| Year | Y | X1 | X2 | X3 | X4 | X5 | X6 |
|---|---|---|---|---|---|---|---|
| 1947 | 60323 | 830 | 234289 | 2356 | 1590 | 107608 | 1 |
| 1948 | 61122 | 885 | 259426 | 2325 | 1456 | 108632 | 2 |
| 1949 | 60171 | 882 | 258054 | 3682 | 1616 | 109773 | 3 |
| 1950 | 61187 | 895 | 284599 | 3351 | 1650 | 110929 | 4 |
| 1951 | 63221 | 962 | 328975 | 2099 | 3099 | 112075 | 5 |
| 1952 | 63639 | 981 | 346999 | 1932 | 3594 | 113270 | 6 |
| 1953 | 64989 | 990 | 365385 | 1870 | 3547 | 115094 | 7 |
| 1954 | 63761 | 1000 | 363112 | 3578 | 3350 | 116219 | 8 |
| 1955 | 66019 | 1012 | 397469 | 2904 | 3048 | 117388 | 9 |
| 1956 | 67857 | 1046 | 419180 | 2822 | 2857 | 118734 | 10 |
| 1957 | 68169 | 1084 | 442769 | 2936 | 2798 | 120445 | 11 |
| 1958 | 66513 | 1108 | 444546 | 4681 | 2637 | 121950 | 12 |
| 1959 | 68655 | 1126 | 482704 | 3813 | 2552 | 123366 | 13 |
| 1960 | 69564 | 1142 | 502601 | 3931 | 2514 | 125368 | 14 |
| 1961 | 69331 | 1157 | 518173 | 4806 | 2572 | 127852 | 15 |
| 1962 | 70551 | 1169 | 554894 | 4007 | 2827 | 130081 | 16 |
5 多重共线性问题
5.1 实验目的及要求
目的:掌握多重共线性的检验与处理方法。
要求:在老师指导下完成计量经济模型的多重共线性检验,并对存在多重共线性的模型进行修正,最终得到正确的分析结果。
5.2 实验原理
线性回归模型的解释变量不满足相互独立的基本假设前提下,如果模型的解释变量存在多重共线性,将导致最小二乘法得到的模型参数估计量非有效且方差变大,参数估计量经济含义不合理等。
5.2.1 什么是模型多重共线性?
\[ \begin{aligned} Y_i&=\beta_1+\beta_2X_{2i}+\beta_3X_{3i}+\cdots+\beta_kX_{ki}+u_i && \text{(PRM)} \end{aligned} \tag{5.1}\]
\[ \begin{aligned} Y_i&=\hat{\beta}_1+\hat{\beta}_2X_{2i}+\hat{\beta}_3X_{3i}+\cdots+\hat{\beta}_kX_{ki}+e_i && \text{(SRM)} \end{aligned} \tag{5.2}\]
定义 5.1 (多重共线性) 在多元线性回归模型中,各解释变量\(\{X_2,X_3,\cdots,X_k \}\)之间有交互相关,但又非完全相关的现象。正式地:
\[ \begin{aligned} \lambda_2X_{2i}+\lambda_3X_{3i}+\cdots+\lambda_kX_{ki}+v_i=0 \end{aligned} \tag{5.3}\]
其中,\(v_i\)为随机误差项。
我们称总体回归模型 式 5.1 存在多重共线性,此时\(\lambda_1;\lambda_2;\cdots;\lambda_k\)不全为0,且\(v_i \neq 0\)。
我们称总体回归模型 式 5.1 存在完全多重共线性,此时\(\lambda_1;\lambda_2;\cdots;\lambda_k\)不全为0,且\(v_i = 0\)。
如果模型出现多重共线性问题,在N-CLRM假设下,OLS估计量仍然是最优线性无偏估计量(BLUE):
只要不是完全共线性,在近似多重共线性的情形下,OLS估计量仍然是无偏的
只要不是完全共线性,在近似多重共线性的情形下,OLS估计量的方差一定是小的
多重共线性本质上是一种样本现象。即使总体中X变量间不存在共线性,由于抽样方法或小样本问题,也可能带来多重共线性问题
但是如果模型出现多重共线性问题,则往往会带来如下一些理论后果:
更大的方差和协方差,估计精度大大下降。(尽管OLS估计仍是BLUE)
参数估计置信区间变宽,系数的检验倾向于不显著。(即回归系数的t检验更倾向接受原假设H0,认为系数为零)
系数的t值倾向于统计上不显著,但判定系数\(R^2\)却会很高
0LS估计量及其标准误对数据的微小变化非常敏感
5.2.2 如何诊断模型多重共线性问题?
为了诊断样本回归模型 式 5.2 是否存在多重共线性问题,并判明其严重程度,我们一般可以采用如下的经验方法:
(1)主回归方程分析报告结果异常。根据样本回归模型 式 5.2 ,如果出现如下情形,我们认为回归方程结果异常,很有可能模型存在多重共线性问题:
主回归分析报告的\(R^2\)值高(大于0.8)
分析报告\(F^{\ast}\)检验显著
但不显著的\(t^\ast\)检验较多(多于回归系数个数的一半及以上)
(2)图形分析发现自变量之间存在明显相关关系。利用样本数据,我们可以分析得到自变量之间的相关系数矩阵和矩阵散点图,如果出现如下情形,我们认为回归方程结果异常,很有可能模型存在多重共线性问题:
相关系数矩阵发现高度线性相关(相关系数大于0.8)
散点图矩阵发现高度线性相关的数据分布模式
(3)分析检查辅助回归方程是否异常。首先构建主回归方程,然后分别构建回归元之间的辅助回归方程。如果出现如下情形,我们认为回归方程结果异常,很有可能模型存在多重共线性问题:
辅助回归方程的判定系数\(R^2_j\)大于主回归方程的判定系数\(R^2\)
辅助回归方程的方差膨胀因子:\(VIF_j\in[10,100]\)表明中度多重共线性;\(VIF_j\geq{100}\)表明严重多重共线性
辅助回归方程的的容忍度:\(TOL_j\in[0.01,0.1]\)表明中度多重共线性;\(TOL_j\leq{0.01}\)表明严重多重共线性
(4)利用回归系数方差分解法(Coefficient Variance Decomposition)。通过计算特征值(eigenvalues),进而得到病态数(\(K_j\))和方差分解比率\(VDP_j\),最后做出多重共线性的诊断结论:
若发现至少一个病态数 \(K_j \leq 0.001\),则表明存在严重多重共线性;
观察病态数最小时所对应的方差分解比率,如果有多个斜率系数的 \(VDP_j \geq 0.5\),则表明存在严重的多重共线性
定义 5.2 (多重共线性辅助回归方程) 为侦察多元回归模型是否存在多重共线性,构建关于自变量之间的一类线性回归方程。正式地,对于样本回归模型 式 5.2 ,我们可以构建得到如下多重共线性辅助回归方程:
\[ \begin{aligned} X_{2i}&=\hat{\alpha}_1+\cdots+\hat{\alpha}_jX_{ji}+\cdots+\hat{\alpha}_kX_{ki}+\epsilon_{2i} \\ &\vdots\\ X_{ji}&=\hat{\alpha}_1+\hat{\alpha}_2X_{2i}+\cdots+\hat{\alpha}_kX_{ki}+\epsilon_{ji} \\ &\vdots\\ X_{ki}&=\hat{\alpha}_1+\hat{\alpha}_2X_{2i}+\cdots+\hat{\alpha}_jX_{ji}+\cdots+\epsilon_{ki} \end{aligned} \tag{5.4}\]
对于样本回归模型 式 5.2 ,在普通最小二乘法下,我们可以证明:
\[ \begin{aligned} S^2_{\hat{\beta}_j}=\frac{\hat{\sigma}^2}{(n-1)S^2_{X_j}} \cdot \frac{1}{1-R^2_j} \end{aligned} \tag{5.5}\]
其中\(R^2_j\)为辅助回归方程 式 5.4 的判定系数。\(S^2_{X_j}\)为变量\(X_j\)的样本方差。
定义 5.3 (方差膨胀因子和容忍度) 用来度量在最小二乘法下,多元线性回归模型的多重共线性问题严重程度的两个指标。
具体地,方差膨胀因子表达为单独一个变量对模型估计方差贡献的比率,一般记为VIF(variance-inflation factor),并正式定义为:
\[ \begin{aligned} VIF_j= \frac{1}{1-R^2_j} \end{aligned} \tag{5.6}\]
容忍度是方差膨胀因子的倒数,一般记为TOL(tolerrance),并正式定义为:
\[ \begin{aligned} TOl_j= {1-R^2_j} \end{aligned} \tag{5.7}\]
根据多元回归分析的矩阵方法实现(第@ref(matrix-regression)章),对于多元回归模型
\[ \begin{aligned} Y_i&=\beta_1+\beta_2X_{2i}+\beta_3X_{3i}+\cdots+\beta_kX_{ki}+u_i \end{aligned} \tag{5.8}\]
\[ \begin{aligned} \mathbf{y} &= \mathbf{X}\mathbf{\beta}+\mathbf{u} && \text{(PRM)} \end{aligned} \tag{5.9}\]
\[ \begin{aligned} \mathbf{y} &= \mathbf{X}\mathbf{\hat{\beta}}+\mathbf{e} && \text{(SRM)} \end{aligned} \tag{5.10}\]
可以得到OLS下参数估计的方差协方差矩阵:
\[ \begin{aligned} var-cov(\mathbf{\hat{\beta}}) = \sigma^2\mathbf{(X'X)}^{-1} = \sigma^2\mathbf{VD^{-1}V'} \end{aligned} \tag{5.11}\]
其中,\(\mathbf{D}\)是含有矩阵\(\mathbf{(X'X)^{-1}}\)的特征值(eigenvalues)\(E_m\)(\(m \in 1,2,\cdots,k\))的一个对角矩阵,而\(\mathbf{V}\)是由相应特征向量构成的一个矩阵。
定义 5.4 (病态数和方差分解比率) 用来诊断多元线性回归模型的多重共线性问题严重程度的一个指标。
具体地,病态数(condition number)采用微分的方法,考察引入一个变量对(多重共线性)模型结果恶化情形出现的相对改变数,一般记为K,并正式定义为:
\[ \begin{aligned} K_j&= \frac{min(E_m)}{E_j} \end{aligned} \tag{5.12}\]
方差分解比率(variance-decomposition proportion),一般记为\(VDP_{ji}\),并正式定义为:
\[ \begin{aligned} \phi_{ij}&=\frac{v^2_{ij}}{E_j}\\ VDP_{ji}&= \frac{\phi_{ij}}{\phi_i} \\ \end{aligned} \tag{5.13}\]
其中\(v_{ij}\)为矩阵\(\mathbf{V}\)的第\((i,j)\)个元素。
5.2.3 如何修正模型多重共线性问题?
一旦发现模型存在比较严重的多重共线性问题,则需要对模型进行修正处理,具体方法可参考:
(1)简单剔除变量法:
依据经济学和实践经验观察,进行变量甄选或变量变换
变量变换法,进行变量处理。具体又包括差分变换法、比率变换法
(2)逐步回归法:包括前向逐步回归(forward stepwise)和后向逐步回归(backward stepwise)
p值判别法:\(p\in[0.1,0.05)\)(比较显著);\(p\in[0.05,0.01)\)(比较显著);\(p\leq 0.01\)(极其显著)
\(t^{\ast}\)值判别法:2t法则
(3)补充新数据(有时候有用!)。由于多重共线性是一个样本特性,故有可能在关于同样变量的另一样本中共线性没有第一个样本那么严重
(4)多项式回归模型中离差形式或正交多项式(orthogonal polynomials)以降低共线性的影响。多项式回归模型的一个特点是解释变量以不同的幂出现,从而容易导致多重共线性
(5)矫正多重共线性问题的其他方法
脊回归或岭回归(ridge regression),常被用来”解决”多重共线性问题。
主成分分析法。先根据主成分分析确定主成分个数(看累积解释百分比),再用主成分得分(scoring)序列进行回归分析。
5.3 实验内容
(1)采用最小二乘法建立主回归模型。
(2)侦查模型是否存在多重共线性。
观察主回归方程分析报告:建立主回归方程,分析回归报告结果。主回归分析报告的\(R^2\)值高(大于0.8),\(F^{\ast}\)检验显著,但不显著的\(t^\ast\)检验较多(多于回归系数个数的一半及以上)
矩阵相关系数和矩阵散点图:绘制回归元之间的相关系数矩阵和散点图矩阵。相关系数矩阵发现高度线性相关(相关系数大于0.8),以及散点图矩阵发现高度线性相关的数据分布模式。
分析辅助回归方程:首先构建主回归方程,然后分别构建回归元之间的辅助回归方程。辅助回归方程的判定系数\(R^2_j\)大于主回归方程的判定系数\(R^2\)。辅助回归方程的方差膨胀因子\(VIF_j\in[10,100]\)表明中度多重共线性,\(VIF_j\geq{100}\)表明严重多重共线性。辅助回归方程的的容忍度\(TOL_j\in[0.01,0.1]\)表明中度多重共线性,\(TOL_j\leq{0.01}\)表明严重多重共线性。
主成分分析法(principal components):计算特征值(eigenvalues),进而得到病态数(\(K\))和病态指数\(CI=\sqrt{k}\)。病态数:\(K \in[100,1000]\)表明中度多重共线性;\(K \geq{1000}\)表明严重多重共线性。病态指数:\(CI \in[10,30]\)表明中度多重共线性;\(CI \geq{30}\)表明严重多重共线性
(3)根据上述对多重共线性的诊断,对模型进行合理修正。
简单剔除变量法:依据经济学和实践经验观察,进行变量甄选或变量变换
逐步回归法:包括前向逐步回归(forward stepwise)和后向逐步回归(backward stepwise) 。采用p值判别法,若\(p\in[0.1,0.05)\),比较显著;若\(p\in[0.05,0.01)\),比较显著;若\(p\leq 0.01\),极其显著。也可以采用\(t^{\ast}\)值判别法,也即2t法则。
补充新数据(有时候有用!)。由于多重共线性是一个样本特性,故有可能在关于同样变量的另一样本中共线性没有第一个样本那么严重。
多项式回归模型中离差形式或正交多项式(orthogonal polynomials)以降低共线性的影响。多项式回归模型的一个特点是解释变量以不同的幂出现,从而容易导致多重共线性
拯救多重共线性的其他方法。包括脊回归(ridge regression)和主成分分析法。
5.4 实验准备
5.4.1 实验软件
本次实验需要提前准备好如下软件:
统计分析软件Eviews 9.0版本及以上
公式编辑软件Mathtype 6.0版本及以上
写作编辑软件Office Word/Excel 2010版本及以上
浏览器软件chrome 66.0版本及以上或 360极速浏览器9.5版本及以上
5.4.2 实验材料
就业情况的郎利数据: 表 5.1 给出美国1947-1961年间就业情况及主要影响因素的数据表。
变量说明见 表 5.2 :
| variable | label |
|---|---|
| Year | 年份 |
| Y | 就业人数(打) |
| X1 | 消费价格指数 |
| X2 | 名义GNP |
| X3 | 失业人数 |
| X4 | 军队人数 |
| X5 | 14岁以上的非机构人口数 |
| X6 | 时间趋势 |
5.4.3 实验规则
本实验将要求保留Eviews操作过程的相关结果,因此对Eviews对象命名规则设计如下:
(1)方程对象(Equation) 的命名规则:
的命名规则:
主回归方程对象保存命名为
eq_m0辅助回归方程对象依次保存命名为
eq_a1、eq_a2、eq_a3、eq_a4、eq_a5、eq_a6用经济学和实践经验删除变量来矫正模型,新方程保存并命名为
eq_adj_man用逐步回归方法来矫正模型,新方程保存并命名为
eq_adj_step
(2)向量对象(Vector) 的命名规则:
的命名规则:
构造含有6个元素的向量对象,用于存放6个辅助回归方程的判定系数,并命名为
r2构造含有6个元素的向量对象,用于存放6个辅助回归方程计算得到的方差膨胀因子,并命名为
vif构造含有6个元素的向量对象,用于存放6个辅助回归方程计算得到的容忍度,并命名为
tol
(4)表格对象(Table) 的命名规则:
的命名规则:
自变量的相关系数矩阵保存为表格对象,并命名为:
tab_cor回归系数方差分解结果保存为表格对象,并命名为:
tab_cvd
5.5 主要实验步骤
5.5.1 新建工作文件并导入数据
目标:构建工作文件,成功导入数据
思路:利用EViews代码创建工作文件并导入数据。
Eviews操作:
(1)新建Eviews工作文件(见 @fig-load-wage )
提示
首先,依次操作:File\(\Rightarrow\)New\(\Rightarrow\)Workfile
然后,进行workfile create引导设置:
workfile structure type:
unstructured/undatededata range:16
workfile names(optional):
WF:
longley(建议命名)Page:
employee(建议命名)
(2)导入外部xlsx数据
提示
首先,处理Excel数据。
然后,Eviews导入数据。
File\(\Rightarrow\)Import\(\Rightarrow\)Import From File:d:\github\books\data\Lab5-longley-short-origin.xlsx
提示
通过运行EViews代码,也可以实现上述操作。在命令视窗中依次输入并运行如下EViews代码:
******
'创建工作文件(工作文件名=longley,子页命名=employee),无结构无日期,样本数为16
`wfcreate(wf=longley, page=employee) u 16`
******
'导入外部数据,路径为`d:\\github\\books\\data\\Lab5-longley-short-origin.xlsx`
`import d:\\github\\books\\data\\Lab5-longley-short-origin.xlsx`5.5.2 采用最小二乘法建立主回归模型
Eviews操作目标:得到回归方程,查看回归结果
思路:构建回归方程对象。回归模型为:
\[ \begin{aligned} \begin{split} Y_i=&+\beta_{1}+\beta_{2}X1_i+\beta_{3}X2_i+\beta_{4}X3_i\\&+\beta_{5}X4_i+\beta_{6}X5_i+\beta_{7}X6_i+u_i \end{split} \end{aligned} \tag{5.14}\]
Eviews操作:构建主回归方程
(1)进入方程估计的引导界面。
- EViews主窗口上依次点击点
Quick\(\Rightarrow\)Estimation Equation
(2)完成方程估计的引导设置。
设置方程。
Equation Estimation\(\Rightarrow\)Specification\(\Rightarrow\)Equation specification中依次输入变量y c x1 x2 x3 x4 x5 x6(注意变量之间的空格,以及截距c)选择估计方程。
Estimation settings中的Method下拉框 \(\Rightarrow\) 下拉选择LS - Least Squares (NLS and ARMA)完成设置,点击
OK
(3)命名并保存回归方程。
- 在未命名的方程对象
UNTITLED视窗下,点击菜单栏Name\(\Rightarrow\) 输入命名eq_m0(建议命名) \(\Rightarrow\) 完成命名,点击Ok
在工作文件视窗下,可以看到如下新生成的方程对象,可以双击查看eq_m0(见 图 5.1 ):
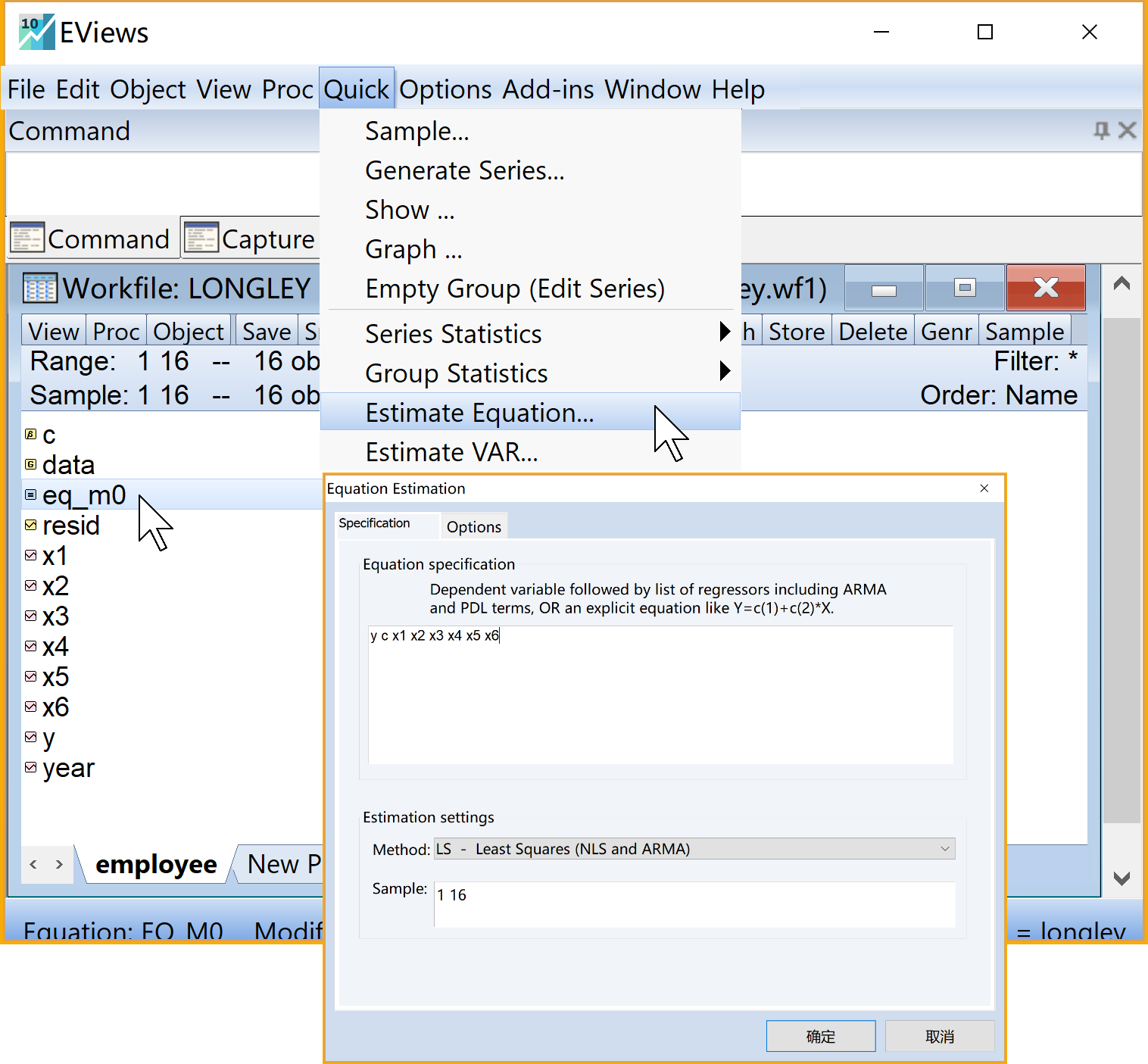
回归方程结果见 图 5.2 :
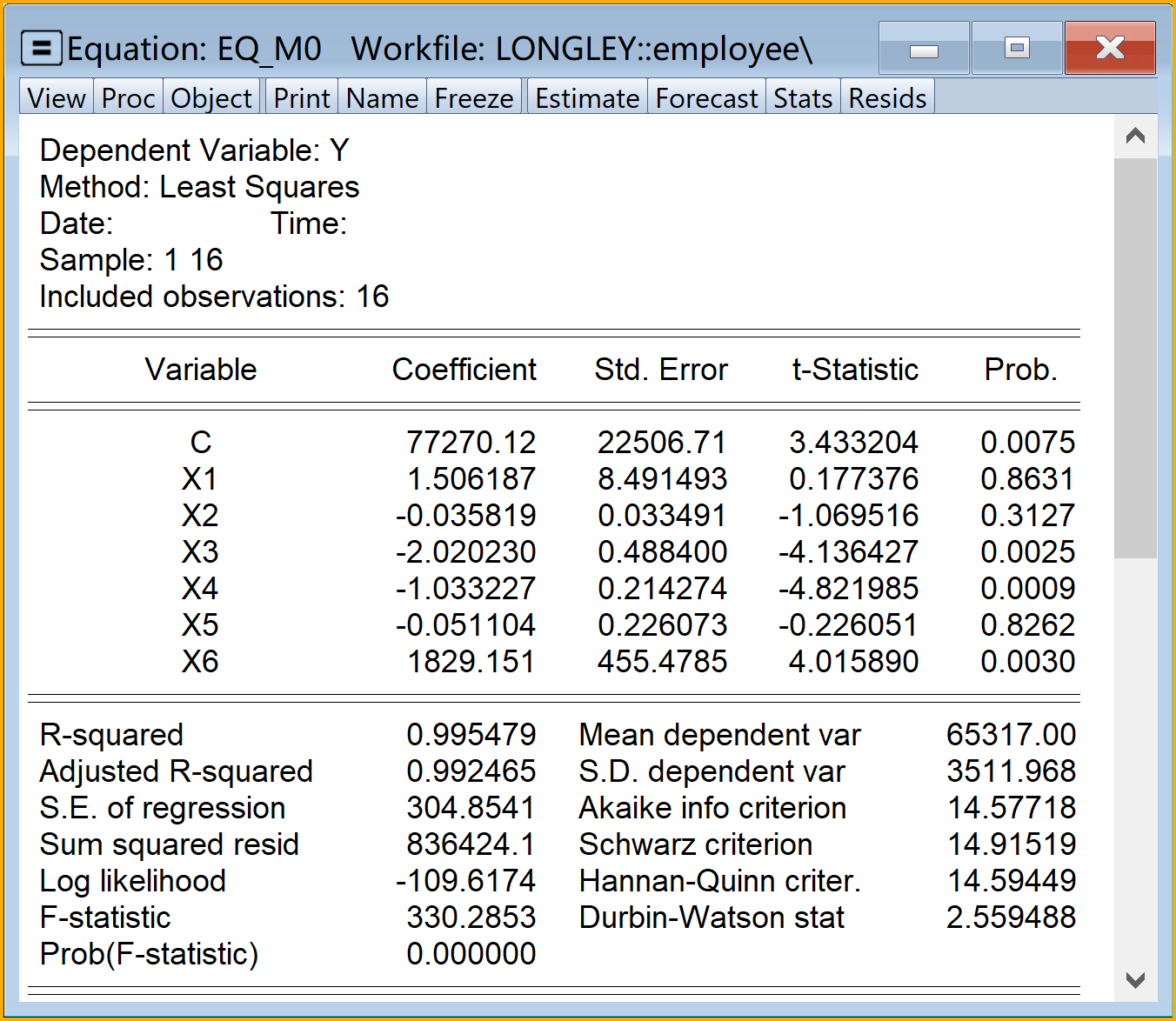
提示
通过运行EViews代码,也可以实现上述操作。在命令视窗中依次输入并运行如下EViews代码:
****
`'生成线性回归模型的方程对象`
`equation eq_m0.ls y c x1 x2 x3 x4 x5 x6`5.5.3 侦查多重共线性
5.5.3.1 主回归方程报告观察法
目标:观察\(t^{\ast}\)检验,判定系数\(R^2\),\(F^{\ast}\)检验的关系
思路:观察主回归分析报告的相关指标,诊断的标准如下:
\(R^2\)值高(大于0.8)
\(F^{\ast}\)检验显著
不显著的\(t^\ast\)检验较多(斜率系数个数的一半及以上)
郎利数据案例中,根据EViews回归结果(见 图 5.2 ),可以整理成简要回归报告如下:
\[ \begin{aligned} \begin{split} \widehat{Y}_i=&+\hat{\beta}_{1}+\hat{\beta}_{2}X1_i+\hat{\beta}_{3}X2_i+\hat{\beta}_{4}X3_i\\&+\hat{\beta}_{5}X4_i+\hat{\beta}_{6}X5_i+\hat{\beta}_{7}X6_i \end{split} \end{aligned} \tag{5.15}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{Y}=&&+77270.12&&+1.51X1_i&&-0.04X2_i&&-2.02X3_i\\ &(s)&&(22506.7070)&&(8.4915)&&(0.0335)&&(0.4884)\\ &(t)&&(+3.43)&&(+0.18)&&(-1.07)&&(-4.14)\\ &(cont.)&&-1.03X4_i&&-0.05X5_i&&+1829.15X6_i &&\\ &(s)&&(0.2143)&&(0.2261)&&(455.4785) &&\\ &(t)&&(-4.82)&&(-0.23)&&(+4.02) &&\\ &(over)&&n=16&&\hat{\sigma}=304.8541 && &&\\ &(fit)&&R^2=0.9955&&\bar{R}^2=0.9925 && &&\\ &(Ftest)&&F^*=330.29&&p=0.0000 && && \end{split} \end{alignedat} \tag{5.16}\]
显然,在\(\alpha=0.05\)水平下t检验结论见 表 5.3:
| 回归元 | 回归系数 | 标准误 | t统计量 | p值 | 显著性结论 |
|---|---|---|---|---|---|
| (Intercept) | 77270.115 | 22506.707 | 3.43 | 0.0075 | |
| X1 | 1.506 | 8.492 | 0.18 | 0.8631 | 不显著 |
| X2 | -0.036 | 0.034 | -1.07 | 0.3127 | 不显著 |
| X3 | -2.020 | 0.488 | -4.14 | 0.0025 | |
| X4 | -1.033 | 0.214 | -4.82 | 0.0009 | |
| X5 | -0.051 | 0.226 | -0.23 | 0.8262 | 不显著 |
| X6 | 1829.151 | 455.478 | 4.02 | 0.0030 |
根据主回归报告(见 图 5.2 和方程 式 5.15 ),下列证据将表明模型可能存在严重的多重共线性问题:
判定系数\(R^2=0.9955\),表明样本回归线拟合较好
\(F^{\ast}=330.29\),对应的概率值\(p=0.0000\),表明F检验极显著
斜率系数\(t^\ast\)检验不显著的有3个(主模型全部斜率系数共有6个),分别是X1、X2、X5。
5.5.3.2 矩阵相关系数和矩阵散点图
目标:观察\(t^{\ast}\)检验,判定系数\(R^2\),\(F^{\ast}\)检验的关系
思路:得到回归元之间的相关系数表,绘制它们的散点矩阵图。分析图表是否存在如下特征:
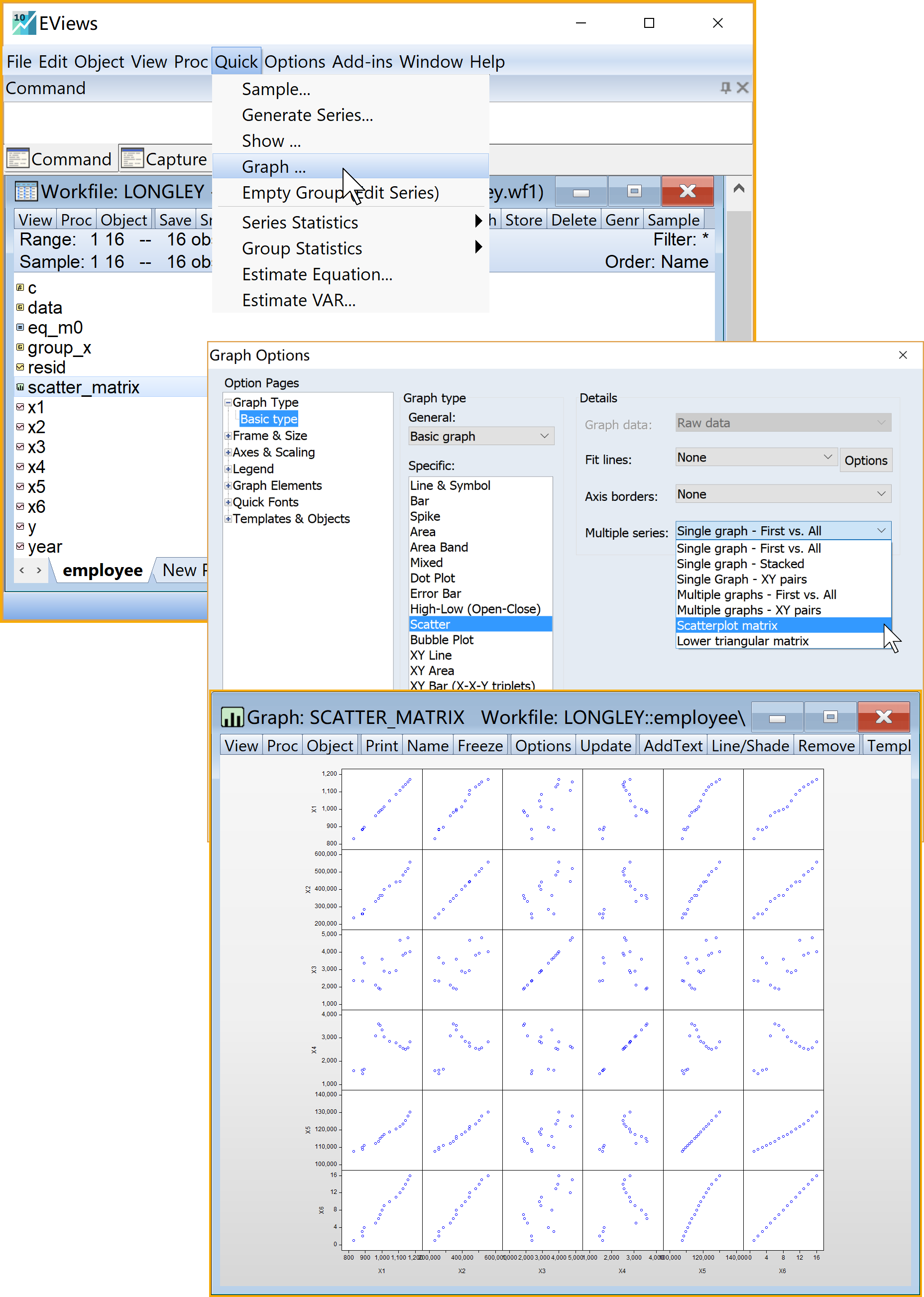
散点图矩阵发现高度线性相关的数据分布模式
相关系数矩阵发现高度线性相关(相关系数大于0.8)
Eviews菜单操作:
(1)构造X数据的组对象(group):
依次选择X变量:X1,X2,X3,X4,X5,X6
以组对象打开,鼠标右键:Open as group
命名并保存组对象:name(建议命名为
group_x)
(2)绘制散点图矩阵
进入group视窗:双击打开组对象
group_x进入引导菜单:\(\Rightarrow\) View \(\Rightarrow\) Graph
- 选择绘图类型(Graph type):Scatter
- 选择绘图细节(Detail):Multiple series \(\Rightarrow\) 下拉框选中Scatterplot matrix
点击完成:OK
命名并保存绘图(graph)对象
 :(建议命名为scatter_matrix)
:(建议命名为scatter_matrix)查看结果:双击
scatter_matrix (见 图 5.3 )
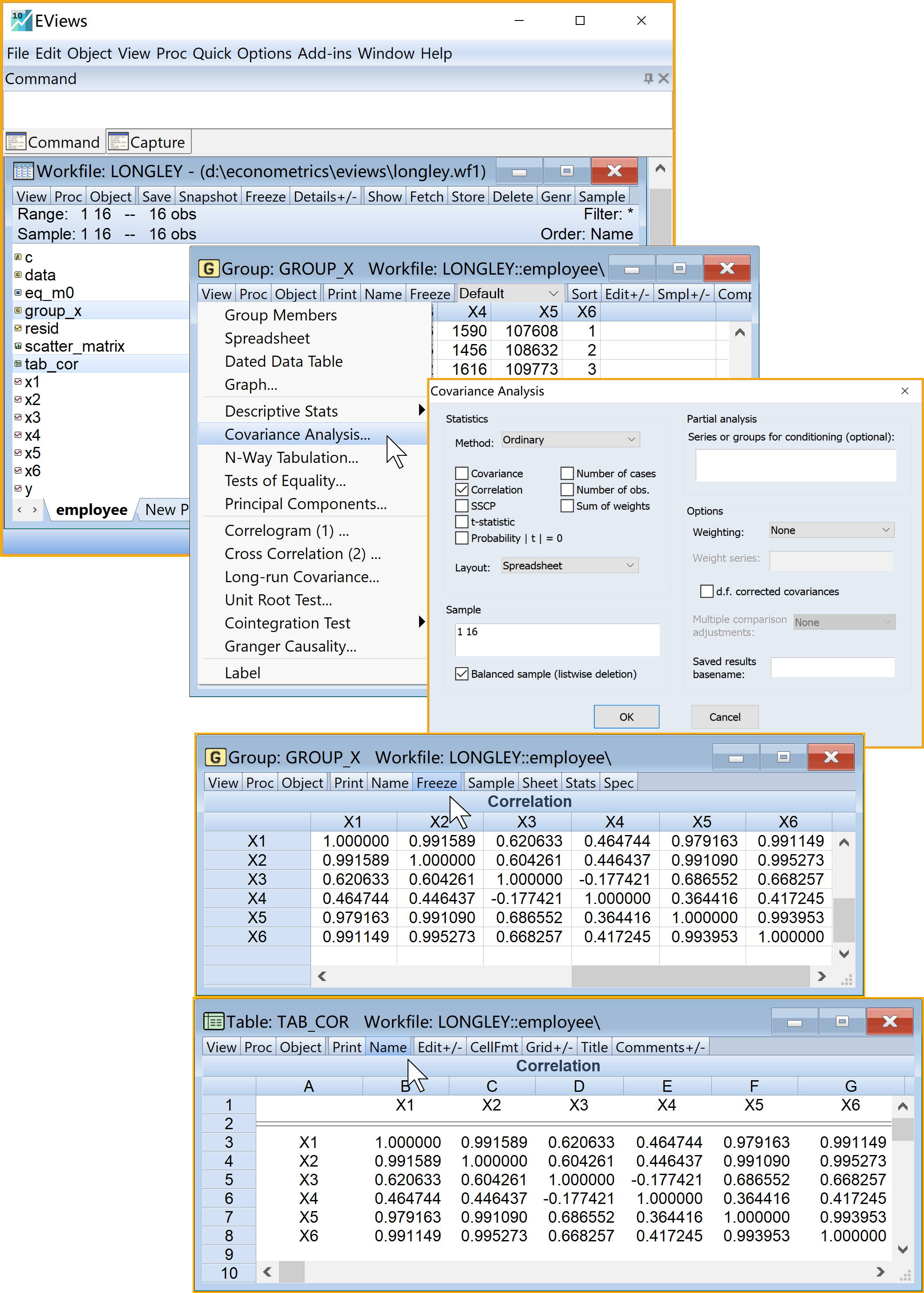
(3)制作得到相关系数矩阵表格(table)
进入group视窗:双击打开组(group)对象
 group_x
group_x进入引导菜单:\(\Rightarrow\) View \(\Rightarrow\) Covariance Analysis
- 选择分析类型(Statistics):只勾选Correlation
- 其他设置细节:(默认设置)
- 点击完成:OK
将上述组(group)对象
group_x另存为表格(table)对象- 另存为表格(table)对象:点击Freeze
- 命名并保存表格(table)对象:点击name(建议为tab_cor)
查看结果:双击
tab_cor (见 图 5.4 )
提示
通过运行EViews代码,也可以实现上述操作。在命令视窗中依次输入并运行如下EViews代码:
****
`'多重共线性诊断:计算自变量的相关系数表格和散点矩阵图`
`group varx x1 x2 x3 x4 x5 x6 '构建只含X的group`
`freeze(tab_cor) varx.cor '把group的相关系数矩阵表视图保存为表格`
`graph scatter_matrix.scatmat varx '绘制散点矩阵图`
| X1 | X2 | X3 | X4 | X5 | X6 | |
|---|---|---|---|---|---|---|
| X1 | 1.00 | |||||
| X2 | 0.99 | 1.00 | ||||
| X3 | 0.62 | 0.60 | 1.00 | |||
| X4 | 0.46 | 0.45 | -0.18 | 1.00 | ||
| X5 | 0.98 | 0.99 | 0.69 | 0.36 | 1.00 | |
| X6 | 0.99 | 1.00 | 0.67 | 0.42 | 0.99 | 1 |
根据相关系数矩阵表( 图 5.3)和散点矩阵图( 图 5.4 ),我们发现有6对X变量呈现明显线性相关关系,分别是:
X1 VS X2:\(r_{2,1}\)=0.9916
X1 VS X5:\(r_{5,1}\)=0.9792
X1 VS X6:\(r_{6,1}\)=0.9911
X2 VS X5:\(r_{5,2}\)=0.9911
X2 VS X6:\(r_{6,2}\)=0.9953
X5 VS X6:\(r_{6,5}\)=0.994
5.5.3.3 构建辅助回归方程
目标:构建并得到6个辅助回归方程及其Eviews报告。
思路:分别构建一个X变量对其他X变量的线性回归,共会得到6个辅助回归方程的Eviews报告。
定义 5.5 (主模型和辅助模型) 主回归模型(Main Model)是指Y变量对全部X变量的线性回归。
辅助回归模型(Auxiliary Model)是指一个X变量对其他X变量的线性回归。
\[ \begin{aligned} Y_t & = \hat{\beta}_0+\hat{\beta}_1X_{1t}+\hat{\beta}_2X_{2t}+\hat{\beta}_3X_{3t}+\hat{\beta}_4X_{4t}+\hat{\beta}_5X_{5t}+\hat{\beta}_6X_{6t}+e_{t} && \text{( M0 )} \end{aligned} \tag{5.17}\]
\[ \begin{aligned} X_{1t}& = \hat{\alpha}_0+\hat{\alpha}_2X_{2t}+\hat{\alpha}_3X_{3t}+\hat{\alpha}_4X_{4t}+\hat{\alpha}_5X_{5t}+\hat{\alpha}_6X_{6t}+e_{t} && \text{( A1 )} \end{aligned} \tag{5.18}\]
\[ \begin{aligned} X_{2t}& = \hat{\alpha}_0+\hat{\alpha}_1X_{1t}+\hat{\alpha}_3X_{3t}+\hat{\alpha}_4X_{4t}+\hat{\alpha}_5X_{5t}+\hat{\alpha}_6X_{6t}+e_{t} && \text{( A2 )} \end{aligned} \tag{5.19}\]
\[ \begin{aligned} X_{3t}& = \hat{\alpha}_0+\hat{\alpha}_1X_{1t}+\hat{\alpha}_2X_{2t}+\hat{\alpha}_4X_{4t}+\hat{\alpha}_5X_{5t}+\hat{\alpha}_6X_{6t}+e_{t} && \text{( A3 )} \end{aligned} \tag{5.20}\]
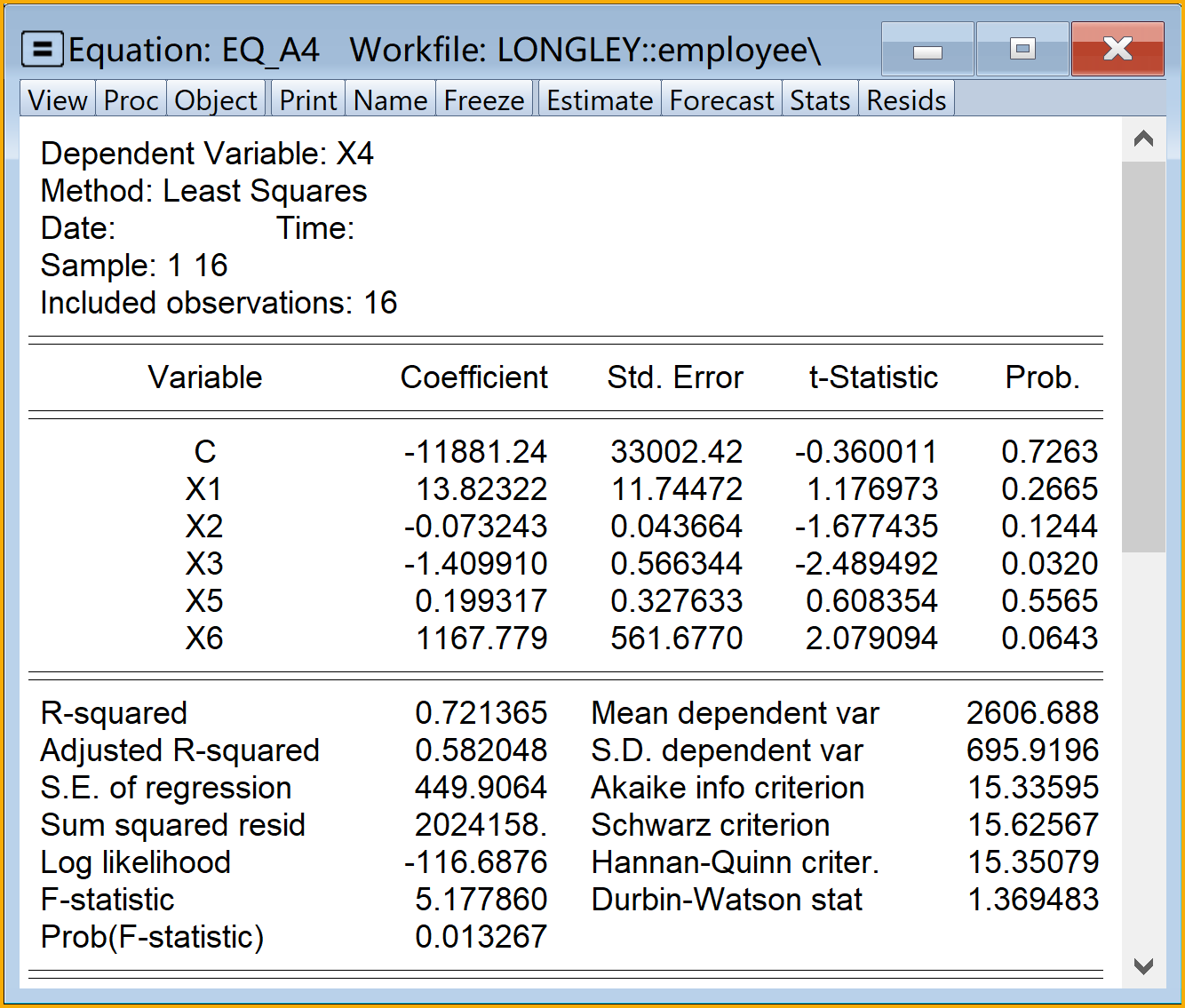
\[ \begin{aligned} X_{4t}& = \hat{\alpha}_0+\hat{\alpha}_1X_{1t}+\hat{\alpha}_2X_{2t}+\hat{\alpha}_3X_{3t}+\hat{\alpha}_5X_{5t}+\hat{\alpha}_6X_{6t}+e_{t} && \text{( A4 )} \end{aligned} \tag{5.21}\]
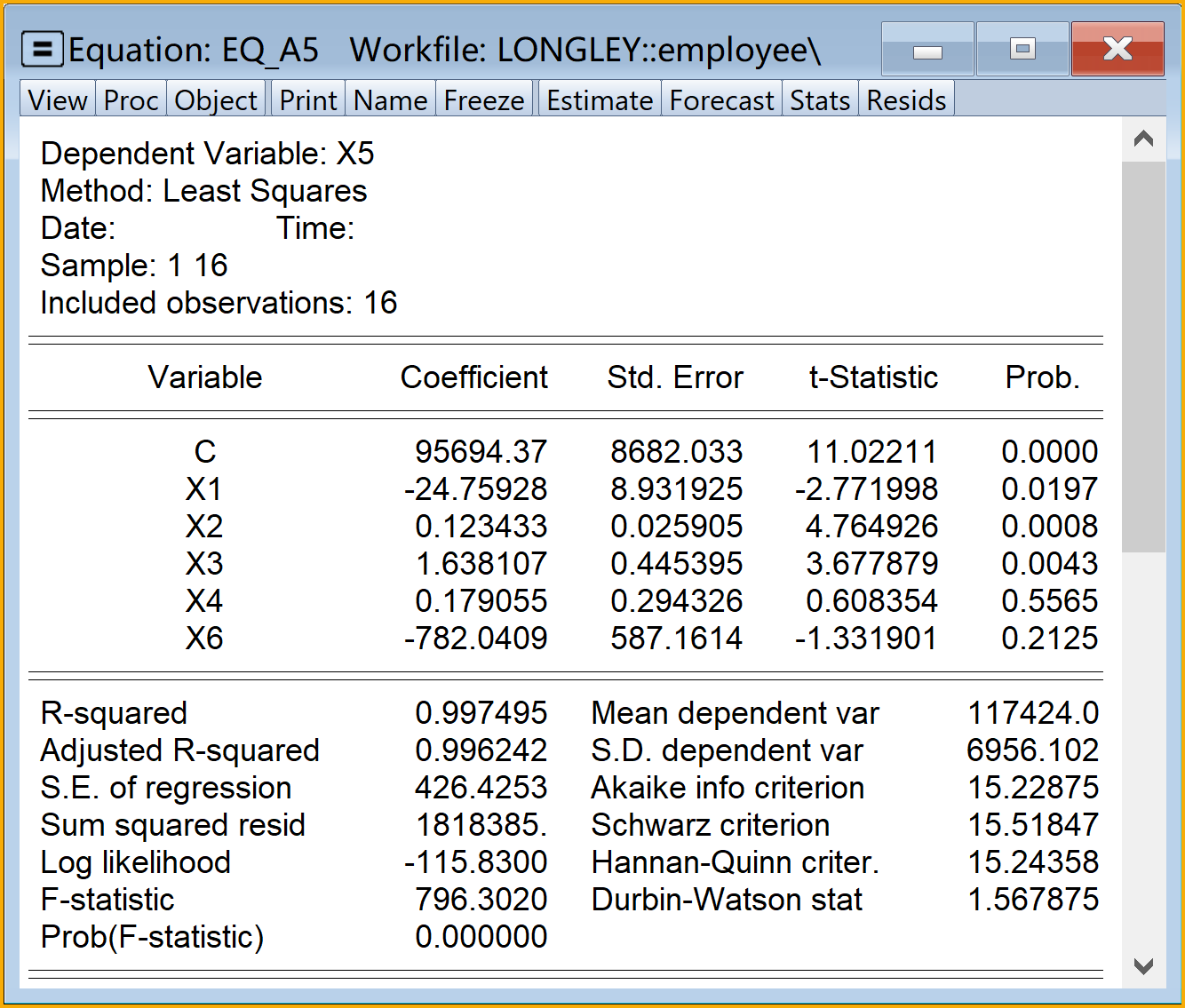
\[ \begin{aligned} X_{5t}& = \hat{\alpha}_0+\hat{\alpha}_1X_{1t}+\hat{\alpha}_2X_{2t}+\hat{\alpha}_3X_{3t}+\hat{\alpha}_4X_{4t}+\hat{\alpha}_6X_{6t}+e_{t} && \text{( A5 )} \end{aligned} \tag{5.22}\]
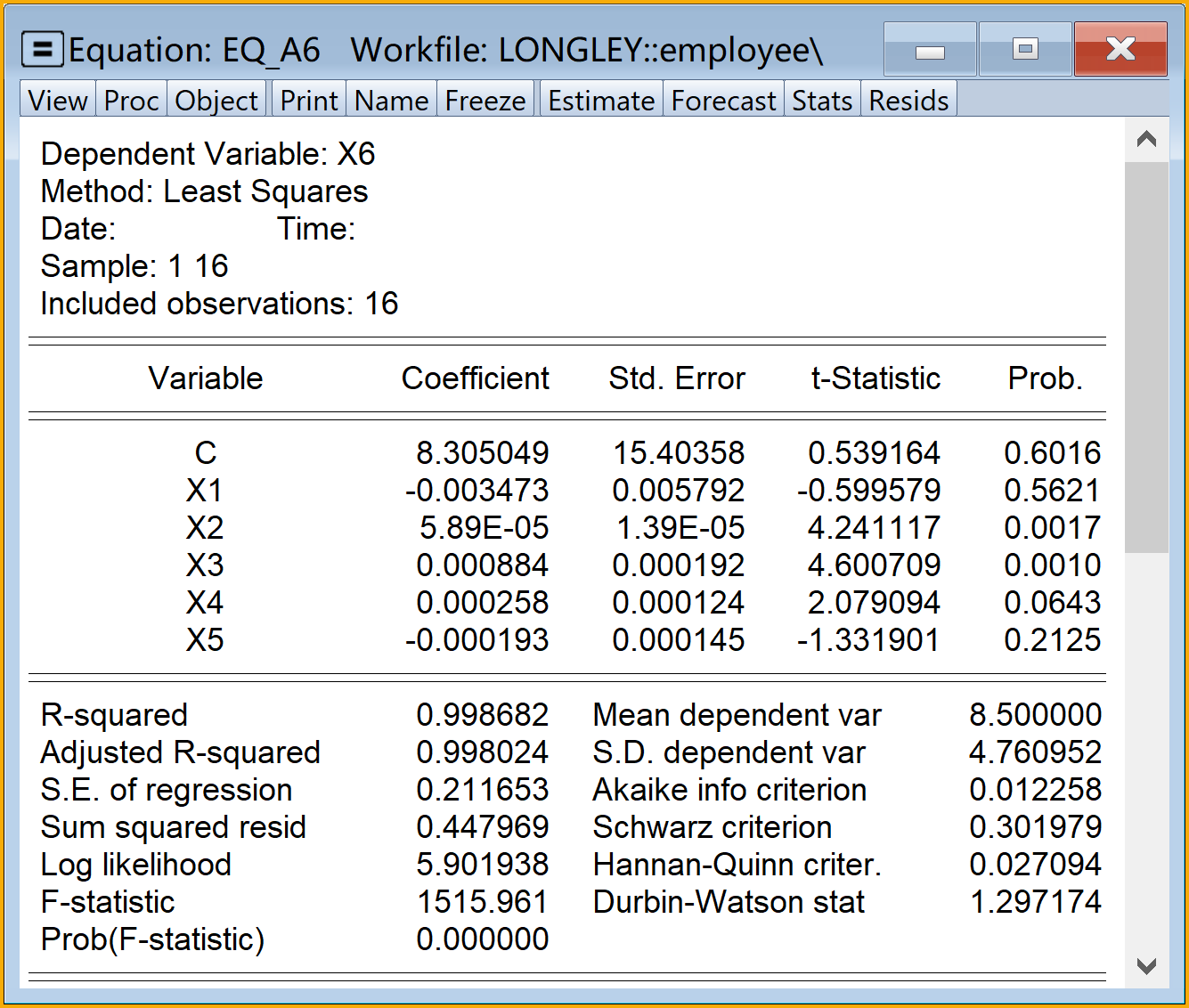
\[ \begin{aligned} X_{6t}& = \hat{\alpha}_0+\hat{\alpha}_1X_{1t}+\hat{\alpha}_2X_{2t}+\hat{\alpha}_3X_{3t}+\hat{\alpha}_4X_{4t}+\hat{\alpha}_5X_{5t}+e_{t} && \text{( A6 )} \end{aligned} \tag{5.23}\]
警告
提示:此处仅以A1 式 5.18 为例,其他辅助模型类似操作。
Eviews菜单操作(具体操作演示见 图 5.5 ):
(1)依次选择\(\Rightarrow\) Quick \(\Rightarrow\) Estimation Equation
(2)引导设置Equation Estimation \(\Rightarrow\) specification
Equation specification:输入方程设置
x1 c x2 x3 x4 x5 x6Estimation settings:
- Method: 下拉选择LS - Least Squares (NLS and ARMA)
- Sample: (默认设置)
(3)点击完成:OK
(4)命名保存方程对象:(建议命名为eq_a1,其他辅助回归方程依次命名为eq_a2,…,eq_a6)
- 查看结果:双击eq_a1
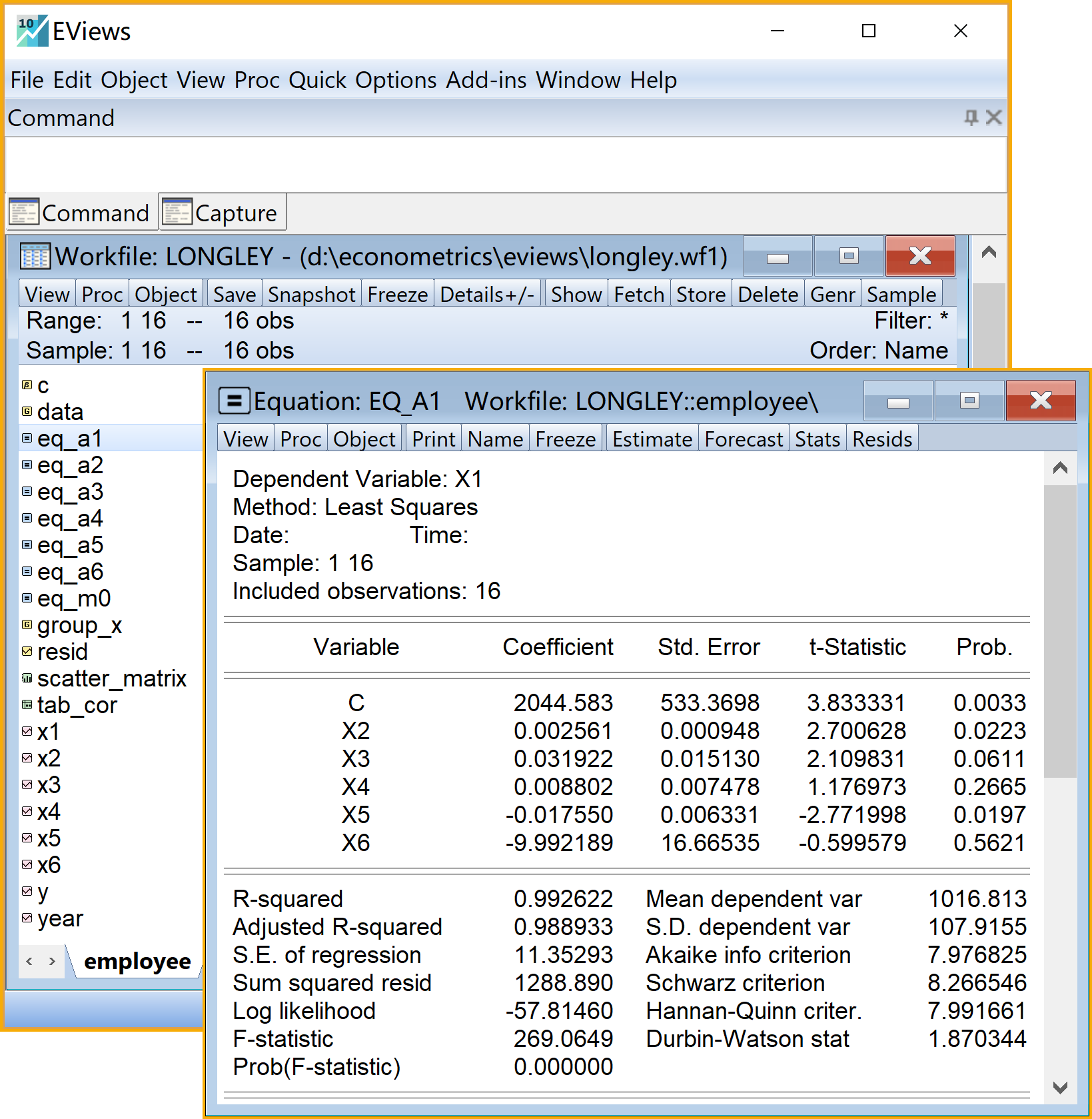
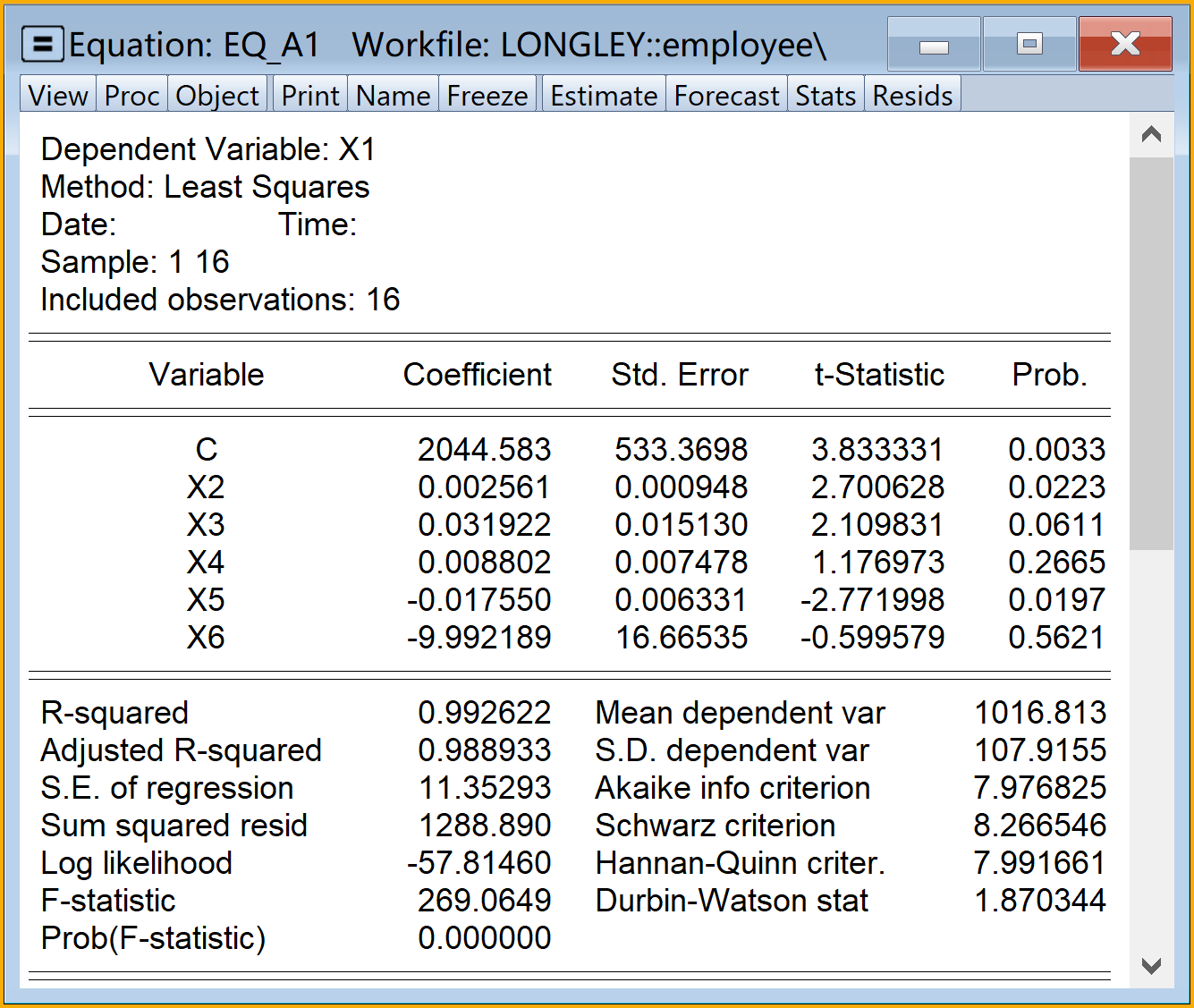
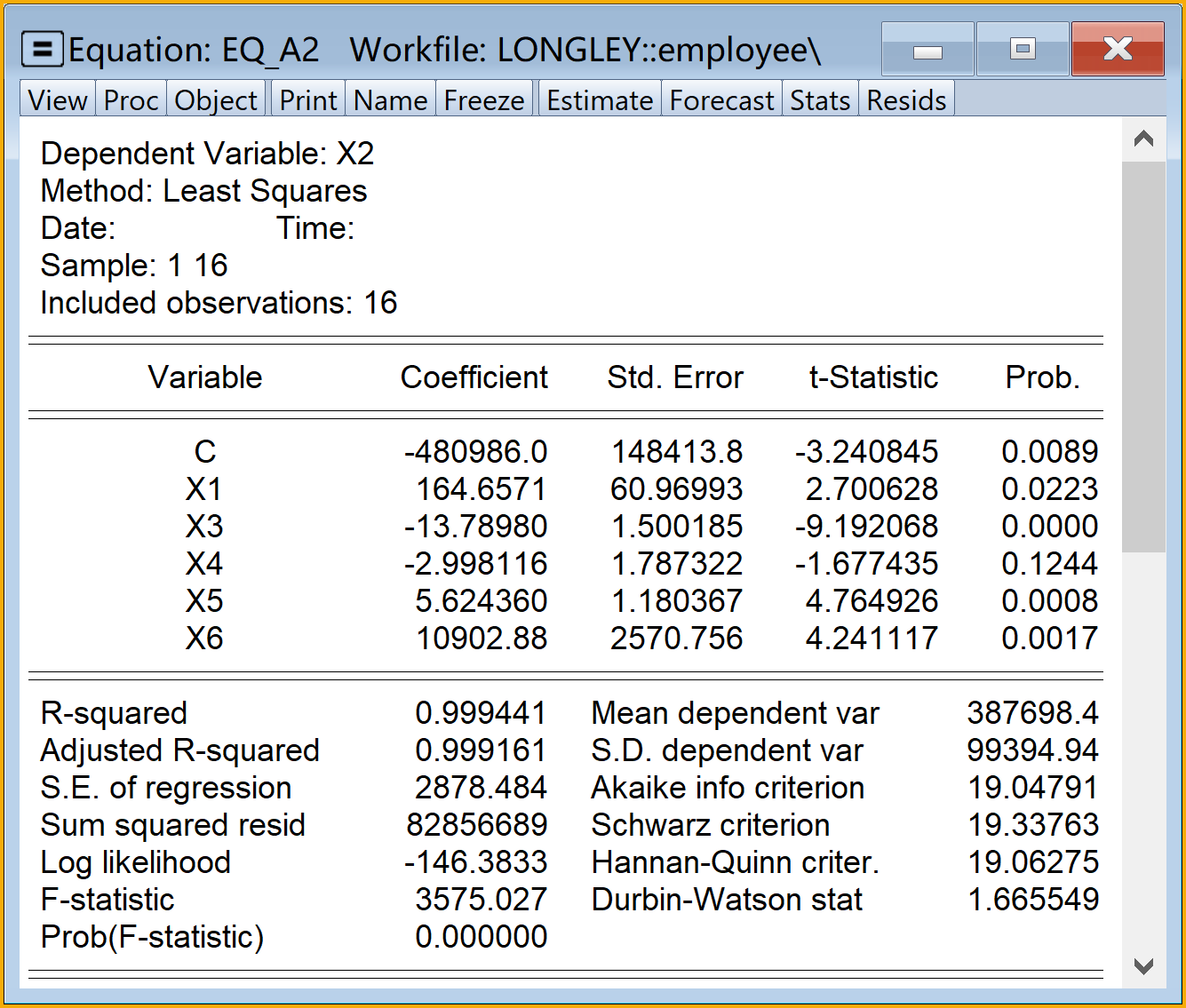
全部6个辅助回归方程的Eviews分析报告结果:A1-A3辅助模型见 图 5.6 ;A4-A6辅助模型见 图 5.7 。
提示
通过运行EViews代码,也可以实现上述操作。在命令视窗中依次输入并运行如下EViews代码:
****
`'多重共线性诊断:构建辅助回归方程`
`equation eq_a1.ls X1 c X2 X3 X4 X5 X6`
`equation eq_a2.ls X2 c X1 X3 X4 X5 X6`
`equation eq_a3.ls X3 c X1 X2 X4 X5 X6`
`equation eq_a4.ls X4 c X1 X2 X3 X5 X6`
`equation eq_a5.ls X5 c X1 X2 X3 X4 X6`
`equation eq_a6.ls X6 c X1 X2 X3 X4 X5`
各个辅助回归方程的简要结果如下:
\[ \begin{alignedat}{999} \begin{split} &\widehat{X1}=&&+2044.58&&+0.00X2_i&&+0.03X3_i&&+0.01X4_i\\ &(s)&&(533.3698)&&(0.0009)&&(0.0151)&&(0.0075)\\ &(t)&&(+3.83)&&(+2.70)&&(+2.11)&&(+1.18)\\ &(cont.)&&-0.02X5_i&&-9.99X6_i && &&\\ &(s)&&(0.0063)&&(16.6654) && &&\\ &(t)&&(-2.77)&&(-0.60) && &&\\ &(over)&&n=16&&\hat{\sigma}=11.3529 && &&\\ &(fit)&&R^2=0.9926&&\bar{R}^2=0.9889 && &&\\ &(Ftest)&&F^*=269.06&&p=0.0000 && && \end{split} \end{alignedat} \tag{5.24}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{X2}=&&-480986.04&&+164.66X1_i&&-13.79X3_i&&-3.00X4_i\\ &(s)&&(148413.7872)&&(60.9699)&&(1.5002)&&(1.7873)\\ &(t)&&(-3.24)&&(+2.70)&&(-9.19)&&(-1.68)\\ &(cont.)&&+5.62X5_i&&+10902.88X6_i && &&\\ &(s)&&(1.1804)&&(2570.7562) && &&\\ &(t)&&(+4.76)&&(+4.24) && &&\\ &(over)&&n=16&&\hat{\sigma}=2878.4838 && &&\\ &(fit)&&R^2=0.9994&&\bar{R}^2=0.9992 && &&\\ &(Ftest)&&F^*=3575.03&&p=0.0000 && && \end{split} \end{alignedat} \tag{5.25}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{X3}=&&-28518.24&&+9.65X1_i&&-0.06X2_i&&-0.27X4_i\\ &(s)&&(11446.8866)&&(4.5736)&&(0.0071)&&(0.1090)\\ &(t)&&(-2.49)&&(+2.11)&&(-9.19)&&(-2.49)\\ &(cont.)&&+0.35X5_i&&+768.55X6_i && &&\\ &(s)&&(0.0954)&&(167.0507) && &&\\ &(t)&&(+3.68)&&(+4.60) && &&\\ &(over)&&n=16&&\hat{\sigma}=197.3861 && &&\\ &(fit)&&R^2=0.9703&&\bar{R}^2=0.9554 && &&\\ &(Ftest)&&F^*=65.24&&p=0.0000 && && \end{split} \end{alignedat} \tag{5.26}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{X4}=&&-11881.24&&+13.82X1_i&&-0.07X2_i&&-1.41X3_i\\ &(s)&&(33002.4231)&&(11.7447)&&(0.0437)&&(0.5663)\\ &(t)&&(-0.36)&&(+1.18)&&(-1.68)&&(-2.49)\\ &(cont.)&&+0.20X5_i&&+1167.78X6_i && &&\\ &(s)&&(0.3276)&&(561.6770) && &&\\ &(t)&&(+0.61)&&(+2.08) && &&\\ &(over)&&n=16&&\hat{\sigma}=449.9064 && &&\\ &(fit)&&R^2=0.7214&&\bar{R}^2=0.5820 && &&\\ &(Ftest)&&F^*=5.18&&p=0.0133 && && \end{split} \end{alignedat} \tag{5.27}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{X5}=&&+95694.37&&-24.76X1_i&&+0.12X2_i&&+1.64X3_i\\ &(s)&&(8682.0335)&&(8.9319)&&(0.0259)&&(0.4454)\\ &(t)&&(+11.02)&&(-2.77)&&(+4.76)&&(+3.68)\\ &(cont.)&&+0.18X4_i&&-782.04X6_i && &&\\ &(s)&&(0.2943)&&(587.1614) && &&\\ &(t)&&(+0.61)&&(-1.33) && &&\\ &(over)&&n=16&&\hat{\sigma}=426.4253 && &&\\ &(fit)&&R^2=0.9975&&\bar{R}^2=0.9962 && &&\\ &(Ftest)&&F^*=796.30&&p=0.0000 && && \end{split} \end{alignedat} \tag{5.28}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{X6}=&&+8.31&&-0.00X1_i&&+0.00X2_i&&+0.00X3_i\\ &(s)&&(15.4036)&&(0.0058)&&(0.0000)&&(0.0002)\\ &(t)&&(+0.54)&&(-0.60)&&(+4.24)&&(+4.60)\\ &(cont.)&&+0.00X4_i&&-0.00X5_i && &&\\ &(s)&&(0.0001)&&(0.0001) && &&\\ &(t)&&(+2.08)&&(-1.33) && &&\\ &(over)&&n=16&&\hat{\sigma}=0.2117 && &&\\ &(fit)&&R^2=0.9987&&\bar{R}^2=0.9980 && &&\\ &(Ftest)&&F^*=1515.96&&p=0.0000 && && \end{split} \end{alignedat} \tag{5.29}\]
5.5.3.4 判定系数比较法
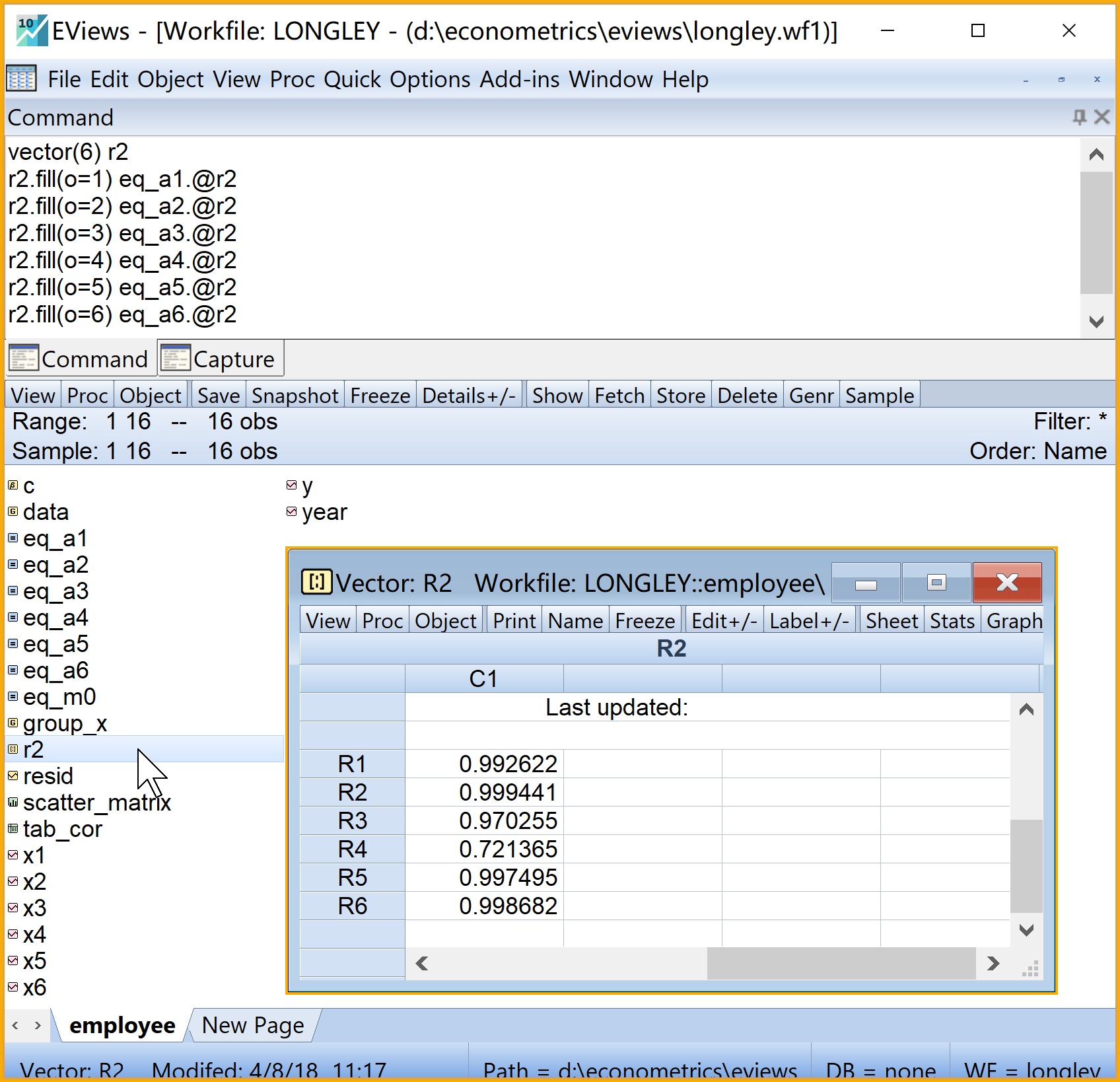
目标:分别6个辅助回归方程的判定系数\(R^2_j(j=1,\cdots,6)\),比较它们与主模型判定系数\(R^2\)的大小关系。
思路:分别提取辅助回归方程的Eviews报告中的判定系数。构造一个列向量(vector)对象(含6个元素),把6个辅助回归方程的判定系数依次放置其中。
提示
提示:多重共线性问题的诊断依据是,辅助回归方程的判定系数\(R^2_j(j=1,\cdots,6)\)大于主回归方程的判定系数\(R^2\)
Eviews操作:
(1)在命令视窗中依次输入并运行如下EViews代码:
'多重共线性诊断:辅助方程的判定系数比较
vector(6) r2
r2.fill(o=1) eq_a1.@r2 '提取辅助方程A1的判定系数
r2.fill(o=2) eq_a2.@r2 '提取辅助方程A2的判定系数
r2.fill(o=3) eq_a3.@r2 '提取辅助方程A3的判定系数
r2.fill(o=4) eq_a4.@r2 '提取辅助方程A4的判定系数
r2.fill(o=5) eq_a5.@r2 '提取辅助方程A5的判定系数
r2.fill(o=6) eq_a6.@r2 '提取辅助方程A6的判定系数
(2)在工作文件视窗下,可以看到如下新生成的对象,可以双击查看(见 图 5.8 ):包含六个辅助方程判定系数的向量对象r2
提示
(1)代码说明:
代码
r2.fill(o=1)表示给列向量(vector)对象r2的第1个元素(o=1)赋值(.fill)代码
eq_a1.@r2表示提取方程(equation)对象eq_a1的判定系数\(R^2\)(.@r2)
(2)参考资料:
向量对象操作命令
.fill的具体使用细节,请参看Eviews在线帮助文档,网址为http://www.eviews.com/help/helpintro.html#page/content%2Fvectorcmd-fill.html%23ww174507方程结果提取命令
@r2的具体使用细节,请参看Eviews在线帮助文档,网址为:http://www.eviews.com/help/helpintro.html#page/content%2Fequationcmd-Equation.html%23ww178434关于EViews方程对象的具体结果,内容请参看Eviews在线帮助文档,网址为:http://www.eviews.com/help/helpintro.html#page/content/Regress1-Equation_Output.html
根据上述比较分析,判定系数比较法的结论初步认为模型 式 5.17 可能存在严重的多重共线性问题理由如下:
| 辅助模型 | 模型形式 | 判定系数 |
|---|---|---|
| A1 | X1 ~ X2 + X3 + X4 + X5 + X6 | 0.99 |
| A2 | X2 ~ X1 + X3 + X4 + X5 + X6 | 1 |
| A3 | X3 ~ X1 + X2 + X4 + X5 + X6 | 0.97 |
| A4 | X4 ~ X1 + X2 + X3 + X5 + X6 | 0.72 |
| A5 | X5 ~ X1 + X2 + X3 + X4 + X6 | 1 |
| A6 | X6 ~ X1 + X2 + X3 + X4 + X5 | 1 |
5.5.3.5 方差膨胀因子(VIF)比较法
目标:分别得到6个辅助回归方程的方差膨胀因子\(VIF_j(j=1,\cdots,6)\),与参考值进行比较,得到相关结论。
思路:
Eviews手动计算:根据6个辅助回归方程的判定系数\(R^2_j\)(见 表 5.5 ),分别计算得到各自的方差膨胀因子\(VIF_j\)。
Eviews方程提取:利用Eviews菜单功能Coefficient Diagnostics \(\Rightarrow\) Variance Inflation Factors 一次性得到主回归模型的Eviews方程
eq_m0全部方差膨胀因子\(VIF_j(j=1,\cdots,6)\)
提示
提示:
操作提示:构造一个列向量(vector)对象
(含6个元素),用来装载6个辅助回归方程的方差膨胀因子\(VIF_j(j=1,\cdots,(6))\)。诊断提示:辅助回归方程的方差膨胀因子中如果\(VIF_j\in[10,100]\)表明中度多重共线性;如果\(VIF_j\geq{100}\)表明严重多重共线性
公式提示:辅助回归方程方差膨胀因子的理论计算公式为
\[ \begin{aligned} VIF_j=\frac{1}{1-R^2_j},(j=1,\cdots,6) \end{aligned} \tag{5.30}\]
(方法1)Eviews命令操作(手动计算实现,具体见 图 5.9 ):
在命令视窗中依次输入并运行如下EViews代码:
'多重共线性诊断:方差膨胀因子
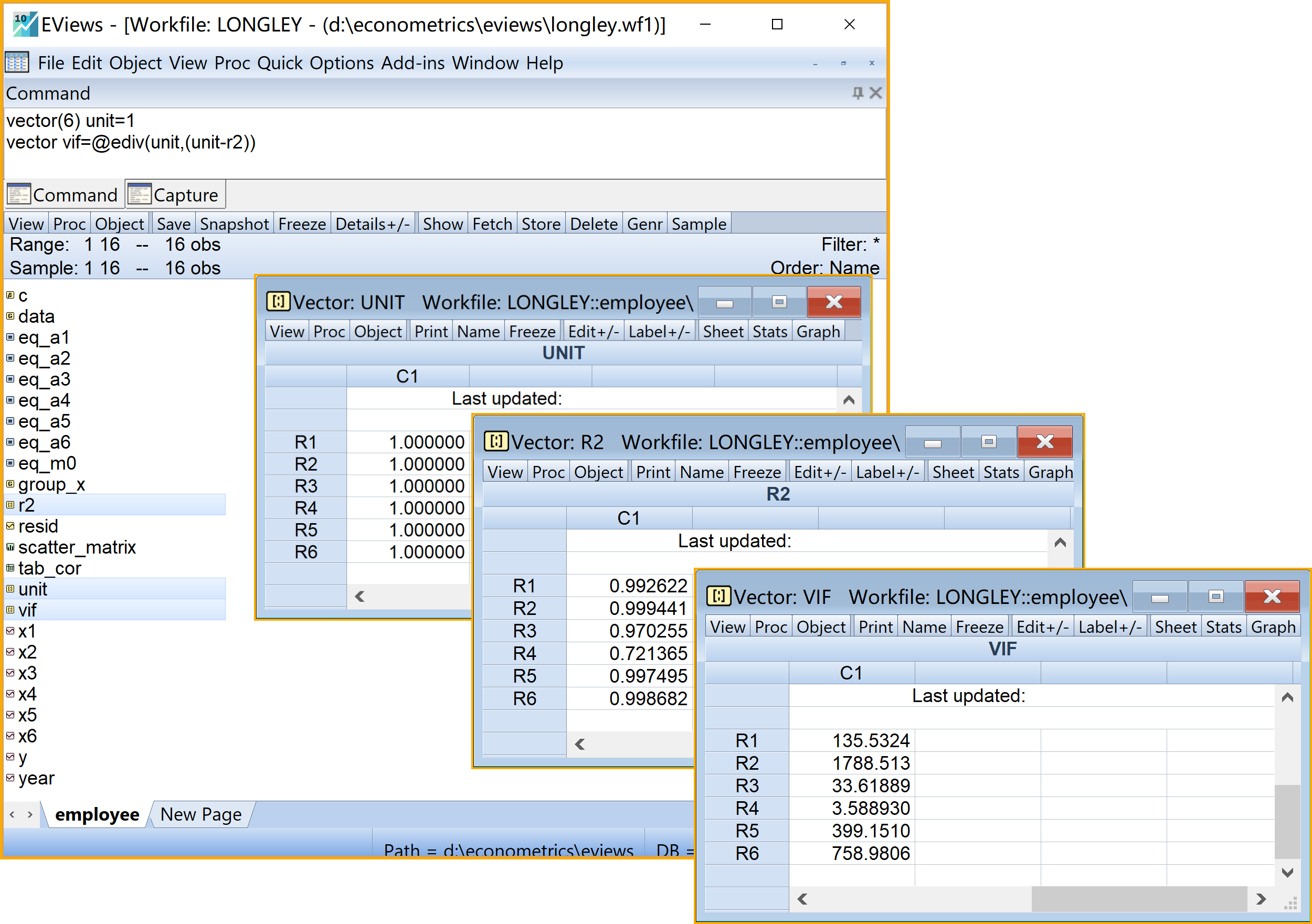
vector(6) unit=1 '为计算做准备
vector vif=@ediv(unit,(unit-r2)) '利用公式计算VIF
在工作文件视窗下,可以看到如下新生成的对象,可以双击查看(见 图 5.9 ):包含6个辅助回归方程各自方差膨胀因子(\(VIF_i\))的向量对象vif
提示
(1)代码说明:
代码
vector(6) unit=1表示生成一个包含6个元素全为1、名为unit的列向量unit。代码
vector vif=\@ediv(unit,(unit-r2))表示生成一个名为vif列向量(vector)对象vif,并使该列向量等于另外两个向量之除,也即=\@ediv(unit,(unit-r2))。代码
\@ediv()为Eviews矩阵运算函数,用于两个向量元素间相除的计算。
(2)参考资料:
@ediv函数代码的具体使用细节请参看Eviews在线帮助文档
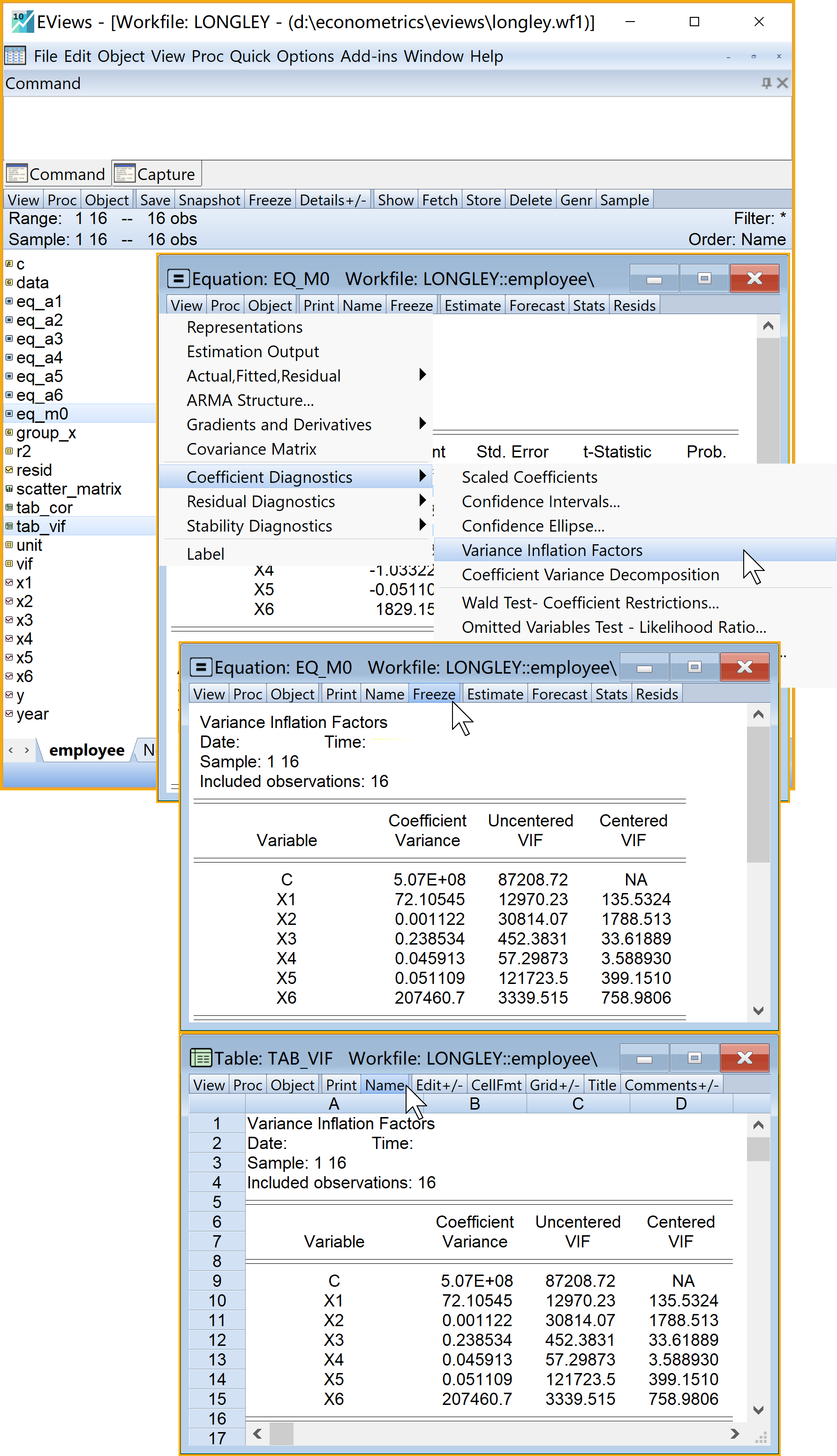
(方法2)Eviews菜单操作(菜单操作实现,具体见 图 5.10 ):
打开主方程:双击方程(equation)对象
eq_m0进入功能菜单:
- 选择分析菜单:\(\Rightarrow\)
View\(\Rightarrow\)Coefficient Diagnostics\(\Rightarrow\)Variance Inflation Factors - 另存为表格(table)对象:点击
Freeze - 命名并保存表格(table)对象:点击
name(建议为tab_vif) - 查看结果:双击
tab_vif
- 选择分析菜单:\(\Rightarrow\)
提示
多重共线性诊断结果。根据诊断经验标准,主回归方程M0的方差膨胀因子中,如果\(VIF_j\in[10,100]\)表明中度多重共线性;如果\(VIF_j\geq{100}\)表明严重多重共线性。
| 自变量 | VIF | >100 | 10~100 |
|---|---|---|---|
| X1 | 135.5 | 很严重 | … |
| X2 | 1788.5 | 很严重 | … |
| X3 | 33.6 | … | 中等 |
| X4 | 3.6 | … | … |
| X5 | 399.1 | 很严重 | … |
| X6 | 759.0 | 很严重 | … |
根据计算结果汇总(见 表 5.6 ),可以认为主模型M0存在较严重的多重共线性问题。其中VIF值大于100的系数就包括X1、X2、X5、X6。
5.5.3.6 容忍度(TOL)比较法
目标:分别得到6个辅助回归方程的容忍度\(TOL_j(j=1,\cdots,6)\),与参考值进行比较,得到相关结论。
思路:根据6个辅助回归方程的判定系数\(R^2_j\)(见 表 5.5 ),分别计算得到各自的容忍度\(TOL_j\)。
提示
提示:
操作提示:构造一个列向量(vector)对象
(含6个元素),用来装载6个辅助回归方程的容忍度\(TOL_j(j=1,\cdots,(6))\)诊断提示:辅助回归方程的的容忍度如果\(TOL_j\in[0.01,0.1]\)表明中度多重共线性;如果\(TOL_j\leq{0.01}\)表明存在严重的多重共线性
公式提示:辅助回归方程容忍度的理论计算公式为
\[ \begin{aligned} TOL_j=1-R^2_j=\frac{1}{VIF_j},(j=1,\cdots,6) \end{aligned} \tag{5.31}\]
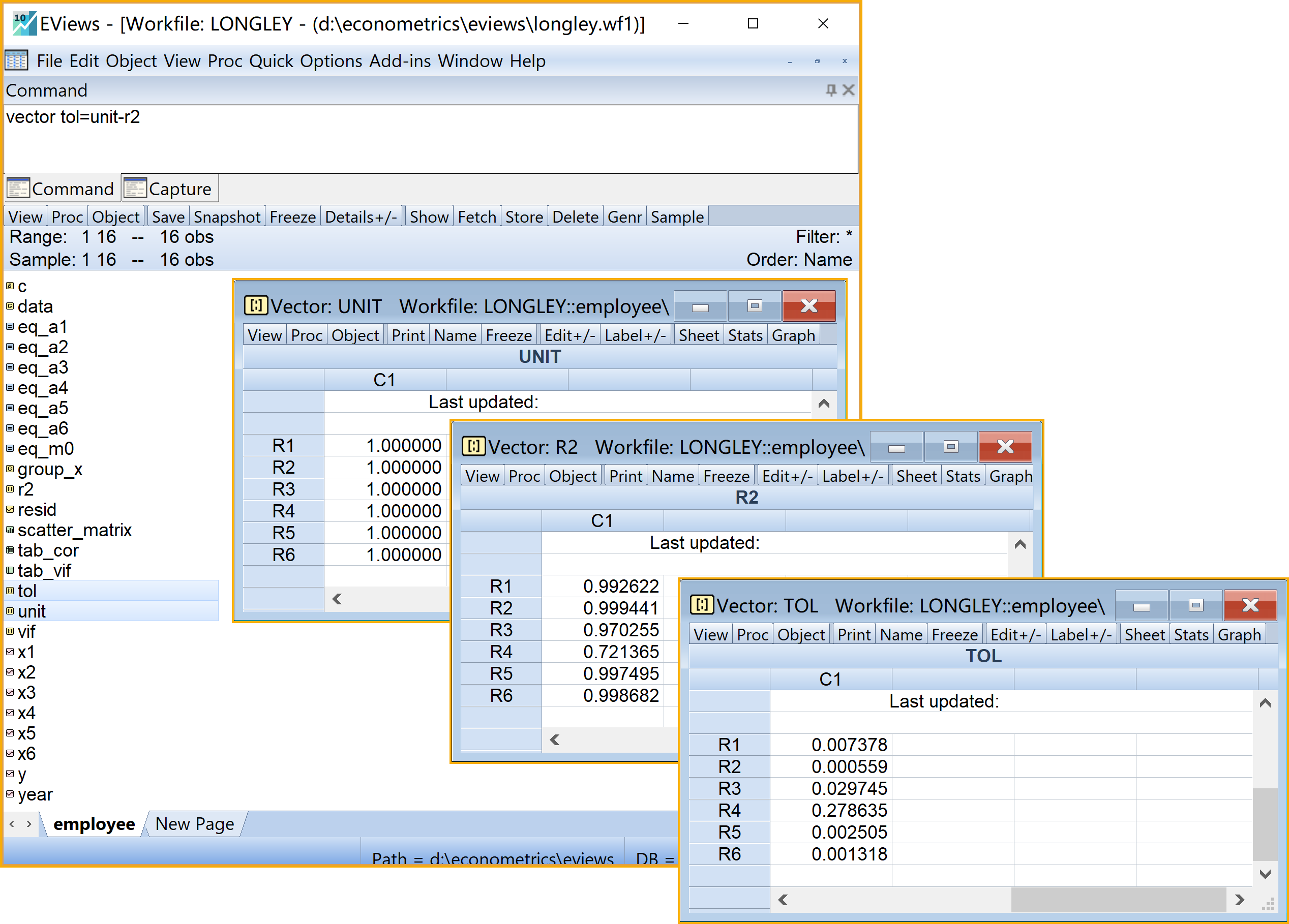
在命令视窗中依次输入并运行如下EViews代码:
'多重共线性诊断:容忍度
vector tol=unit-r2 '利用公式计算TOL在工作文件视窗下,可以看到如下新生成的对象,可以双击查看(见 图 5.11 ):
- 辅助方程容忍度\(TOL_i\)组成的向量对象tol
5.5.3.7 回归系数方差分解法
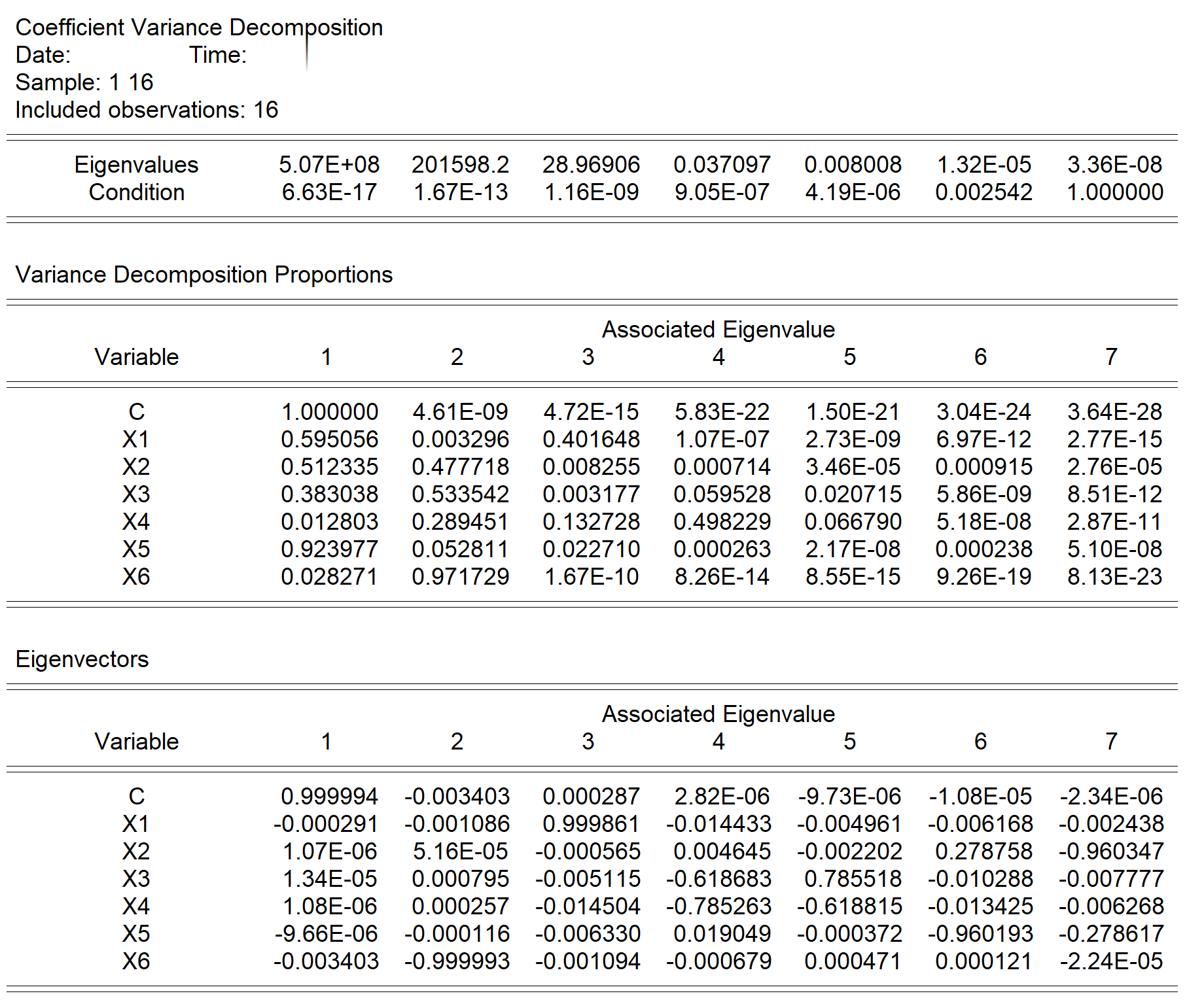
目标:利用Eviews的共线性诊断菜单,进行回归系数方差分解(Coefficient Variance Decomposition)。分析病态数(Condition Numbers,K)和方差分解比率(variance-decomposition proportions,VDP),并与参考值进行比较,得到相关结论
思路:特征值(Eigenvalue);病态数(condition number,K);方差分解比率(variance-decomposition proportions,VDP)
提示
提示:
操作提示:用Eviews的共线性诊断菜单 \(\Rightarrow\) View \(\Rightarrow\) Coefficient Diagnostics \(\Rightarrow\) Coefficient Variance Decomposition
诊断提示:若发现至少一个病态数\(K \leq{(0.001}\),则表明存在严重多重共线性;观察病态数最小时所对应的方差分解比率,如果有多个斜率系数的\(VDP \geq{0.5}\) ,则表明它们存在严重的多重共线性
\[ \begin{aligned} \widehat{var}\_\widehat{cov}(\mathbf{\hat{\beta}})=\hat{\sigma}^2\mathbf{(X'X)^{-1}} \end{aligned} \]
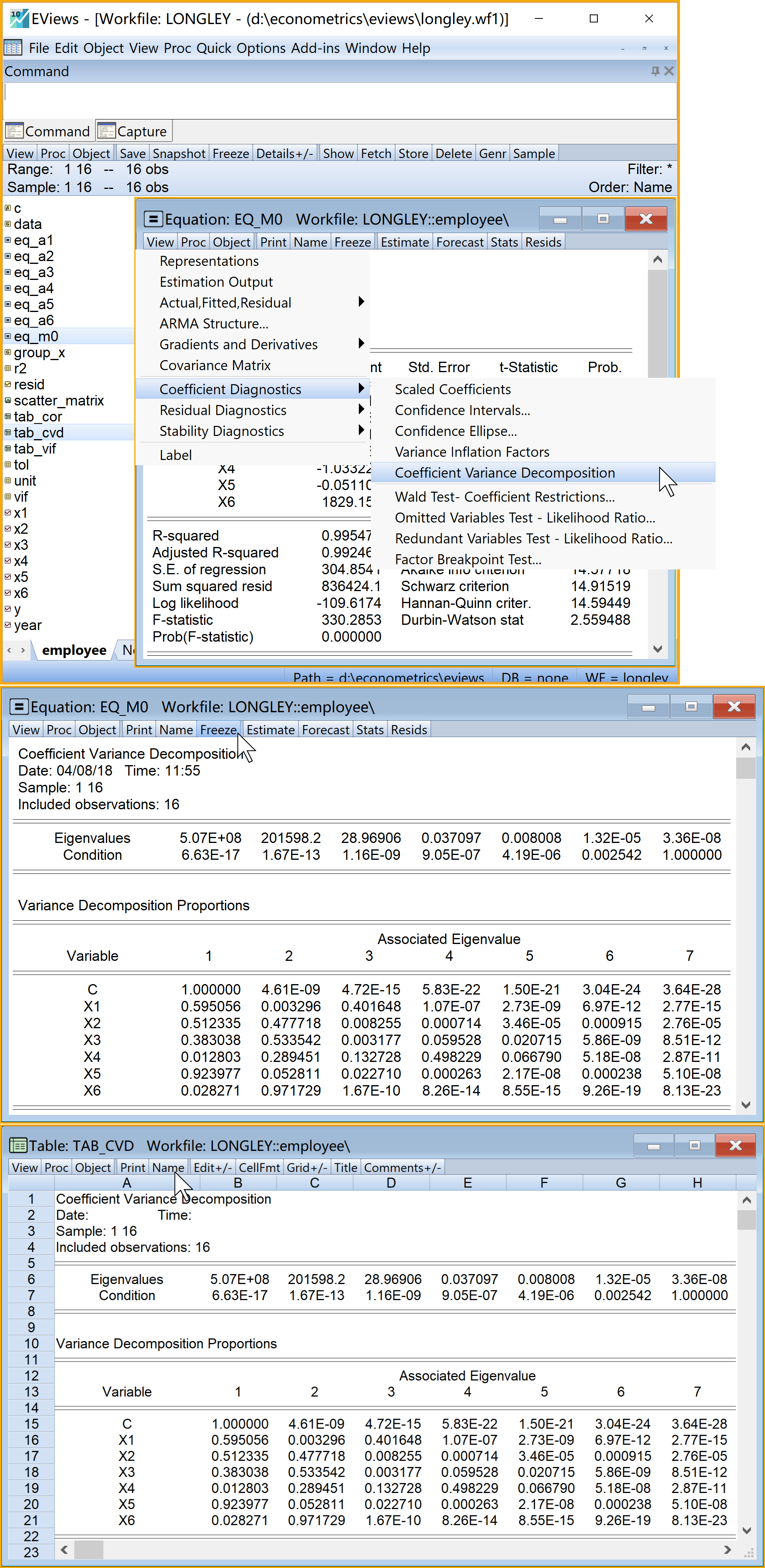
Eviews操作(菜单操作实现,具体见 图 5.12 ):
(1)打开主方程:双击方程(equation)对象eq_m0
(2)进入功能菜单:
选择分析菜单:\(\Rightarrow\) View \(\Rightarrow\) Coefficient Diagnostics \(\Rightarrow\) Coefficient Variance Decomposition
另存为表格(table)对象:点击Freeze
命名并保存表格(table)对象:点击name(建议为tab_cvd)
查看结果:双击
tab_cvd
提示
(1)通过运行EViews代码,也可以实现上述操作。在命令视窗中依次输入并运行如下EViews代码:
****
`'多重共线性诊断:回归系数方差分解法`
`freeze(tab_vcd) eq_m0.cvardecomp `
(2)代码说明:
系数方差分解表视图命令
.cvardecomp属于一种方程视图(Equation View)的EViews调用命令,可以得到方程的系数方差分解表。系数方差分解表视图命令
.cvardecomp命令的具体使用方法可参阅EViews在线帮助文档
(3)参考资料:
系数方差分解诊断方法由Belsley, Kuh and Welsch (BKW) 2004提出,具体细节可以参考Eviews帮助文档
Eviews软件中病态数的计算是基于矩阵\(\mathbf{(X'X)}^{-1}\),而不是基于矩阵\(\mathbf{X}\)
多重共线性诊断分析,具体Eviews报告见 图 5.13 。
5.5.4 多重共线性模型矫正
5.5.4.1 经济学和实践观察法
目标:根据某种考虑或规则,删除特定变量,重新估计回归模型,得到相关结论。
思路:面对严重的共线性,最简单的方法就是去掉某些变量,但剔除变量会导致设定误差。实际中需要权衡利弊。
提示
理论提示:酌情删除:经济学和实践观察法。利用先验信息(成为研究领域的专家!)酌情删除特定变量,减弱模型的多重共线性问题。那怎样才能获得先验信息呢?它往往源自经验研究工作或者有关基础理论。
操作提示:
改用真实GNP,不用名义GNP(X2):将名义GNP(X2)除以价格指数CPI(X1)
留下14 岁以上非机构人口数(X5),去掉时间趋势(X6):14 岁以上非机构人口数随时间不断增长,它与时间趋势变量高度相;而且时间趋势变量还和很多其他变量高度相关。
去掉失业人数变量(X3):可能失业率是劳动力市场状况的一个更好的度量指标,但我们没有这方面的数据,而失业人数也没有充分的理由包括进来。
Eviews操作(菜单操作实现,见 图 5.15 ):
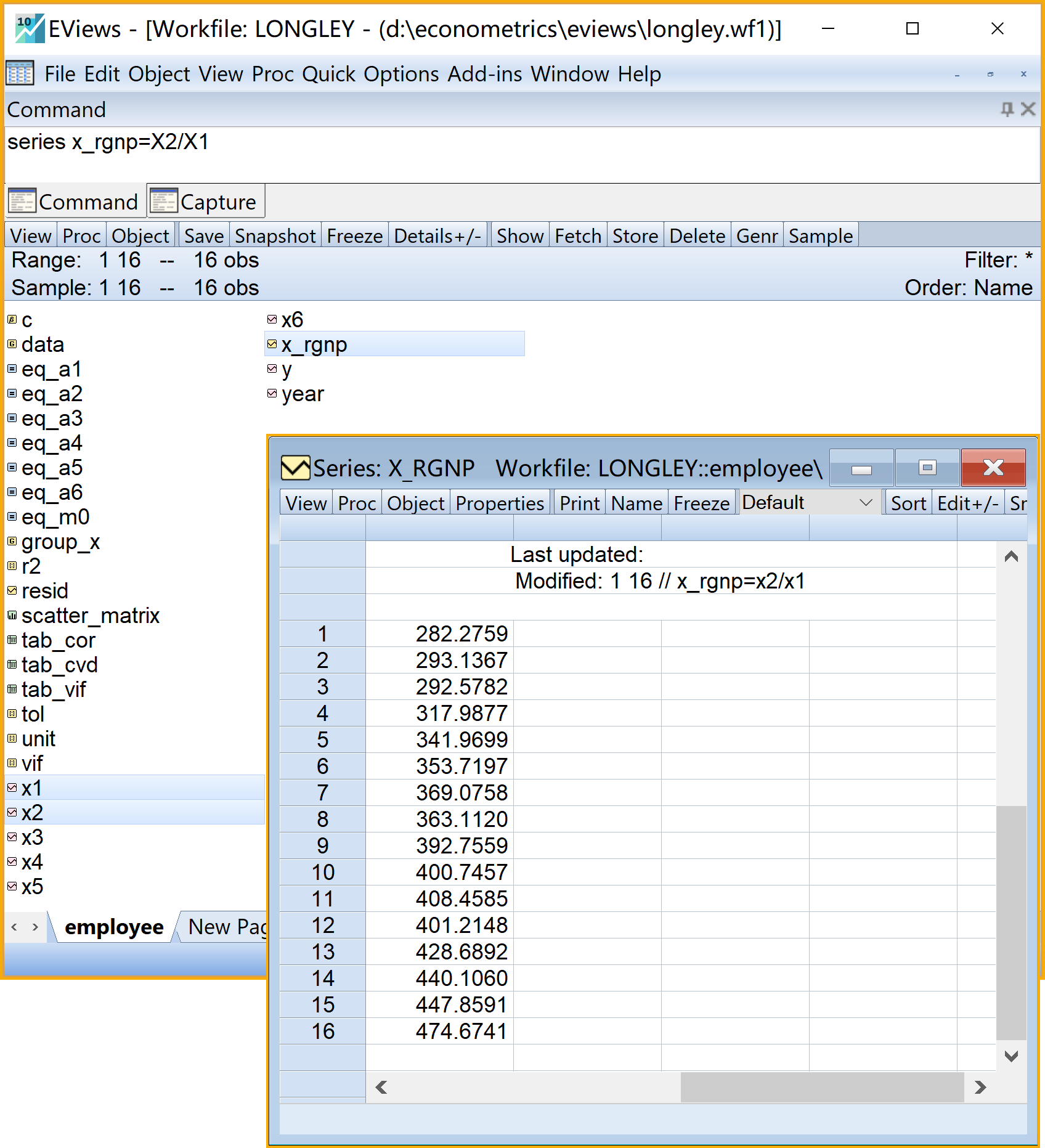
(1)变量变换,生成实际GNP(=名义GNP/CPI)(见 图 5.15 )
命令视窗(Command)输入命令 :
series x_rgnp=X2/X1运行命令:命令行中按Enter键
查看计算结果
(2)引导设置Equation Estimation\(\Rightarrow\)specification
Equation specification:输入命令 Y c x_rgnp X3 X4 X5
Estimation settings:
- Method: 下拉选择
LS - Least Squares (NLS and ARMA) - Sample: 默认设置
- Method: 下拉选择
点击
OK
(3)模型命名:建议为eq_adj_man
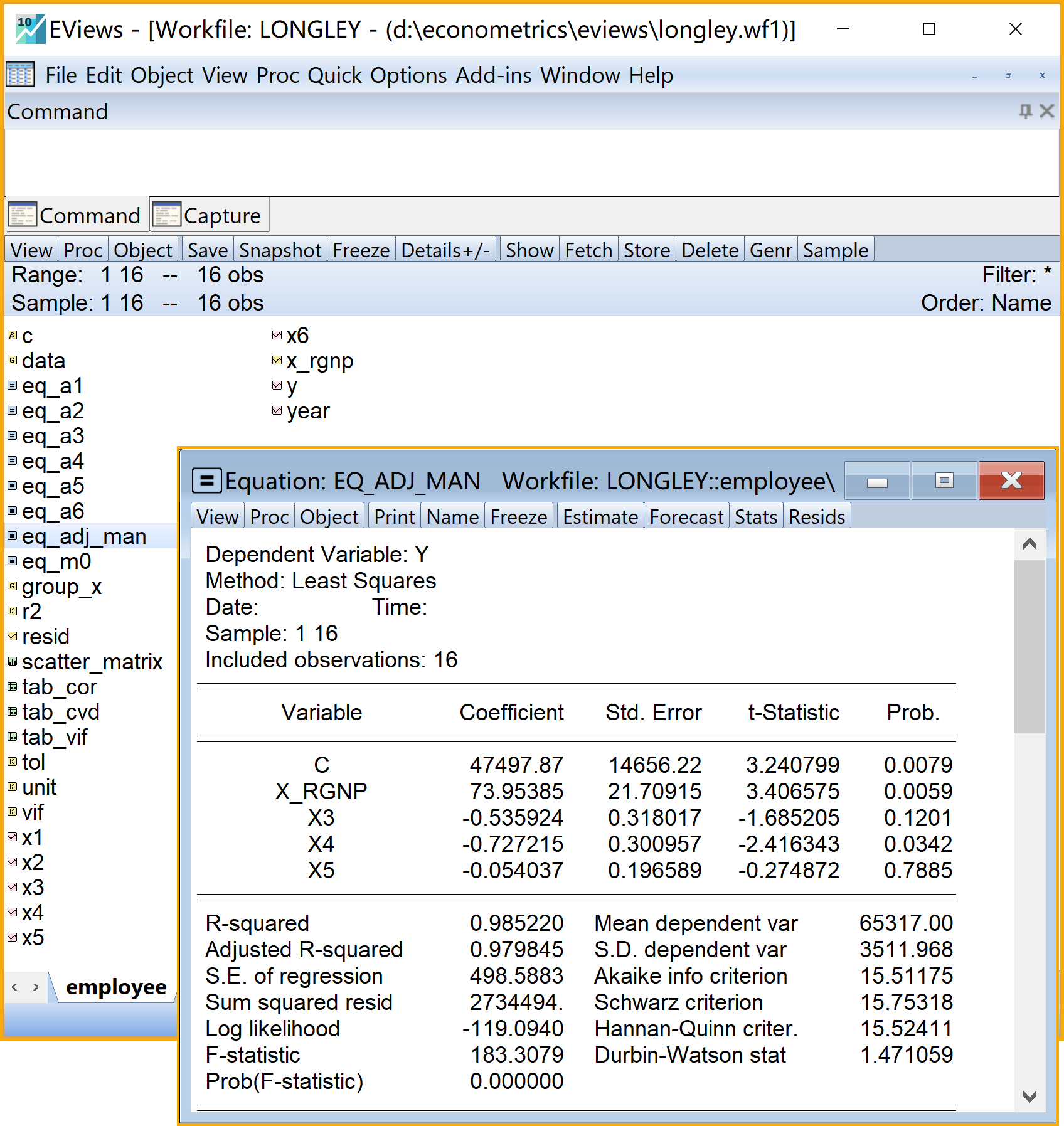
酌情法矫正的分析结果如图:
提示
通过运行EViews代码,也可以实现上述操作。在命令视窗中依次输入并运行如下EViews代码:
****
`'多重共线性矫正:经济学和实践观察法`
`series x_rgnp=x2/x1 ' 构造新变量`
`equation eq_adj_man.ls y c x2/x1 x3 x4 x5 '回归新方程` 利用酌情删除法的矫正多重共线性问题后的简要回归报告如下:
\[ \begin{aligned} \begin{split} \widehat{Y}_i=&+\hat{\beta}_{1}+\hat{\beta}_{2}\frac{X2}{X1})_i+\hat{\beta}_{3}X3_i+\hat{\beta}_{4}X4_i\\&+\hat{\beta}_{5}X5_i \end{split} \end{aligned} \tag{5.32}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{Y}=&&+47497.87&&+73.95X2/X1_i&&-0.54X3_i\\ &(s)&&(14656.2227)&&(21.7092)&&(0.3180)\\ &(t)&&(+3.24)&&(+3.41)&&(-1.69)\\ &(cont.)&&-0.73X4_i&&-0.05X5_i &&\\ &(s)&&(0.3010)&&(0.1966) &&\\ &(t)&&(-2.42)&&(-0.27) &&\\ &(over)&&n=16&&\hat{\sigma}=498.5883 &&\\ &(fit)&&R^2=0.9852&&\bar{R}^2=0.9798 &&\\ &(Ftest)&&F^*=183.31&&p=0.0000 && \end{split} \end{alignedat} \tag{5.33}\]
5.5.4.2 变量变换法
目标:根据某种考虑或规则,删除特定变量,重新估计回归模型,得到相关结论。
思路:面对严重的共线性,最简单的方法就是去掉某些变量,但剔除变量会导致设定误差。实际中需要权衡利弊。
理论提示1:一阶差分法(first difference form)巧妙删除变量。
模型中两个解释变量\(X_{k,i}\)和\(X_{w,i}\)可能导致高度多重共线性,但是分别对二者进行一阶差分,再进行回归建模,新模型可能的多重共线性问题很可能大大缓解!
具体变换如下:
\[ \begin{aligned} Y_t & =\beta_1+\beta_2X_{2,t}+\beta_3X_{3,t}+u_t && \text{(原模型)} \end{aligned} \tag{5.34}\]
\[ \begin{aligned} Y_{t-1} & =\beta_1+\beta_2X_{2,t-1}+\beta_3X_{3,t-1}+u_{t-1} && \text{(滞后1阶变量模型)} \end{aligned} \tag{5.35}\]
\[ \begin{aligned} Y_t-Y_{t-1} & =\beta_2(X_{2,t}-X_{2,t-1})+\beta_3(X_{3,t}-X_{3,t-1})+(u_t-u_{t-1}) && \text{(一阶差分模型)} \end{aligned} \tag{5.36}\]
\[ \begin{aligned} Y^{\ast}_t &=\beta_2X^{\ast}_{2,t}+\beta_3X^{\ast}_{3,t}+v_t && \text{(精简化模型)} \end{aligned} \tag{5.37}\]
需要注意的是,“按下葫芦浮起瓢”,治疗比疾病更糟糕?差分变换\(Y_{t-1}\)减少了自由度;同时\(v_t=(u_t-u_{t-1})\)可能带来异方差问题。
理论提示2:比率变换法(ratio transformation)巧妙删除变量。
模型中两个解释变量\(X_{k,i}\)和\(X_{w,i}\)可能导致高度多重共线性,如果可以用其中的一个变量同时对模型其他变量进行比率变换,而且如果变换后的所有变量还能具有经济学含义,那么理论上将至少消掉一个回归元,从而大大缓解甚至消除多重共线性问题!
具体变换如下:
消费支出决定案例:\(Y_t\) 为以真实价格表示的消费支出,\(X_{2,t}\)表示GDP, \(X_{3,t}\)表示总人口。
\[ \begin{aligned} Y_t & =\beta_1+\beta_2X_{2,t}+\beta_3X_{3,t}+u_t && \text{(原模型)} \end{aligned} \tag{5.38}\]
\[ \begin{aligned} \frac{Y_t}{X_{3,t}} & =\frac{\beta_1}{X_{3,t}}+\beta_2\frac{X_{2,t}}{X_{3,t}}+\frac{u_t}{X_{3,t}} && \text{(比率变换模型)} \end{aligned} \tag{5.39}\]
\[ \begin{aligned} Y^{\ast}_t &=\beta^{\ast}_1+\beta^{\ast}_2X^{\ast}_{2,t}+v_t && \text{(精简化模型)} \end{aligned} \tag{5.40}\]
同样需要注意的是,“按下葫芦浮起瓢”,治疗比疾病更糟糕?\(v_t=\frac{u_t}{X_{3,t}}\)可能带来异方差问题。
5.5.4.3 逐步最小二乘回归法
目标:根据某种考虑或规则,删除特定变量,重新估计回归模型,得到相关结论。
思路:面对严重的共线性,最简单的方法就是去掉某些变量,但剔除变量会导致设定误差。实际中需要权衡利弊。
理论提示:逐步最小二乘回归法(Stepwise Least Squares Regression)通过多个统计标准,可以自动判断模型该引入还是删除某些自变量X。这些统计标准主要包括分析引入新变量对回归平方和ESS的贡献大小,及F检验等。
前向逐步回归法(Stepwise-Forwards),是从一个简化模型(很少X变量)开始,再逐步引入新的X变量,直至达到某个统计标准(主要是p值标准)
后向逐步回归法(Stepwise-Backwards),是从一个完全模型(全部X变量)开始,对模型逐步删除某些X变量,直至剩余变量都达到某个统计标准(主要是p值标准)
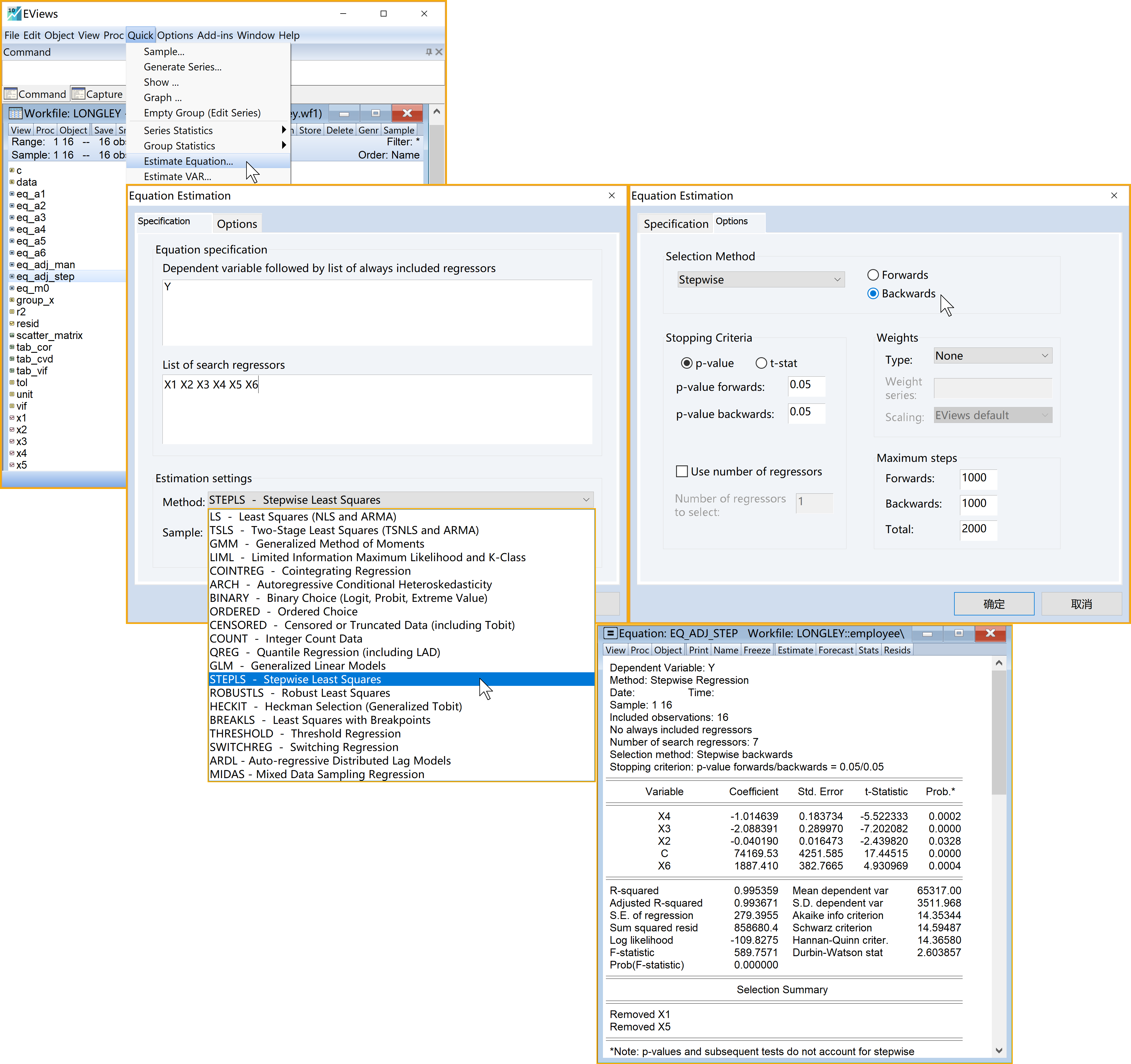
Eviews操作(以后向逐步回归法为例,见 图 5.16 ):
(1)依次选择\(\Rightarrow\) Quick \(\Rightarrow\) Estimation Equation
(2)引导设置Equation Estimation \(\Rightarrow\) Specification
输入因变量和选择一直保留的自变量(Dependent variable followed by list of always included regressors): Y (此处如果仅填Y变量,则任何X变量都没有强制一定要留在模型中)
输入自变量(List of search regressors):Y c X1 X2 X3 X4 X5 X6
估计方法(Estimation settings):
- Method:下拉选择
STEPLS - stepwise Least Squares - Sample: 默认设置
- Method:下拉选择
(3)引导设置Equation Estimation \(\Rightarrow\) Options
方法设置(Selection Method):
- 下拉选择Stepwise
- 点击选择Backwards
标准设置(Stopping Criteria):
- 点击选择p-value
- 填写(p-value forwards):0.05
- 填写(p-value backwards):0.05
- 其他:默认设置
权重设置(Weights):默认设置
步数设置(Maximum steps):默认设置
完成设置:点击
OK
(4)模型命名:建议为eq_adj_step
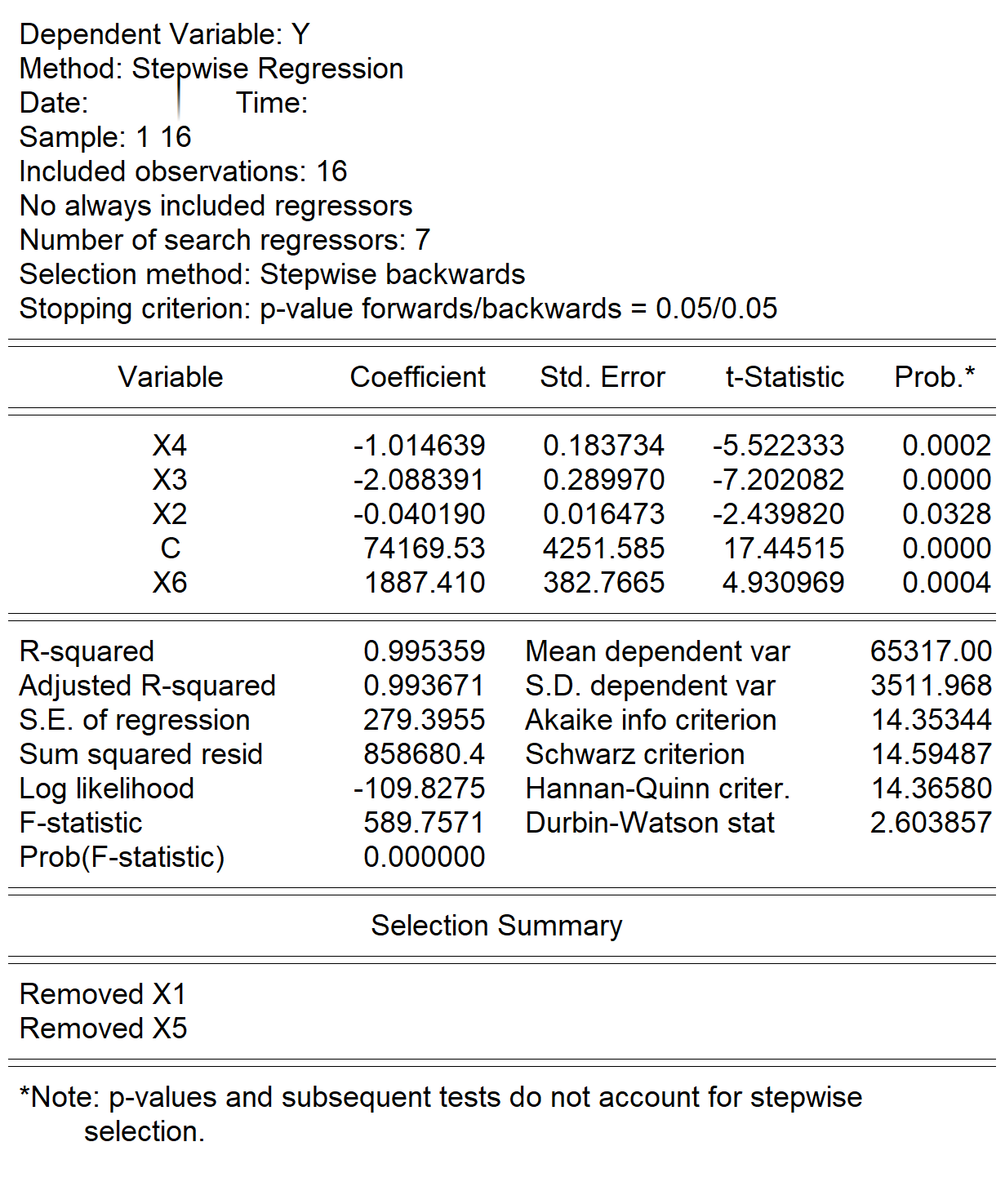
(5)查看分析报告(见 图 5.17 )
提示
(1)通过运行EViews代码,也可以实现上述操作。在命令视窗中依次输入并运行如下EViews代码:
****
`'多重共线性矫正:逐步最小二乘回归法(后向逐步回归,p值标准为0.05)`
`equation eq_adj_step.stepls(back,btol=0.05) Y @ c X1 X2 X3 X4 X5 X6 `
(2)代码说明:
回归方法命令
.stepls(back,btol=0.05),可以引用逐步回归分析方法。逐步回归法是方程对象(Equation)的一种分析方法(method),可以参看EViews的方程方法(Equation Methods)列表说明.
回归方法命令
.stepls(back,btol=0.05)的具体使用方法,可参阅EViews在线帮助文档
(3)参考资料:
- 逐步回归分析方法,可参看Eviews在线说明文档
逐步回归法矫正后的简要回归报告如下:
\[ \begin{aligned} \begin{split} \widehat{Y}_i=&+\hat{\beta}_{1}+\hat{\beta}_{2}X2_i+\hat{\beta}_{3}X3_i\\&+\hat{\beta}_{4}X4_i+\hat{\beta}_{5}X5_i \end{split} \end{aligned} \tag{5.41}\]
\[ \begin{alignedat}{999} \begin{split} &\widehat{Y}=&&+74169.53&&-0.04X2_i&&-2.09X3_i\\ &(s)&&(4251.5849)&&(0.0165)&&(0.2900)\\ &(t)&&(+17.45)&&(-2.44)&&(-7.20)\\ &(cont.)&&-1.01X4_i&&+1887.41X6_i &&\\ &(s)&&(0.1837)&&(382.7665) &&\\ &(t)&&(-5.52)&&(+4.93) &&\\ &(over)&&n=16&&\hat{\sigma}=279.3955 &&\\ &(fit)&&R^2=0.9954&&\bar{R}^2=0.9937 &&\\ &(Ftest)&&F^*=589.76&&p=0.0000 && \end{split} \end{alignedat} \tag{5.42}\]
5.5.4.4 主成分法(自学)
5.6 附录:prg源代码
实际操作中,在EViews命令视窗中逐条输入代码,既容易出错,又不便于维护这些代码,还不能进行代码的重复使用(在第一章的 小节 1.8 中已经论述)。
因此,读者可以创建一个.prg编程文件 ,并在其中编写EViews代码,进行管理、维护、运行和分析。下面代码按本章主要实验步骤编写,读者可以用于本章的EViews编程参考,进行实验练习。
,并在其中编写EViews代码,进行管理、维护、运行和分析。下面代码按本章主要实验步骤编写,读者可以用于本章的EViews编程参考,进行实验练习。
'=========================================================================================================
'说明:以下为EViews编程文件longley.prg的代码
'将展示第五章中“郎利就业数据案例”主要分析步骤的“批量式命令驱动”实现方法(::
'其中,符号'起始的行,为注释行,其他为EViews命令行。
'=========================================================================================================
'创建工作文件(工作文件名=longley,子页命名=employee),无结构无日期,样本数为16
wfcreate(wf=longley,page=employee) u 16
'导入外部数据,路径为d:\github\books\data\Lab5-longley-short-origin.xlsx
import d:\github\books\data\Lab5-longley-short-origin.xlsx
'生成线性回归模型的方程对象
equation eq_m0.ls Y c x1 x2 x3 x4 x5 x6 '回归方程
scalar r2_m0=eq_m0.@r2
'多重共线性诊断:计算自变量的相关系数表格和散点矩阵图
group varx x1 x2 x3 x4 x5 x6 '构建只含X的group
freeze(tab_cor) varx.cor '把group的相关系数矩阵表视图保存为表格
graph scatter_matrix.scatmat varx '绘制散点矩阵图
'多重共线性诊断:构建辅助回归方程
equation eq_a1.ls X1 c X2 X3 X4 X5 X6
equation eq_a2.ls X2 c X1 X3 X4 X5 X6
equation eq_a3.ls X3 c X1 X2 X4 X5 X6
equation eq_a4.ls X4 c X1 X2 X3 X5 X6
equation eq_a5.ls X5 c X1 X2 X3 X4 X6
equation eq_a6.ls X6 c X1 X2 X3 X4 X5
'多重共线性诊断:辅助方程的判定系数比较
vector(6) r2
r2.fill(o=1) eq_a1.@r2 '提取辅助方程A1的判定系数
r2.fill(o=2) eq_a2.@r2 '提取辅助方程A2的判定系数
r2.fill(o=3) eq_a3.@r2 '提取辅助方程A3的判定系数
r2.fill(o=4) eq_a4.@r2 '提取辅助方程A4的判定系数
r2.fill(o=5) eq_a5.@r2 '提取辅助方程A5的判定系数
r2.fill(o=6) eq_a6.@r2 '提取辅助方程A6的判定系数
'多重共线性诊断:方差膨胀因子
vector(6) unit=1 '为计算做准备
vector vif=@ediv(unit,(unit-r2)) '利用公式计算VIF
freeze(tab_vif) eq_m0.varinf '直接冻结主方程的一个view(varinf)为VIF表格
'多重共线性诊断:容忍度
vector tol=unit-r2 '利用公式计算TOL
'多重共线性诊断:回归系数方差分解法
freeze(tab_vcd) eq_m0.cvardecomp '
'多重共线性矫正:经济学和实践观察法
series x_rgnp=x2/x1 ' 构造新变量
equation eq_adj_man.ls y c x_rgnp x3 x4 x5 '回归新方程
'多重共线性矫正:逐步最小二乘回归法(后向逐步回归,p值标准为0.05)
equation eq_adj_step.stepls(back,btol=0.05) Y @ c X1 X2 X3 X4 X5 X6
' ===========================================================================
5.7 实验作业
就业情况的郎利数据: 表 5.1 给出美国1947-1961年间就业情况及主要影响因素的数据表。
| X1 | x1 | x2 | x3 | x4 | x5 | x6 | Ydata1 | Ydata2 | Ydata3 |
|---|---|---|---|---|---|---|---|---|---|
| id | x1 | x2 | x3 | x4 | x5 | x6 | 2015014495 | 2016010317 | 2016011222 |
| name | x1 | x2 | x3 | x4 | x5 | x6 | 刘琳 | 王雪明 | 韩双瑞 |
| class | x1 | x2 | x3 | x4 | x5 | x6 | 保险1601 | 保险1601 | 保险1601 |
| n1 | 83 | 509300 | 3740 | 2552 | 120287 | 1 | 64630.6 | 64630.1 | 64630.33 |
| n2 | 84 | 529500 | 3852 | 2514 | 121836 | 2 | 65777.740000000005 | 65776.649999999994 | 65776.23 |
| n42 | 400 | 9855900 | 5692 | 1405 | 218061 | 42 | 136890.85999999999 | 136889.85 | 136891.1 |
| n43 | 410 | 10171600 | 6801 | 1412 | 220800 | 43 | 136932.07 | 136933.24 | 136931.37 |
| n44 | 417 | 10500200 | 8378 | 1425 | 223532 | 44 | 136483.95000000001 | 136485.51 | 136486.79 |
变量说明见 表 5.8 :
| variable | label |
|---|---|
| Year | 年份 |
| Y | 就业人数(打) |
| X1 | 消费价格指数 |
| X2 | 名义GNP |
| X3 | 失业人数 |
| X4 | 军队人数 |
| X5 | 14岁以上的非机构人口数 |
| X6 | 时间趋势 |
请考虑如下样本回归模型:
\[ \begin{aligned} Y_t=\hat{\beta}_0+\hat{\beta}_1X_{1t}+\hat{\beta}_2X_{2t}+\hat{\beta}_3X_{3t}+\hat{\beta}_4X_{4t}+\hat{\beta}_5X_{5t}+\hat{\beta}_6X_{6t}+e_{t} \end{aligned} \tag{5.43}\]
请回答如下问题:
(1)根据回归模型 式 5.43 ,写出总体回归模型(PRM),并对参数的理论预期(符号、大小、关系)进行说明。
答:
PRM:
参数预期:
(2)利用Eviews对样本回归模型 式 5.43 进行回归分析(将报告截图过来,并写出相应的简要报告形式——三行式或四行式)。参数估计结果符合你的理论预期么?
答:
报告截图:
简要报告(三行式或四行式):
参数估计结果是否符合你前面的理论预期:
(3)数据中存在多重共线性的证据吗?(请以此按照下列方法进行诊断):
根据上题中主回归报告结果,观察t检验,判定系数,F检验的关系,请你得出关于多重共线性的初步结论。
答:利用Eviews绘制矩阵散点图(matrix scatter)(截图过来),请你得出关于多重共线性的初步结论。
答:
- 利用Eviews得到简单相关系数矩阵(截图过来),请你得出关于多重共线性的初步结论。
答:
- 利用Eviews进行辅助回归诊断(完成下表,并将8个辅助回归结果依次截图过来),请你得出关于多重共线性的初步结论。
答:
| 辅助模型 | 模型形式 | 判定系数 |
|---|---|---|
| Main | Y ~ X1 + X2 + X3 + X4 + X5 + X6 | |
| A1 | X1 ~ X2 + X3 + X4 + X5 + X6 | |
| A2 | X2 ~ X1 + X3 + X4 + X5 + X6 | |
| A3 | X3 ~ X1 + X2 + X4 + X5 + X6 | |
| A4 | X4 ~ X1 + X2 + X3 + X5 + X6 | |
| A5 | X5 ~ X1 + X2 + X3 + X4 + X6 | |
| A6 | X6 ~ X1 + X2 + X3 + X4 + X5 |
(4)请按下列要求完成下表和提问:
c.根据上述结果,请你得出关于多重共线性的初步结论。
| 辅助模型 | 模型形式 | 判定系数 | \(容忍度TOL_j\) | \(辅助模型 VIF_j\) | \(主模型 VIF_j\) |
|---|---|---|---|---|---|
| A1 | X1 ~ X2 + X3 + X4 + X5 + X6 | ||||
| A2 | X2 ~ X1 + X3 + X4 + X5 + X6 | ||||
| A3 | X3 ~ X1 + X2 + X4 + X5 + X6 | ||||
| A4 | X4 ~ X1 + X2 + X3 + X5 + X6 | ||||
| A5 | X5 ~ X1 + X2 + X3 + X4 + X6 | ||||
| A6 | X6 ~ X1 + X2 + X3 + X4 + X5 |
(5)计算病态数(Condition Numbers,K)和方差分解比率(variance-decomposition proportions,VDP。并根据分析结果,得出关于多重共线性的初步结论。
答:
(6)若存在多重共线性问题,那你会采用什么补救措施(如果有的话)?
- 简单剔除变量法——经济学和实践观察法。请写明剔除变量的理由,并将纠正后模型的Eviews结果截图过来,新模型减弱了多重共线性问题吗?
答:
- 简单剔除变量法——逐步回归法。将逐步回归后模型的Eviews结果截图过来,新模型减弱了多重共线性问题吗?
答:
- 主成分法(principal components)。将因子回归模型的Eviews结果截图过来,新模型减弱了多重共线性问题吗?(此题选作)
答:
【本次实验题目完毕啦!!】