第4章: 最小二乘回归
4 最小二乘回归
4.1 介绍
在本章中,我们研究线性回归模型中最小二乘估计器的一些有限样本属性。特别是,我们计算其有限样本期望和协方差矩阵,并提出系数估计器的标准误差。
4.2 随机抽样
假设 \(3.1\) 指定观测值具有相同的分布。为了导出估计量的有限样本属性,我们需要另外指定观测值之间的依赖结构。
最简单的情况是观察值相互独立,在这种情况下,我们说它们是独立同分布的或独立同分布的。描述 i.i.d 也很常见。观察作为随机样本。传统上,随机抽样一直是横截面(例如调查)背景下的默认假设。非常方便,因为 i.i.d.抽样可以得出估计方差的简单表达式。当样本较小且相对分散时,该假设似乎是合适的(意味着它应该大致有效)。也就是说,如果您从美国等大国随机抽取 1000 人样本,那么将他们的反应建模为相互独立似乎是合理的。
假设 4.1 随机变量 \(\left\{\left(Y_{1}, X_{1}\right), \ldots,\left(Y_{i}, X_{i}\right), \ldots,\left(Y_{n}, X_{n}\right)\right\}\) 是独立且同分布的。
在本章的大部分内容中,我们将使用假设 \(4.1\) 来导出 OLS 估计器的属性。
假设 \(4.1\) 意味着如果您在样本中选取任意两个个体 \(i \neq j\),则值 \(\left(Y_{i}, X_{i}\right)\) 独立于值 \(\left(Y_{j}, X_{j}\right)\),但具有相同的分布。独立性意味着个人\(i\)的决定和选择不会影响个人\(j\)的决定,反之亦然。
如果样本中的个人以某种方式存在联系,例如,如果他们是邻居、同村成员、学校同学,甚至是特定行业内的公司,则可能会违反这一假设。在这种情况下,决策可能是相互关联的,因此相互依赖而不是独立,这似乎是合理的。允许这种相互作用会使推理变得复杂并且需要专门的处理。目前流行的允许相互依赖的方法称为集群依赖,它假设观察结果被分组为“集群”(例如学校)。我们将在 4.21 节中更详细地讨论聚类。
4.3 样本平均值
我们从拦截模型最简单的设置开始
\[ \begin{aligned} Y &=\mu+e \\ \mathbb{E}[e] &=0 . \end{aligned} \]
这相当于 \(k=1\) 和 \(X=1\) 的回归模型。在截距模型中,\(\mu=\mathbb{E}[Y]\) 是 \(Y\) 的期望。 (参见练习 2.15。)最小二乘估计量 \(\widehat{\mu}=\bar{Y}\) 等于样本均值,如方程 (3.8) 所示。
我们现在计算估计器 \(\bar{Y}\) 的期望和方差。由于样本均值是观测值的线性函数,因此其期望值很容易计算
\[ \mathbb{E}[\bar{Y}]=\mathbb{E}\left[\frac{1}{n} \sum_{i=1}^{n} Y_{i}\right]=\frac{1}{n} \sum_{i=1}^{n} \mathbb{E}\left[Y_{i}\right]=\mu . \]
这表明最小二乘估计量的期望值(样本均值)等于投影系数(总体期望)。具有其期望等于其估计参数的属性的估计器称为无偏估计器。
定义 \(4.1\) 如果 \(\mathbb{E}[\widehat{\theta}]=\theta\),则 \(\theta\) 的估计器 \(\widehat{\theta}\) 是无偏的
接下来我们计算假设 4.1 下估计量 \(\bar{Y}\) 的方差。进行替换 \(Y_{i}=\mu+e_{i}\) 我们发现
\[ \bar{Y}-\mu=\frac{1}{n} \sum_{i=1}^{n} e_{i} . \]
然后
\[ \begin{aligned} \operatorname{var}[\bar{Y}] &=\mathbb{E}\left[(\bar{Y}-\mu)^{2}\right] \\ &=\mathbb{E}\left[\left(\frac{1}{n} \sum_{i=1}^{n} e_{i}\right)\left(\frac{1}{n} \sum_{j=1}^{n} e_{j}\right)\right] \\ &=\frac{1}{n^{2}} \sum_{i=1}^{n} \sum_{j=1}^{n} \mathbb{E}\left[e_{i} e_{j}\right] \\ &=\frac{1}{n^{2}} \sum_{i=1}^{n} \sigma^{2} \\ &=\frac{1}{n} \sigma^{2} . \end{aligned} \]
倒数第二个不等式是因为由于独立性,\(\mathbb{E}\left[e_{i} e_{j}\right]=\sigma^{2}\) 对应于 \(i=j\),而 \(\mathbb{E}\left[e_{i} e_{j}\right]=0\) 对应于 \(i \neq j\)。
我们已经证明了\(\operatorname{var}[\bar{Y}]=\frac{1}{n} \sigma^{2}\)。这是样本均值方差的常见公式。
4.4 线性回归模型
我们现在考虑线性回归模型。在本章中,我们保持以下内容。
假设4.2 线性回归模型 变量\((Y, X)\)满足线性回归方程
\[ \begin{aligned} Y &=X^{\prime} \beta+e \\ \mathbb{E}[e \mid X] &=0 . \end{aligned} \]
变量具有有限的二阶矩
\[ \begin{aligned} &\mathbb{E}\left[Y^{2}\right]<\infty \\ &\mathbb{E}\|X\|^{2}<\infty \end{aligned} \]
和可逆设计矩阵
\[ \boldsymbol{Q}_{X X}=\mathbb{E}\left[X X^{\prime}\right]>0 . \]
我们将考虑条件方差 \(\mathbb{E}\left[e^{2} \mid X\right]=\sigma^{2}(X)\) 不受限制的异方差回归的一般情况,以及条件方差恒定的同方差回归的特殊情况。在后一种情况下,我们添加以下假设。
假设 4.3 同方差线性回归模型 除了假设 \(4.2\)
\[ \mathbb{E}\left[e^{2} \mid X\right]=\sigma^{2}(X)=\sigma^{2} \]
独立于 \(X\)。
4.5 最小二乘估计器的期望
在本节中,我们将证明 OLS 估计量在线性回归模型中是无偏的。该计算可以使用求和符号或矩阵符号来完成。我们将同时使用两者。
首先采用求和符号。观察(4.1)-(4.2)下的情况
\[ \mathbb{E}\left[Y_{i} \mid X_{1}, \ldots, X_{n}\right]=\mathbb{E}\left[Y_{i} \mid X_{i}\right]=X_{i}^{\prime} \beta . \]
第一个等式指出,给定 \(\left\{X_{1}, \ldots, X_{n}\right\}\) 时,\(Y_{i}\) 的条件期望仅取决于 \(X_{i}\),因为 \(i\) 之间的观察结果是独立的。第二个等式是线性条件期望的假设。使用定义(3.11)、条件定理(定理 2.3)、期望的线性度(4.4)和矩阵逆的性质,
\[ \begin{aligned} \mathbb{E}\left[\widehat{\beta} \mid X_{1}, \ldots, X_{n}\right] &=\mathbb{E}\left[\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} Y_{i}\right) \mid X_{1}, \ldots, X_{n}\right] \\ &=\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime}\right)^{-1} \mathbb{E}\left[\left(\sum_{i=1}^{n} X_{i} Y_{i}\right) \mid X_{1}, \ldots, X_{n}\right] \\ &=\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime}\right)^{-1} \sum_{i=1}^{n} \mathbb{E}\left[X_{i} Y_{i} \mid X_{1}, \ldots, X_{n}\right] \\ &=\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime}\right)^{-1} \sum_{i=1}^{n} X_{i} \mathbb{E}\left[Y_{i} \mid X_{i}\right] \\ &=\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime}\right)^{-1} \sum_{i=1}^{n} X_{i} X_{i}^{\prime} \beta \\ &=\beta . \end{aligned} \]
现在让我们使用矩阵表示法显示相同的结果。 (4.4) 意味着
\[ \mathbb{E}[\boldsymbol{Y} \mid \boldsymbol{X}]=\left(\begin{array}{c} \vdots \\ \mathbb{E}\left[Y_{i} \mid \boldsymbol{X}\right] \\ \vdots \end{array}\right)=\left(\begin{array}{c} \vdots \\ X_{i}^{\prime} \beta \\ \vdots \end{array}\right)=\boldsymbol{X} \beta . \]
相似地
\[ \mathbb{E}[\boldsymbol{e} \mid \boldsymbol{X}]=\left(\begin{array}{c} \vdots \\ \mathbb{E}\left[e_{i} \mid \boldsymbol{X}\right] \\ \vdots \end{array}\right)=\left(\begin{array}{c} \vdots \\ \mathbb{E}\left[e_{i} \mid X_{i}\right] \\ \vdots \end{array}\right)=0 . \]
使用 \(\widehat{\beta}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{Y}\right)\)、条件定理、期望线性 (4.5) 以及矩阵逆矩阵的属性,
\[ \begin{aligned} \mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}] &=\mathbb{E}\left[\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{Y} \mid \boldsymbol{X}\right] \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \mathbb{E}[\boldsymbol{Y} \mid \boldsymbol{X}] \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{X} \beta \\ &=\beta . \end{aligned} \]
冒着繁琐推导的风险,计算相同结果的另一种方法如下。将\(\boldsymbol{Y}=\boldsymbol{X} \beta+\boldsymbol{e}\)代入\(\widehat{\beta}\)的公式中,得到
\[ \begin{aligned} \widehat{\beta} &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime}(\boldsymbol{X} \beta+\boldsymbol{e})\right) \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{X} \beta+\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{e}\right) \\ &=\beta+\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{e} . \end{aligned} \]
这是估计器 \(\widehat{\beta}\) 到真实参数 \(\beta\) 和随机分量 \(\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{e}\) 的有用线性分解。再次,我们可以计算出
\[ \begin{aligned} \mathbb{E}[\widehat{\beta}-\beta \mid \boldsymbol{X}] &=\mathbb{E}\left[\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{e} \mid \boldsymbol{X}\right] \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \mathbb{E}[\boldsymbol{e} \mid \boldsymbol{X}]=0 . \end{aligned} \]
无论采用哪种方法,我们都已经证明了\(\mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]=\beta\)。我们已经证明了以下定理。
定理4.1 最小二乘估计器的期望 在具有独立同分布的线性回归模型(假设 4.2)中抽样(假设4.1)
\[ \mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]=\beta . \]
方程 (4.7) 表示估计器 \(\widehat{\beta}\) 对于 \(\beta\) 是无偏的,以 \(\boldsymbol{X}\) 为条件。这意味着 \(\widehat{\beta}\) 的条件分布以 \(\beta\) 为中心。 “以 \(X\) 为条件”意味着分布对于回归矩阵 \(\boldsymbol{X}\) 的任何实现都是无偏的。在条件模型中,我们简单地将其称为“\(" \widehat{\beta}\) 对于 \(\beta\) 是无偏的”。
值得一提的是,定理 4.1 以及本章中的所有有限样本结果都隐含假设 \(\boldsymbol{X}^{\prime} \boldsymbol{X}\) 是概率为 1 的满秩。
4.6 最小二乘方差估计器
在本节中,我们计算 OLS 估计量的条件方差。
对于任何 \(r \times 1\) 随机向量 \(Z\) 定义 \(r \times r\) 协方差矩阵
\[ \operatorname{var}[Z]=\mathbb{E}\left[(Z-\mathbb{E}[Z])(Z-\mathbb{E}[Z])^{\prime}\right]=\mathbb{E}\left[Z Z^{\prime}\right]-(\mathbb{E}[Z])(\mathbb{E}[Z])^{\prime} \]
并为任意对 \((Z, X)\) 定义条件协方差矩阵
\[ \operatorname{var}[Z \mid X]=\mathbb{E}\left[(Z-\mathbb{E}[Z \mid X])(Z-\mathbb{E}[Z \mid X])^{\prime} \mid X\right] . \]
我们将 \(\boldsymbol{V}_{\widehat{\beta}} \stackrel{\text { def }}{=} \operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]\) 定义为回归系数估计量的条件协方差矩阵。我们现在推导出它的形式。
\(n \times 1\) 回归误差 \(\boldsymbol{e}\) 的条件协方差矩阵是 \(n \times n\) 矩阵
\[ \operatorname{var}[\boldsymbol{e} \mid \boldsymbol{X}]=\mathbb{E}\left[\boldsymbol{e} \boldsymbol{e}^{\prime} \mid \boldsymbol{X}\right] \stackrel{\text { def }}{=} \boldsymbol{D} . \]
\(\boldsymbol{D}\) 的 \(i^{t h}\) 对角线元素是
\[ \mathbb{E}\left[e_{i}^{2} \mid \boldsymbol{X}\right]=\mathbb{E}\left[e_{i}^{2} \mid X_{i}\right]=\sigma_{i}^{2} \]
而 \(\boldsymbol{D}\) 的 \(i j^{t h}\) 非对角线元素是
\[ \mathbb{E}\left[e_{i} e_{j} \mid \boldsymbol{X}\right]=\mathbb{E}\left(e_{i} \mid X_{i}\right) \mathbb{E}\left[e_{j} \mid X_{j}\right]=0 \]
其中第一个等式使用观察的独立性(假设 4.1),第二个等式是(4.2)。因此 \(\boldsymbol{D}\) 是一个对角矩阵,其中 \(i^{t h}\) 对角元素为 \(\sigma_{i}^{2}\):
\[ \boldsymbol{D}=\operatorname{diag}\left(\sigma_{1}^{2}, \ldots, \sigma_{n}^{2}\right)=\left(\begin{array}{cccc} \sigma_{1}^{2} & 0 & \cdots & 0 \\ 0 & \sigma_{2}^{2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \sigma_{n}^{2} \end{array}\right) \]
在线性同方差回归模型 (4.3) 的特殊情况下,则 \(\mathbb{E}\left[e_{i}^{2} \mid X_{i}\right]=\sigma_{i}^{2}=\sigma^{2}\) 和我们的简化 \(\boldsymbol{D}=\boldsymbol{I}_{n} \sigma^{2}\) 。然而,一般来说,\(\boldsymbol{D}\) 不一定采用这种简化形式。
对于任意 \(n \times r\) 矩阵 \(\boldsymbol{A}=\boldsymbol{A}(\boldsymbol{X})\),
\[ \operatorname{var}\left[\boldsymbol{A}^{\prime} \boldsymbol{Y} \mid \boldsymbol{X}\right]=\operatorname{var}\left[\boldsymbol{A}^{\prime} \boldsymbol{e} \mid \boldsymbol{X}\right]=\boldsymbol{A}^{\prime} \boldsymbol{D} \boldsymbol{A} . \]
特别是,我们可以写 \(\widehat{\beta}=\boldsymbol{A}^{\prime} \boldsymbol{Y}\) where \(\boldsymbol{A}=\boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\) ,因此
\[ \boldsymbol{V}_{\widehat{\beta}}=\operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]=\boldsymbol{A}^{\prime} \boldsymbol{D} \boldsymbol{A}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \]
值得注意的是
\[ \boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}=\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \sigma_{i}^{2}, \]
\(\boldsymbol{X}^{\prime} \boldsymbol{X}\) 的加权版本。
在线性同方差回归模型的特殊情况下,\(\boldsymbol{D}=\boldsymbol{I}_{n} \sigma^{2}\),因此\(\boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}=\boldsymbol{X}^{\prime} \boldsymbol{X} \sigma^{2}\),协方差矩阵简化为\(\boldsymbol{V}_{\widehat{\beta}}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2}\)。
定理4.2最小二乘方差估计器 在具有独立同分布的线性回归模型(假设 4.2)中抽样(假设4.1)
\[ \boldsymbol{V}_{\widehat{\beta}}=\operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \]
其中 \(\boldsymbol{D}\) 在 (4.8) 中定义。另外,如果误差是同方差的(假设 4.3),则 (4.10) 简化为 \(\boldsymbol{V}_{\widehat{\beta}}=\sigma^{2}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\)。
4.7 无条件时刻
前面的部分导出了最小二乘估计量的条件期望和方差的形式,其中我们以回归矩阵 \(\boldsymbol{X}\) 为条件。无条件期望和方差又如何呢?
事实上,\(\widehat{\beta}\) 是否具有有限的期望或方差并不明显。以没有截距的单个虚拟变量回归器 \(D_{i}\) 为例。假设\(\mathbb{P}\left[D_{i}=1\right]=p<1\)。然后
\[ \widehat{\beta}=\frac{\sum_{i=1}^{n} D_{i} Y_{i}}{\sum_{i=1}^{n} D_{i}} \]
如果 \(\sum_{i=1}^{n} D_{i}>0\) 定义良好。然而,\(\mathbb{P}\left[\sum_{i=1}^{n} D_{i}=0\right]=(1-p)^{n}>0\)。这意味着 \(\widehat{\beta}\) 不存在的概率为正(但很小)。因此 \(\widehat{\beta}\) 没有有限矩!我们在实践中忽略了这种复杂性,但它确实给理论带来了难题。只要存在离散回归量,就会出现这种存在问题。
当回归量具有连续分布时,可以避免这种困境。 Kinal (1980) 在正常回归量和误差的假设下获得了清晰的陈述。定理 4.3 Kinal (1980)
在具有 i.i.d. 的线性回归模型中抽样,如果此外 \((X, e)\) 具有联合正态分布,则对于任何 \(r, \mathbb{E}\|\widehat{\beta}\|^{r}<\infty\) 当且仅当 \(r<n-k+1\)。
这表明,当误差和回归量呈正态分布时,最小二乘估计器拥有直到 \(n-k\) 的所有矩,其中包括所有实际感兴趣的矩。正态性假设对该结果并不重要。关键是假设回归量是连续分布的。
迭代期望定律(定理 2.1)与定理 \(4.1\) 和 \(4.3\) 相结合,使我们能够推断出最小二乘估计量是无条件无偏的。在正态假设下,定理 \(4.3\) 允许我们应用迭代期望定律,因此使用定理 \(4.1\) 我们推断,如果 \(n>k\)
\[ \mathbb{E}[\widehat{\beta}]=\mathbb{E}[\mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]]=\beta . \]
因此 \(\widehat{\beta}\) 正如所断言的那样无条件无偏。
此外,如果 \(n-k>1\) 则 \(\mathbb{E}\|\widehat{\beta}\|^{2}<\infty\) 和 \(\widehat{\beta}\) 具有有限的无条件方差。使用定理 \(2.8\) 我们可以明确地计算出
\[ \operatorname{var}[\widehat{\beta}]=\mathbb{E}[\operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]]+\operatorname{var}[\mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]]=\mathbb{E}\left[\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\right] \]
第二个等式是因为 \(\mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]=\beta\) 的方差为零。在同方差的情况下,这简化为
\[ \operatorname{var}[\widehat{\beta}]=\sigma^{2} \mathbb{E}\left[\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\right] . \]
在这两种情况下,期望都不能通过矩阵逆,因为这是一个非线性函数。因此,除了说明它是条件方差的期望之外,无条件方差没有简单的表达式。
4.8 高斯-马尔可夫定理
高斯-马尔可夫定理是计量经济学理论中最著名的成果之一。它为最小二乘估计量提供了经典的论证,表明它是无偏估计量中方差最低的。
将同方差线性回归模型写为向量格式:
\[ \begin{aligned} \boldsymbol{Y} &=\boldsymbol{X} \beta+\boldsymbol{e} \\ \mathbb{E}[\boldsymbol{e} \mid \boldsymbol{X}] &=0 \\ \operatorname{var}[\boldsymbol{e} \mid \boldsymbol{X}] &=\boldsymbol{I}_{n} \sigma^{2} . \end{aligned} \]
在此模型中,我们知道最小二乘估计量对于 \(\beta\) 是无偏的,并且具有协方差矩阵 \(\sigma^{2}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\)。本节提出的问题是是否存在另一个具有较小协方差矩阵的无偏估计量 \(\widetilde{\beta}\)。
该定理的以下版本来自 B. E. Hansen (2021)。
定理4.4高斯-马尔可夫 采用同方差线性回归模型(4.11)-(4.13)。如果 \(\widetilde{\beta}\) 是 \(\beta\) 的无偏估计量,那么
\[ \operatorname{var}[\widetilde{\beta} \mid \boldsymbol{X}] \geq \sigma^{2}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \]
定理 \(4.4\) 在同方差假设下提供了无偏估计量协方差矩阵的下界。它表示没有无偏估计量的方差矩阵(在正定意义上)小于 \(\sigma^{2}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\)。由于 OLS 估计量的方差恰好等于该界限,这意味着没有无偏估计量的方差低于 OLS。因此,我们将 OLS 描述为无偏估计类中的有效方法。
这个定理 \(4.4\) 的最早版本是由卡尔·弗里德里希·高斯 (Carl Friedrich Gauss) 在 1823 年提出的。安德烈·安德烈耶维奇·马尔科夫 (Andreı̆ Andreevich Markov) 在 1912 年提供了该定理的教科书式处理,并阐明了无偏性的核心作用,而高斯只是隐含地假设了这一点。
他们的定理版本将注意力限制在 \(\beta\) 的线性估计量上,这些估计量可以写成 \(\widetilde{\beta}=\boldsymbol{A}^{\prime} \boldsymbol{Y}\),其中 \(\boldsymbol{A}=\boldsymbol{A}(\boldsymbol{X})\) 是回归量 \(\boldsymbol{X}\) 的 \(m \times n\) 函数。在这种情况下,线性意味着“\(\boldsymbol{Y}\) 中的线性”。这种限制简化了方差计算,但极大地限制了估计器的类别。该定理的这个经典版本引起了将 OLS 描述为最佳线性无偏估计器 (BLUE)。然而,如上所述的定理 \(4.4\) 表明 OLS 是最好的无偏估计量 (BUE)。
在线性估计器限制下的高斯-马尔可夫定理的推导很简单,所以我们现在提供这个演示。对于 \(\widetilde{\beta}=\boldsymbol{A}^{\prime} \boldsymbol{Y}\) 我们有
\[ \mathbb{E}[\widetilde{\beta} \mid \boldsymbol{X}]=\boldsymbol{A}^{\prime} \mathbb{E}[\boldsymbol{Y} \mid \boldsymbol{X}]=\boldsymbol{A}^{\prime} \boldsymbol{X} \beta, \]
第二个等式是因为 \(\mathbb{E}[\boldsymbol{Y} \mid \boldsymbol{X}]=\boldsymbol{X} \beta\)。那么当(且仅当)\(\boldsymbol{A}^{\prime} \boldsymbol{X}=\boldsymbol{I}_{k}\) 时,\(\widetilde{\beta}\) 对所有 \(\beta\) 都是无偏的。此外,我们在(4.9)中看到
\[ \operatorname{var}[\widetilde{\beta} \mid \boldsymbol{X}]=\operatorname{var}\left[\boldsymbol{A}^{\prime} \boldsymbol{Y} \mid \boldsymbol{X}\right]=\boldsymbol{A}^{\prime} \boldsymbol{D} \boldsymbol{A}=\boldsymbol{A}^{\prime} \boldsymbol{A} \boldsymbol{\sigma}^{2} \]
最后一个等式使用同方差假设 (4.13)。为了建立定理,我们需要证明对于任何这样的矩阵 \(\boldsymbol{A}\),
\[ \boldsymbol{A}^{\prime} \boldsymbol{A} \geq\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \text {. } \]
设置 \(\boldsymbol{C}=\boldsymbol{A}-\boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\)。请注意 \(\boldsymbol{X}^{\prime} \boldsymbol{C}=0\)。我们计算出
\[ \begin{aligned} \boldsymbol{A}^{\prime} \boldsymbol{A}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} &=\left(\boldsymbol{C}+\boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\right)^{\prime}\left(\boldsymbol{C}+\boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\right)-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\boldsymbol{C}^{\prime} \boldsymbol{C}+\boldsymbol{C}^{\prime} \boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}+\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{C} \\ &+\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\boldsymbol{C}^{\prime} \boldsymbol{C} \geq 0 \end{aligned} \]
最终的不等式表明矩阵 \(\boldsymbol{C}^{\prime} \boldsymbol{C}\) 是正半定的,这是二次形式的属性(参见附录 A.10)。我们已按要求显示了(4.14)。
上述推导施加了这样的限制:估计器 \(\widetilde{\beta}\) 在 \(\boldsymbol{Y}\) 中是线性的。一般情况下定理 \(4.4\) 的证明要先进得多。在这里,我们为感兴趣的读者提供了该论证的简化草图,并在第 4.24 节中提供了完整的证明。为简单起见,将回归量 \(X\) 视为固定,并假设 \(Y\) 的密度为 \(f(y)\),且支持度为 \(\mathscr{Y}\)。不失一般性,假设真实系数等于 \(\beta_{0}=0\)。
由于 \(Y\) 具有有限的支持 \(\mathscr{Y}\),因此存在一个集合 \(B \subset \mathbb{R}^{m}\),使得 \(\left|y X^{\prime} \beta / \sigma^{2}\right|<1\) 对于所有 \(\beta \in B\) 和 \(y \in \mathscr{Y}\)。对于 \(\beta\) 的此类值,定义辅助密度函数
\[ f_{\beta}(y)=f(y)\left(1+y X^{\prime} \beta / \sigma^{2}\right) . \]
在假设下,\(0 \leq f_{\beta}(y) \leq 2 f(y), f_{\beta}(y)\) 具有支持 \(\mathscr{Y}\) 和 \(\int_{\mathscr{Y}} f_{\beta}(y) d y=1\)。要查看后者,请观察标准化 \(\beta_{0}=0\) 下的 \(\int_{\mathscr{Y}} y f(y) d y=X^{\prime} \beta_{0}=0\),因此
\[ \int_{\mathscr{Y}} f_{\beta}(y) d y=\int_{\mathscr{Y}} f(y) d y+\int_{\mathscr{Y}} f(y) y d y X^{\prime} \beta / \sigma^{2}=1 \]
因为\(\int_{\mathscr{Y}} f(y) d y=1\)。因此 \(f_{\beta}\) 是密度函数的参数族。在 \(\beta_{0}\) 上进行评估,我们看到 \(f_{0}=f\),这意味着 \(f_{\beta}\) 是一个正确指定的参数族,具有真实的参数值 \(\beta_{0}=0\)。
为了说明这一点,以 \(X=1\) 为例。图 4.1 显示了 \([-1,1]\) 上的密度 \(f(y)=(3 / 4)\left(1-y^{2}\right)\) 和辅助密度 \(f_{\beta}(y)=f(y)(1+y)\) 的示例。我们可以看到辅助密度是原始密度 \(f(y)\) 的倾斜版本。
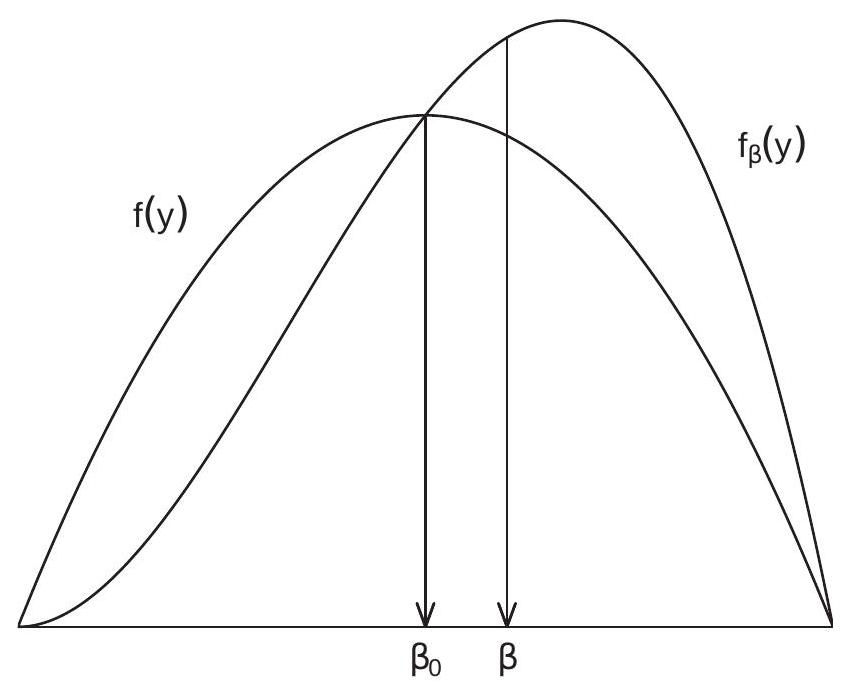
图 4.1:原始密度和辅助密度
令 \(\mathbb{E}_{\beta}\) 表示对辅助分布的期望。由于 \(\int_{\mathscr{Y}} y f(y) d y=0\) 和 \(\int_{\mathscr{Y}} y^{2} f(y) d y=\) \(\sigma^{2}\),我们发现
\[ \mathbb{E}_{\beta}[Y]=\int_{\mathscr{Y}} y f_{\beta}(y) d y=\int_{\mathscr{Y}} y f(y) d y+\int_{\mathscr{Y}} y^{2} f(y) d y X^{\prime} \beta / \sigma^{2}=X^{\prime} \beta . \]
这表明\(f_{\beta}\)是一个回归模型,回归系数为\(\beta\)。
在图 4.1 中,两个密度的平均值由指向 \(\mathrm{x}\) 轴的箭头指示。在这个例子中,我们可以看到辅助密度如何具有更大的期望值,因为密度已向右倾斜。
\(\beta \in B\) 上的参数族 \(f_{\beta}\) 具有以下属性:其期望为 \(X^{\prime} \beta\),其方差是有限的,真实值 \(\beta_{0}\) 位于 \(B\) 的内部,且分布的支持度不存在取决于 \(\beta\)。
使用 \(Y_{i}=e_{i}\) 的事实,观测的辅助密度函数的似然得分为
\[ S_{i}=\left.\frac{\partial}{\partial \beta}\left(\log f_{\beta}\left(Y_{i}\right)\right)\right|_{\beta=0}=\left.\frac{\partial}{\partial \beta}\left(\log f\left(e_{i}\right)+\log \left(1+e_{i} X_{i}^{\prime} \beta / \sigma^{2}\right)\right)\right|_{\beta=0}=X_{i} e_{i} / \sigma^{2} . \]
因此信息矩阵为
\[ \mathscr{I}=\sum_{i=1}^{n} \mathbb{E}\left[S_{i} S_{i}^{\prime}\right]=\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \mathbb{E}\left[e_{i}^{2}\right] / \sigma^{4}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right) / \sigma^{2} . \]
根据假设,\(\widetilde{\beta}\) 是无偏的。 Cramér-Rao 下界指出
\[ \operatorname{var}[\widetilde{\beta}] \geq \mathscr{I}^{-1}=\sigma^{2}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \]
这是方差下界,完成了定理 4.4 的证明。
上面的论证是相当棘手的。其核心是模型 \(f_{\beta}\) 是所有线性回归模型集的子模型。任何常规参数子模型上的 Cramér-Rao 界是任何无偏估计量方差的下界。这意味着 \(f_{\beta}\) 上的 Cramér-Rao 界限是回归系数无偏估计的下限。模型 \(f_{\beta}\) 是明智选择的,使其 Cramér-Rao 界等于最小二乘估计量的方差,这足以建立界。
4.9 广义最小二乘法
采用矩阵格式的线性回归模型
\[ \boldsymbol{Y}=\boldsymbol{X} \beta+\boldsymbol{e} . \]
考虑一种普遍情况,其中观测误差可能是相关的和/或异方差的。具体来说,假设
\[ \begin{gathered} \mathbb{E}[\boldsymbol{e} \mid \boldsymbol{X}]=0 \\ \operatorname{var}[\boldsymbol{e} \mid \boldsymbol{X}]=\Sigma \sigma^{2} \end{gathered} \]
对于某些 \(n \times n\) 矩阵 \(\Sigma>0\),可能是 \(\boldsymbol{X}\) 的函数,以及某些标量 \(\sigma^{2}\)。这包括独立采样框架,其中 \(\Sigma\) 是对角矩阵,但也允许非对角协方差矩阵。作为缩放协方差矩阵,\(\Sigma\) 必然是对称且半正定的。
在这些假设下,通过类似于前面部分的参数,我们可以计算 OLS 估计量的期望和方差:
\[ \begin{gathered} \mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]=\beta \\ \operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]=\sigma^{2}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \Sigma \boldsymbol{X}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \end{gathered} \]
(参见练习 4.5)。
Aitken (1935) 建立了高斯-马尔可夫定理的推广。以下声明来自 B. E. Hansen (2021)。定理4.5 取线性回归模型(4.17)-(4.19)。如果 \(\widetilde{\beta}\) 是 \(\beta\) 的无偏估计量,那么
\[ \operatorname{var}[\widetilde{\beta} \mid \boldsymbol{X}] \geq \sigma^{2}\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1} \]
我们将证明推迟到第 4.24 节。另请参见练习 4.6。
定理 \(4.5\) 提供了无偏估计量协方差矩阵的下界。定理 \(4.4\) 是特殊情况 \(\Sigma=\boldsymbol{I}_{n}\)。
当 \(\Sigma\) 已知时,Aitken (1935) 构建了一个达到定理 4.5 中下界的估计器。采用线性模型 (4.17) 并预乘以 \(\Sigma^{-1 / 2}\)。这会产生方程 \(\tilde{\boldsymbol{Y}}=\widetilde{\boldsymbol{X}} \beta+\widetilde{\boldsymbol{e}}\),其中 \(\tilde{\boldsymbol{Y}}=\Sigma^{-1 / 2} \boldsymbol{Y}, \widetilde{\boldsymbol{X}}=\Sigma^{-1 / 2} \boldsymbol{X}\) 和 \(\widetilde{\boldsymbol{e}}=\Sigma^{-1 / 2} \boldsymbol{e}\)。考虑此方程中 \(\beta\) 的 OLS 估计。
\[ \begin{aligned} \widetilde{\beta}_{\text {gls }} &=\left(\widetilde{\boldsymbol{X}}^{\prime} \widetilde{\boldsymbol{X}}\right)^{-1} \widetilde{\boldsymbol{X}}^{\prime} \widetilde{\boldsymbol{Y}} \\ &=\left(\left(\Sigma^{-1 / 2} \boldsymbol{X}\right)^{\prime}\left(\Sigma^{-1 / 2} \boldsymbol{X}\right)\right)^{-1}\left(\Sigma^{-1 / 2} \boldsymbol{X}\right)^{\prime}\left(\Sigma^{-1 / 2} \boldsymbol{Y}\right) \\ &=\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{Y} . \end{aligned} \]
这称为 \(\beta\) 的广义最小二乘法 (GLS) 估计器。
你可以计算一下
\[ \begin{gathered} \mathbb{E}\left[\widetilde{\beta}_{\text {gls }} \mid \boldsymbol{X}\right]=\beta \\ \operatorname{var}\left[\widetilde{\beta}_{\text {gls }} \mid \boldsymbol{X}\right]=\sigma^{2}\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1} . \end{gathered} \]
这表明 GLS 估计量是无偏的,并且协方差矩阵等于定理 4.5 的下界。这表明下限是尖锐的。因此,GLS 在无偏估计类中是有效的。
在具有独立观测值和已知条件方差的线性回归模型中,因此 \(\Sigma=\boldsymbol{D}=\operatorname{diag}\left(\sigma_{1}^{2}, \ldots, \sigma_{n}^{2}\right)\),GLS 估计量采用以下形式
\[ \begin{aligned} \widetilde{\beta}_{\mathrm{gls}} &=\left(\boldsymbol{X}^{\prime} \boldsymbol{D}^{-1} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{D}^{-1} \boldsymbol{Y} \\ &=\left(\sum_{i=1}^{n} \sigma_{i}^{-2} X_{i} X_{i}^{\prime}\right)^{-1}\left(\sum_{i=1}^{n} \sigma_{i}^{-2} X_{i} Y_{i}\right) . \end{aligned} \]
在本例中,对于 \(i=1, \ldots n\),假设 \(\Sigma>0\) 简化为 \(\sigma_{i}^{2}>0\)。
在大多数设置中,矩阵 \(\Sigma\) 是未知的,因此 GLS 估计器不可行。然而,GLS 估计器的形式通过用合适的估计器替换 \(\Sigma\) 有效地激发了可行的版本。
4.10 残差
线性回归模型中残差 \(\widehat{e}_{i}=Y_{i}-X_{i}^{\prime} \widehat{\beta}\) 和预测误差 \(\widetilde{e}_{i}=Y_{i}-X_{i}^{\prime} \widehat{\beta}_{(-i)}\) 有哪些属性?
回想一下(3.24),我们可以将残差用向量表示法写为 \(\widehat{\boldsymbol{e}}=\boldsymbol{M} \boldsymbol{e}\),其中 \(\boldsymbol{M}=\boldsymbol{I}_{n}-\) \(\boldsymbol{X}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime}\) 是正交投影矩阵。使用条件期望的属性
\[ \mathbb{E}[\widehat{\boldsymbol{e}} \mid \boldsymbol{X}]=\mathbb{E}[\boldsymbol{M e} \mid \boldsymbol{X}]=\boldsymbol{M} \mathbb{E}[\boldsymbol{e} \mid \boldsymbol{X}]=0 \]
和
\[ \operatorname{var}[\widehat{\boldsymbol{e}} \mid \boldsymbol{X}]=\operatorname{var}[\boldsymbol{M} \boldsymbol{e} \mid \boldsymbol{X}]=\boldsymbol{M} \operatorname{var}[\boldsymbol{e} \mid \boldsymbol{X}] \boldsymbol{M}=\boldsymbol{M D} \boldsymbol{M} \]
其中 \(\boldsymbol{D}\) 在 (4.8) 中定义。
我们可以在条件同方差的假设下简化这个表达式
\[ \mathbb{E}\left[e^{2} \mid X\right]=\sigma^{2} . \]
在这种情况下(4.25)简化为
\[ \operatorname{var}[\widehat{\boldsymbol{e}} \mid \boldsymbol{X}]=\boldsymbol{M} \sigma^{2} . \]
特别是,对于单个观测值 \(i\),我们可以通过采用 (4.26) 的 \(i^{t h}\) 对角元素来找到 \(\widehat{e}_{i}\) 的方差。由于 \(M\) 的 \(i^{t h}\) 对角线元素是 (3.40) 中定义的 \(1-h_{i i}\),我们得到
\[ \operatorname{var}\left[\widehat{e}_{i} \mid \boldsymbol{X}\right]=\mathbb{E}\left[\widehat{e}_{i}^{2} \mid \boldsymbol{X}\right]=\left(1-h_{i i}\right) \sigma^{2} . \]
由于此方差是 \(h_{i i}\) 的函数,因此 \(X_{i}\) 的残差 \(\widehat{e}_{i}\) 也是异方差的,即使误差 \(e_{i}\) 是同方差的。还要注意,(4.27) 意味着 \(\widehat{e}_{i}^{2}\) 是 \(\sigma^{2}\) 的有偏估计量。
类似地,回想一下 (3.45),预测误差 \(\widetilde{e}_{i}=\left(1-h_{i i}\right)^{-1} \widehat{e}_{i}\) 可以用向量表示法写为 \(\widetilde{\boldsymbol{e}}=\boldsymbol{M}^{*} \widehat{\boldsymbol{e}}\),其中 \(\boldsymbol{M}^{*}\) 是一个对角矩阵,其中 \(i^{t h}\) 对角元素 \(\left(1-h_{i i}\right)^{-1}\)。因此\(\widetilde{\boldsymbol{e}}=\boldsymbol{M}^{*} \boldsymbol{M} \boldsymbol{e}\)。我们可以计算出
\[ \mathbb{E}[\tilde{\boldsymbol{e}} \mid \boldsymbol{X}]=\boldsymbol{M}^{*} \boldsymbol{M} \mathbb{E}[\boldsymbol{e} \mid \boldsymbol{X}]=0 \]
和
\[ \operatorname{var}[\widetilde{\boldsymbol{e}} \mid \boldsymbol{X}]=\boldsymbol{M}^{*} \boldsymbol{M} \operatorname{var}[\boldsymbol{e} \mid \boldsymbol{X}] \boldsymbol{M} \boldsymbol{M}^{*}=\boldsymbol{M}^{*} \boldsymbol{M D} \boldsymbol{M} \boldsymbol{M}^{*} \]
在同方差下简化为
\[ \operatorname{var}[\widetilde{\boldsymbol{e}} \mid \boldsymbol{X}]=\boldsymbol{M}^{*} \boldsymbol{M} \boldsymbol{M} \boldsymbol{M}^{*} \sigma^{2}=\boldsymbol{M}^{*} \boldsymbol{M} \boldsymbol{M}^{*} \sigma^{2} . \]
\(i^{t h}\) 预测误差的方差为
\[ \begin{aligned} \operatorname{var}\left[\widetilde{e}_{i} \mid \boldsymbol{X}\right] &=\mathbb{E}\left[\widetilde{e}_{i}^{2} \mid \boldsymbol{X}\right] \\ &=\left(1-h_{i i}\right)^{-1}\left(1-h_{i i}\right)\left(1-h_{i i}\right)^{-1} \sigma^{2} \\ &=\left(1-h_{i i}\right)^{-1} \sigma^{2} . \end{aligned} \]
可以通过重新缩放获得具有恒定条件方差的残差。标准化残差为
\[ \bar{e}_{i}=\left(1-h_{i i}\right)^{-1 / 2} \widehat{e}_{i}, \]
并用向量表示法
\[ \overline{\boldsymbol{e}}=\left(\bar{e}_{1}, \ldots, \bar{e}_{n}\right)^{\prime}=\boldsymbol{M}^{* 1 / 2} \boldsymbol{M e} . \]
由上述计算可知,在同方差条件下,
\[ \operatorname{var}[\overline{\boldsymbol{e}} \mid \boldsymbol{X}]=\boldsymbol{M}^{* 1 / 2} \boldsymbol{M} \boldsymbol{M}^{* 1 / 2} \sigma^{2} \]
和
\[ \operatorname{var}\left[\bar{e}_{i} \mid \boldsymbol{X}\right]=\mathbb{E}\left[\bar{e}_{i}^{2} \mid \boldsymbol{X}\right]=\sigma^{2} \]
因此,当原始误差同方差时,这些标准化残差与原始误差具有相同的偏差和方差。
4.11 误差方差的估计
即使在异方差回归或投影模型中,误差方差 \(\sigma^{2}=\mathbb{E}\left[e^{2}\right]\) 也可以是感兴趣的参数。 \(\sigma^{2}\) 测量回归中“无法解释”部分的变化。其矩估计器(MME)方法是残差平方的样本平均值:
\[ \widehat{\sigma}^{2}=\frac{1}{n} \sum_{i=1}^{n} \widehat{e}_{i}^{2} . \]
在线性回归模型中,我们可以计算\(\widehat{\sigma}^{2}\)的期望。从 (3.28) 和迹算子的性质观察到
\[ \widehat{\sigma}^{2}=\frac{1}{n} \boldsymbol{e}^{\prime} \boldsymbol{M} \boldsymbol{e}=\frac{1}{n} \operatorname{tr}\left(\boldsymbol{e}^{\prime} \boldsymbol{M} \boldsymbol{e}\right)=\frac{1}{n} \operatorname{tr}\left(\boldsymbol{M e}^{\prime}\right) . \]
然后
\[ \begin{aligned} \mathbb{E}\left[\widehat{\sigma}^{2} \mid \boldsymbol{X}\right] &=\frac{1}{n} \operatorname{tr}\left(\mathbb{E}\left[\boldsymbol{M e e}^{\prime} \mid \boldsymbol{X}\right]\right) \\ &=\frac{1}{n} \operatorname{tr}\left(\boldsymbol{M}\left[\boldsymbol{e} \boldsymbol{e}^{\prime} \mid \boldsymbol{X}\right]\right) \\ &=\frac{1}{n} \operatorname{tr}(\boldsymbol{M D}) \\ &=\frac{1}{n} \sum_{i=1}^{n}\left(1-h_{i i}\right) \sigma_{i}^{2} \end{aligned} \]
最终等式成立,因为迹是 \(\boldsymbol{M D}\) 对角线元素的总和,并且因为 \(\boldsymbol{D}\) 是对角线,所以 \(M D\) 的对角线元素是 \(M\) 和 \(\boldsymbol{D}\) 对角线元素的乘积,它们是分别为 \(1-h_{i i}\) 和 \(\sigma_{i}^{2}\)。
添加条件同方差假设 \(\mathbb{E}\left[e^{2} \mid X\right]=\sigma^{2}\) 使得 \(\boldsymbol{D}=\boldsymbol{I}_{n} \sigma^{2}\),则 (4.30) 简化为
\[ \mathbb{E}\left[\widehat{\sigma}^{2} \mid \boldsymbol{X}\right]=\frac{1}{n} \operatorname{tr}\left(\boldsymbol{M} \sigma^{2}\right)=\sigma^{2}\left(\frac{n-k}{n}\right) \]
最终等于(3.22)。此计算表明 \(\widehat{\sigma}^{2}\) 偏向于零。偏差的阶数取决于 \(k / n\),即估计系数数量与样本大小的比率。
另一种了解这一点的方法是使用(4.27)。注意
\[ \mathbb{E}\left[\widehat{\sigma}^{2} \mid \boldsymbol{X}\right]=\frac{1}{n} \sum_{i=1}^{n} \mathbb{E}\left[\widehat{e}_{i}^{2} \mid \boldsymbol{X}\right]=\frac{1}{n} \sum_{i=1}^{n}\left(1-h_{i i}\right) \sigma^{2}=\left(\frac{n-k}{n}\right) \sigma^{2} \]
最后一个等式使用定理 3.6。
由于偏差采用尺度形式,获得无偏估计量的经典方法是重新调整尺度。定义
\[ s^{2}=\frac{1}{n-k} \sum_{i=1}^{n} \widehat{e}_{i}^{2} . \]
通过上面的计算\(\mathbb{E}\left[s^{2} \mid \boldsymbol{X}\right]=\sigma^{2}\)和\(\mathbb{E}\left[s^{2}\right]=\sigma^{2}\)。因此,估计器 \(s^{2}\) 对于 \(\sigma^{2}\) 是无偏的。因此,\(s^{2}\) 被称为 \(\sigma^{2}\) 的偏差校正估计器,而在经验实践中,\(s^{2}\) 是 \(\sigma^{2}\) 使用最广泛的估计器。有趣的是,这并不是为 \(\sigma^{2}\) 构建无偏估计量的唯一方法。使用 (4.28) 中的标准化残差 \(\mathbb{E}\left[s^{2} \mid \boldsymbol{X}\right]=\sigma^{2}\) 构建的估计量为
\[ \bar{\sigma}^{2}=\frac{1}{n} \sum_{i=1}^{n} \bar{e}_{i}^{2}=\frac{1}{n} \sum_{i=1}^{n}\left(1-h_{i i}\right)^{-1} \widehat{e}_{i}^{2} . \]
你可以证明(参见练习 4.9)
\[ \mathbb{E}\left[\bar{\sigma}^{2} \mid \boldsymbol{X}\right]=\sigma^{2} \]
因此 \(\bar{\sigma}^{2}\) 对于 \(\sigma^{2}\) 是无偏的(在同方差线性回归模型中)。
当 \(k / n\) 很小时,估计器 \(\widehat{\sigma}^{2}, s^{2}\) 和 \(\bar{\sigma}^{2}\) 可能彼此相似。然而,如果 \(k / n\) 很大,那么 \(s^{2}\) 和 \(\bar{\sigma}^{2}\) 通常优于 \(\widehat{\sigma}^{2}\)。因此,最好在应用程序中使用偏差校正方差估计器之一。
4.12 均方预测误差
估计回归的一种用途是预测样本外。考虑样本外实现 \(\left(Y_{n+1}, X_{n+1}\right)\),其中观察到 \(X_{n+1}\),但未观察到 \(Y_{n+1}\)。给定系数估计器 \(\widehat{\beta}\),\(\mathbb{E}\left[Y_{n+1} \mid X_{n+1}\right]=X_{n+1}^{\prime} \beta\) 的标准点估计器是 \(\widetilde{Y}_{n+1}=X_{n+1}^{\prime} \widehat{\beta}\)。预测误差是实际值 \(Y_{n+1}\) 与点预测值 \(\widetilde{Y}_{n+1}\) 之间的差异。这是预测误差\(\widetilde{e}_{n+1}=Y_{n+1}-\widetilde{Y}_{n+1}\)。均方预测误差 (MSFE) 是其预期平方值 \(\left(Y_{n+1}, X_{n+1}\right)\)。在线性回归模型 \(\left(Y_{n+1}, X_{n+1}\right)\) 中,所以
\[ \operatorname{MSFE}_{n}=\mathbb{E}\left[e_{n+1}^{2}\right]-2 \mathbb{E}\left[e_{n+1} X_{n+1}^{\prime}(\widehat{\beta}-\beta)\right]+\mathbb{E}\left[X_{n+1}^{\prime}(\widehat{\beta}-\beta)(\widehat{\beta}-\beta)^{\prime} X_{n+1}\right] . \]
(4.33) 中的第一项是 \(\sigma^{2}\)。 (4.33) 中的第二项为零,因为 \(e_{n+1} X_{n+1}^{\prime}\) 独立于 \(\widehat{\beta}-\beta\) 并且两者均值为零。使用迹算子的属性,(4.33) 中的第三项是
\[ \begin{aligned} &\operatorname{tr}\left(\mathbb{E}\left[X_{n+1} X_{n+1}^{\prime}\right] \mathbb{E}\left[(\widehat{\beta}-\beta)(\widehat{\beta}-\beta)^{\prime}\right]\right) \\ &=\operatorname{tr}\left(\mathbb{E}\left[X_{n+1} X_{n+1}^{\prime}\right] \mathbb{E}\left[\mathbb{E}\left[(\widehat{\beta}-\beta)(\widehat{\beta}-\beta)^{\prime} \mid \boldsymbol{X}\right]\right]\right) \\ &=\operatorname{tr}\left(\mathbb{E}\left[X_{n+1} X_{n+1}^{\prime}\right] \mathbb{E}\left[\boldsymbol{V}_{\widehat{\beta}}\right]\right) \\ &=\mathbb{E}\left[\operatorname{tr}\left(\left(X_{n+1} X_{n+1}^{\prime}\right) \boldsymbol{V}_{\widehat{\beta}}\right)\right] \\ &=\mathbb{E}\left[X_{n+1}^{\prime} \boldsymbol{V}_{\widehat{\beta}} X_{n+1}\right] \end{aligned} \]
其中我们使用 \(X_{n+1}\) 独立于 \(\widehat{\beta}\) 的事实、定义 \(\boldsymbol{V}_{\widehat{\beta}}=\mathbb{E}\left[(\widehat{\beta}-\beta)(\widehat{\beta}-\beta)^{\prime} \mid \boldsymbol{X}\right]\) 以及 \(X_{n+1}\) 独立于 \(\boldsymbol{V}_{\widehat{\beta}}\) 的事实。因此
\[ \operatorname{MSFE}_{n}=\sigma^{2}+\mathbb{E}\left[X_{n+1}^{\prime} \boldsymbol{V}_{\widehat{\beta}} X_{n+1}\right] . \]
在条件同方差下,这简化为
\[ \operatorname{MSFE}_{n}=\sigma^{2}\left(1+\mathbb{E}\left[X_{n+1}^{\prime}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} X_{n+1}\right]\right) . \]
通过对预测误差平方求平均值获得 MSFE 的简单估计量 (3.46)
\[ \widetilde{\sigma}^{2}=\frac{1}{n} \sum_{i=1}^{n} \widetilde{e}_{i}^{2} \]
其中 \(\widetilde{e}_{i}=Y_{i}-X_{i}^{\prime} \widehat{\beta}_{(-i)}=\widehat{e}_{i}\left(1-h_{i i}\right)^{-1}\).确实,我们可以计算出
\[ \begin{aligned} \mathbb{E}\left[\widetilde{\sigma}^{2}\right] &=\mathbb{E}\left[\widetilde{e}_{i}^{2}\right] \\ &=\mathbb{E}\left[\left(e_{i}-X_{i}^{\prime}\left(\widehat{\beta}_{(-i)}-\beta\right)\right)^{2}\right] \\ &=\sigma^{2}+\mathbb{E}\left[X_{i}^{\prime}\left(\widehat{\beta}_{(-i)}-\beta\right)\left(\widehat{\beta}_{(-i)}-\beta\right)^{\prime} X_{i}\right] . \end{aligned} \]
通过与 (4.34) 类似的计算,我们发现
\[ \mathbb{E}\left[\widetilde{\sigma}^{2}\right]=\sigma^{2}+\mathbb{E}\left[X_{i}^{\prime} \boldsymbol{V}_{\widehat{\beta}_{(-i)}} X_{i}\right]=\operatorname{MSFE}_{n-1} . \]
这是基于大小为 \(n-1\) 而不是大小为 \(n\) 的样本的 MSFE。之所以会出现差异,是因为 \(i \leq n\) 的样本内预测误差 \(\widetilde{e}_{i}\) 是使用有效样本大小 \(n-1\) 计算的,而样本外预测误差 \(\widetilde{e}_{n+1}\) 是根据完整的 \(n\) 观察结果。除非 \(n\) 非常小,否则我们应该期望 \(\operatorname{MSFE}_{n-1}\) (基于 \(n-1\) 观测值的 MSFE)接近 \(n-1\) (基于 \(n-1\) 观测值的 MSFE)。因此 \(n-1\) 是 MSFE \(n-1\) 的合理估计量。
定理4.6 MSFE 在线性回归模型(假设 4.2)和 i.i.d.抽样(假设4.1)
\[ \operatorname{MSFE}_{n}=\mathbb{E}\left[\widetilde{e}_{n+1}^{2}\right]=\sigma^{2}+\mathbb{E}\left[X_{n+1}^{\prime} \boldsymbol{V}_{\widehat{\beta}} X_{n+1}\right] \]
其中 \(\boldsymbol{V}_{\widehat{\beta}}=\operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]\).此外,(3.46)中定义的\(\widetilde{\sigma}^{2}\)是\(\operatorname{MSFE}_{n-1}\)的无偏估计,因为\(\mathbb{E}\left[\widetilde{\sigma}^{2}\right]=\operatorname{MSFE}_{n-1}\)。
4.13 同方差下的协方差矩阵估计
为了进行推理,我们需要最小二乘估计器的协方差矩阵 \(\boldsymbol{V}_{\widehat{\beta}}\) 的估计器。在本节中,我们考虑同方差回归模型(假设 4.3)。
在同方差下,协方差矩阵采用简单形式
\[ \boldsymbol{V}_{\widehat{\beta}}^{0}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2} \]
其规模已知为 \(\sigma^{2}\)。在 \(4.11\) 节中,我们讨论了 \(\sigma^{2}\) 的三个估计器。最常用的选择是 \(s^{2}\) 导致经典的协方差矩阵估计器
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} s^{2} . \]
由于 \(s^{2}\) 对于 \(\sigma^{2}\) 是有条件无偏的,因此在同方差假设下,可以简单地计算出 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}\) 对于 \(\boldsymbol{V}_{\widehat{\beta}}\) 有条件无偏:
\[ \mathbb{E}\left[\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0} \mid \boldsymbol{X}\right]=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \mathbb{E}\left[s^{2} \mid \boldsymbol{X}\right]=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2}=\boldsymbol{V}_{\widehat{\beta}} . \]
多年来,这是应用计量经济学中占主导地位的协方差矩阵估计量,并且仍然是大多数回归包中的默认方法。例如,Stata 在线性回归中默认使用协方差矩阵估计器 (4.35),除非指定了替代方案。如果使用估计器 (4.35) 但回归误差是异方差的,则 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}\) 可能会对正确的协方差矩阵 \(\boldsymbol{V}_{\widehat{\beta}}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\) 有很大偏差。例如,假设 \(k=1\) 和 \(\sigma_{i}^{2}=X_{i}^{2}\) 以及 \(\mathbb{E}[X]=0\)。最小二乘估计量的真实方差与方差估计量的期望之比为
\[ \frac{\boldsymbol{V}_{\widehat{\beta}}}{\mathbb{E}\left[\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0} \mid \boldsymbol{X}\right]}=\frac{\sum_{i=1}^{n} X_{i}^{4}}{\sigma^{2} \sum_{i=1}^{n} X_{i}^{2}} \simeq \frac{\mathbb{E}\left[X^{4}\right]}{\left(\mathbb{E}\left[X^{2}\right]\right)^{2}} \stackrel{\text { def }}{=} \kappa \]
(请注意,我们使用 \(\sigma_{i}^{2}=X_{i}^{2}\) 暗示 \(\sigma^{2}=\mathbb{E}\left[\sigma_{i}^{2}\right]=\mathbb{E}\left[X^{2}\right]\) 这一事实。)常数 \(\kappa\) 是回归量 \(X\) 的标准化四阶矩(或峰度),可以是任何大于 1 的数字。例如,如果 \(X \sim \mathrm{N}\left(0, \sigma^{2}\right)\) 则 \(\kappa=3\),因此真实方差 \(\boldsymbol{V}_{\widehat{\beta}}\) 比预期同方差估计量 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}\) 大三倍。但 \(\kappa\) 可以大得多。以 CPS 数据集中的可变工资为例。它满足 \(\sigma_{i}^{2}=X_{i}^{2}\),因此如果条件方差等于 \(\sigma_{i}^{2}=X_{i}^{2}\),则真实方差 \(\sigma_{i}^{2}=X_{i}^{2}\) 比预期同方差估计量 \(\sigma_{i}^{2}=X_{i}^{2}\) 大 30 倍。虽然这是一个极端的情况,但要点是,当同方差假设失败时,经典的协方差矩阵估计器 (4.35) 可能会有很大偏差。
4.14 异方差下的协方差矩阵估计
在上一节中,我们表明,如果同方差失败,经典的协方差矩阵估计器可能会出现很大的偏差。在本节中,我们将展示如何构造不需要同方差的协方差矩阵估计器。
回想一下,协方差矩阵的一般形式是
\[ \boldsymbol{V}_{\widehat{\beta}}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \]
\(\boldsymbol{D}\) 在 (4.8) 中定义。这取决于未知矩阵 \(\boldsymbol{D}\),我们可以将其写为
\[ \boldsymbol{D}=\operatorname{diag}\left(\sigma_{1}^{2}, \ldots, \sigma_{n}^{2}\right)=\mathbb{E}\left[\boldsymbol{e} \boldsymbol{e}^{\prime} \mid \boldsymbol{X}\right]=\mathbb{E}[\widetilde{\boldsymbol{D}} \mid \boldsymbol{X}] \]
其中 \(\widetilde{\boldsymbol{D}}=\operatorname{diag}\left(e_{1}^{2}, \ldots, e_{n}^{2}\right)\).因此 \(\widetilde{\boldsymbol{D}}\) 是 \(\boldsymbol{D}\) 的条件无偏估计量。如果平方误差 \(e_{i}^{2}\) 是可观察到的,我们可以为 \(\boldsymbol{V}_{\widehat{\beta}}\) 构造一个无偏估计量,如下所示
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\text {ideal }} &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \widetilde{\boldsymbol{D}} \boldsymbol{X}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} e_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \end{aligned} \]
的确,
\[ \begin{aligned} \mathbb{E}\left[\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\text {ideal }} \mid \boldsymbol{X}\right] &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \mathbb{E}\left[e_{i}^{2} \mid \boldsymbol{X}\right]\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \sigma_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{D} \boldsymbol{X}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}=\boldsymbol{V}_{\widehat{\beta}} \end{aligned} \]
验证 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\text {ideal }}\) 对于 \(\boldsymbol{V}_{\widehat{\beta}}\) 是无偏的。由于错误 \(e_{i}^{2}\) 未被观察到,因此 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\text {ideal }}\) 不是一个可行的估计器。但是,我们可以用残差平方 \(\widehat{e}_{i}^{2}\) 替换 \(e_{i}^{2}\)。通过这种替换,我们得到了估计量
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 0}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \widehat{e}_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \]
标签“HC”是指“异方差一致”。标签“HC0”指的是基线异方差一致的协方差矩阵估计量。
然而,我们知道 \(\widehat{e}_{i}^{2}\) 偏向于零(回想方程(4.27))。为了估计方差 \(\sigma^{2}\),无偏估计器 \(s^{2}\) 将矩估计器 \(\widehat{\sigma}^{2}\) 按 \(n /(n-k)\) 进行缩放。进行相同的调整,我们得到估计量
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC1}}=\left(\frac{n}{n-k}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \widehat{e}_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \]
虽然 \(n /(n-k)\) 的缩放是 \(a d h o c, \mathrm{HCl}\),但通常建议使用未缩放的 HC0 估计器。
或者,我们可以使用标准化残差 \(\bar{e}_{i}\) 或预测误差 \(\widetilde{e}_{i}\),产生“HC2”和“HC3”估计量
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 2} &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \bar{e}_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n}\left(1-h_{i i}\right)^{-1} X_{i} X_{i}^{\prime} \widehat{e}_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \end{aligned} \]
和
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 3} &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \tilde{e}_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n}\left(1-h_{i i}\right)^{-2} X_{i} X_{i}^{\prime} \widehat{e}_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \end{aligned} \]
四个估计量 \(\mathrm{HC}\)、\(\mathrm{HC1}\)、HC2 和 HC3 统称为稳健、异方差一致或异方差稳健协方差矩阵估计量。 HC0 估计量首先由 Eicker (1963) 开发,并由 White (1980) 引入计量经济学,有时称为 Eicker-White 或 White 协方差矩阵估计量。 \(\mathrm{HCl}\) 中的自由度调整是由 Hinkley (1977) 推荐的,并且是 Stata 中实现的默认稳健协方差矩阵估计器。它是通过“, \(r\)”选项实现的。在当前应用计量经济学实践中,这是最流行的协方差矩阵估计器。 HC2 估计器由 Horn、Horn 和 Duncan (1975) 提出,并使用 Stata 中的 vce (hc2) 选项实现。 HC3 估计器由 MacKinnon 和 White (1985) 根据折刀原理(参见第 10.3 节)推导出来,由 Andrews (1991a) 根据留一交叉验证原理推导出来,并使用 vce(hc3 ) Stata 中的选项。
由于 \(\left(1-h_{i i}\right)^{-2}>\left(1-h_{i i}\right)^{-1}>1\) 很容易证明
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 0}<\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 2}<\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 3} . \]
(参见练习 4.10。)当应用于矩阵时,不等式 \(\boldsymbol{A}<\boldsymbol{B}\) 意味着矩阵 \(\boldsymbol{B}-\boldsymbol{A}\) 是正定的。一般来说,协方差矩阵估计量的偏差很复杂,但在同方差假设下却很简单(4.3)。例如,使用(4.27),
\[ \begin{aligned} \mathbb{E}\left[\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 0} \mid \boldsymbol{X}\right] &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \mathbb{E}\left[\widehat{e}_{i}^{2} \mid \boldsymbol{X}\right]\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime}\left(1-h_{i i}\right) \sigma^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} h_{i i}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2} \\ &<\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2}=\boldsymbol{V}_{\widehat{\beta}} \end{aligned} \]
此计算表明 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 0}\) 偏向于零。
通过类似的计算(同样在同方差下),我们可以计算出 HC2 估计量是无偏的
\[ \mathbb{E}\left[\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 2} \mid \boldsymbol{X}\right]=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2} . \]
(参见练习 4.11。)
在同方差假设下比较异方差稳健估计量的偏差可能看起来相当奇怪,但它确实为我们提供了比较的基线。
另一个有趣的计算表明,一般来说(即,在不假设同方差的情况下)HC3 估计量会偏离零。事实上,使用预测误差的定义(3.44)
\[ \widetilde{e}_{i}=Y_{i}-X_{i}^{\prime} \widehat{\beta}_{(-i)}=e_{i}-X_{i}^{\prime}\left(\widehat{\beta}_{(-i)}-\beta\right) \]
所以
\[ \widetilde{e}_{i}^{2}=e_{i}^{2}-2 X_{i}^{\prime}\left(\widehat{\beta}_{(-i)}-\beta\right) e_{i}+\left(X_{i}^{\prime}\left(\widehat{\beta}_{(-i)}-\beta\right)\right)^{2} . \]
请注意,\(e_{i}\) 和 \(\widehat{\beta}_{(-i)}\) 是非重叠观测值的函数,因此是独立的。因此 \(\mathbb{E}\left[\left(\widehat{\beta}_{(-i)}-\beta\right) e_{i} \mid \boldsymbol{X}\right]=0\) 和
\[ \begin{aligned} \mathbb{E}\left[\widetilde{e}_{i}^{2} \mid \boldsymbol{X}\right] &=\mathbb{E}\left[e_{i}^{2} \mid \boldsymbol{X}\right]-2 X_{i}^{\prime} \mathbb{E}\left[\left(\widehat{\beta}_{(-i)}-\beta\right) e_{i} \mid \boldsymbol{X}\right]+\mathbb{E}\left[\left(X_{i}^{\prime}\left(\widehat{\beta}_{(-i)}-\beta\right)\right)^{2} \mid \boldsymbol{X}\right] \\ &=\sigma_{i}^{2}+\mathbb{E}\left[\left(X_{i}^{\prime}\left(\widehat{\beta}_{(-i)}-\beta\right)\right)^{2} \mid \boldsymbol{X}\right] \\ & \geq \sigma_{i}^{2} . \end{aligned} \]
它遵循
\[ \begin{aligned} \mathbb{E}\left[\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 3} \mid \boldsymbol{X}\right] &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \mathbb{E}\left[\tilde{e}_{i}^{2} \mid \boldsymbol{X}\right]\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \\ & \geq\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{i=1}^{n} X_{i} X_{i}^{\prime} \sigma_{i}^{2}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}=\boldsymbol{V}_{\widehat{\beta}} \end{aligned} \]
这意味着 HC3 估计量是保守的,因为它比 \(\boldsymbol{X}\) 的任何实现的正确方差稍大(在预期中)。
我们引入了五个协方差矩阵估计器,包括同方差估计器 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}\) 和四个 HC 估计器。你应该使用哪个?经典估计器 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}\) 通常是一个糟糕的选择,因为它仅在不太可能的同方差限制下有效。因此,它通常不用于当代计量经济学研究。不幸的是,标准回归包将默认选择设置为 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}\),因此用户必须有意选择一个稳健的协方差矩阵估计器。
在四个稳健估计器中,\(\mathrm{HCl}\) 是最常用的,因为它是 Stata 中默认的稳健协方差矩阵选项。然而,优选HC2和HC3。 HC2 是无偏的(在同方差下),而 HC3 对于任何 \(\boldsymbol{X}\) 都是保守的。在大多数应用程序中,\(\mathrm{HC} 1, \mathrm{HC} 2\) 和 \(\mathrm{HC} 3\) 是相似的,因此这个选择并不重要。估计量可能存在很大差异的情况是,当样本对于至少一个观测值具有较大的杠杆值 \(h_{i i}\) 时。您可以通过比较公式 (4.37)、(4.38) 和 (4.39) 来看到这一点,并注意到唯一的区别是杠杆值 \(h_{i i}\) 的缩放。如果 \(h_{i i}\) 的观测值接近 1,则 \(\left(1-h_{i i}\right)^{-1}\) 和 \(\left(1-h_{i i}\right)^{-2}\) 将很大,从而使该观测值在协方差矩阵公式中具有更大的权重。

4.15 标准误
方差估计器(例如 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}\))是 \(\widehat{\beta}\) 分布方差的估计器。更容易解释的传播度量是其平方根——标准差。在讨论参数估计量的分布时,这一点非常重要,我们有一个特殊的名称来表示其标准差的估计值。
定义 \(4.2\) 实值估计量 \(\widehat{\beta}\) 的标准误差 \(s(\widehat{\beta})\) 是 \(\widehat{\beta}\) 分布的标准差的估计量。
当 \(\beta\) 是带有估计器 \(\widehat{\beta}\) 和协方差矩阵估计器 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}\) 的向量时,各个元素的标准误差是 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}\) 对角线元素的平方根。那是,
\[ s\left(\widehat{\beta}_{j}\right)=\sqrt{\widehat{\boldsymbol{V}}_{\widehat{\beta}_{j}}}=\sqrt{\left[\widehat{\boldsymbol{V}}_{\widehat{\beta}}\right]_{j j}} \]
当使用经典协方差矩阵估计器 (4.35) 时,标准误差采用简单形式
\[ s\left(\widehat{\beta}_{j}\right)=s \sqrt{\left[\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\right]_{j j}} . \]
正如我们在上一节中讨论的,存在多种可能的协方差矩阵估计量,因此标准误差不是唯一的。因此,了解作者在研究其作品时使用的公式和方法非常重要。同样重要的是要理解,特定的标准误差可能在一组模型假设下相关,但在另一组假设下则不相关。
为了说明这一点,我们回到第 3.7 节的对数工资回归(3.12)。我们计算\(s^{2}=0.160\)。因此同方差协方差矩阵估计为
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{0}=\left(\begin{array}{cc} 5010 & 314 \\ 314 & 20 \end{array}\right)^{-1} 0.160=\left(\begin{array}{cc} 0.002 & -0.031 \\ -0.031 & 0.499 \end{array}\right) \]
我们还计算出
\[ \sum_{i=1}^{n}\left(1-h_{i i}\right)^{-1} X_{i} X_{i}^{\prime} \widehat{e}_{i}^{2}=\left(\begin{array}{cc} 763.26 & 48.513 \\ 48.513 & 3.1078 \end{array}\right) . \]
因此 HC2 协方差矩阵估计为
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC} 2} &=\left(\begin{array}{cc} 5010 & 314 \\ 314 & 20 \end{array}\right)^{-1}\left(\begin{array}{cc} 763.26 & 48.513 \\ 48.513 & 3.1078 \end{array}\right)\left(\begin{array}{cc} 5010 & 314 \\ 314 & 20 \end{array}\right)^{-1} \\ &=\left(\begin{array}{cc} 0.001 & -0.015 \\ -0.015 & 0.243 \end{array}\right) . \end{aligned} \]
标准误差是这些矩阵对角线元素的平方根。编写具有标准误差的估计方程的传统格式是
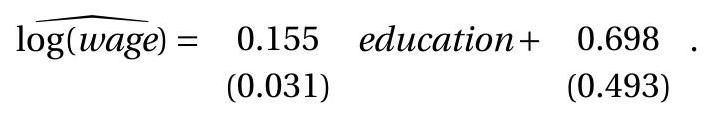
或者,可以使用其他公式计算标准误差。我们在下表中报告了不同的标准误差。
表 4.1:标准误
| Education | Intercept | |
|---|---|---|
| Homoskedastic (4.35) | \(0.045\) | \(0.707\) |
| HC0 (4.36) | \(0.029\) | \(0.461\) |
| HC1 \((4.37)\) | \(0.030\) | \(0.486\) |
| HC2 \((4.38)\) | \(0.031\) | \(0.493\) |
| HC3 \((4.39)\) | \(0.033\) | \(0.527\) |
同方差标准误差与其他标准误差明显不同(在本例中更大)。尽管 HC3 标准误差比其他标准误差大,但稳健标准误差彼此相当接近。
4.16 使用稀疏虚拟变量进行估计
在某些情况下,异方差鲁棒协方差矩阵估计量可能非常不精确。一种是存在稀疏虚拟变量 - 当虚拟变量仅针对极少数观测值取值 1 或 0 时。在这些情况下,协方差矩阵的一个组成部分仅根据少数观测值进行估计,并且是不精确的。这对用户来说是有效隐藏的。要查看问题,让 \(D\) 为虚拟变量(采用值 1 和 0 )并考虑虚拟变量回归
\[ Y=\beta_{1} D+\beta_{2}+e . \]
\(D_{i}=1\) 为 \(n_{1}=\sum_{i=1}^{n} D_{i}\) 的观测值数量。 \(D_{i}=0\) 为 \(n_{2}=n-n_{1}\) 的观测值数量。如果 \(n_{1}\) 或 \(n_{2}\) 很小,我们就说设计是稀疏的。
为了简化我们的分析,我们采用极端情况\(n_{1}=1\)。这些想法扩展到 \(n_{1}>1\) 的情况,但规模较小,但影响较小。
在回归模型(4.45)中,我们可以计算出在条件同方差简化假设下系数的最小二乘估计量的真实协方差矩阵为
\[ \boldsymbol{V}_{\widehat{\beta}}=\sigma^{2}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}=\sigma^{2}\left(\begin{array}{ll} 1 & 1 \\ 1 & n \end{array}\right)^{-1}=\frac{\sigma^{2}}{n-1}\left(\begin{array}{cc} n & -1 \\ -1 & 1 \end{array}\right) \]
特别是,虚拟变量系数的估计量的方差为
\[ V_{\widehat{\beta}_{1}}=\sigma^{2} \frac{n}{n-1} . \]
本质上,系数 \(\beta_{1}\) 是根据单个观测值估计的,因此其方差大致不受样本大小的影响。一个重要的信息是,无论样本大小如何,在存在稀疏虚拟变量的情况下,某些系数估计器都将不精确。仅靠大样本不足以确保精确估计。
现在让我们检查标准 HC1 协方差矩阵估计器 (4.37)。回归与 \(D_{i}=1\) 的观测值完美拟合,因此相应的残差为 \(\widehat{e}_{i}=0\)。由此可见,\(D_{i} \widehat{e}_{i}=0\) 对于所有 \(i\) (\(D_{i}=0\) 或 \(\widehat{e}_{i}=0\) )。因此
\[ \sum_{i=1}^{n} X_{i} X_{i}^{\prime} \hat{e}_{i}^{2}=\left(\begin{array}{cc} 0 & 0 \\ 0 & \sum_{i=1}^{n} \widehat{e}_{i}^{2} \end{array}\right)=\left(\begin{array}{cc} 0 & 0 \\ 0 & (n-2) s^{2} \end{array}\right) \]
其中 \(s^{2}=(n-2)^{-1} \sum_{i=1}^{n} \widehat{e}_{i}^{2}\) 是 \(\sigma^{2}\) 的偏差校正估计量。我们一起发现
\[ \begin{aligned} \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC1}} &=\left(\frac{n}{n-2}\right) \frac{1}{(n-1)^{2}}\left(\begin{array}{cc} n & -1 \\ -1 & 1 \end{array}\right)\left(\begin{array}{cc} 0 & 0 \\ 0 & (n-2) s^{2} \end{array}\right)\left(\begin{array}{cc} n & -1 \\ -1 & 1 \end{array}\right) \\ &=s^{2} \frac{n}{(n-1)^{2}}\left(\begin{array}{cc} 1 & -1 \\ -1 & 1 \end{array}\right) . \end{aligned} \]
特别是,\(V_{\widehat{\beta}_{1}}\) 的估计量是
\[ \widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC} 1}=s^{2} \frac{n}{(n-1)^{2}} \]
是有期待的
\[ \mathbb{E}\left[\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC1}}\right]=\sigma^{2} \frac{n}{(n-1)^{2}}=\frac{V_{\widehat{\beta}_{1}}}{n-1}<<V_{\widehat{\beta}_{1}} . \]
方差估计器 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HCl}}\) 对 \(V_{\widehat{\beta}_{1}}\) 有极大偏差。它太小了 \(n\) 的倍数!报告的方差和标准误差小得令人误解。方差估计错误地表述了 \(\widehat{\beta}_{1}\) 的精度。
应用研究人员不太可能注意到 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HCl}}\) 有偏见的事实。报告的输出中没有任何内容会提醒研究人员注意该问题。查看该问题的另一种方法是考虑系数 \(\theta=\beta_{1}+\beta_{2}\) 之和的估计器 \(\widehat{\theta}=\widehat{\beta}_{1}+\widehat{\beta}_{2}\)。该估计量具有真实方差 \(\sigma^{2}\)。然而,方差估计器是 \(\widehat{\boldsymbol{V}}_{\widehat{\theta}}^{\mathrm{HC1}}=0\) ! (它等于 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{HC1}}\) 中四个元素的总和)。显然,估计器“0”对真实值\(\sigma^{2}\)有偏差。
另一个见解是检查杠杆值。 \(D_{i}=1\) 的(单个)观察有
\[ h_{i i}=\frac{1}{n-1}\left(\begin{array}{ll} 1 & 1 \end{array}\right)\left(\begin{array}{cc} n & -1 \\ -1 & 1 \end{array}\right)\left(\begin{array}{l} 1 \\ 1 \end{array}\right)=1 . \]
这是一个极端的杠杆值。
一种可能的解决方案是将有偏协方差矩阵估计器 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC1}}\) 替换为无偏估计器 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC} 2}\) (同方差下无偏)或保守估计器 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC}} .\) 这两种方法都不能在极端稀疏的情况下完成 \(n_{1}=1\) (对于 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC} 2}\) 和 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC}}\) 无法计算(如果 \(h_{i i}=1\) 对于任何观察),但适用于其他情况。当 \(h_{i i}=1\) 用于观察时,无法计算 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC} 2}\) 和 \(\widehat{V}_{\widehat{\beta}_{1}}^{\mathrm{HC1}}\)。在这种情况下,无偏协方差矩阵估计似乎是不可能的。
目前尚不清楚是否有最佳实践来避免这种情况。一次可能性就是计算最大杠杆值。如果非常大,请使用多种方法计算标准误差以查看是否发生变化。
4.17 计算
我们说明了计算方程 (3.13) 标准误差的方法,扩展了 \(3.25 .\) 节的代码
Stata 文件(续)
- 同方差公式(4.35):
reg 工资 教育经历 exp2 if \((\mathrm{mnwf}==1)\)
- \(\quad\) HC1 公式 (4.37):
reg 工资 教育经历 exp2 if \((\operatorname{mnwf}==1), \mathrm{r}\)
- \(\mathrm{HC} 2\) 公式 (4.38):
注册工资 教育经历 \(\exp 2\) 如果 \((\mathrm{mnwf}==1)\)、vce \((\mathrm{hc} 2)\)
- \(\quad\) HC3 公式 (4.39):
reg 工资 教育经验 exp2 if (mnwf \(==1)\), vce \((\mathrm{hc} 3)\)

.jpg)
4.18 适合度测量
正如我们在上一章中所描述的,常见的回归拟合度量是回归 \(R^{2}\) ,定义为
\[ R^{2}=1-\frac{\sum_{i=1}^{n} \widehat{e}_{i}^{2}}{\sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}}=1-\frac{\widehat{\sigma}^{2}}{\widehat{\sigma}_{Y}^{2}} . \]
其中 \(\widehat{\sigma}_{Y}^{2}=n^{-1} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2} \cdot R^{2}\) 是总体参数的估计器
\[ \rho^{2}=\frac{\operatorname{var}\left[X^{\prime} \beta\right]}{\operatorname{var}[Y]}=1-\frac{\sigma^{2}}{\sigma_{Y}^{2}} . \]
然而,\(\widehat{\sigma}^{2}\) 和 \(\widehat{\sigma}_{Y}^{2}\) 是有偏差的。 Theil (1961) 建议用无偏版本 \(s^{2}\) 和 \(\widetilde{\sigma}_{Y}^{2}=(n-1)^{-1} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}\) 替换它们,产生所谓的 R-bar-squared 或调整后的 R-squared:
\[ \bar{R}^{2}=1-\frac{s^{2}}{\widetilde{\sigma}_{Y}^{2}}=1-\frac{(n-1)^{-1} \sum_{i=1}^{n} \widehat{e}_{i}^{2}}{(n-k)^{-1} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}} . \]
虽然 \(\bar{R}^{2}\) 是对 \(R^{2}\) 的改进,但更好的改进是
\[ \widetilde{R}^{2}=1-\frac{\sum_{i=1}^{n} \widetilde{e}_{i}^{2}}{\sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}}=1-\frac{\widetilde{\sigma}^{2}}{\widehat{\sigma}_{Y}^{2}} \]
其中 \(\widetilde{e}_{i}\) 是预测误差 (3.44),\(\widetilde{\sigma}^{2}\) 是来自 (3.46) 的 MSPE。如第 (4.12) 节中所述,\(\widetilde{\sigma}^{2}\) 是样本外均方预测误差的良好估计器,因此 \(\widetilde{R}^{2}\) 是由回归预测解释的预测方差百分比的良好估计器。从这个意义上说,\(\widetilde{R}^{2}\) 是一个很好的拟合度量。
\(R^{2}\) 被 \(\bar{R}^{2}\) 部分校正并被 \(\widetilde{R}^{2}\) 完全校正的一个问题是,当将回归量添加到回归模型中时,\(R^{2}\) 必然会增加。发生这种情况是因为 \(R^{2}\) 是残差平方和的负函数,添加回归量时该函数无法增加。相反,\(\bar{R}^{2}\) 和 \(\widetilde{R}^{2}\) 的回归量数量是非单调的。 \(\widetilde{R}^{2}\) 甚至可能为负,当估计模型的预测结果比纯常数模型更差时就会发生这种情况。
在统计文献中,MSPE \(\widetilde{\sigma}^{2}\) 被称为留一交叉验证标准,在模型比较和选择中很受欢迎,尤其是在高维和非参数环境中。相当于使用\(\widetilde{R}^{2}\)或\(\widetilde{\sigma}^{2}\)来比较和选择模型。就预期样本外平方误差而言,具有较高 \(\widetilde{R}^{2}\) (或较低 \(\widetilde{\sigma}^{2}\) )的模型是更好的模型。相反,\(R^{2}\) 不能用于模型选择,因为当将回归量添加到回归模型时,它必然会增加。 \(\bar{R}^{2}\) 对于模型选择来说也是一个不合适的选择(它倾向于选择具有太多参数的模型),尽管要证明这一断言的合理性需要研究模型选择的理论。不幸的是,一些经济学家经常使用 \(\bar{R}^{2}\),这可能是前几代人的遗留问题。
综上所述,建议省略\(R^{2}\)和\(\bar{R}^{2}\)。如果需要拟合度测量,请报告 \(\widetilde{R}^{2}\) 或 \(\widetilde{\sigma}^{2}\)。

4.19 实证例子
我们再次回到我们的工资方程,但使用了一个更大的样本,其中所有受过至少 12 年教育的个体。对于回归变量,我们包括受教育年限、潜在工作经验、经验平方和虚拟变量指标:女性、女性工会成员、男性工会成员、已婚女性 \({ }^{1}\)、已婚男性、曾婚女性 \({ }^{2}\)、以前已婚男性、西班牙裔、黑人、美洲印第安人、亚洲人和混血\({ }^{3}\)。可用样本为 46,943,因此参数估计相当精确,如表 4.2 所示。对于标准误差,我们使用无偏 HC2 公式。
表 \(4.2\) 以标准表格格式显示参数估计值。报告所有系数的参数估计值和标准误差。除了系数估计值之外,该表还报告了估计误差标准差和样本量。这些是有用的总结性衡量标准,可以帮助读者。
表 4.2:\(\log (\) 工资 \()\) 线性方程的 OLS 估计
| \(\widehat{\beta}\) | \(s(\widehat{\beta})\) | |
|---|---|---|
| Education | \(0.117\) | \(0.001\) |
| Experience | \(0.033\) | \(0.001\) |
| Experience \(^{2} / 100\) | \(-0.056\) | \(0.002\) |
| Female | \(-0.098\) | \(0.011\) |
| Female Union Member | \(0.023\) | \(0.020\) |
| Male Union Member | \(0.095\) | \(0.020\) |
| Married Female | \(0.016\) | \(0.010\) |
| Married Male | \(0.211\) | \(0.010\) |
| Formerly Married Female | \(-0.006\) | \(0.012\) |
| Formerly Married Male | \(0.083\) | \(0.015\) |
| Hispanic | \(-0.108\) | \(0.008\) |
| Black | \(-0.096\) | \(0.008\) |
| American Indian | \(-0.137\) | \(0.027\) |
| Asian | \(-0.038\) | \(0.013\) |
| Mixed Race | \(-0.041\) | \(0.021\) |
| Intercept | \(0.909\) | \(0.021\) |
| \(\widehat{\sigma}\) | \(0.565\) | |
| Sample Size | 46,943 |
标准误是异方差一致的(Horn-Horn-Duncan 公式)。
作为一般规则,建议始终报告标准误差以及参数估计值。这使读者能够评估参数估计的精度,并且正如我们将在后面的章节中讨论的那样,如果需要,可以形成各个系数的置信区间和 t 检验。
表 \(4.2\) 中的结果证实了我们之前的发现,即一年教育的回报约为 \(12 %\),经验的回报是凹的,单身女性的收入大约比单身男性少 \(10 %\),黑人的收入约为 \(10 %\)。此外,我们还发现西班牙裔美国人的收入比白人低约 \(11 %\),美洲印第安人的收入比白人低 \(14 %\),亚洲人和混血人种的收入比白人低约 \(4 %\)。我们也看到那里
\({ }^{1}\) 将“已婚”定义为婚姻代码 1,2 或 \(3 .\)
\({ }^{2}\) 将“以前已婚”定义为婚姻代码 4,5 或 6 。
\({ }^{3}\) 竞赛代码 6 或更高。是工会成员(约 \(10 %\) )、已婚(约 21%)或曾经结婚(约 \(8 %\) )的男性的工资溢价,但女性没有明显的类似溢价。
4.20 多重共线性
正如第 3.24 节中所讨论的,如果 \(\boldsymbol{X}^{\prime} \boldsymbol{X}\) 是单数,则 \(\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\) 和 \(\widehat{\beta}\) 未定义。这种情况称为严格多重共线性,因为 \(\boldsymbol{X}\) 的列是线性相关的,即存在一些 \(\alpha \neq 0\) 使得 \(\boldsymbol{X} \alpha=0\) 存在。最常见的是,当包含相同相关的回归量集时,就会出现这种情况。在 \(3.24\) 节中,我们讨论了严格多重共线性的可能原因,并讨论了病态的相关问题,在严重的情况下可能会导致数值不准确。
一种相关的常见情况是接近多重共线性,为简洁起见,通常将其称为“多重共线性”。这是回归量高度相关时的情况。近似多重共线性的含义是个体系数估计将不精确。如果报告的标准误差准确,这对于计量经济分析来说不一定是问题。然而,稳健的标准误差可能对近多重共线性下可能发生的大杠杆值敏感。这会导致系数估计不精确但标准误差小得令人误解的不良情况。
我们可以在具有两个回归量的简单同方差线性回归模型中看到近多重共线性对精度的影响
\[ Y=X_{1} \beta_{1}+X_{2} \beta_{2}+e \]
和
\[ \frac{1}{n} \boldsymbol{X}^{\prime} \boldsymbol{X}=\left(\begin{array}{ll} 1 & \rho \\ \rho & 1 \end{array}\right) . \]
在这种情况下
\[ \operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]=\frac{\sigma^{2}}{n}\left(\begin{array}{ll} 1 & \rho \\ \rho & 1 \end{array}\right)^{-1}=\frac{\sigma^{2}}{n\left(1-\rho^{2}\right)}\left(\begin{array}{cc} 1 & -\rho \\ -\rho & 1 \end{array}\right) . \]
相关性 \(\rho\) 表示共线性,因为当 \(\rho\) 接近 1 时,矩阵变得奇异。我们可以通过观察系数估计值 \(\sigma^{2}\left[n\left(1-\rho^{2}\right)\right]^{-1}\) 的方差随着 \(\rho\) 接近 1 而接近无穷大来了解共线性对精度的影响。因此,回归量越“共线”,各个系数估计的精度就越差。
所发生的情况是,当回归量高度依赖时,从统计上来说很难将 \(\beta_{1}\) 的影响与 \(\beta_{2}\) 的影响区分开来。结果,个人估计的精确度降低了。
许多早期教科书过分强调多重共线性。对这些文本的一个有趣的模仿是《微观数字》,《戈德伯格计量经济学课程》(1991) 的 \(23.3\) 章。他的章节中有以下诙谐的言论。
当 \(n=0\) 时出现极端情况,即“精确的微观数字”,在这种情况下,\(\mu\) 的样本估计值不是唯一的。 (从技术上讲,这违反了等级条件 \(n>0\) :矩阵 0 是奇异的。)
测试是否存在微数需要明智地使用各种手指。一些研究人员更喜欢用一根手指,另一些人则用脚趾,还有一些人则用拇指来统治。
通过计算观察结果的数量可以获得普遍可靠的指导。大多数时候,在计量经济学分析中,当 \(n\) 接近于零时,它也远离无穷大。
Arthur S. Goldberger,计量经济学课程 (1991),第 \(249 .\) 要理解 Goldberger 的基本观点,您应该注意到估计方差 \(\sigma^{2}\left[n\left(1-\rho^{2}\right)\right]^{-1}\) 同等且对称地取决于相关性 \(\rho\) 和样本大小 \(n\) 。他指出,同方差模型中多重共线性的唯一统计意义是缺乏精度。小样本量也具有完全相同的含义。
| Arthur S. Goldberger |
|---|
| Art Goldberger (1930-2009) was one of the most distinguished members of the |
| Department of Economics at the University of Wisconsin. His Ph.D. thesis devel- |
| oped a pioneering macroeconometric forecasting model (the Klein-Goldberger |
| model). Most of his remaining career focused on microeconometric issues. He |
| was the leading pioneer of what has been called the Wisconsin Tradition of em- |
| pirical work - a combination of formal econometric theory with a careful critical |
| analysis of empirical work. Goldberger wrote a series of highly regarded and in- |
| fluential graduate econometric textbooks, including Econometric Theory (1964), |
| Topics in Regression Analysis (1968), and A Course in Econometrics (1991). |
4.21 聚类抽样
在 \(4.2\) 节中,我们简要提到了聚类抽样作为随机抽样假设的替代方案。现在,我们更详细地介绍该框架,并将本章的主要结果扩展到包含集群依赖。
通过考虑一个具体的例子可能是最容易理解集群概念的。 Duflo、Dupas 和 Kremer(2011)在一项随机实验中研究了跟踪(根据初始测试成绩分配学生)对教育程度的影响。他们的数据集的摘录可以在教科书网页上的文件 DDK2011 中找到。
2005年,肯尼亚140所小学获得资金聘请额外的一年级教师以减少班级规模。在一半的学校(随机选择)中,学生根据初始测试成绩(“跟踪”)被分配到教室;在其余学校,学生被随机分配到教室。在他们的分析中,作者将注意力集中在最初只有一个一年级班级的 121 所学校。
论文中的关键回归\({ }^{4}\)是
\[ \text { TestScore }_{i g}=-0.071+0.138 \text { Tracking }_{g}+e_{i g} \]
其中 TestScore \({ }_{i g}\) 是学校 \(g\) 中学生 \(i\) 的标准化测试分数(标准化为均值 0 和方差 1),如果学校 \(g\) 正在跟踪,则跟踪 \(g\) 是等于 1 的虚拟值。 OLS 估计表明,跟踪学生的学校的测试成绩总体提高了约 \(0.14\) 标准差,这是有意义的。估计了该回归的更一般版本,其中许多采用以下形式
\[ \text { TestScore }_{i g}=\alpha+\gamma \text { Tracking }_{g}+X_{i g}^{\prime} \beta+e_{i g} \]
其中 \(X_{i g}\) 是一组特定于学生的控件(包括年龄、性别和初始测试成绩)。
\({ }^{4}\) 表 2,第 (1) 列。 Duflo、Dupas 和 Kremer (2011) 报告了 \(0.139\) 的系数估计,这可能是由于标准化测试分数的计算略有不同。应用经典回归框架的一个困难在于,学生的成绩可能在给定学校内相关。学生的成绩可能会受到当地人口统计、个别教师和同学的影响,所有这些都意味着依赖性。然而,这些担忧并不表明学校之间的成绩是相关的,因此将学校之间的成绩建模为相互独立似乎是合理的。我们称这种依赖为集群。
在聚类上下文中,可以方便地将观测值双重索引为 \(\left(Y_{i g}, X_{i g}\right)\),其中 \(g=1, \ldots, G\) 对聚类进行索引,而 \(i=1, \ldots, n_{g}\) 对 \(g^{t h}\) 聚类中的个体进行索引。每个集群 \(n_{g}\) 的观察数量可能因集群而异。簇的数量是 \(G\)。观察总数为 \(n=\sum_{g=1}^{G} n_{g}\)。在肯尼亚学校教育示例中,估计样本中的聚类(学校)数量为 \(G=121\),每所学校的学生人数从 19 到 62 不等,观察总数为 \(n=5795\)。
虽然通常使用双索引符号 \(\left(Y_{i g}, X_{i g}\right)\) 来编写观察结果,但使用簇级符号也很有用。令 \(\boldsymbol{Y}_{g}=\left(Y_{1 g}, \ldots, Y_{n_{g} g}\right)^{\prime}\) 和 \(\boldsymbol{X}_{g}=\left(X_{1 g}, \ldots, X_{n_{g} g}\right)^{\prime}\) 表示因变量的 \(n_{g} \times 1\) 向量和 \(g^{t h}\) 簇的回归量 \(n_{g} \times k\) 矩阵。线性回归模型可以由个人编写为
\[ Y_{i g}=X_{i g}^{\prime} \beta+e_{i g} \]
并使用簇符号作为
\[ \boldsymbol{Y}_{g}=\boldsymbol{X}_{g} \beta+\boldsymbol{e}_{g} \]
其中 \(\boldsymbol{e}_{g}=\left(e_{1 g}, \ldots, e_{n_{g} g}\right)^{\prime}\) 是 \(n_{g} \times 1\) 误差向量。我们还可以将观察结果堆叠到完整的样本矩阵中,并将模型写为
\[ \boldsymbol{Y}=\boldsymbol{X} \beta+\boldsymbol{e} . \]
使用这种表示法,我们可以使用双和 \(\sum_{g=1}^{G} \sum_{i=1}^{n_{g}}\) 写出观测值的总和。这是每个簇内观测值总和的簇间总和。 OLS 估计器可以写为
\[ \begin{aligned} \widehat{\beta} &=\left(\sum_{g=1}^{G} \sum_{i=1}^{n_{g}} X_{i g} X_{i g}^{\prime}\right)^{-1}\left(\sum_{g=1}^{G} \sum_{i=1}^{n_{g}} X_{i g} Y_{i g}\right) \\ &=\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{X}_{g}\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{Y}_{g}\right) \\ &=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{Y}\right) \end{aligned} \]
残差在个体级别表示法中为 \(\widehat{e}_{i g}=Y_{i g}-X_{i g}^{\prime} \widehat{\beta}\),在集群级别表示法中为 \(\widehat{\boldsymbol{e}}_{g}=\boldsymbol{Y}_{g}-\boldsymbol{X}_{g} \widehat{\beta}\)。
标准的聚类假设是研究人员已知聚类并且观察结果在聚类之间是独立的。
假设 4.4 簇 \(\left(\boldsymbol{Y}_{g}, \boldsymbol{X}_{g}\right)\) 在簇 \(g\) 之间相互独立。
在我们的示例中,集群是学校。在其他常见的应用中,集群依赖被假设在单个教室、家庭、村庄、地区以及更大的单位(例如工业和国家)内。这种选择取决于研究人员,尽管其理由取决于背景、数据的性质,并将反映关于观察之间的依赖结构的信息和假设。该模型是假设下的线性回归
\[ \mathbb{E}\left[\boldsymbol{e}_{g} \mid \boldsymbol{X}_{g}\right]=0 . \]
这与假设各个误差有条件均值为零相同
\[ \mathbb{E}\left[e_{i g} \mid \boldsymbol{X}_{g}\right]=0 \]
或者给定 \(\boldsymbol{X}_{g}\) 时 \(\boldsymbol{Y}_{g}\) 的条件期望是线性的。如独立情况方程 (4.50) 所示,意味着线性回归模型已正确指定。在聚类回归模型中,这要求在单个回归变量 \(X_{i g}\) 的规范中考虑聚类内的所有相互作用效应。
在回归(4.46)中,条件期望必然是线性的并且满足(4.50),因为
 \ 控制(4.50)要求任何学生的成绩不受同一学校内其他学生的个人控制(例如年龄、性别和初始考试成绩)的影响。
\ 控制(4.50)要求任何学生的成绩不受同一学校内其他学生的个人控制(例如年龄、性别和初始考试成绩)的影响。
给定 (4.50),我们可以计算 OLS 估计器的期望。将(4.48)代入(4.49)我们发现
\[ \widehat{\beta}-\beta=\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{X}_{g}\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{e}_{g}\right) \]
所有回归量的 \(\widehat{\beta}-\beta\) 条件的平均值是
\[ \begin{aligned} \mathbb{E}[\widehat{\beta}-\beta \mid \boldsymbol{X}] &=\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{X}_{g}\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \mathbb{E}\left[\boldsymbol{e}_{g} \mid \boldsymbol{X}\right]\right) \\ &=\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{X}_{g}\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \mathbb{E}\left[\boldsymbol{e}_{g} \mid \boldsymbol{X}_{g}\right]\right) \\ &=0 . \end{aligned} \]
第一个等式由线性成立,第二个等式由假设 4.4 成立,第三个等式由 (4.50) 成立。
这表明,如果条件期望是线性的,则 OLS 在聚类下是无偏的。
定理4.7 在聚类线性回归模型中(假设\(4.4\)和(4.50))\(\mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]=\beta\)。
现在考虑 \(\widehat{\beta}\) 的协方差矩阵。令 \(\Sigma_{g}=\mathbb{E}\left[\boldsymbol{e}_{g} \boldsymbol{e}_{g}^{\prime} \mid \boldsymbol{X}_{g}\right]\) 表示 \(g^{t h}\) 簇内误差的 \(n_{g} \times n_{g}\) 条件协方差矩阵。由于观察结果在簇之间是独立的,
\[ \begin{aligned} \operatorname{var}\left[\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{e}_{g}\right) \mid \boldsymbol{X}\right] &=\sum_{g=1}^{G} \operatorname{var}\left[\boldsymbol{X}_{g}^{\prime} \boldsymbol{e}_{g} \mid \boldsymbol{X}_{g}\right] \\ &=\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \mathbb{E}\left[\boldsymbol{e}_{g} \boldsymbol{e}_{g}^{\prime} \mid \boldsymbol{X}_{g}\right] \boldsymbol{X}_{g} \\ &=\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \Sigma_{g} \boldsymbol{X}_{g} \\ & \stackrel{\text { def }}{=} \Omega_{n} \end{aligned} \]
它遵循
\[ \boldsymbol{V}_{\widehat{\beta}}=\operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \Omega_{n}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \]
由于簇内观测值之间的相关性,这与独立情况下的公式不同。差异的大小取决于簇内观测值之间的相关程度以及簇内观测值的数量。要看到这一点,假设所有簇对于 \(i \neq \ell\) 都有相同数量的观测值 \(n_{g}=N, \mathbb{E}\left[e_{i g}^{2} \mid \boldsymbol{X}_{g}\right]=\sigma^{2}, \mathbb{E}\left[e_{i g} e_{\ell g} \mid \boldsymbol{X}_{g}\right]=\sigma^{2} \rho\),并且回归量 \(X_{i g}\) 在簇内没有变化。在这种情况下,OLS 估计器的精确方差等于 \({ }^{5}\) (经过一些计算)
\[ \boldsymbol{V}_{\widehat{\beta}}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \sigma^{2}(1+\rho(N-1)) . \]
如果 \(\rho>0\) 的精确方差适当地是传统公式的 \(\rho N\) 的倍数。在肯尼亚学校的示例中,平均簇大小为 48 。如果 \(\rho=0.25\) 这意味着精确方差超出传统公式约 12 倍。在这种情况下,正确的标准误差(方差的平方根)大约是传统公式的三倍。这是一个巨大的差异,不应被忽视。
Arellano (1987) 提出了一种集群鲁棒协方差矩阵估计器,它是 White 估计器的扩展。回想一下,White 协方差估计器的见解是平方误差 \(e_{i}^{2}\) 对于 \(\mathbb{E}\left[e_{i}^{2} \mid X_{i}\right]=\sigma_{i}^{2}\) 是无偏的。类似地,由于簇依赖性,矩阵 \(\boldsymbol{e}_{g} \boldsymbol{e}_{g}^{\prime}\) 对于 \(\mathbb{E}\left[\boldsymbol{e}_{g} \boldsymbol{e}_{g}^{\prime} \mid \boldsymbol{X}_{g}\right]=\Sigma_{g}\) 是无偏的。这意味着 (4.51) 的无偏估计量是 \(\widetilde{\Omega}_{n}=\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \boldsymbol{e}_{g} \boldsymbol{e}_{g}^{\prime} \boldsymbol{X}_{g}\)。这是不可行的,但我们可以用 OLS 残差替换未知误差以获得 Arellano 估计量:
\[ \begin{aligned} \widehat{\Omega}_{n} &=\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \widehat{\boldsymbol{e}}_{g} \widehat{\boldsymbol{e}}_{g}^{\prime} \boldsymbol{X}_{g} \\ &=\sum_{g=1}^{G} \sum_{i=1}^{n_{g}} \sum_{\ell=1}^{n_{g}} X_{i g} X_{\ell g}^{\prime} \widehat{e}_{i g} \widehat{e}_{\ell g} \\ &=\sum_{g=1}^{G}\left(\sum_{i=1}^{n_{g}} X_{i g} \widehat{e}_{i g}\right)\left(\sum_{\ell=1}^{n_{g}} X_{\ell g} \widehat{e}_{\ell g}\right)^{\prime} . \end{aligned} \]
(4.54) 中的三个表达式给出了三个可用于计算 \(\widehat{\Omega}_{n}\) 的等效公式。最终表达式根据簇和 \(\sum_{\ell=1}^{n_{g}} X_{\ell g} \widehat{e}_{\ell g}\) 写入 \(\widehat{\Omega}_{n}\),这是我们的示例 \(\mathrm{R}\) 和下面所示的 MATLAB 代码的基础。
给定表达式 (4.51)-(4.52),自然聚类协方差矩阵估计量采用以下形式
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}=a_{n}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \widehat{\Omega}_{n}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \]
其中 \(a_{n}\) 是可能的有限样本调整。 Stata集群命令使用
\[ a_{n}=\left(\frac{n-1}{n-k}\right)\left(\frac{G}{G-1}\right) . \]
因子 \(G /(G-1)\) 是由 Chris Hansen (2007) 在同等大小集群的背景下导出的,目的是在集群 \(G\) 数量较小时提高性能。因子 \((n-1) /(n-k)\) 是 \(a d\) 的临时概括,它嵌套了 (4.37) 中使用的调整,因为 \(G=n\) 意味着简化 \(a_{n}=n /(n-k)\)。
可以使用簇级预测误差构建替代的簇鲁棒协方差矩阵估计器,例如 \(\widetilde{\boldsymbol{e}}_{g}=\boldsymbol{Y}_{g}-\boldsymbol{X}_{g} \widehat{\beta}_{(-g)}\),其中 \(\widehat{\beta}_{(-g)}\) 是省略簇 \(g\) 的最小二乘估计器。如第 3.20 节所示,我们可以证明
\[ \widetilde{\boldsymbol{e}}_{g}=\left(\boldsymbol{I}_{n_{g}}-\boldsymbol{X}_{g}\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}_{g}^{\prime}\right)^{-1} \widehat{\boldsymbol{e}}_{g} \]
\({ }^{5}\) 该公式源自 Moulton (1990)。和
\[ \widehat{\beta}_{(-g)}=\widehat{\beta}-\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}_{g}^{\prime} \widetilde{\boldsymbol{e}}_{g} . \]
然后我们就有了稳健的协方差矩阵估计器
\[ \widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{CR} 3}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\sum_{g=1}^{G} \boldsymbol{X}_{g}^{\prime} \widetilde{\boldsymbol{e}}_{g} \widetilde{\boldsymbol{e}}_{g}^{\prime} \boldsymbol{X}_{g}\right)\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} . \]
标签“CR”是指“集群鲁棒性”,“CR3”是指 HC3 估计器的类似公式。
与异方差稳健情况类似,您可以证明 CR3 是 \(\boldsymbol{V}_{\widehat{\beta}}\) 的保守估计量,因为 \(\widehat{\boldsymbol{V}}_{\widehat{\beta}}^{\mathrm{CR} 3}\) 的条件期望超过 \(\boldsymbol{V}_{\widehat{\beta}}\)。然而,这种协方差矩阵估计器实现起来比较麻烦,因为簇级预测误差 (4.57) 无法通过简单的线性运算来计算,并且需要跨簇的循环来计算。
为了在肯尼亚学校教育示例的背景下进行说明,我们在学校级别的跟踪虚拟模型上展示了学生测试成绩的回归,并显示了两个标准误差。第一个(括号中)是传统的稳健标准误差。第二个[方括号中]是聚类标准误差 (4.55)-(4.56),其中聚类处于学校级别。

我们可以看到,集群鲁棒标准误大约是传统鲁棒标准误的三倍。因此,系数的置信区间很大程度上受到选择的影响。
为了便于说明,我们在此列出了在 Stata、R 和 MATLAB 中生成具有聚类标准误差的回归结果所需的命令。
.jpg)
您可以看到,在 Stata 中计算聚类标准误差很简单。

由于方便的 rowsum 命令可以对簇内的变量进行求和,因此在 \(\mathrm{R}\) 中编程簇标准错误也相对容易。

在这里我们看到,在 MATLAB 中编程集群标准错误不如其他包方便,但仍然只需几行代码即可执行。此示例使用 Accumarray 命令,该命令类似于 \(\mathrm{R}\) 中的 rowsum 命令,但只能应用于向量(因此跨回归量的循环),并且如果 clusterid 变量是索引(这就是为什么原始 schoolid 变量是转换为 schoolidx 中的索引。这些命令的应用需要小心和注意。
4.22 使用聚类样本进行推理
在本节中,我们对计量经济学实践中的集群鲁棒推理给出一些警告性评论和一般性建议。直到最近,关于集群鲁棒性方法的特性的理论研究还非常少,因此这些言论可能很快就会过时。
在许多方面,聚类鲁棒推理应该被视为类似于异方差鲁棒推理,其中聚类鲁棒情况中的“聚类”被解释为类似于异方差鲁棒情况中的“观察”。特别是,有效样本大小应被视为簇的数量,而不是“样本大小”\(n\)。这是因为聚类稳健协方差矩阵估计器有效地将每个聚类视为单个观测值,并根据聚类均值的变化来估计协方差矩阵。因此,如果只有 \(G=50\) 簇,则推断应该被视为(最多)类似于使用 \(n=50\) 观测值进行异方差鲁棒推断。当回归量的数量很大(例如 \(k=20\) )时,这有点令人不安,因为协方差矩阵的估计将不精确。
此外,大多数集群鲁棒性理论(例如 Chris Hansen (2007) 的工作)都假设集群是同质的,包括集群大小都相同的假设。事实证明这是一个非常重要的简化。当违反这一点时(例如,当簇大小高度异质时),回归应被视为大致相当于具有极高异方差性的异方差情况。簇和的方差与簇大小成正比,因此如果簇大小是异质的,则簇和的方差也将是异质的。这对有限样本推理也有很大影响。当聚类异质时,聚类稳健推理类似于具有高度异方差观测的异方差稳健推理。
总而言之,如果簇 \(G\) 的数量很小,并且每个簇的观察数量变化很大,那么我们应该非常谨慎地解释推理语句。不幸的是,具有异构集群大小的小型 \(G\) 很常见。许多关于美国“州”级别数据集群的实证研究意味着有 50 或 51 个集群(哥伦比亚特区通常被视为一个州)。由于人口高度不平等,各州的观察数量差异很大。因此,当您阅读包含个人级别数据但聚集在“状态”级别的实证论文时,您应该谨慎并认识到这相当于使用少量极其异质的观察进行推断。
当我们对治疗感兴趣时,会出现进一步的并发症,如上一节给出的跟踪示例中所示。在许多情况下(包括 Duflo、Dupas 和 Kremer(2011)),人们感兴趣的是在集群层面(例如学校)应用治疗的效果。在许多情况下(然而,Duflo、Dupas 和 Kremer (2011) 除外),处理的簇数量相对于簇总数而言很小;在极端情况下,只有一个经过处理的簇。基于上面给出的推理,这些应用程序应该被解释为等价于第 4.16 节中讨论的稀疏虚拟变量的异方差鲁棒推理。正如那里所讨论的,标准误差估计可能会错误地小。在单个处理集群的极端情况下(在示例中,如果仅跟踪一所学校),则跟踪的估计系数将非常不精确地估计,但会具有误导性的小集群标准误差。一般来说,报告的标准误差会大大低估参数估计的不精确性。
4.23 在什么级别进行集群?
在集群鲁棒推理的背景下出现的一个实际问题是“我们应该在什么级别进行集群?”在某些示例中,您可以在非常精细的级别(例如家庭或教室)进行聚类,或者在更高的聚合级别(例如社区、学校、城镇、县或州)进行聚类。正确的聚类级别是什么?从业者一直倡导经验法则,但目前几乎没有正式的分析来提供有用的指导。我们知道什么?
首先,假设集群依赖性被忽略或施加得太细(例如,按家庭而不是村庄进行集群)。那么方差估计器将会有偏差,因为它们会忽略协方差项。由于相关性通常为正,这表明标准误差将太小,从而导致显着性和精度的虚假指示。
其次,假设集群依赖性被强加在过于聚合的措施上(例如,按州而不是村庄进行集群)。这不会造成偏见。但方差估计器将包含许多额外的分量,因此协方差矩阵估计器的精度会很差。这意味着,与聚类聚合程度较低相比,报告的标准误差将不精确,更加随机。
这些考虑表明,在通过集群鲁棒性方法估计协方差矩阵时,在偏差和方差之间存在权衡。根据当前的理论,根本不清楚该做什么。我强调这一点。我们真的不知道进行集群鲁棒推理的“正确”级别是什么。这是一个非常有趣的问题,当然应该通过计量经济学研究来探索。一个挑战是,在实证实践中,许多人观察到:“聚类很重要。无论我们是否聚类,标准误差都会发生很大变化。因此,我们应该只报告聚类标准误差。”这种推理的缺陷在于,我们不知道为什么在特定的经验示例中,标准误差在聚类下会发生变化。一种可能性是聚类减少了偏差,因此更加准确。另一种可能性是聚类增加了采样噪声,因此不太准确。事实上,这两个因素很可能都存在。
无论如何,研究人员应了解报告计算中使用的聚类数量,并应将聚类数量视为评估推论的有效样本量。例如,如果簇的数量为 \(G=20\),则应将其视为非常小的样本。
为了说明思想实验,请考虑 Duflo、Dupas 和 Kremer (2011) 的经验例子。他们报告了学校级别的标准误差,该应用程序使用了 111 所学校。因此 \(G=111\) 是有效样本量。观察对象(学生)的数量从 19 到 62 不等,相当均匀。这似乎是聚类方差估计的一个平衡良好的应用。然而,人们可以想象在不同的聚合级别上进行聚类。我们可能会考虑在不太聚合的级别(例如教室级别)进行聚类,但这在这个特定的应用程序中无法完成,因为每所学校只有一个教室。在此应用程序中,可以在“区域”级别上完成更聚合级别的集群。然而,只有9个区域。因此,如果我们按区域进行聚类,则 \(G=9\) 是有效样本大小,这将导致不精确的标准误差。在这个特定的例子中,学校层面的聚类(正如作者所做的那样)确实是谨慎的选择。
4.24 技术证明*
定理 \(\mathbf{4 . 4}\) 和 \(\mathbf{4 . 5}\) 的证明 定理 \(4.4\) 是一个特例,因此我们重点关注定理 4.5。该论点摘自 B. E. Hansen (2021)。
我们的方法是计算精心设计的参数模型的 Cramér-Rao 界限。这是基于 Newey(1990,附录 B)对人口预期的更简单背景的见解。
不失一般性,假设真实系数等于 \(\beta_{0}=0\) 和 \(\sigma^{2}=1\)。这些只是简化符号的标准化。还假设 \(\boldsymbol{Y}\) 具有联合密度 \(f(\boldsymbol{y})\)。通过使用 Radon-Nikodym 导数可以避免这种假设。
定义截断函数 \(\mathbb{R}^{n} \rightarrow \mathbb{R}^{n}\)
\[ \psi_{c}(\boldsymbol{y})=\boldsymbol{y} \mathbb{1}\left\{\left|\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{y}\right| \leq c\right\}-\mathbb{E}\left[\boldsymbol{Y} \mathbb{1}\left\{\left|\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{Y}\right| \leq c\right\}\right] . \]
请注意,它满足 \(\left|\psi_{c}(\boldsymbol{y})\right| \leq 2 c, \mathbb{E}\left[\psi_{c}(\boldsymbol{Y})\right]=0\),并且
\[ \mathbb{E}\left[\boldsymbol{Y} \psi_{c}(\boldsymbol{Y})^{\prime}\right]=\mathbb{E}\left[\boldsymbol{Y} \boldsymbol{Y}^{\prime} \mathbb{1}\left\{\left|\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{Y}\right| \leq c\right\}\right] \stackrel{\text { def }}{=} \Sigma_{c} . \]
作为 \(c \rightarrow \infty, \Sigma_{c} \rightarrow \mathbb{E}\left[\boldsymbol{Y} \boldsymbol{Y}^{\prime}\right]=\Sigma\)。选择足够大的\(c\),以便\(\Sigma_{c}>0\),这是可行的,因为\(\Sigma>0\)。
定义辅助关节密度函数
\[ f_{\beta}(\boldsymbol{y})=f(\boldsymbol{y})\left(1+\psi_{c}(\boldsymbol{y})^{\prime} \Sigma_{c}^{-1} \boldsymbol{X} \beta\right) \]
对于集合中的参数 \(\beta\)
\[ B=\left\{\beta \in \mathbb{R}^{m}:\|\beta\| \leq \frac{1}{2 c}\right\} . \]
边界意味着对于 \(\beta \in B\) 和所有 \(y\)
\[ \left|\psi_{c}(\boldsymbol{y})^{\prime} \Sigma_{c}^{-1} \boldsymbol{X} \beta\right|<1 . \]
这意味着 \(f_{\beta}\) 与 \(f\) 具有相同的支持度并且满足边界
\[ 0<f_{\beta}(y)<2 f(y) . \]
我们计算出
\[ \begin{aligned} \int f_{\beta}(\boldsymbol{y}) d \boldsymbol{y} &=\int f(\boldsymbol{y}) d \boldsymbol{y}+\int \psi_{c}(\boldsymbol{y})^{\prime} \Sigma_{c}^{-1} \boldsymbol{X} \beta f_{\beta}(\boldsymbol{y}) d \boldsymbol{y} \\ &=1+\mathbb{E}\left[\psi_{c}(\boldsymbol{Y})\right]^{\prime} \Sigma_{c}^{-1} \boldsymbol{X} \beta \\ &=1 \end{aligned} \]
最后一个等式是因为 \(\mathbb{E}\left[\psi_{c}(\boldsymbol{Y})\right]=0\)。总之,这些事实意味着 \(f_{\beta}\) 是一个有效的密度函数,并且 \(\beta \in B\) 是 \(\boldsymbol{Y}\) 的参数族。在位于 \(B\) 内部的 \(\beta_{0}=0\) 处进行评估,我们看到 \(f_{0}=f\)。这意味着 \(f_{\beta}\) 是一个正确指定的参数族,其参数值为 \(\beta_{0}\)。
让 \(\mathbb{E}_{\beta}\) 表示密度 \(f_{\beta}\) 下的期望。该模型中 \(\boldsymbol{Y}\) 的期望是
\[ \begin{aligned} \mathbb{E}_{\beta}[\boldsymbol{Y}] &=\int \boldsymbol{y} f_{\beta}(\boldsymbol{y}) d \boldsymbol{y} \\ &=\int \boldsymbol{y} f(\boldsymbol{y}) d \boldsymbol{y}+\int \boldsymbol{y} \psi_{c}(\boldsymbol{y})^{\prime} \Sigma_{c}^{-1} \boldsymbol{X} \beta f_{\beta}(\boldsymbol{y}) d \boldsymbol{y} \\ &=\mathbb{E}[\boldsymbol{Y}]+\mathbb{E}\left[\boldsymbol{Y} \psi_{c}(\boldsymbol{Y})^{\prime}\right] \Sigma_{c}^{-1} \boldsymbol{X} \beta \\ &=\boldsymbol{X} \beta \end{aligned} \]
因为 \(\mathbb{E}[\boldsymbol{Y}]=0\) 和 \(\mathbb{E}\left[\boldsymbol{Y}_{c}(\boldsymbol{Y})^{\prime}\right]=\Sigma_{c}\)。因此,模型 \(f_{\beta}\) 是一个线性回归,回归系数为 \(\beta\)。
界限 (4.61) 意味着
\[ \mathbb{E}_{\beta}\left[\|\boldsymbol{Y}\|^{2}\right]=\int\|\boldsymbol{y}\|^{2} f_{\beta}(\boldsymbol{y}) d \boldsymbol{y} \leq 2 \int\|\boldsymbol{y}\|^{2} f(\boldsymbol{y}) d \boldsymbol{y}=2 \mathbb{E}\left[\|\boldsymbol{Y}\|^{2}\right]=2 \operatorname{tr}(\Sigma)<\infty . \]
这意味着 \(f_{\beta}\) 对所有 \(\beta \in B\) 都有有限方差。
\(f_{\beta}\) 的似然得分为
\[ \begin{aligned} S &=\left.\frac{\partial}{\partial \beta} \log f_{\beta}(\boldsymbol{Y})\right|_{\beta=0} \\ &=\left.\frac{\partial}{\partial \beta} \log \left(1+\psi_{c}(\boldsymbol{Y})^{\prime} \Sigma_{c}^{-1} \boldsymbol{X} \beta\right)\right|_{\beta=0} \\ &=\boldsymbol{X}^{\prime} \Sigma_{c}^{-1} \psi_{c}(\boldsymbol{Y}) . \end{aligned} \]
信息矩阵为
\[ \begin{aligned} \mathscr{I}_{c} &=\mathbb{E}\left[S S^{\prime}\right] \\ &=\boldsymbol{X}^{\prime} \Sigma_{c}^{-1} \mathbb{E}\left[\psi_{c}(\boldsymbol{Y}) \psi_{c}(\boldsymbol{Y})^{\prime}\right] \Sigma_{c}^{-1} \boldsymbol{X} \\ & \leq \boldsymbol{X}^{\prime} \Sigma_{c}^{-1} \boldsymbol{X}, \end{aligned} \]
其中不等式是
\[ \mathbb{E}\left[\psi_{c}(\boldsymbol{Y}) \psi_{c}(\boldsymbol{Y})^{\prime}\right]=\Sigma_{c}-\mathbb{E}\left[\boldsymbol{Y} \mathbb{1}\left\{\left|\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{Y}\right| \leq c\right\}\right] \mathbb{E}\left[\boldsymbol{Y} \mathbb{1}\left\{\left|\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{Y}\right| \leq c\right\}\right]^{\prime} \leq \Sigma_{c} . \]
根据假设,估计器 \(\widetilde{\beta}\) 对于 \(\beta\) 是无偏的。模型 \(f_{\beta}\) 是正则的(它被正确指定,因为它包含真实密度 \(f\),\(Y\) 的支持不依赖于 \(\beta\),真实值 \(\beta_{0}=0\) 位于 \(B\) )。因此由 Cramér-Rao 定理(经济学家概率与统计定理 \(10.6\))
\[ \operatorname{var}[\widetilde{\beta}] \geq \mathscr{I}_{c}^{-1} \geq\left(\boldsymbol{X}^{\prime} \Sigma_{c}^{-1} \boldsymbol{X}\right)^{-1} \]
其中第二个不等式是 (4.62)。由于这对于所有 \(c\) 和 \(\Sigma_{c} \rightarrow \Sigma\) 以及 \(c \rightarrow \infty\) 都成立,
\[ \operatorname{var}[\widetilde{\beta}] \geq \limsup _{c \rightarrow \infty}\left(\boldsymbol{X}^{\prime} \Sigma_{c}^{-1} \boldsymbol{X}\right)^{-1}=\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1} . \]
这是方差下界。
4.25 练习
练习4.1 对于某个整数\(k\),设置\(\mu_{k}=\mathbb{E}\left[Y^{k}\right]\)。
为 \(\mu_{k}\) 构造一个估计器 \(\widehat{\mu}_{k}\)。
证明 \(\widehat{\mu}_{k}\) 对于 \(\mu_{k}\) 是无偏的。
计算 \(\widehat{\mu}_{k}\) 的方差,例如 \(\operatorname{var}\left[\widehat{\mu}_{k}\right]\)。需要什么假设才能使 \(\operatorname{var}\left[\widehat{\mu}_{k}\right]\) 是有限的?
提出 \(\operatorname{var}\left[\widehat{\mu}_{k}\right]\) 的估计量
练习 4.2 计算 \(\mathbb{E}\left[(\bar{Y}-\mu)^{3}\right]\),即 \(\bar{Y}\) 的偏度。什么情况下为零?
练习 4.3 解释 \(\bar{Y}\) 和 \(\mu\) 之间的区别。解释 \(n^{-1} \sum_{i=1}^{n} X_{i} X_{i}^{\prime}\) 和 \(\mathbb{E}\left[X_{i} X_{i}^{\prime}\right]\) 之间的区别
练习 4.4 对或错。如果 \(Y=X^{\prime} \beta+e, X \in \mathbb{R}, \mathbb{E}[e \mid X]=0\) 和 \(\widehat{e}_{i}\) 是 \(Y_{i}\) 对 \(X_{i}\) 回归的 OLS 残差,则 \(\sum_{i=1}^{n} X_{i}^{2} \widehat{e}_{i}=0\)。
练习 4.5 证明 (4.20) 和 (4.21)。
练习 4.6 在线性估计量的限制下证明定理 \(4.5\)。
练习 4.7 设 \(\widetilde{\beta}\) 为假设(4.18)和(4.19)下的 GLS 估计量(4.22)。假设 \(\Sigma\) 已知,而 \(\sigma^{2}\) 未知。定义残差向量 \(\widetilde{\boldsymbol{e}}=\boldsymbol{Y}-\boldsymbol{X} \widetilde{\beta}\) 和 \(\sigma^{2}\) 的估计器
\[ \widetilde{\sigma}^{2}=\frac{1}{n-k} \widetilde{\boldsymbol{e}}^{\prime} \Sigma^{-1} \widetilde{\boldsymbol{e}} \]
显示(4.23)。
显示(4.24)。
证明\(\widetilde{\boldsymbol{e}}=\boldsymbol{M}_{1} \boldsymbol{e}\),其中\(\boldsymbol{M}_{1}=\boldsymbol{I}-\boldsymbol{X}\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \Sigma^{-1}\)。
证明\(\boldsymbol{M}_{1}^{\prime} \Sigma^{-1} \boldsymbol{M}_{1}=\Sigma^{-1}-\Sigma^{-1} \boldsymbol{X}\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \Sigma^{-1}\)。 (e) 找到\(\mathbb{E}\left[\widetilde{\sigma}^{2} \mid \boldsymbol{X}\right]\)。
\(\widetilde{\sigma}^{2}\) 是 \(\sigma^{2}\) 的合理估计量吗?
练习 4.8 令 \(\left(Y_{i}, X_{i}\right)\) 为 \(\mathbb{E}[Y \mid X]=X^{\prime} \beta\) 的随机样本。考虑加权最小二乘 (WLS) 估计器 \(\widetilde{\beta}_{\text {wls }}=\left(\boldsymbol{X}^{\prime} \boldsymbol{W} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{W} \boldsymbol{Y}\right)\),其中 \(\boldsymbol{W}=\operatorname{diag}\left(w_{1}, \ldots, w_{n}\right)\) 和 \(w_{i}=X_{j i}^{-2}\),其中 \(X_{j i}\) 是 \(X_{i}\) 之一。
在什么情况下 \(\widetilde{\beta}_{\mathrm{wls}}\) 是一个好的估计器?
根据您的直觉,您预计 \(\widetilde{\beta}_{\text {wls }}\) 在哪些情况下会比 OLS 表现更好?
练习4.9 在同方差回归模型中显示(4.32)。
练习 4.10 证明 (4.40)。
练习4.11 在同方差回归模型中显示(4.41)。
练习 4.12 设 \(\mu=\mathbb{E}[Y], \sigma^{2}=\mathbb{E}\left[(Y-\mu)^{2}\right]\) 和 \(\mu_{3}=\mathbb{E}\left[(Y-\mu)^{3}\right]\) 并考虑样本均值 \(\bar{Y}=\) \(\frac{1}{n} \sum_{i=1}^{n} Y_{i}\)。求 \(\mathbb{E}\left[(\bar{Y}-\mu)^{3}\right]\) 作为 \(\mu, \sigma^{2}, \mu_{3}\) 和 \(n\) 的函数。
练习 4.13 采用简单回归模型 \(Y=X \beta+e, X \in \mathbb{R}, \mathbb{E}[e \mid X]=0\)。定义 \(\sigma_{i}^{2}=\mathbb{E}\left[e_{i}^{2} \mid X_{i}\right]\) 和 \(\mu_{3 i}=\mathbb{E}\left[e_{i}^{3} \mid X_{i}\right]\) 并考虑 OLS 系数 \(\widehat{\beta}\)。找到\(\mathbb{E}\left[(\widehat{\beta}-\beta)^{3} \mid \boldsymbol{X}\right]\)。
练习 4.14 使用 \(\mathbb{E}[e \mid X]=0\) 和独立同分布建立回归模型 \(Y=X \beta+e\)。观测值 \(\left(Y_{i}, X_{i}\right)\) 和标量 \(X\)。感兴趣的参数是 \(\theta=\beta^{2}\)。考虑 OLS 估计器 \(\widehat{\beta}\) 和 \(\widehat{\theta}=\widehat{\beta}^{2}\)。
使用我们对 \(\mathbb{E}[\widehat{\beta} \mid \boldsymbol{X}]\) 和 \(V_{\widehat{\beta}}=\operatorname{var}[\widehat{\beta} \mid \boldsymbol{X}]\) 的了解来找到 \(\mathbb{E}[\widehat{\theta} \mid \boldsymbol{X}]\)。 \(\widehat{\theta}\) 是否对 \(\theta\) 有偏差?
使用 \(V_{\widehat{\beta}}\) 的估计器 \(\widehat{V}_{\widehat{\beta}}\) 建议一个(近似)偏差校正估计器 \(\widehat{\theta}^{*}\)。
为了使 \(\widehat{\theta}^{*}\) 潜在无偏,\(V_{\widehat{\beta}}\) 的哪个估计量最合适?
在什么条件下\(\widehat{\theta}^{*}\)是无偏的?
练习 4.15 考虑一个独立同分布示例 \(\left\{Y_{i}, X_{i}\right\} i=1, \ldots, n\),其中 \(X\) 是 \(k \times 1\)。假设线性条件期望模型 \(Y=X^{\prime} \beta+e\) 和 \(\mathbb{E}[e \mid X]=0\)。假设 \(n^{-1} \boldsymbol{X}^{\prime} \boldsymbol{X}=\boldsymbol{I}_{k}\) (正交回归量)。考虑 OLS 估计器 \(\widehat{\beta}\)。
找到 \(\boldsymbol{V}_{\widehat{\beta}}=\operatorname{var}[\widehat{\beta}]\)
一般来说,\(\widehat{\beta}_{j}\) 和 \(\widehat{\beta}_{\ell}\) 与 \(j \neq \ell\) 相关还是不相关?
找到一个充分条件,使得 \(j \neq \ell\) 的 \(\widehat{\beta}_{j}\) 和 \(\widehat{\beta}_{\ell}\) 不相关。
练习4.16 求线性同方差CEF
\[ \begin{aligned} Y^{*} &=X^{\prime} \beta+e \\ \mathbb{E}[e \mid X] &=0 \\ \mathbb{E}\left[e^{2} \mid X\right] &=\sigma^{2} \end{aligned} \]
并假设 \(Y^{*}\) 的测量存在误差。我们观察的是 \(Y=Y^{*}+u\),而不是 \(Y^{*}\),其中 \(u\) 是测量误差。假设 \(e\) 和 \(u\) 是独立的并且
\[ \begin{aligned} \mathbb{E}[u \mid X] &=0 \\ \mathbb{E}\left[u^{2} \mid X\right] &=\sigma_{u}^{2}(X) \end{aligned} \]
导出 \(Y\) 的方程作为 \(X\) 的函数。明确地将误差项写为结构误差 \(e\) 和 \(u\) 的函数。该测量误差对模型 (4.63) 有什么影响?
描述在观察到的 \(Y\) 对 \(X\) 的可行回归中,该测量误差对 \(\beta\) 的 OLS 估计的影响。
描述该测量误差对 \(\widehat{\beta}\) 标准误差计算的影响(如果有)。
练习 4.17 假设对于随机变量 \((Y, X)\) 和 \(X>0\),经济模型意味着
\[ \mathbb{E}[Y \mid X]=(\gamma+\theta X)^{1 / 2} . \]
有朋友建议你通过\(Y^{2}\)对\(X\)的线性回归来估计\(\gamma\)和\(\theta\),即估计方程
\[ Y^{2}=\alpha+\beta X+e . \]
调查你朋友的建议。定义\(u=Y-(\gamma+\theta X)^{1 / 2}\)。表明 \(\mathbb{E}[u \mid X]=0\) 由 (4.64) 隐含。
使用 \(Y=(\gamma+\theta X)^{1 / 2}+u\) 计算 \(\mathbb{E}\left[Y^{2} \mid X\right]\)。关于隐含方程 (4.65),这告诉你什么?
你能从 (4.65) 的估计中恢复 \(\gamma\) 和/或 \(\theta\) 吗?是否需要额外的假设?
这个建议合理吗?
练习4.18 建立模型
\[ \begin{aligned} Y &=X_{1}^{\prime} \beta_{1}+X_{2}^{\prime} \beta_{2}+e \\ \mathbb{E}[e \mid X] &=0 \\ \mathbb{E}\left[e^{2} \mid X\right] &=\sigma^{2} \end{aligned} \]
其中 \(X=\left(X_{1}, X_{2}\right)\)、\(X_{1} k_{1} \times 1\) 和 \(X_{2} k_{2} \times 1\)。考虑短回归 \(Y_{i}=X_{1 i}^{\prime} \widehat{\beta}_{1}+\widehat{e}_{i}\) 并定义误差方差估计器 \(s^{2}=\left(n-k_{1}\right)^{-1} \sum_{i=1}^{n} \widehat{e}_{i}^{2}\)。找到 \(\mathbb{E}\left[s^{2} \mid \boldsymbol{X}\right]\)。
练习 4.19 令 \(\boldsymbol{Y}\) 为 \(n \times 1, \boldsymbol{X}\) 为 \(n \times k\) 和 \(\boldsymbol{X}^{*}=\boldsymbol{X} \boldsymbol{C}\),其中 \(\boldsymbol{C}\) 为 \(k \times k\) 并且是满秩的。令 \(\widehat{\beta}\) 为 \(Y\) 对 \(X\) 回归的最小二乘估计量,并令 \(\boldsymbol{Y}\) 为其渐近协方差矩阵的估计值。令 \(\boldsymbol{Y}\) 和 \(\boldsymbol{Y}\) 为 \(\boldsymbol{Y}\) 对 \(\boldsymbol{Y}\) 的回归结果。将 \(\boldsymbol{Y}\) 的表达式推导为 \(\boldsymbol{Y}\) 的函数。
练习 4.20 用向量表示法建立模型
\[ \begin{aligned} \boldsymbol{Y} &=\boldsymbol{X} \beta+\boldsymbol{e} \\ \mathbb{E}[\boldsymbol{e} \mid \boldsymbol{X}] &=0 \\ \mathbb{E}\left[\boldsymbol{e} \boldsymbol{e}^{\prime} \mid \boldsymbol{X}\right] &=\Sigma . \end{aligned} \]
为简单起见,假设 \(\Sigma\) 已知。考虑 OLS 和 GLS 估计器 \(\widehat{\beta}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \boldsymbol{Y}\right)\) 和 \(\widetilde{\beta}=\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{Y}\right)\)。计算 \(\widehat{\beta}\) 和 \(\widetilde{\beta}\) 之间的(条件)协方差:
\[ \mathbb{E}\left[(\widehat{\beta}-\beta)(\widetilde{\beta}-\beta)^{\prime} \mid \boldsymbol{X}\right] \]
求 \(\widehat{\beta}-\widetilde{\beta}\) 的(条件)协方差矩阵:
\[ \mathbb{E}\left[(\widehat{\beta}-\widetilde{\beta})(\widehat{\beta}-\beta)^{\prime} \mid \boldsymbol{X}\right] . \]
练习 4.21 模型是
\[ \begin{aligned} Y_{i} &=X_{i}^{\prime} \beta+e_{i} \\ \mathbb{E}\left[e_{i} \mid X_{i}\right] &=0 \\ \mathbb{E}\left[e_{i}^{2} \mid X_{i}\right] &=\sigma_{i}^{2} \\ \Sigma &=\operatorname{diag}\left\{\sigma_{1}^{2}, \ldots, \sigma_{n}^{2}\right\} . \end{aligned} \]
参数 \(\beta\) 由 OLS \(\widehat{\beta}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{Y}\) 和 GLS \(\widetilde{\beta}=\left(\boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\prime} \Sigma^{-1} \boldsymbol{Y}\) 估计。让 \(\widehat{\boldsymbol{e}}=\boldsymbol{Y}-\boldsymbol{X} \widehat{\beta}\) 和 \(\widetilde{\boldsymbol{e}}=\boldsymbol{Y}-\boldsymbol{X} \widetilde{\beta}\) 表示残差。让 \(\widehat{R}^{2}=1-\widehat{\boldsymbol{e}}^{\prime} \widehat{\boldsymbol{e}} /\left(\boldsymbol{Y}^{* \prime} \boldsymbol{Y}^{*}\right)\) 和 \(\widetilde{R}^{2}=1-\widetilde{\boldsymbol{e}}^{\prime} \widetilde{\boldsymbol{e}} /\left(\boldsymbol{Y}^{* \prime} \boldsymbol{Y}^{*}\right)\) 表示方程 \(R^{2}\),其中 \(\boldsymbol{Y}^{*}=\boldsymbol{Y}-\bar{Y}\)。如果错误 \(\beta\) 确实是异方差,那么 \(\beta\) 或 \(\beta\) 会更小吗?
练习 4.22 一位经济学家朋友告诉你,观测值 \(\left(Y_{i}, X_{i}\right)\) 是独立同分布的假设。意味着回归 \(Y=X^{\prime} \beta+e\) 是同方差的。你同意你朋友的观点吗?你会如何解释你的立场?
练习 4.23 使用 \(\mathbb{E}[\boldsymbol{Y} \mid \boldsymbol{X}]=\boldsymbol{X} \beta\) 建立线性回归模型。定义岭回归估计器
\[ \widehat{\beta}=\left(\boldsymbol{X}^{\prime} \boldsymbol{X}+\boldsymbol{I}_{k} \lambda\right)^{-1} \boldsymbol{X}^{\prime} \boldsymbol{Y} \]
其中 \(\lambda>0\) 是固定常数。找到\(E[\widehat{\beta} \mid \boldsymbol{X}]\)。 \(\widehat{\beta}\) 是否对 \(\beta\) 有偏差?
练习 4.24 继续练习 3.24 中的实证分析。
使用同方差公式和 \(4.14 .\) 节中的四个协方差矩阵计算标准误差
用第二种编程语言重复。它们相同吗?
练习 4.25 继续练习 3.26 中的实证分析。使用 HC3 方法计算标准误差。用您的第二种编程语言重复此操作。它们相同吗?
练习 4.26 使用教科书网站上的 DDK2011 数据集扩展 \(4.21\) 节中报告的实证分析。对跟踪、年龄、性别、分配给的标准化测试分数(总分数标准化为均值为零和方差 1)进行回归合同教师和学生在初始分配中的百分位数。 (由于某些观察缺少变量,样本量会较小。)使用传统的稳健公式和基于学校的聚类来计算标准误差。
比较两组标准误差。聚类后哪个标准误变化最大?哪个变化最小?
通过包含单独的控制,跟踪系数如何变化(与(4.60)的结果相比)?