(h_{\mathrm{cv}}=\infty\) 也是如此。这没关系。它只是意味着回归估计器简化为其完整样本版本。对于 Nadaraya-Watson 估计器,这是 \(\hat{m}_{\mathrm{nw}}(x)=\bar{Y}\)。对于局部线性估计器,这是 \(\hat{m}_{\mathrm{LL}}(x)=\widehat{\alpha}+\widehat{\beta} x\)。
对于 NW 和 LL 估计,标准 (19.11) 要求对每个观测值 \(X_{i}\) 的条件均值进行留一估计。这与估计器 \(\widehat{m}(x)\) 的计算不同,因为后者通常是在 \(x\) 的一组固定值上完成的,以用于显示目的。
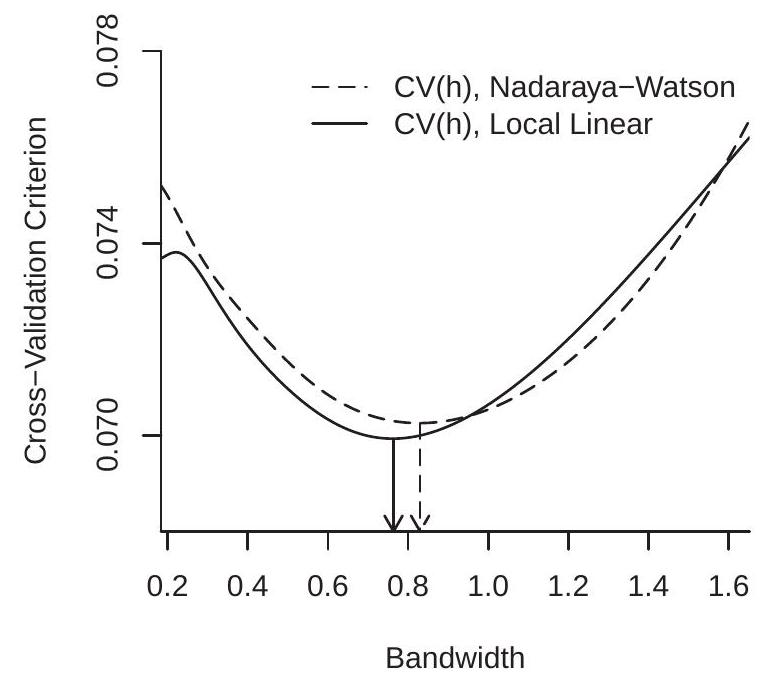
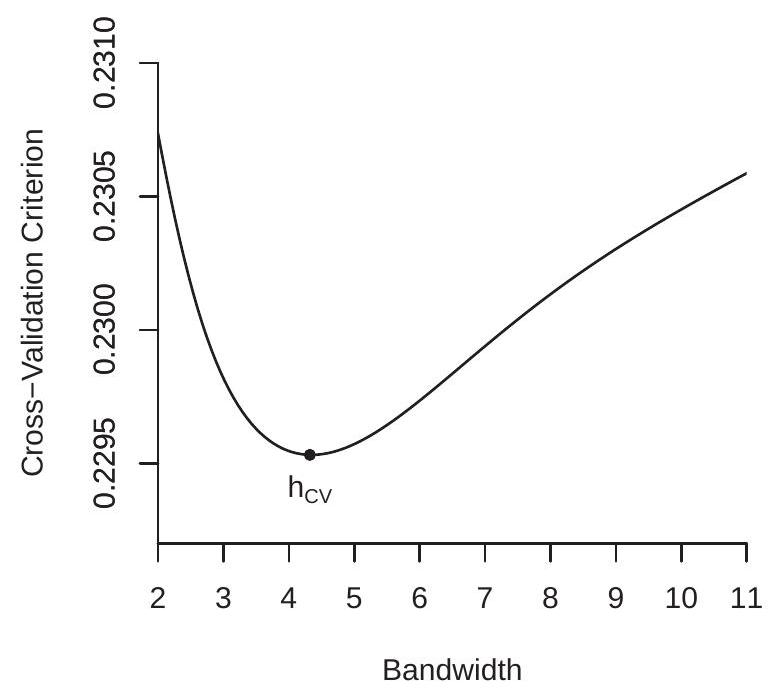
为了说明这一点,图 19.4(a) 使用图 19.1 中的数据显示了 Nadaraya-Watson 和局部线性估计器的交叉验证标准 \(\mathrm{CV}(h)\),两者都使用高斯核。 CV 函数在 \(\left[h_{\mathrm{rot}} / 3,3 h_{\mathrm{rot}}\right]\) 上具有 200 个网格点的网格上计算。 Nadaraya-Watson 估计器的 CV 最小化带宽为 \(h_{\mathrm{nw}}=0.830\),局部线性估计器的 CV 最小化带宽为 \(h_{\mathrm{LL}}=0.764\)。这些值略高于之前计算的经验法则 \(h_{\mathrm{rot}}=0.551\) 值。图 19.4(a) 通过箭头显示了最小化带宽。
CV 准则还可用于在不同的非参数估计量之间进行选择。 CVselected 估计器是具有最低最小化 CV 标准的估计器。例如,在图 19.4(a) 中,您可以看到 LL 估计器具有最小化 CV 准则 \(0.0699\),该准则低于最小值
- 交叉验证标准
.jpg)
- 非参数估计
图 19.4:带宽选择
\(0.0703\) 由 NW 估计器获得。由于 LL 估计器实现了 CV 标准的较低值,因此 LL 是 CV 选择的估计器。然而,差异很小,表明两个估计器实现了相似的 IMSE。
图 19.4(b) 显示使用 ROT 和 CV 带宽以及真实条件平均值 \(m(x)\) 的局部线性估计 \(\widehat{m}(x)\)。估计器很好地跟踪了真实函数,并且在此应用中带宽之间的差异相对较小。
19.13 渐近分布
我们首先提供一致性结果。
定理 19.8 在假设 19.1 下,\(\hat{m}_{\mathrm{nw}}(x) \underset{p}{\rightarrow} m(x)\) 和 \(\hat{m}_{\mathrm{LL}}(x) \underset{p}{\longrightarrow}\) \(m(x)\)
Nadaraya-Watson 估计器的证明在第 19.26 节中给出。对于局部线性估计,请参见 Fan 和 Gijbels (1996)。
定理 \(19.8\) 表明,在温和连续性假设下,\(m(x)\) 的估计量是一致的。特别是,除了连续性之外,\(m(x)\) 上不需要任何平滑条件。
接下来我们给出一个渐近分布结果。下图表明,核回归估计量是渐近正态的,具有非参数收敛率、非平凡渐近偏差和非简并渐近方差。定理 19.9 假设假设 \(19.1\) 成立。另外假设 \(m^{\prime \prime}(x)\) 和 \(f^{\prime}(x)\) 在 \(\mathscr{N}\) 中是连续的,对于某些 \(r>2\) 和 \(x \in \mathscr{N}\),
\[ \mathbb{E}\left[|e|^{r} \mid X=x\right] \leq \bar{\sigma}<\infty, \]
和
\[ n h^{5}=O(1) . \]
然后
\[ \sqrt{n h}\left(\widehat{m}_{\mathrm{nw}}(x)-m(x)-h^{2} B_{\mathrm{nw}}(x)\right) \underset{d}{\longrightarrow} \mathrm{N}\left(0, \frac{R_{K} \sigma^{2}(x)}{f(x)}\right) . \]
相似地,
\[ \sqrt{n h}\left(\widehat{m}_{\mathrm{LL}}(x)-m(x)-h^{2} B_{\mathrm{LL}}(x)\right) \underset{d}{\longrightarrow} \mathrm{N}\left(0, \frac{R_{K} \sigma^{2}(x)}{f(x)}\right) . \]
Nadaraya-Watson 估计器的证明出现在第 19.26 节中。对于局部线性估计,请参见 Fan 和 Gijbels (1996)。
相对于定理 19.8,定理 \(19.9\) 要求条件均值和边际密度具有更强的平滑条件。还有两个技术规律性条件。第一个是条件矩界限 (19.14)(用于验证 CLT 的 Lindeberg 条件),第二个是带宽界限 \(n h^{5}=O(1)\)。后者意味着带宽必须至少以 \(n^{-1 / 5}\) 的速率下降到零,并使用 \({ }^{6}\) 来确保高阶偏差项不会进入渐近分布(19.16)。
渐近分布有几个有趣的特征,它们与参数估计量明显不同。首先,估计器以 \(\sqrt{n h}\) 而非 \(\sqrt{n}\) 的速率收敛。由于 \(h \rightarrow 0\)、\(\sqrt{n h}\) 的发散速度比 \(\sqrt{n}\) 慢,因此非参数估计器比参数估计器收敛得更慢。其次,渐近分布包含不可忽略的偏差项 \(h^{2} B(x)\)。第三,分布(19.16)在形式上与核密度估计量相同(经济学家概率与统计定理 \(17.7\))。
估计量以 \(\sqrt{n h}\) 的速率收敛这一事实导致将 \(n h\) 解释为“有效样本量”。这是因为用于构造 \(\widehat{m}(x)\) 的观测值数量与 \(n h\) 成正比,而不是与参数估计器的 \(n\) 成正比。
理解非参数估计器相对于参数渐近理论的收敛速度较低是有帮助的,因为被估计的对象 - \(m(x)-\) 是非参数的。这比估计有限维参数更困难,因此是有代价的。
与参数估计不同,非参数估计量的渐近分布包括表示估计量偏差的项。渐近分布 (19.16) 显示了这种偏差的形式。它与带宽平方 \(h^{2}\)(平滑程度)以及函数 \(B_{\mathrm{nw}}(x)\) 或 \(B_{\mathrm{LL}}(x)\) 成正比,函数 \(B_{\mathrm{nw}}(x)\) 或 \(B_{\mathrm{LL}}(x)\) 取决于 CEF \(m(x)\) 的斜率和曲率。有趣的是,当 \(m(x)\) 恒定时,\(B_{\mathrm{nw}}(x)=B_{\mathrm{LL}}(x)=0\) 和核估计器没有渐近偏差。 CEF 函数 \(m(x)\) 的曲率偏差本质上是增加的。这是因为局部平均平滑了 \(m(x)\),而当 \(m(x)\) 弯曲时,平滑会产生更多偏差。由于偏差项乘以 \(h^{2}\)
\({ }^{6}\) 如果假设更强的平滑条件,这可能会被削弱。例如,如果 \(m^{(4)}(x)\) 和 \(f^{(3)}(x)\) 连续,则 (19.15) 可以减弱为 \(n h^{9}=O(1)\),这意味着带宽必须至少以 \(n^{-1 / 9}\) 的速率下降到零。它趋于零,可能会认为偏差项是渐近可忽略的并且可以省略,但这是错误的,因为它们位于括号内,并乘以因子 \(\sqrt{n h}\)。仅当 \(\sqrt{n h} h^{2} \rightarrow 0\) 时才可以省略偏差项,这称为欠平滑条件,将在下一节中讨论。
\(\widehat{m}(x)\) 的渐近方差与边际密度 \(f(x)\) 成反比。这意味着 \(\widehat{m}(x)\) 对于 \(X\) 密度较低的区域具有相对较低的精度。这是有道理的,因为这些区域的观察相对较少。这意味着非参数估计器 \(\widehat{m}(x)\) 在 \(X\) 分布的尾部相对不准确。
19.14 欠平滑
如果选择带宽比最优速率 \(n^{-1 / 5}\) 更快地收敛到零,则可以在技术上消除核密度估计器渐近分布中的偏差项,从而 \(h=\) \(o\left(n^{-1 / 5}\right)\)。这称为欠平滑带宽。通过使用小带宽,可以减少偏差并增加方差。因此,随机成分支配着偏差成分(渐近地)。以下是技术声明。
定理 19.10 在定理 19.9 和 \(n h^{5}=o(1)\) 的条件下,
\[ \begin{aligned} &\sqrt{n h}\left(\widehat{m}_{\mathrm{nw}}(x)-m(x)\right) \underset{d}{\longrightarrow} \mathrm{N}\left(0, \frac{R_{K} \sigma^{2}(x)}{f(x)}\right) \\ &\sqrt{n h}\left(\widehat{m}_{\mathrm{LL}}(x)-m(x)\right) \underset{d}{\longrightarrow} \mathrm{N}\left(0, \frac{R_{K} \sigma^{2}(x)}{f(x)}\right) . \end{aligned} \]
定理 \(19.10\) 的优点是没有偏差项。因此,该定理受到一些作者的欢迎。也有几个缺点。首先,欠平滑带宽的假设并不能真正消除偏差,它只是假设它消失了。因此,在任何有限样本中总是存在偏差。其次,尚不清楚如何设置带宽以使其不平滑。第三,欠平滑的带宽意味着估计器的方差增加并且效率低下。最后,该理论作为估计量分布的表征完全具有误导性。
19.15 条件方差估计
条件方差是
\[ \sigma^{2}(x)=\operatorname{var}[Y \mid X=x]=\mathbb{E}\left[e^{2} \mid X=x\right] . \]
在许多情况下需要估计 \(\sigma^{2}(x)\),包括估计 CEF 的预测区间和置信区间。一般来说,条件方差函数是非参数的,因为经济模型很少指定 \(\sigma^{2}(x)\) 的形式。因此,\(\sigma^{2}(x)\) 的估计通常是非参数完成的。由于 \(\sigma^{2}(x)\) 是给定 \(X\) 的 \(e^{2}\) 的 CEF,因此可以通过非参数回归进行估计。例如,理想的 NW 估计量(如果观察到 \(e\))是
\[ \bar{\sigma}^{2}(x)=\frac{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) e_{i}^{2}}{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)} . \]
由于错误 \(e\) 没有被观察到,我们需要用估计器替换它们。一个简单的选择是残差 \(\widehat{e}_{i}=Y_{i}-\widehat{m}\left(X_{i}\right)\)。更好的选择是留一法预测误差 \(\widetilde{e}_{i}=Y_{i}-\widehat{m}_{-i}\left(X_{i}\right)\)。建议使用后者进行方差估计,因为它们不会过度拟合。通过这种替换,条件方差的 NW 估计量为
\[ \widehat{\sigma}^{2}(x)=\frac{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) \widetilde{e}_{i}^{2}}{\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)} . \]
该估计器取决于带宽 \(h\),但该带宽没有理由与用于估计 CEF 的带宽相同。使用 \(\widetilde{e}_{i}^{2}\) 作为因变量的 ROT 或交叉验证可用于选择用于估计 \(\widehat{\sigma}^{2}(x)\) 的带宽,与用于估计 \(\widehat{m}(x)\) 的选择分开。
CEF 和条件方差估计之间存在细微差别。条件方差本质上是非负的 \(\sigma^{2}(x) \geq 0\),并且估计器需要满足此属性。 NW 估计量 (19.17) 必然是非负的,因为它是非负残差平方的平滑平均值。然而,不能保证 LL 估计器对于所有 \(x\) 都是非负的。此外,NW 估计器具有作为特殊情况的同方差估计器 \(\widehat{\sigma}^{2}(x)=\widehat{\sigma}^{2}\) (全样本方差),这可能是相关的选择。由于这些原因,NW 估计器可能更适合条件方差估计。
Fan 和 Yao (1998) 推导了估计量 (19.17) 的渐近分布。他们得到了令人惊讶的结果,即两步估计器 \(\widehat{\sigma}^{2}(x)\) 的渐近分布与一步理想化估计器 \(\bar{\sigma}^{2}(x)\) 的渐近分布相同。
19.16 方差估计和标准误差
计算 Nadaraya-Watson、局部线性或局部多项式估计量的精确条件方差相对简单。估计量可以写成
\[ \widehat{\beta}(x)=\left(Z^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1}\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Y}\right)=\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1}\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{m}\right)+\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1}\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{e}\right) \]
其中 \(m\) 是均值 \(m\left(X_{i}\right)\) 的 \(n \times 1\) 向量。第一个分量仅是回归量的函数,第二个分量与误差 \(\boldsymbol{e}\) 呈线性关系。因此,在回归量 \(\boldsymbol{X}\) 上有条件,
\[ \boldsymbol{V}_{\widehat{\beta}}(x)=\operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]=\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1}\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{D} \boldsymbol{K} \boldsymbol{Z}\right)\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1} \]
其中 \(\boldsymbol{D}=\operatorname{diag}\left(\sigma^{2}\left(X_{1}\right), \ldots \sigma^{2}\left(X_{n}\right)\right)\)
White 型估计量可以通过用残差平方 \(\widehat{e}_{i}^{2}\) 或预测误差 \(\widetilde{e}_{i}^{2}\) 替换 \(\sigma^{2}\left(X_{i}\right)\) 来形成
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}(x)=\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1}\left(\sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)^{2} Z_{i}(x) Z_{i}(x)^{\prime} \widetilde{e}_{i}^{2}\right)\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1} . \]
或者,\(\sigma^{2}\left(X_{i}\right)\) 可以替换为估计器,例如在 \(\widehat{\sigma}^{2}\left(X_{i}\right)\) 或 \(\widehat{\sigma}^{2}(x)\) 处评估的 (19.17)。
一个简单的选择是渐近公式
\[ \widehat{V}_{\widehat{m}(x)}=\frac{R_{K} \widehat{\sigma}^{2}(x)}{n h \widehat{f}(x)} \]
其中 \(\widehat{\sigma}^{2}(x)\) 来自 (19.17) 和 \(\widehat{f}(x)\) 是密度估计器,例如
\[ \widehat{f}(x)=\frac{1}{n b} \sum_{i=1}^{n} K\left(\frac{X_{i}-x}{b}\right) \]
其中 \(b\) 是带宽。 (参见《经济学家的概率与统计》第 17 章。)
一般来说,我们建议使用预测误差计算(19.18),因为这是有限样本协方差矩阵的最接近的模拟。
对于局部线性和局部多项式估计器,估计器 \(\widehat{V}_{\widehat{m}(x)}\) 是矩阵 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}(x)\) 的第一个对角元素。对于任何方差估计器,\(\widehat{m}(x)\) 的标准误差是 \(\widehat{V}_{\widehat{m}(x)}\) 的平方根。
19.17 置信带
我们可以构造渐近置信区间。 \(m(x)\) 的 95% 区间是
\[ \widehat{m}(x) \pm 1.96 \sqrt{\widehat{V}_{\widehat{m}(x)}} . \]
该置信区间可以与 \(\widehat{m}(x)\) 一起绘制以评估精度。
然而,应该指出的是,这个置信区间有两个不寻常的特性。首先,它在 \(x\) 中是逐点的,这意味着它被设计为在每个 \(x\) 上具有覆盖概率,而不是在 \(x\) 上均匀分布。因此,它们通常称为逐点置信区间。
其次,因为它没有考虑偏差,所以它不是 \(m(x)\) 的渐近有效置信区间。相反,它是伪真实(平滑)值的渐近有效置信区间,例如\(m(x)+h^{2} B(x)\)。思考这个问题的一种方法是,置信区间考虑了估计量的方差,但不考虑其偏差。解决这个问题的一个技术技巧是假设一个欠平滑的带宽。在这种情况下,上述置信区间在技术上是渐近有效的。这只是一个技术技巧,因为它并不能真正消除偏差,只是假设它消失了。显而易见的事实是,一旦我们诚实地承认真正的 CEF 是非参数的,那么任何有限样本估计量都将具有有限样本偏差,并且这种偏差本质上是未知的,因此很难纳入置信区间。
尽管有这些不寻常的特性,我们仍然可以使用区间 (19.20) 来显示不确定性并检查估计的精度。
19.18 核回归的局部性质
核回归估计器(Nadaraya-Watson、局部线性和局部多项式)本质上都是局部估计器,因为给定 \(h\),估计器 \(\widehat{m}(x)\) 仅是子样本的函数,其中 \(X\) 接近于 \(数学4\)。其他观察结果不会直接影响估计器。这也反映在分配理论中。定理 \(19.8\) 表明,如果 \(m(x)\) 在 \(x\) 处连续,则 \(\widehat{m}(x)\) 与 \(m(x)\) 是一致的。定理 \(19.9\) 表明 \(h\) 的渐近分布仅取决于 \(h\) 点处的函数 \(h\)、\(h\) 和 \(h\)。该分布不依赖于 \(h\) 的全局行为。然而,全局特征确实会通过带宽 \(h\) 影响估计器 \(h\)。这里描述的带宽选择方法本质上是全局的,因为它们试图最小化 AIMSE。也可以采用局部带宽(旨在最小化单点 \(h\) 处的 AMSE),但这些不太常用,部分原因是此类带宽估计器具有很高的不精确性。选择本地带宽会增加额外的噪音。
此外,所选择的带宽可以是有意义的大,使得估计窗口可以是样本的大部分。在这种情况下,估计既不是局部的也不是完全全局的。
19.19 工资回归的应用
我们通过 CPS 数据集的应用来说明这些方法。我们对 \(\log\)(工资)对经验的非参数回归感兴趣。为了说明这一点,我们选取受过 12 年教育的黑人男性(高中毕业生)作为子样本。该样本有 762 个观察值。
我们首先需要决定我们将计算回归估计器的感兴趣区域(经验范围)。我们选择 \([0,40]\) 范围是因为大多数观察结果 (90%) 的经验水平低于 40 年。
为了避免边界偏差,我们使用局部线性估计器。
接下来我们计算 Fan-Gijbels 经验带宽 (19.9) 并找到 \(h_{\text {rot }}=5.14\)。然后,我们使用经验法则作为基线来计算交叉验证标准。 CV 准则如图 19.5(a) 所示。最小化器是 \(h_{\mathrm{cv}}=4.32\),它比 ROT 带宽稍小。
我们使用两种带宽计算局部线性估计器,并在图 19.5(b) 中显示估计值。经验水平达到 20 年时,回归函数会不断增加,然后变得平坦。虽然这些函数大致是凹函数,但它们与传统的二次规范明显不同。比较估计值,较小的 CV 选择带宽产生的回归估计有点太波动,而 ROT 带宽产生的回归估计更平滑,但捕获了相同的基本特征。基于此检查,我们选择基于 ROT 带宽的估计(面板 (b) 中的实线)。
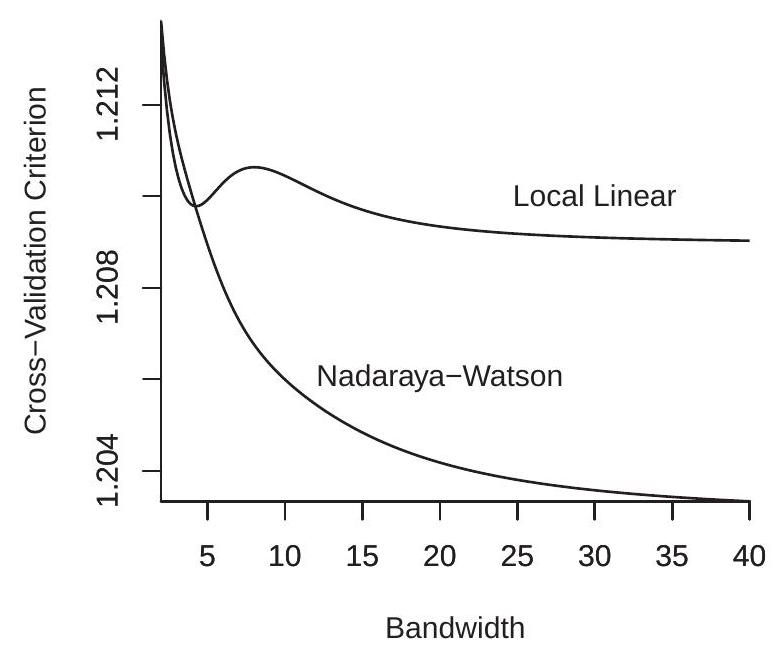
接下来我们考虑条件方差函数的估计。我们使用预测误差平方计算回归的 ROT 带宽,并发现 \(h_{\mathrm{rot}}=6.77\) 大于用于条件均值估计的带宽。接下来,我们使用 NW 和 LL 回归计算条件方差估计(经验预测误差平方的回归)的交叉验证函数。 CV 函数如图 19.6(a) 所示。 CV 情节非常有趣。对于 LL 估计器,CV 函数在 \(h=5\) 附近有一个局部最小值,但全局最小值是无界的。 NW 估计器的 CV 函数随着无界极小值全局递减。 NW 还获得了比 LL 估计器低得多的 CV 值。这意味着 CV 选择的方差估计器是带有 \(h=\infty\) 的 NW 估计器,它是使用预测误差计算的简单全样本估计器 \(\widehat{\sigma}^{2}\)。
接下来我们使用公式(19.18)计算回归函数估计的标准误差。在图 19.6(b) 中,我们显示了估计的回归(与使用 ROT 带宽的图 \(19.5\) 相同)以及按 (19.20) 计算的 \(95 %\) 渐近置信带。通过显示置信带,我们可以看到,对于低经验水平,估计器存在相当大的不精确性。我们仍然可以看到,估计值和置信区间表明,经验概况在大约 20 年的经验范围内不断增加,然后在 20 年以上趋于平缓。该估计表明,对于这一人群(高中毕业生的黑人男性)来说,前 20 年工作经验(从 18 岁到 38 岁)的平均工资会上涨,然后趋于平缓,接下来的平均工资不再增加。 20年工作经验(38岁至58岁)。
- 交叉验证标准
.jpg)
- 局部线性回归
图 19.5:经验的对数工资回归
19.20 聚类观察
聚类观察结果是聚类 \(g=1, \ldots, G\) 中个体 \(i=1, \ldots, n_{g}\) 的 \(\left(Y_{i g}, X_{i g}\right)\)。模型是
\[ \begin{aligned} Y_{i g} &=m\left(X_{i g}\right)+e_{i g} \\ \mathbb{E}\left[e_{i g} \mid \boldsymbol{X}_{g}\right] &=0 \end{aligned} \]
其中 \(\boldsymbol{X}_{g}\) 是堆叠的 \(X_{i g}\)。假设簇是相互独立的。每个集群内的依赖性是非结构化的。
写
\[ Z_{i g}(x)=\left(\begin{array}{c} 1 \\ X_{i g}-x \end{array}\right) . \]
将 \(Y_{i g}, e_{i g}\) 和 \(Z_{i g}(x)\) 堆叠到簇级变量 \(\boldsymbol{Y}_{g}, \boldsymbol{e}_{g}\) 和 \(Z_{g}(x)\) 中。让\(\boldsymbol{K}_{g}(x)=\operatorname{diag}\left\{K\left(\frac{X_{i g}-x}{h}\right)\right\}\)。局部线性估计器可以写为
\[ \begin{aligned} \widehat{\beta}(x) &=\left(\sum_{g=1}^{G} \sum_{i=1}^{n_{g}} K\left(\frac{X_{i g}-x}{h}\right) Z_{i g}(x) Z_{i g}(x)^{\prime}\right)^{-1}\left(\sum_{g=1}^{G} \sum_{i=1}^{n_{g}} K\left(\frac{X_{i g}-x}{h}\right) Z_{i g}(x) Y_{i g}\right) \\ &=\left(\sum_{g=1}^{G} \boldsymbol{Z}_{g}(x)^{\prime} \boldsymbol{K}_{g}(x) \boldsymbol{Z}_{g}(x)\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{Z}_{g}(x)^{\prime} \boldsymbol{K}_{g}(x) \boldsymbol{Y}_{g}\right) . \end{aligned} \]
局部线性估计器 \(\widehat{m}(x)=\widehat{\beta}_{1}(x)\) 是 (19.21) 中的截距。
获得预测误差的自然方法是通过删除簇回归。 \(\beta\) 的删除簇估计器是
\[ \widetilde{\beta}_{(-g)}(x)=\left(\sum_{j \neq g} \boldsymbol{Z}_{j}(x)^{\prime} \boldsymbol{K}_{j}(x) \boldsymbol{Z}_{j}(x)\right)^{-1}\left(\sum_{j \neq g} \boldsymbol{Z}_{j}(x)^{\prime} \boldsymbol{K}_{j}(x) \boldsymbol{Y}_{j}\right) . \]
- 条件方差的交叉验证
.jpg)
- 置信区间回归
图 19.6:置信带构建
\(m(x)\) 的删除簇估计器是 (19.22) 中的截距 \(\widetilde{m}_{1}(x)=\widetilde{\beta}_{1(-g)}(x)\)。观测 \(i g\) 的删除簇预测误差为
\[ \widetilde{e}_{i g}=Y_{i g}-\widetilde{\beta}_{1(-g)}\left(X_{i g}\right) . \]
令 \(\widetilde{\boldsymbol{e}}_{g}\) 为簇 \(g\) 的堆叠 \(\widetilde{e}_{i g}\)。
(19.21) 的方差以回归量 \(\boldsymbol{X}\) 为条件,为
\[ \boldsymbol{V}_{\widehat{\beta}}(x)=\left(\sum_{g=1}^{G} \boldsymbol{Z}_{g}(x)^{\prime} \boldsymbol{K}_{g}(x) \boldsymbol{Z}_{g}(x)\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{Z}_{g}(x)^{\prime} \boldsymbol{K}_{g}(x) \boldsymbol{S}_{g}(x) \boldsymbol{K}_{g}(x) \boldsymbol{Z}_{g}(x)\right)\left(\sum_{g=1}^{G} \boldsymbol{Z}_{g}(x)^{\prime} \boldsymbol{K}_{g}(x) \boldsymbol{Z}_{g}(x)\right)^{-1} \]
其中 \(\boldsymbol{S}_{g}=\mathbb{E}\left[\boldsymbol{e}_{g} \boldsymbol{e}_{g}^{\prime} \mid \boldsymbol{X}_{g}\right]\).协方差矩阵 (19.24) 可以通过用 \(\boldsymbol{e}_{g} \boldsymbol{e}_{g}^{\prime}\) 估计器替换 \(\boldsymbol{S}_{g}\) 来估计。基于与回归估计的类比,我们建议删除簇预测误差 \(\widetilde{\boldsymbol{e}}_{g}\),因为它们不会受到过度拟合的影响。使用此选择的协方差矩阵估计器是
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}(x)=\left(\sum_{g=1}^{G} \boldsymbol{Z}_{g}(x)^{\prime} \boldsymbol{K}_{g}(x) \boldsymbol{Z}_{g}(x)\right)^{-1}\left(\sum_{g=1}^{G} Z_{g}(x) \boldsymbol{K}_{g}(x) \widetilde{\boldsymbol{e}}_{g} \widetilde{\boldsymbol{e}}_{g}^{\prime} \boldsymbol{K}_{g}(x) \boldsymbol{Z}_{g}(x)\right)\left(\sum_{g=1}^{G} \boldsymbol{Z}_{g}(x) \boldsymbol{K}_{g}(x) \boldsymbol{Z}_{g}(x)\right)^{-1} . \]
\(\widehat{m}(x)\) 的标准误差是 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}(x)\) 第一个对角线元素的平方根。
目前还没有关于如何使用聚类观测值来选择带宽 \(h\) 进行非参数回归的理论。 Fan-Ghybels ROT 带宽 \(h_{\text {rot }}\) 是为独立观测而设计的,因此在集群观测的情况下可能是一个粗略的选择。标准交叉验证也有类似的局限性。一个实用的替代方案是选择带宽 \(h\) 来最小化删除集群交叉验证标准。虽然没有正式的理论来证明这种选择的合理性,但这似乎是一个合理的选择。删除簇 CV 准则为
\[ \mathrm{CV}(h)=\frac{1}{n} \sum_{g=1}^{G} \sum_{i=1}^{n_{g}} \widetilde{e}_{i g}^{2} \]
其中 \(\widetilde{e}_{i g}\) 是删除簇预测误差 (19.23)。删除簇 CV 带宽是最小化此函数的值:
\[ h_{\mathrm{cV}}=\underset{h \geq h_{\ell}}{\operatorname{argmin}} \mathrm{CV}(h) . \]
对于传统交叉验证的情况,绘制 \(\mathrm{CV}(h)\) 与 \(h\) 的关系图可能很有价值,以验证是否已获得最小值并评估敏感性。
19.21 测试成绩的应用
我们通过使用 Duflo、Dupas 和 Kremer(2011)对学生跟踪对测试分数的影响的调查,用聚类观察来说明核回归。回想一下,核心问题是虚拟变量跟踪对连续变量测试分数的影响。包括一组对照,其中包括记录学生初始测试分数(作为百分位数)的连续变量百分位数。我们使用局部线性回归研究了作者对该控制的规范。
我们对 1487 名经历过跟踪的女孩进行了子样本分析,并估计了百分位数测试分数的回归。对于此应用程序,我们使用非标准化 \({ }^{7}\) 测试分数,范围从 0 到大约 40 。我们使用带有高斯核的局部线性回归。
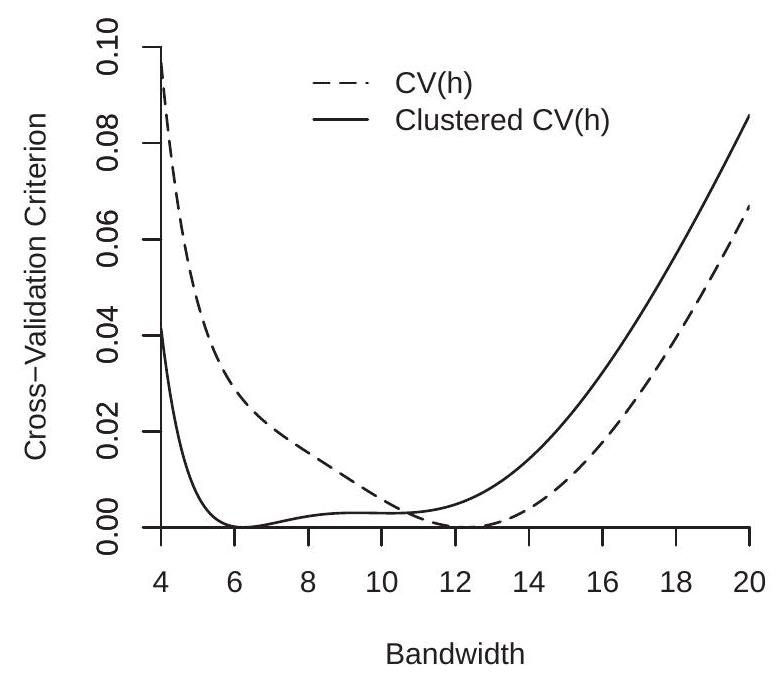
首先考虑带宽选择。 Fan-Ghybels ROT 和传统交叉验证带宽为 \(h_{\mathrm{rot}}=6.7\) 和 \(h_{\mathrm{cv}}=12.3\)。然后,我们计算了具有最小化 \(h_{\mathrm{cv}}=6.2\) 的聚类交叉验证标准。为了理解差异,我们在图 19.7(a) 中绘制了标准交叉验证函数和集群交叉验证函数。为了在同一张图上绘制,我们通过减去它们的最小值来标准化每个图(因此每个图都最小化为零)。从图 19.7(a) 中我们可以看到,虽然传统 CV 准则在 \(h=12.3\) 处急剧最小化,但聚类 CV 准则在 5 和 11 之间基本平坦。这意味着聚类 CV 准则很难区分这些带宽选择。
使用集群交叉验证选择的带宽,我们计算回归函数的局部线性估计器 \(\hat{m}_{\mathrm{LL}}(x)\)。估计值如图 19.7(b) 所示。我们计算删除簇预测误差 \(\widetilde{\boldsymbol{e}}_{g}\) 并使用这些误差通过公式 (19.25) 计算局部线性估计器 \(\widehat{m}_{\mathrm{LL}}(x)\) 的标准误差。 (这些标准误差大约是使用非聚类公式计算的标准误差的两倍。)我们使用标准误差来计算 \(95 %\) 渐近点置信带,如 (19.20) 中所示。这些与点估计一起绘制在图 19.7(b) 中。还绘制了估计的线性回归线以进行比较。局部线性估计器类似于低于 \(80 %\) 的初始百分位数的全局线性回归。但对于高于 \(80 %\) 的初始百分位数,两条线有所不同。置信带表明这些差异具有统计意义。初始测试成绩位于初始分布顶部的学生的平均最终测试成绩高于线性规范的预测。
19.22 多重回归器
为了简单起见,我们的分析重点关注实值 \(X\) 的情况,但核回归方法扩展到多重回归器情况,但代价是收敛速度降低。在本节中我们
\({ }^{7}\) 在第 4.21 节中,继 Duflo、Dupas 和 Kremer(2011)之后,因变量是标准化测试分数(标准化为均值为零,方差为一)。
- 交叉验证标准
.jpg)
- 局部线性回归
图 19.7:测试分数作为初始百分位数的函数
考虑估计条件期望函数 \(\mathbb{E}[Y \mid X=x]=m(x)\) 的情况,其中
\[ X=\left(\begin{array}{c} X_{1} \\ \vdots \\ X_{d} \end{array}\right) \in \mathbb{R}^{d} . \]
对于任何评估点 \(x\) 和观察值 \(i\) 定义核权重
\[ K_{i}(x)=K\left(\frac{X_{1 i}-x_{1}}{h_{1}}\right) K\left(\frac{X_{2 i}-x_{2}}{h_{2}}\right) \cdots K\left(\frac{X_{d i}-x_{d}}{h_{d}}\right), \]
\(d\) 倍的产品内核。核权重 \(K_{i}(x)\) 评估回归向量 \(X_{i}\) 是否接近欧几里得空间 \(\mathbb{R}^{d}\) 中的评估点 \(x\)。
这些权重取决于一组 \(d\) 带宽、\(h_{j}\),每个回归量一个。给定这些权重,Nadaraya-Watson 估计量采用以下形式
\[ \widehat{m}(x)=\frac{\sum_{i=1}^{n} K_{i}(x) Y_{i}}{\sum_{i=1}^{n} K_{i}(x)} . \]
对于局部线性估计器,定义
\[ Z_{i}(x)=\left(\begin{array}{c} 1 \\ X_{i}-x \end{array}\right) \]
然后局部线性估计器可以写成 \(\widehat{m}(x)=\widehat{\alpha}(x)\) 其中
\[ \begin{aligned} \left(\begin{array}{c} \widehat{\alpha}(x) \\ \widehat{\beta}(x) \end{array}\right) &=\left(\sum_{i=1}^{n} K_{i}(x) Z_{i}(x) Z_{i}(x)^{\prime}\right)^{-1} \sum_{i=1}^{n} K_{i}(x) Z_{i}(x) Y_{i} \\ &=\left(\boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Z}\right)^{-1} \boldsymbol{Z}^{\prime} \boldsymbol{K} \boldsymbol{Y} \end{aligned} \]
其中 \(K=\operatorname{diag}\left\{K_{1}(x), \ldots, K_{n}(x)\right\}\).
在多重回归器核回归中,交叉验证仍然是带宽选择的推荐方法。留一残差 \(\widetilde{e}_{i}\) 和交叉验证标准 \(\mathrm{CV}\left(h_{1}, \ldots, h_{d}\right)\) 的定义与单回归量情况中的定义相同。唯一的区别是,现在 CV 标准是 \(d\) 带宽 \(h_{1}, \ldots, h_{d}\) 上的函数。这意味着数值最小化需要比简单的网格搜索更有效地完成。
多回归量情况下估计量的渐近分布是单回归量情况的扩展。设\(f(x)\)表示\(X, \sigma^{2}(x)=\mathbb{E}\left[e^{2} \mid X=x\right]\)的边际密度,表示\(e=Y-m(X)\)的条件方差,并设置\(|h|=h_{1} h_{2} \cdots h_{d}\)。
命题 19.1 让 \(\hat{m}(x)\) 表示 \(m(x)\) 的 Nadarya-Watson 或局部线性估计器。由于 \(n \rightarrow \infty\) 和 \(h_{j} \rightarrow 0\) 使得 \(n|h| \rightarrow \infty\),
\[ \sqrt{n|h|}\left(\widehat{m}(x)-m(x)-\sum_{j=1}^{d} h_{j}^{2} B_{j}(x)\right) \underset{d}{\longrightarrow} \mathrm{N}\left(0, \frac{R_{K}^{d} \sigma^{2}(x)}{f(x)}\right) . \]
对于尊敬的沃森估计者
\[ B_{j}(x)=\frac{1}{2} \frac{\partial^{2}}{\partial x_{j}^{2}} m(x)+f(x)^{-1} \frac{\partial}{\partial x_{j}} f(x) \frac{\partial}{\partial x_{j}} m(x) \]
对于局部线性估计器
\[ B_{j}(x)=\frac{1}{2} \frac{\partial^{2}}{\partial x_{j}^{2}} m(x) . \]
我们不提供正则性条件或正式证明,而是建议感兴趣的读者参考 Fan 和 Gijbels (1996)。
19.23 维度诅咒
术语“维数灾难”用于描述非参数估计器的收敛速度随着维数的增加而减慢的现象。
当 \(X\) 是向量值时,我们将 AIMSE 定义为偏差平方加方差的积分,相对于 \(f(x) w(x)\) 进行积分,其中 \(w(x)\) 是可积权重函数。为了符号简单起见,考虑有一个公共带宽 \(h\) 的情况。在这种情况下,\(\widehat{m}(x)\) 的 AIMSE 等于
\[ \text { AIMSE }=h^{4} \int_{S}\left(\sum_{j=1}^{d} B_{j}(x)\right)^{2} f(x) w(x) d x+\frac{R_{K}^{d}}{n h^{d}} \int_{S} \sigma^{2}(x) w(x) d x \]
我们看到平方偏差的阶数是 \(h^{4}\),与单回归量的情况相同。然而,方差的数量级更大\(\left(n h^{d}\right)^{-1}\)。
如果选择带宽来最小化 AIMSE,我们发现对于某个常数 c,它等于 \(h=\mathrm{cn}^{-1 /(4+d)}\)。这概括了一维情况的公式。 \(n^{-1 /(4+d)}\) 的速率比 \(n^{-1 / 5}\) 的速率慢。这实际上意味着使用多个回归器需要更大的带宽。当带宽设置为 \(h=c n^{-1 /(4+d)}\) 时,AIMSE 的阶数为 \(O\left(n^{-4 /(4+d)}\right)\)。与一维情况相比,这是一个较慢的收敛速度。
定理 19.11 对于向量值 \(X\),最小化 AIMSE 的带宽的量级为 \(h \sim n^{-1 /(4+d)}\)。使用 \(h \sim n^{-1 /(4+d)}\),然后使用 AIMSE \(=O\left(n^{-4 /(4+d)}\right)\)。
参见练习 19.6。
我们看到最优 AIMSE 率 \(O\left(n^{-4 /(4+d)}\right)\) 取决于维度 \(d\)。随着 \(d\) 的增加,这个速度会减慢。因此,使用多个回归器时,核回归估计器的精度会变差。原因是估计器 \(\widehat{m}(x)\) 是 \(Y\) 观测值的局部平均值,使得 \(X\) 接近 \(x\),并且当存在多个回归器时,此类观测值的数量本质上会较小。
这种现象——非参数估计的收敛速度随着维数的增加而降低——被称为维数灾难。它在大多数非参数估计问题中都很常见,并且并非特定于核回归。
维数灾难导致了这样的实际规则:非参数回归的大多数应用都只有一个回归量。有些有两个回归量;偶尔,三个。更多的是不常见的。
19.24 部分线性回归
为了处理离散回归量和/或降低维度,我们可以将回归函数分为非参数部分和参数部分。将回归量划分为 \((X, Z)\),其中 \(X\) 和 \(Z\) 分别是 \(d\) 和 \(k\) 维。部分线性回归模型是
\[ \begin{aligned} Y &=m(X)+Z^{\prime} \beta+e \\ \mathbb{E}[e \mid X, Z] &=0 . \end{aligned} \]
该模型结合了两个元素。第一,它指定 CEF 在 \(X\) 和 \(Z\) 之间是可分离的(不存在非参数交互)。第二,它指定 CEF 在回归量 \(Z\) 中是线性的。这些假设可能是正确的,也可能是错误的。在实践中,最好将假设视为近似值。
当某些回归量是离散的(这在计量经济学应用中很常见)时,它们属于 \(Z\)。回归量 \(X\) 必须连续分布。在典型应用中,\(X\) 是标量或二维的。这在实践中可能不是限制,因为许多计量经济学应用仅具有少量连续分布的回归量。
Robinson (1988) 对 (19.26) 的估计做出了开创性的贡献,他提出了残差回归的非参数版本。他的主要见解是发现非参数成分可以通过变换消除。取以 \(X\) 为条件的方程 (19.26) 的期望。这是
\[ \mathbb{E}[Y \mid X]=m(X)+\mathbb{E}[Z \mid X]^{\prime} \beta . \]
从 (19.26) 中减去该值,得到
\[ Y-\mathbb{E}[Y \mid X]=(Z-\mathbb{E}[Z \mid X])^{\prime} \beta+e . \]
该模型现在是非参数回归误差 \(Y-\mathbb{E}[Y \mid X]\) 对非参数回归误差向量 \(Z-\mathbb{E}[Z \mid X]\) 的线性回归。
罗宾逊估计器用非参数对应物代替了不可行的回归误差。结果是一个三步估计器。 1. 使用非参数回归(NW 或 LL),对 \(Y_{i}\) 对 \(X_{i}, Z_{1 i}\) 对 \(X_{i}, Z_{2 i}\) 对 \(X_{i}, \ldots\) 进行回归,对 \(Z_{k i}\) 对 \(X_{i}\) 进行回归,获得拟合值 \(\widehat{g}_{0 i}, \widehat{g}_{1 i}, \ldots\) 和 \(\widehat{g}_{k i}\)。
对 \(Z_{1 i}-\widehat{g}_{1 i}, \ldots, Z_{k i}-\widehat{g}_{k i}\) 进行回归 \(Y_{i}-\widehat{g}_{0 i}\) 以获得系数估计值 \(\widehat{\beta}\) 和标准误差。
使用非参数回归将 \(Y_{i}-Z_{i}^{\prime} \widehat{\beta}\) 回归到 \(X_{i}\) 上,以获得非参数估计量 \(\widehat{m}(x)\) 和置信区间。
在带宽的特定假设下,所得的估计量和标准误差具有传统的渐近分布。 Robinson (1988) 提供了完整的证明。 Andrews (2004) 提供了一种更通用的处理方法,深入了解半参数估计量的一般结构。
最困难的挑战是证明渐近分布 \(\widehat{\beta}\) 不受第一步估计的影响。简而言之,这些是论证的步骤。首先,第一步误差 \(Z-\mathbb{E}[Z \mid X]\) 与回归误差 \(e\) 的协方差为零。其次,如果用第一步非参数估计量替换(在此协方差中)期望 \(\mathbb{E}[Z \mid X]\) 会导致 \(o_{p}\left(n^{-1 / 2}\right)\) 阶误差,则渐近分布将不受第一步估计的影响。第三,由于协方差是一个乘积,因此当第一步估计器的收敛率为 \(o_{p}\left(n^{-1 / 4}\right)\) 时,这一点成立。第四,如果 \(h \sim n^{-1 /(4+d)}\) 和 \(d<4\),则这在定理 \(19.11\) 下成立。
第三步估计量具有传统渐近分布的原因比较容易解释。估计器 \(\widehat{\beta}\) 以传统的 \(O_{p}\left(n^{-1 / 2}\right)\) 速率收敛。非参数估计器 \(\widehat{m}(x)\) 的收敛速度比 \(O_{p}\left(n^{-1 / 2}\right)\) 慢。因此,\(\widehat{\beta}\) 的采样误差是较低阶的,不会影响 \(\widehat{m}(x)\) 的一阶渐近分布。
再次,理论是先进的,因此以上两段不应被视为解释。好消息是估计方法很简单。
19.25 计算
Stata 有两个实现内核回归的命令:lpoly 和 npregress。 1poly 对任何 \(p\) 实现局部多项式估计,包括 Nadaraya-Watson(默认)和局部线性估计,并使用 Fan-Gijbels ROT 方法选择带宽。它默认使用 Epanechnikov 内核,但可以选择高斯内核。 l poly 命令自动显示估计的 CEF 以及 95% 置信带以及使用 (19.18) 计算的标准误差。
Stata 命令 npregress 估计局部线性(默认)或 Nadaraya-Watson 回归。默认情况下,它通过交叉验证选择带宽。它默认使用 Epanechnikov 内核,但可以选择高斯内核。置信区间可以使用百分位数引导来计算。可以使用后估计命令裕度来显示特定点处的估计 CEF 和 95% 置信带(使用百分位数引导程序计算)。
有几个 R 包可以实现内核回归。一种灵活的选择是 np 包中提供的 npreg。其默认方法是使用高斯核进行 Nadaraya-Watson 估计,并通过交叉验证选择带宽。有一些选项允许局部线性和局部多项式估计、替代内核和替代带宽选择方法。
19.26 技术证明*
对于所有技术证明,我们做出简化假设,即核函数 \(K(u)\) 具有有限支持,因此 \(K(u)=0\) 对于 \(|u|>a\)。结果扩展到高斯核,但有额外的技术参数。定理证明 19.1.1。方程(19.3)表明
\[ \mathbb{E}\left[\widehat{m}_{\mathrm{nW}}(x) \mid \boldsymbol{X}\right]=m(x)+\frac{\widehat{b}(x)}{\widehat{f}(x)} \]
其中 \(\widehat{f}(x)\) 是 \(f(x)\) 与 \(b=h\) 的核密度估计器 (19.19) 和
\[ \widehat{b}(x)=\frac{1}{n h} \sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)\left(m\left(x_{i}\right)-m(x)\right) . \]
《经济学家概率与统计》的定理 \(17.6\) 确立了 \(\widehat{f}(x) \underset{p}{\longrightarrow} f(x)\)。通过证明 \(\widehat{b}(x)=h^{2} f(x) B_{\mathrm{nw}}(x)+o_{p}\left(h^{2}+1 / \sqrt{n h}\right)\) 来完成证明。
由于 \(\widehat{b}(x)\) 是样本平均值,因此它具有期望
\[ \begin{aligned} \mathbb{E}[\widehat{b}(x)] &=\frac{1}{h} \mathbb{E}\left[K\left(\frac{X-x}{h}\right)(m(X)-m(x))\right] \\ &=\int_{-\infty}^{\infty} \frac{1}{h} K\left(\frac{v-x}{h}\right)(m(v)-m(x)) f(v) d v \\ &=\int_{-\infty}^{\infty} K(u)(m(x+h u)-m(x)) f(x+h u) d u . \end{aligned} \]
第二个等式将期望写成相对于 \(X\) 密度的积分。第三个使用变量更改 \(v=x+h u\)。接下来我们使用两个泰勒级数展开式
\[ \begin{gathered} m(x+h u)-m(x)=m^{\prime}(x) h u+\frac{1}{2} m^{\prime \prime}(x) h^{2} u^{2}+o\left(h^{2}\right) \\ f(x+h u)=f(x)+f^{\prime}(x) h u+o(h) \end{gathered} \]
代入(19.29)我们发现(19.29)等于
\[ \begin{aligned} &\int_{-\infty}^{\infty} K(u)\left(m^{\prime}(x) h u+\frac{1}{2} m^{\prime \prime}(x) h^{2} u^{2}+o\left(h^{2}\right)\right)\left(f(x)+f^{\prime}(x) h u+o(h)\right) d u \\ &=h\left(\int_{-\infty}^{\infty} u K(u) d u\right) m^{\prime}(x)(f(x)+o(h)) \\ &+h^{2}\left(\int_{-\infty}^{\infty} u^{2} K(u) d u\right)\left(\frac{1}{2} m^{\prime \prime}(x) f(x)+m^{\prime}(x) f^{\prime}(x)\right) \\ &+h^{3}\left(\int_{-\infty}^{\infty} u^{3} K(u) d u\right) \frac{1}{2} m^{\prime \prime}(x) f^{\prime}(x)+o\left(h^{2}\right) \\ &=h^{2}\left(\frac{1}{2} m^{\prime \prime}(x) f(x)+m^{\prime}(x) f^{\prime}(x)\right)+o\left(h^{2}\right) \\ &=h^{2} B_{\mathrm{nw}}(x) f(x)+o\left(h^{2}\right) . \end{aligned} \]
第二个等式使用以下事实:核 \(K(x)\) 积分为 1,其奇矩为零,核方差为 1。我们已经证明了\(\mathbb{E}[\widehat{b}(x)]=B_{\mathrm{nw}}(x) f(x) h^{2}+o\left(h^{2}\right)\)。
现在考虑 \(\widehat{b}(x)\) 的方差。由于\(\widehat{b}(x)\)是独立分量的样本平均值并且方差小于二阶矩
\[ \begin{aligned} \operatorname{var}[\widehat{b}(x)] &=\frac{1}{n h^{2}} \operatorname{var}\left[K\left(\frac{X-x}{h}\right)(m(X)-m(x))\right] \\ & \leq \frac{1}{n h^{2}} \mathbb{E}\left[K\left(\frac{X-x}{h}\right)^{2}(m(X)-m(x))^{2}\right] \\ &=\frac{1}{n h} \int_{-\infty}^{\infty} K(u)^{2}(m(x+h u)-m(x))^{2} f(x+h u) d u \\ &=\frac{1}{n h} \int_{-\infty}^{\infty} u^{2} K(u)^{2} d u\left(m^{\prime}(x)\right)^{2} f(x)\left(h^{2}+o(1)\right) \\ & \leq \frac{h}{n} \bar{K}\left(m^{\prime}(x)\right)^{2} f(x)+o\left(\frac{h}{n}\right) \end{aligned} \]
第二个等式将期望写成积分。第三个使用(19.30)。最终的不等式使用定义 19.1.1 中的 \(K(u) \leq \bar{K}\) 以及核方差为 1 的事实。这表明
\[ \operatorname{var}[\widehat{b}(x)] \leq O\left(\frac{h}{n}\right) . \]
我们共同得出结论:
\[ \widehat{b}(x)=h^{2} f(x) B_{\mathrm{nw}}(x)+o\left(h^{2}\right)+O_{p}\left(\sqrt{\frac{h}{n}}\right) \]
和
\[ \frac{\widehat{b}(x)}{\widehat{f}(x)}=h^{2} B_{\mathrm{nw}}(x)+o_{p}\left(h^{2}\right)+O_{p}\left(\sqrt{\frac{h}{n}}\right) . \]
与 (19.27) 一起意味着定理 19.1.1。
定理证明19.2.1。方程(19.4)表明
\[ n h \operatorname{var}\left[\widehat{m}_{\mathrm{nw}}(x) \mid \boldsymbol{X}\right]=\frac{\widehat{v}(x)}{\widehat{f}(x)^{2}} \]
在哪里
\[ \widehat{v}(x)=\frac{1}{n h} \sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right)^{2} \sigma^{2}\left(X_{i}\right) \]
\(\widehat{f}(x)\) 是 \(f(x)\) 的估计器 (19.19)。经济学家概率论与数理统计定理\(17.6\)成立\(\widehat{f}(x) \underset{p}{\longrightarrow} f(x)\)。通过显示 \(\widehat{v}(x) \underset{p}{\rightarrow} R_{K} \sigma^{2}(x) f(x)\) 即可完成证明。
首先,将期望写成关于 \(f(x)\) 的积分,使变量变化为 \(v=x+h u\),并诉诸 \(\sigma^{2}(x)\) 和 \(f(x)\) 在 \(x\) 上的连续性,
\[ \begin{aligned} \mathbb{E}[\widehat{v}(x)] &=\int_{-\infty}^{\infty} \frac{1}{h} K\left(\frac{v-x}{h}\right)^{2} \sigma^{2}(v) f(v) d v \\ &=\int_{-\infty}^{\infty} K(u)^{2} \sigma^{2}(x+h u) f(x+h u) d u \\ &=\int_{-\infty}^{\infty} K(u)^{2} \sigma^{2}(x) f(x)+o(1) \\ &=R_{K} \sigma^{2}(x) f(x) . \end{aligned} \]
其次,因为\(\widehat{v}(x)\)是独立随机变量的平均值并且方差小于二阶矩
\[ \begin{aligned} n h \operatorname{var}[\widehat{v}(x)] &=\frac{1}{h} \operatorname{var}\left[K\left(\frac{X-x}{h}\right)^{2} \sigma^{2}(X)\right] \\ & \leq \frac{1}{h} \int_{-\infty}^{\infty} K\left(\frac{v-x}{h}\right)^{4} \sigma^{4}(v) f(v) d v \\ &=\int_{-\infty}^{\infty} K(u)^{4} \sigma^{4}(x+h u) f(x+h u) d u \\ & \leq \bar{K}^{2} R_{k} \sigma^{4}(x) f(x)+o(1) \end{aligned} \]
所以\(\operatorname{var}[\widehat{v}(x)] \rightarrow 0\)。
我们从马尔可夫不等式推导出\(\widehat{v}(x) \underset{p}{\longrightarrow} R_{K} \sigma^{2}(x) f(x)\),完成证明。
定理19.7的证明。观察到 \(m\left(X_{i}\right)-\tilde{m}_{-i}\left(X_{i}, h\right)\) 仅是 \(\left(X_{1}, \ldots, X_{n}\right)\) 和 \(\left(e_{1}, \ldots, e_{n}\right)\) 的函数,不包括 \(e_{i}\),因此与 \(e_{i}\) 不相关。由于 \(\widetilde{e}_{i}(h)=m\left(X_{i}\right)-\widetilde{m}_{-i}\left(X_{i}, h\right)+e_{i}\),那么
\[ \begin{aligned} \mathbb{E}[\mathrm{CV}(h)] &=\mathbb{E}\left(\widetilde{e}_{i}(h)^{2} w\left(X_{i}\right)\right) \\ &=\mathbb{E}\left[e_{i}^{2} w\left(X_{i}\right)\right]+\mathbb{E}\left[\left(\widetilde{m}_{-i}\left(X_{i}, h\right)-m\left(X_{i}\right)\right)^{2} w\left(X_{i}\right)\right] \\ &+2 \mathbb{E}\left[\left(\widetilde{m}_{-i}\left(X_{i}, h\right)-m\left(X_{i}\right)\right) w\left(X_{i}\right) e_{i}\right] \\ &=\bar{\sigma}^{2}+\mathbb{E}\left[\left(\widetilde{m}_{-i}\left(X_{i}, h\right)-m\left(X_{i}\right)\right)^{2} w\left(X_{i}\right)\right] . \end{aligned} \]
第二项是对随机变量 \(X_{i}\) 和 \(\widetilde{m}_{-i}(x, h)\) 的期望,它们是独立的,因为第二项不是 \(i^{t h}\) 观测值的函数。因此,在给定排除 \(i^{t h}\) 观察值的样本的情况下,取条件期望,这只是对 \(X_{i}\) 的期望,它是相对于其密度的积分
\[ \mathbb{E}_{-i}\left[\left(\widetilde{m}_{-i}\left(X_{i}, h\right)-m\left(X_{i}\right)\right)^{2} w\left(X_{i}\right)\right]=\int\left(\widetilde{m}_{-i}(x, h)-m(x)\right)^{2} f(x) w(x) d x . \]
采取无条件期望收益率
\[ \begin{aligned} \mathbb{E}\left[\left(\widetilde{m}_{-i}\left(X_{i}, h\right)-m\left(X_{i}\right)\right)^{2} w\left(X_{i}\right)\right] &=\mathbb{E}\left[\int\left(\widetilde{m}_{-i}(x, h)-m(x)\right)^{2} f(x) w(x) d x\right] \\ &=\operatorname{IMSE}_{n-1}(h) \end{aligned} \]
其中,这是大小为 \(n-1\) 的样本的 IMSE,因为估计器 \(\widetilde{m}_{-i}\) 使用 \(n-1\) 观测值。结合(19.35)我们得到(19.12),如所期望的。
定理19.8的证明。我们可以将 Nadaraya-Watson 估计量写为
\[ \widehat{m}_{\mathrm{nw}}(x)=m(x)+\frac{\widehat{b}(x)}{\widehat{f}(x)}+\frac{\widehat{g}(x)}{\widehat{f}(x)} \]
其中 \(\widehat{f}(x)\) 是估计器 (19.19),\(\widehat{b}(x)\) 在 (19.28) 中定义,并且
\[ \widehat{g}(x)=\frac{1}{n h} \sum_{i=1}^{n} K\left(\frac{X_{i}-x}{h}\right) e_{i} . \]
由于 \(\widehat{f}(x) \underset{p}{\longrightarrow} f(x)>0\) 由《经济学家概率论与数理统计》定理 \(17.6\) 得出,通过显示 \(\widehat{b}(x) \underset{p}{\longrightarrow} 0\) 和 \(\widehat{g}(x) \underset{p}{\longrightarrow} 0\) 即可完成证明。以 \(\widehat{b}(x)\) 为例。从 (19.29) 以及 \(m(x)\) 和 \(f(x)\) 的连续性
\[ \mathbb{E}[\widehat{b}(x)]=\int_{-\infty}^{\infty} K(u)(m(x+h u)-m(x)) f(x+h u) d u=o(1) \]
作为 \(h \rightarrow \infty\)。从 (19.33) 开始,
\[ n h \operatorname{var}[\widehat{b}(x)] \leq \int_{-\infty}^{\infty} K(u)^{2}(m(x+h u)-m(x))^{2} f(x+h u) d u=o(1) \]
作为 \(h \rightarrow \infty\)。因此\(\operatorname{var}[\widehat{b}(x)] \longrightarrow 0\)。根据马尔可夫不等式我们得出\(\widehat{b}(x) \stackrel{p}{\longrightarrow} 0\)。
以 \(\widehat{g}(x)\) 为例。由于 \(\widehat{g}(x)\) 在 \(e_{i}\) 和 \(\mathbb{E}[e \mid X]=0\) 中是线性的,因此我们找到 \(\mathbb{E}[\widehat{g}(x)]=0\)。由于\(\widehat{g}(x)\)是独立随机变量的平均值,方差小于二阶矩,定义\(\sigma^{2}(X)=\mathbb{E}\left[e^{2} \mid X\right]\)
\[ \begin{aligned} n h \operatorname{var}[\widehat{g}(x)] &=\frac{1}{h} \operatorname{var}\left[K\left(\frac{X-x}{h}\right) e\right] \\ & \leq \frac{1}{h} \mathbb{E}\left[K\left(\frac{X-x}{h}\right)^{2} e^{2}\right] \\ &=\frac{1}{h} \mathbb{E}\left[K\left(\frac{X-x}{h}\right)^{2} \sigma^{2}(X)\right] \\ &=\int_{-\infty}^{\infty} K(u)^{2} \sigma^{2}(x+h u) f(x+h u) d u \\ &=R_{K} \sigma^{2}(x) f(x)+o(1) \end{aligned} \]
因为 \(\sigma^{2}(x)\) 和 \(f(x)\) 在 \(x\) 中是连续的。因此\(\operatorname{var}[\widehat{g}(x)] \longrightarrow 0\)。根据马尔可夫不等式我们得出\(\widehat{g}(x) \underset{p}{\longrightarrow} 0\),完成证明。
定理19.9的证明。从(19.36),《经济学家概率与统计定理 \(17.6\)》和(19.34)我们有
\[ \begin{aligned} \sqrt{n h}\left(\widehat{m}_{\mathrm{nw}}(x)-m(x)-h^{2} B_{\mathrm{nw}}(x)\right) &=\sqrt{n h}\left(\frac{\widehat{g}(x)}{\widehat{f}(x)}\right)+\sqrt{n h}\left(\frac{\widehat{b}(x)}{\widehat{f}(x)}-h^{2} B_{\mathrm{nw}}(x)\right) \\ &=\sqrt{n h}\left(\frac{\widehat{g}(x)}{f(x)}\right)\left(1+o_{p}(1)\right)+\sqrt{n h}\left(o_{p}\left(h^{2}\right)+O_{p}\left(\sqrt{\frac{h}{n}}\right)\right) \\ &=\sqrt{n h}\left(\frac{\widehat{g}(x)}{f(x)}\right)\left(1+o_{p}(1)\right)+\left(o_{p}\left(\sqrt{n h^{5}}\right)+O_{p}(h)\right) \\ &=\sqrt{n h}\left(\frac{\widehat{g}(x)}{f(x)}\right)+o_{p}(1) \end{aligned} \]
其中最终等式成立,因为 \(\sqrt{n h} \widehat{g}(x)=O_{p}(1)\) 除以 (19.38) 且假设 \(n h^{5}=O(1)\)。通过显示 \(\sqrt{n h} \widehat{g}(x) \underset{d}{\longrightarrow} \mathrm{N}\left(0, R_{K} \sigma^{2}(x) f(x)\right)\) 即可完成证明。
定义 \(Y_{n i}=h^{-1 / 2} K\left(\frac{X_{i}-x}{h}\right) e_{i}\) ,它们是独立的且均值为零。我们可以将 \(\sqrt{n h} \widehat{g}(x)=\sqrt{n} \bar{Y}\) 写为标准化样本平均值。我们验证了 Lindeberg CLT 的条件(定理 6.4)。在定理 6.4 的表示法中,将 \(\bar{\sigma}_{n}^{2}=\operatorname{var}[\sqrt{n} \bar{Y}] \rightarrow R_{K} f(x) \sigma^{2}(x)\) 设置为 \(h \rightarrow 0\)。如果我们能够验证 Lindeberg 条件,则 CLT 成立。
这是一种高级计算,大多数读者不会感兴趣。它是为那些对完整推导感兴趣的人提供的。修复 \(\epsilon>0\) 和 \(\delta>0\)。由于 \(K(u)\) 是有界的,我们可以写成 \(K(u) \leq \bar{K}\)。让 \(n h\) 足够大,以便
\[ \left(\frac{\epsilon n h}{\bar{K}^{2}}\right)^{(r-2) / 2} \geq \frac{\bar{\sigma}}{\delta} . \]
条件矩界限 (19.14) 意味着对于 \(x \in \mathscr{N}\),
\[ \begin{aligned} \mathbb{E}\left[e^{2} \mathbb{1}\left\{e^{2}>\frac{\epsilon n h}{\bar{K}^{2}}\right\} \mid X=x\right] &=\mathbb{E}\left[\frac{|e|^{r}}{|e|^{r-2}} \mathbb{1}\left\{e^{2}>\frac{\epsilon n h}{\bar{K}^{2}}\right\} \mid X=x\right] \\ & \leq \mathbb{E}\left[\frac{|e|^{r}}{\left(\epsilon n h / \bar{K}^{2}\right)^{(r-2) / 2}} \mid X=x\right] \\ & \leq \delta . \end{aligned} \]
由于 \(Y_{n i}^{2} \leq h^{-1} \bar{K}^{2} e_{i}^{2}\) 我们发现
\[ \begin{aligned} \mathbb{E}\left[Y_{n i}^{2} \mathbb{1}\left\{Y_{n i}^{2}>\epsilon n\right\}\right] & \leq \frac{1}{h} \mathbb{E}\left[K\left(\frac{X-x}{h}\right)^{2} e^{2} \mathbb{1}\left\{e^{2}>\frac{\epsilon n h}{\bar{K}^{2}}\right\}\right] \\ &=\frac{1}{h} \mathbb{E}\left[K\left(\frac{X-x}{h}\right)^{2} \mathbb{E}\left(e^{2} \mathbb{1}\left\{e^{2}>\frac{\epsilon n h}{\bar{K}^{2}}\right\} \mid X\right)\right] \\ &=\int_{-\infty}^{\infty} K(u)^{2} \mathbb{E}\left[e^{2} \mathbb{1}\left\{e^{2}>\epsilon n h / \bar{K}^{2}\right\} \mid X=x+h u\right] f(x+h u) d u \\ & \leq \delta \int_{-\infty}^{\infty} K(u)^{2} f(x+h u) d u \\ &=\delta R_{K} f(x)+o(1) \\ &=o(1) \end{aligned} \]
因为 \(\delta\) 是任意的。这就是林德伯格条件 (6.2)。 Lindeberg CLT(定理 6.4)表明
\[ \sqrt{n h} \widehat{g}(x)=\sqrt{n} \bar{Y} \underset{d}{\longrightarrow} \mathrm{N}\left(0, R_{K} \sigma^{2}(x) f(x)\right) \]
这样就完成了证明。
19.27 练习
练习19.1 对于核回归,假设您重新缩放\(Y\),例如用\(100 Y\)替换\(Y\)。带宽 \(h\) 应该如何变化?要回答这个问题,首先要解决函数 \(m(x)\) 和 \(\sigma^{2}(x)\) 在重新缩放下如何变化,然后计算 \(\bar{B}\) 和 \(\bar{\sigma}^{2}\) 如何变化。推断最优 \(h_{0}\) 如何因重新缩放 \(Y\) 而发生变化。你的答案直观吗?
练习 19.2 证明 (19.6) 最小化了 AIMSE (19.5)。
练习19.3 用文字描述局部线性估计器的偏差如何在\(m(x)\)中的凸性和凹性区域中变化。这有直观意义吗?
练习19.4 假设真实的回归函数是线性的\(m(x)=\alpha+\beta x\),我们使用Nadaraya-Watson 估计器来估计该函数。计算偏差函数\(B(x)\)。假设\(\beta>0\)。 \(B(x)>0\) 对应哪些区域,\(B(x)<0\) 对应哪些区域?现在假设 \(\beta<0\) 并重新回答问题。您能否直观地解释为什么 NW 估计量对这些区域有正偏和负偏?练习19.5 假设\(m(x)=\alpha\)是一个常数函数。找到用于 NW 估计的 AIMSE 最佳带宽 (19.6)?解释。
练习19.6 证明定理19.11:表明当\(d \geq 1\) 时,AIMSE 最佳带宽采用\(h_{0}=c n^{-1 /(4+d)}\) 形式,AIMSE 为\(O\left(n^{-4 /(4+d)}\right)\)。
练习 19.7 获取 DDK2011 数据集和经历过跟踪的男孩的子样本。如 \(19.21\) 节中所示,使用局部线性估计器来估计百分位数测试分数的回归,但现在使用男孩的子样本。使用 \(95 %\) 置信区间绘图。评论与女孩子样本估计值的异同。
练习19.8 取cps09mar数据集和受教育程度=20(专业学位或博士学位)、经验在0到40年之间的个体的子样本。
使用 Nadaraya-Watson 分别估计男性和女性的 log(工资)对经验的回归。使用 \(95 %\) 置信区间绘图。评论估计工资情况如何随经验变化。特别是,您是否认为有证据表明该教育群体的经验水平高于 20 时预期工资会下降?
使用局部线性估计器重复。估计值和置信区间如何变化?
练习 19.9 使用 Invest1993 数据集和 \(Q \leq 5\) 的观测子样本。 (在数据集中 \(Q\) 是变量 vala。)
使用 Nadaraya-Watson 估计 \(I\) 对 \(Q\) 的回归。 (在数据集中 \(I\) 是变量 inva。)使用 \(95 %\) 置信区间进行绘图。
使用局部线性估计器重复。
是否有证据表明回归函数是非线性的?
练习 19.10 RR2010 数据集来自 Reinhart 和 Rogoff (2010)。它包含对 1791 年至 2009 年较长时期内美国 GDP 增长率、通货膨胀率以及债务/GDP 比率的观察。该论文强烈主张,随着债务/GDP 的增加,GDP 增长放缓,特别是这种关系是非线性的,债务比率超过 \(90 %\) 时,债务会对增长产生负面影响。他们的完整数据集包括 44 个国家/地区。我们的摘录仅包括美国。
使用 Nadaraya-Watson 估计 GDP 增长对债务比率的回归。具有 95% 置信区间的绘图。
使用局部线性估计器重复。
您是否看到 \(90 %\) 处存在非线性和/或关系变化的证据?
现在估计 GDP 增长对通货膨胀率的回归。评论你的发现。
练习19.11 我们将考虑gdp增长率的非线性AR(1)模型
\[ \begin{aligned} &Y_{t}=m\left(Y_{t-1}\right)+e_{t} \\ &Y_{t}=100\left(\left(\frac{G D P_{t}}{G D P_{t-1}}\right)^{4}-1\right) \end{aligned} \]
创建 GDP 增长率 \(Y_{t}\)。从 FRED-QD 中提取美国实际 GDP 水平(\(\left.g d p c 1\right)\),并将上述转换为增长率。
使用 Nadaraya-Watson 估计 \(m(x)\)。具有 95% 置信区间的绘图。
使用局部线性估计器重复。
你看到非线性的证据了吗?