为什么需要把数据进行数据库化?
数据不仅整理好了,也清理好了,是不是就可以分析研究了呢?
运用计算机就需要满足计算机对数据的要求,那就是数据库。
数据库化的目的就是为了便于分析和使用。基本的要求是通过数据库化,让数据格式化、结构化,符合统计分析、计算的要求。
网络数据库和分析数据库
数据的数据库化,就是把得到的变量、变量属性或者标签输入计算机,变成结构化的数据矩阵。从数据库化的目标来分,主要有如下两类:
计算机网络系统的数据库化,主要是用于存储数据,有各种类型的数据库应用程序。
常见的结构化数据库SQL数据库有有多种,比如开源的免费的My Circle。
分析计算用的数据库化,主要是通过建立数据库,用于统计分析软件的计算。
我们这里所学的就是这一类数据库化。
我们主要学习常用的运用于计算机单机统计计算与分析用的数据库化。
大数据的数据库化有不一样的特点和需求。
计算系统的数据库示例(SQL):医院档案
下面我们以结构化查询语言SQL为例,介绍计算系统的数据库。
某医院档案中有如下两个数据框:
计算系统的数据库示例(SQL):基本信息表和病人检查信息表
计算系统的数据库示例(SQL):创建SQL数据库
以下为R编程下的最简化SQL使用示例:
# 加载必要的包
library(DBI) # 用于构建数据库接口
library(RSQLite) # 用于创建SQLite数据库
# 数据库路径
db_path <- here::here("slide/slide-reveal/code/demo-sql/hospital.db")
# 创建或连接数据库
db <- DBI::dbConnect(RSQLite::SQLite(), db_path)
# 展示数据库文件
fs::dir_tree(here::here("slide/slide-reveal/code/demo-sql"))
D:/github/course-st/slide/slide-reveal/code/demo-sql
└── hospital.db
计算系统的数据库示例(SQL):把数据框写入数据库
# 把数据框写入数据库
dbWriteTable(db, "tbl_info", df_info)
dbWriteTable(db, "tbl_check", df_check)
# 查询数据库中存在的表格及名称
dbListTables(db)
[1] "tbl_check" "tbl_info"
计算系统的数据库示例(SQL):读取数据库中的表格
# 读取数据库中的表格tbl_info
dbReadTable(db, "tbl_info")
id name age
1 1 Alice 25
2 2 Bob 30
3 3 Charlie 35
4 4 David 40
5 5 Eve 45
6 6 Frank 50
7 7 George 55
8 8 Helen 60
9 9 Ivy 65
10 10 Jack 70
# 读取数据库中的表格tbl_check
dbReadTable(db, "tbl_check")
id blood_pressure heart_rate blood_type
1 6 120 70 A
2 2 130 75 B
3 4 140 80 O
4 8 150 85 AB
5 7 160 90 A
计算系统的数据库示例(SQL):查询数据库中的关联表格信息1
采用SQL语言分别查询信息:
# 采用SQL语言分别查询信息
## 分别从tbl_info和tbl_check获得所需要的信息
### 从tbl_info表获得病人的编号、名字和年龄
dbGetQuery(db, "SELECT id, name, age FROM tbl_info WHERE id = 2")
### 从tbl_check表获得病人的血压
dbGetQuery(db, "SELECT id, blood_pressure FROM tbl_check WHERE id = 2")
id blood_pressure
1 2 130
计算系统的数据库示例(SQL):查询数据库中的关联表格信息2
采用SQL语言一次性查询关联信息:
# 采用SQL语言一次性查询关联信息
## 使用JOIN连接两个表进行查询
dbGetQuery(db,
"
-- 这是SQL查询语法
SELECT i.id, i.name, i.age, c.blood_pressure -- 选择需要的字段
FROM tbl_info i /* 病人基本信息表,使用别名i */
JOIN tbl_check c /* 病人检查信息表,使用别名c */
ON i.id = c.id /* 通过id字段关联两个表 */
WHERE i.id = 2 /* 筛选编号为2的病人 */
"
)
id name age blood_pressure
1 2 Bob 30 130
计算系统的数据库示例(SQL):关闭数据库连接
最后,记得关闭数据库连接。
# 关闭数据库连接
dbDisconnect(db)
分析用途的数据库示例(SPSS)
SPSS是社会科学统计计算运用比较多的一个大型统计计算软件
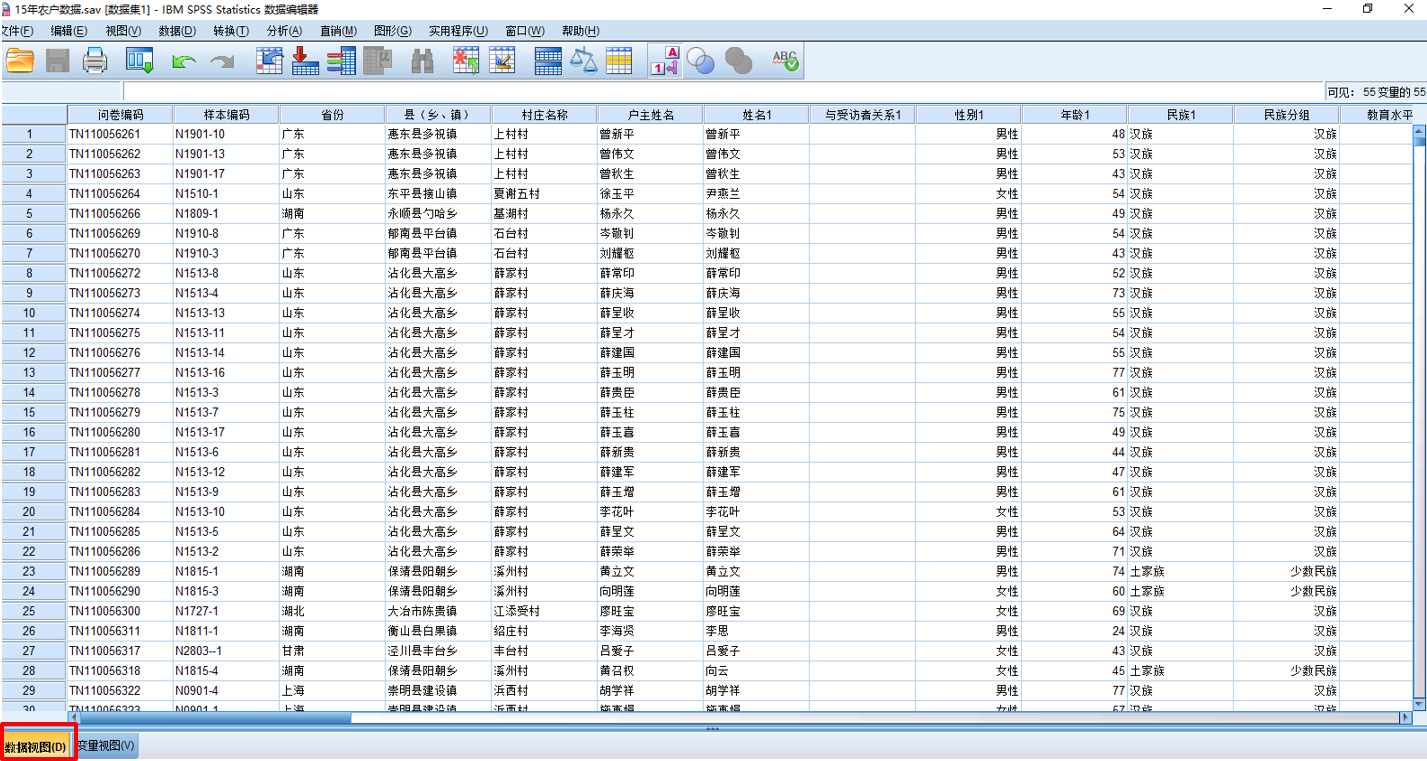
SPSS数据库的数据视图:
- 每一行代表样本,
- 每一列代表变量
- 中间单元格表示数据取值
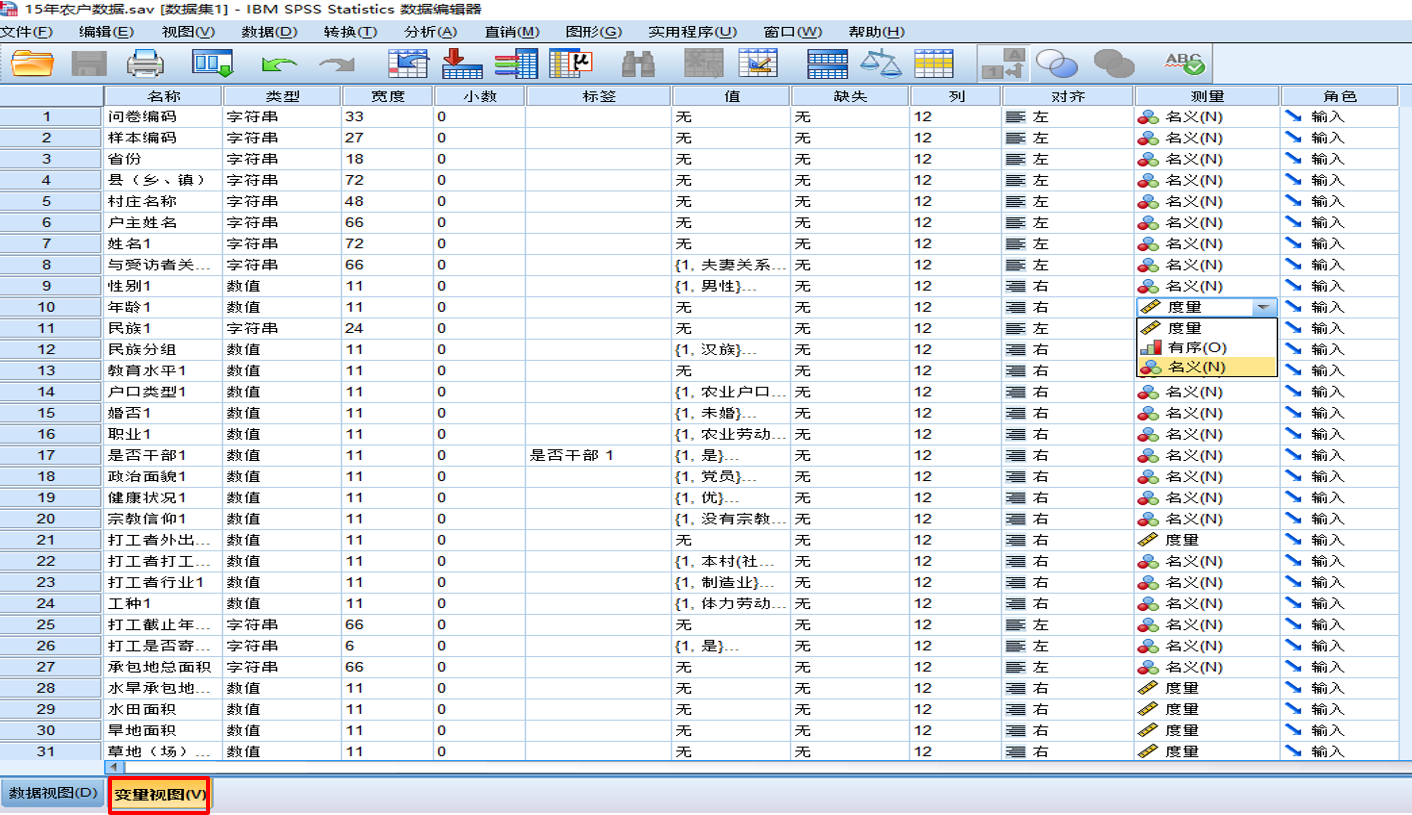
SPSS数据库的变量视图
调查数据库的主要步骤
问卷调查的数据,在完成了问卷的审核、归档、清理以后,在用于分析软件的分析之前,就需要把它转化为数据表示的数据库。通常有三个步骤:
第一步,编码。
- 在清理工作中,这项工作应该已经完成了,不过在数据入库之前还需要审核。
第二步,数据录入与转化。
- 如果是纸版问卷调查,这个时候就需要录入数据。建议采用专门的录入软件进行录入,尽量避免录入中出现的差错,进而降低调查误差。
- 如果是计算机辅助调查,这个时候就需要转化数据。无论是内容转化还是格式转化,也建议尽量采用可靠的工具,避免出现差错。
第三步,对录入完成和转化完成的数据,做基本的检验和清理。
调查数据库的编码
编码:就是把调查问卷的每一道访题用符号或者数字组合代码换,包括对每一道访题的选项或应答赋值。
调查数据库的编码示例
我们来看一道调查问卷中的一道提问:
【问题】1.5,请问您希望孩子念书,最高念到哪一个程度?(共7个选项)。
【选项】A.小学;B.初中;C.高中;D.专科、职高、技校、大专;E.大学本科;F本科以上;G.不必念书
对这套访题我们可以这样编码,访题可以编为B1.5。(为什么这么编?)
对选项的编码,就以选项的编号做编码。(你还可以怎么编?)
调查数据库的编码方法
问卷调查数据的编码,一般有三种方法:
第一:原始编码,就是直接运用问卷的编码。
- 通常这种方法仅仅用在访题数量极少,应答非常简单的情况下。
第二:先编码,在调查开始之前,编码工作就已经做好了。
第三,后编码,就是在问卷调查完成以后再做编码。
编码部相当于问卷数据的一个索引,把变量、变量值,变量标签关联起来,类似于一本问卷数据字典。
调查数据库的录入
对于简单的问卷调查,可以运用常用的办公软件或统计分析工具来做录入,
- MS Office Excel
- Mac Numbers
- SPSS
- Stata、statistica…
对于相对庞大复杂的问卷调查,需要使用专门的数据录入软件。
专用录入软件的能提高录入效率,并减少录入误差:
- 可把纸版问卷计算机界面化,把纸版问卷完整呈现在计算机屏幕上。
- 可通过对跳转、阈值、变量类型等的控制,尽量减少录入所带来的误差。
- 在录入完成以后,还可以直接把录好的数据导出为数据库表文件。
调查数据库的检验和清洗1/2
针对的已经数据库化的数据,通常需要运用统计分析方法进行检验和清洗:
第一,录入错误清理。可以把双录入的数据输出为一个清理数据库,核对录入中出现的冲突数据。
第二,编码清理。对不在编码值范围的变量值进行清理。
- 假设性别属性值的编码原本只有0和1,如果在数据表中出现了其它值,那就一定是哪里有错误了,就需要清理并且改正错误。
第三,逻辑清理。主要是针对基本事实逻辑的清理。
- 比如样本为男性,在是否怀孕的访题下,变量值说明他有怀孕记录,这就是逻辑错误
调查数据库的检验和清洗2/2
数据库检验和清洗还需要注意如下问题:
离群值:偏离了日常理解的范围,但实际上可能是有效值的一部分。
- 男性怀孕令人奇怪,女性怀孕就没有什么让人奇怪的了,对不对?
- 女性16岁-49岁之间怀孕都是正常的。如果数据显示有一位七十岁的老奶奶怀孕了, 有没有可能呢?
极大值和极小值, 都是需要再次确认的变量值。
无应答的处理,通过分析已经应答的数值,确定对无应答的处理方式,比如差值。
- 变量的再编码,在数据的清理中也可以产生衍生变量。
- 比如受教育程度或者年龄的重新分组
- 比如依据受教育程度和收入来建构社会经济地位
访谈调查数据库的主要步骤
对访谈调查的数据,在完成了访谈笔记的整理、格式化、归档、清理之后,在用于分析之前也需要把相关的信息录到数据库中。访谈记录与整理信息应该数据库化。
第一步,编码。
- 记录信息的编码(重点工作)
- 记录内容的编码(如果要进行文本分析,则需要此步骤)
第二步,录入。
- 录入访谈记录信息,便于检索,也便于查找。
- 如果要做内容分析,访谈内容就需要全部地录入。
第三步,清理。
- 一般需要逐行核查。内容数据是没有办法采用统计分析方法的进行核查。
访谈调查数据库的录入
访谈数据的录入工具:
要是涉及到数字数据的,就可以使用Excel、SPSS、Stata、Statistica、r等等
对文本数据,就可以使用Word,当然也可以使用Numbers和Pages。
对访谈内容,还可以采用内容分析软件,比如Nvivo、Aquad、ATLAS.ti和Qualrus。
文本数据库示例:大连理工大学情感词典库(简介)
中文情感词汇库是中文文本分析(如文本情感分析)的一个重要基础。
大连理工大学信息检索研究室在林鸿飞教授的指导下整理和标注形成一个中文本体资源。该资源从不同角度描述一个中文词汇或者短语,包括词语词性种类、情感类别、情感强度及极性等信息。
在进行文本情感分析时,可以采用该资源来构建情感词典。词库维护网站及词库下载(xlsx格式)链接http://ir.dlut.edu.cn/info/1013/1142.htm
文本数据库示例:大连理工大学情感词典库(说明)
中文情感词汇本体的情感分类体系是在国外比较有影响的Ekman的6大类情感分类体系的基础上构建的。
在Ekman的基础上,词汇本体加入情感类别”好”对褒义情感进行了更细致的划分,最终词汇本体中的情感共分为7大类21小类。
文本数据库示例:大连理工大学情感词典库(情感词汇举例)
文本数据库示例:大连理工大学情感词典库(情感分类定义)
文本数据库示例:网购红酒评论文本分析(消费者评论txt文件)
通过对红酒网购消费者评论的文本抓取,我们搜集得到了一个txt文件,文件中每一行都是一条消费者评论。
D:/github/course-st/slide/slide-reveal/code/demo-txt
├── wine-comment.txt
├── word-dict-daliang-instruction.doc
└── word-dict-daliang.xlsx
文本数据库示例:网购红酒评论文本分析(消费者评论内容)
[1] "红酒味道比较淡,不如其他国外经典品牌的红酒好喝。"
[2] "这款红酒口感不错,果香浓郁,单宁柔顺,回味悠长。"
[3] "包装很精美,适合送礼。"
[4] "价格有点贵,性价比不高。"
[5] "买了以后价格就降了,感觉被坑了。"
[6] "这款红酒口感一般,果香不足,单宁较涩。"
[7] "物流速度很快,包装完好无损。"
[8] "赠送的小礼品很贴心,很喜欢。"
[9] "差评,口感很差,不推荐。"
[10] "物流速度很慢,等了好久。"
[11] "上次买过这款红酒,口感很好,这次又买了。"
[12] "收到货后有破损,联系客服后很快就解决了。"
[13] "双十一的价格实在太香了,囤了几瓶。"
[14] "这款红酒口感很独特,值得一试。"
[15] "包装很用心,送礼很有面子。"
[16] "用了平台券,价格很划算。"
[17] "国产红酒也有这么好的品质,很惊喜。"
[18] "客服态度很差,解决问题不积极。"
[19] "包装很简陋,感觉不值这个价。"
[20] "口感很一般,性价比不高。"
文本数据库示例:网购红酒评论文本分析(分析结果-精简)
文本数据库示例:网购红酒评论文本分析(分析结果-原始)
文本数据库示例:网购红酒评论文本分析(R函数)
### 辅助函数:基于jiebaR分词====
### 同时考虑情感词典中的情感类型pos和强度intensity
analyze_sentiment <- function(text, sentiment_dict) {
# 创建分词引擎
seg <- worker()
# 文本分词并进行情感分析
sentiment_scores <- text %>%
# 分词处理
map(segment, seg) %>%
# 转换为tibble
enframe(name = "id", value = "words") %>%
# 展开词列表
unnest(words) %>%
# 与情感词典匹配
inner_join(sentiment_dict, by = c("words" = "word")) %>%
# 计算情感得分
mutate(
# 将pos转换为得分:褒义=1,贬义=-1,中性=0,兼有褒贬=0
score = case_when(
pos == 1 ~ 1,
pos == 2 ~ -1,
pos == 0 ~ 0,
pos == 3 ~ 0,
TRUE ~ 0
),
# 考虑情感强度
weighted_score = score * (intensity / 9) # 将强度归一化
) %>%
# 按文本ID分组统计
group_by(id) %>%
summarise(
# 统计词数
word_count = n(),
# 统计情感词数
positive_words = sum(score > 0),
negative_words = sum(score < 0),
neutral_words = sum(score == 0),
# 计算得分
total_score = sum(weighted_score),
# 计算平均强度
avg_intensity = mean(intensity),
# 计算情感倾向(正负比例)
sentiment_ratio = (positive_words + 1) / (negative_words + 1),
.groups = "drop"
)
return(sentiment_scores)
}
文本数据库示例:网购红酒评论文本分析(R分析)
### 使用示例
results <- analyze_sentiment(
text = tbl_txt$comment,
sentiment_dict = sentiment_dict
) %>%
# 与原始文本合并
left_join(tbl_txt, by = "id") %>%
# 添加情感标签
mutate(
sentiment_label = case_when(
total_score > 0 ~ "正面",
total_score < 0 ~ "负面",
TRUE ~ "中性"
)
)
观察数据的数据库化主要步骤
观察数据怎么数据库化呢?主要也是三个步骤:
第一步,编码。
- 观察调查数据的编码与其他编码不一样的地方在于观察记录信息比访谈记录信息要丰富得多。当然对观察记录的内容,如果希望用作分析素材,也需要编码。
第二步,录入。
- 在大多数情况下,主要录入观察记录信息,同样,如果要把观察记录的内容作为统计分析的素材,那么也需要把它录到数据库中。
第三步,清理。
- 同样在录入完成之后,要对已经录入的数据进行核查,如果有观察记录的内容,就需要对已经数据库化的内容做仔细的核查,确保内容准确。
观察数据的数据库化编码
观察数据的编码主要包括两个方面:
观察数据的数据库化录入
观察记录的录入:
文本数据、数字数据的录入。采用word或pages录入。
图片数据的录入。可以采用类似于Adobe的Lightroom之类的数据库。可以先扫描,再录入记录信息。
视频数据的录入,则可以运用类似于Adobe Premier之类的编辑库。
音频数据的录入,也可以寻找适用的音频数据库。
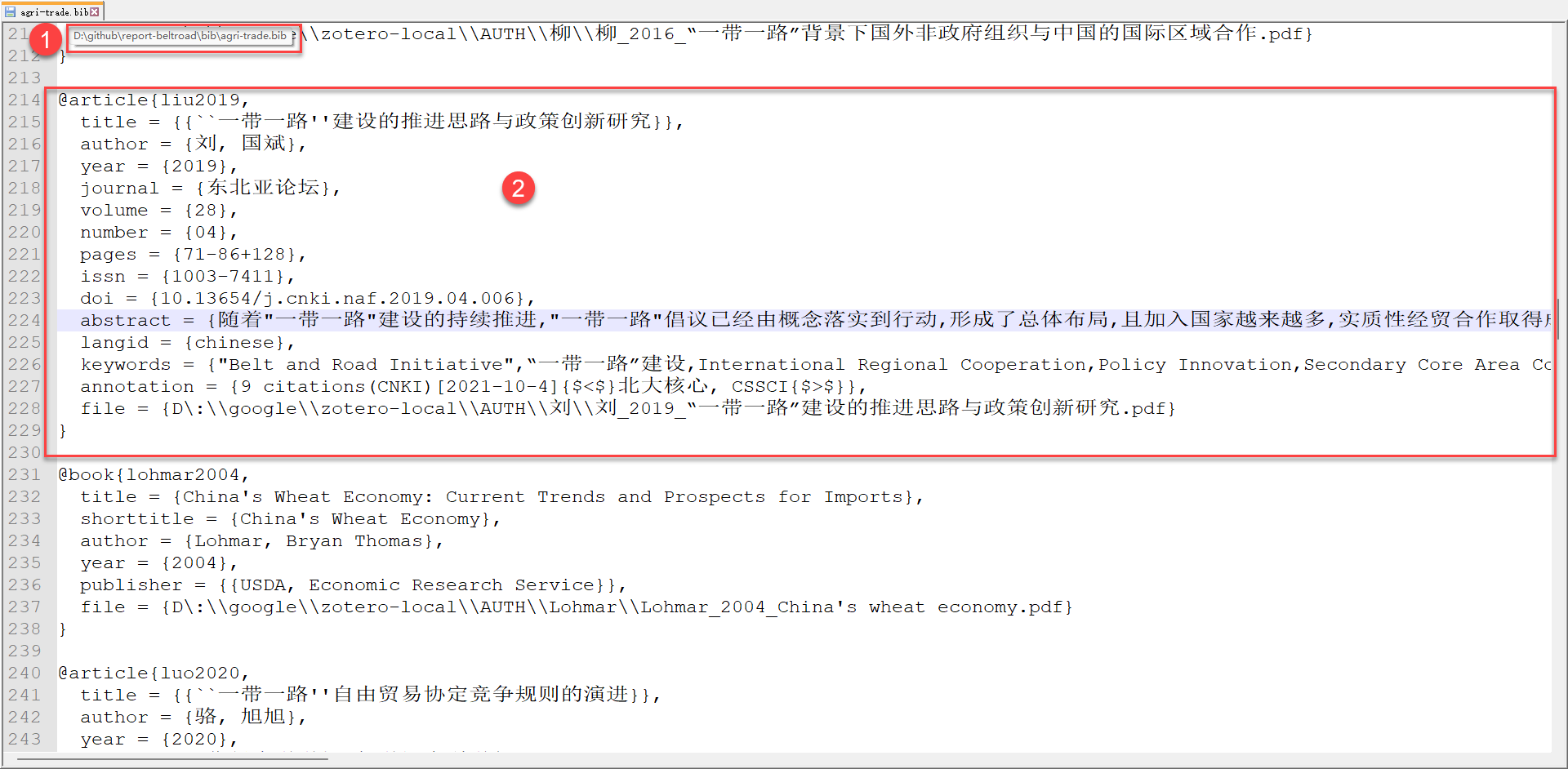
文献数据库的编码
为了确保同学们已经掌握了文献编目信息,我重复一遍文献的编码。
文献记录信息的录入和管理。
- 基本变量主要有作者、篇名、时间、载体、存放、DOI,或者ISBO,或者ISNN等。
- 文献记录的编码可以直接运用文献记录的原始编码,一些数据库化的数据,比如
jasdo,还支持编码的数据直接导出。
- 专门的信息录入和文献管理软件:
Zotero、Endnote和papers。
文献内容信息的录入和管理。
- 主要管理的是文献内容、阅读笔记、思路图谱、总结要点等
- 专门的内容录入和关系管理软件:
onenote、Mindmanager、印象笔记等。
旱区农业科技资源配置情况研究
研究议题:旱区农业科技资源配置情况研究。具体研究内容如下:
2.1 科技装备
- 2.1.1 农业机械动力
- 2.1.2 农用拖拉机
- 2.1.3 农用灌溉机械
- 2.1.4 农用收获机械
- 2.1.5 农业化学要素
2.2 科技投入
- 2.2.1 公共财政投入
- 2.2.2 RD研发投入
2.3 科技计划
- 2.3.1 重大基础类科技计划
- 2.3.2 国家自然科学基金
- 2.3.3 农业综合开发投入
2.4 科技条件
- 2.4.1 国家工程技术研究中心
- 2.4.2 国家重点实验室
2.5 科技服务
- 2.5.1 国家农业科技园区
- 2.5.2 技术示范转移机构
- 2.5.3 高技术产业和科技企业
资料和数据
研究对象:旱区16个省份——北京、天津、河北、山西、内蒙古、辽宁、吉林、黑龙江、山东、河南、西藏、陕西、甘肃、青海、宁夏、新疆
文本资料:政府公开资料、公共信息、图书、文献…
数据资料:统计年鉴、网页数据、商业数据库信息…
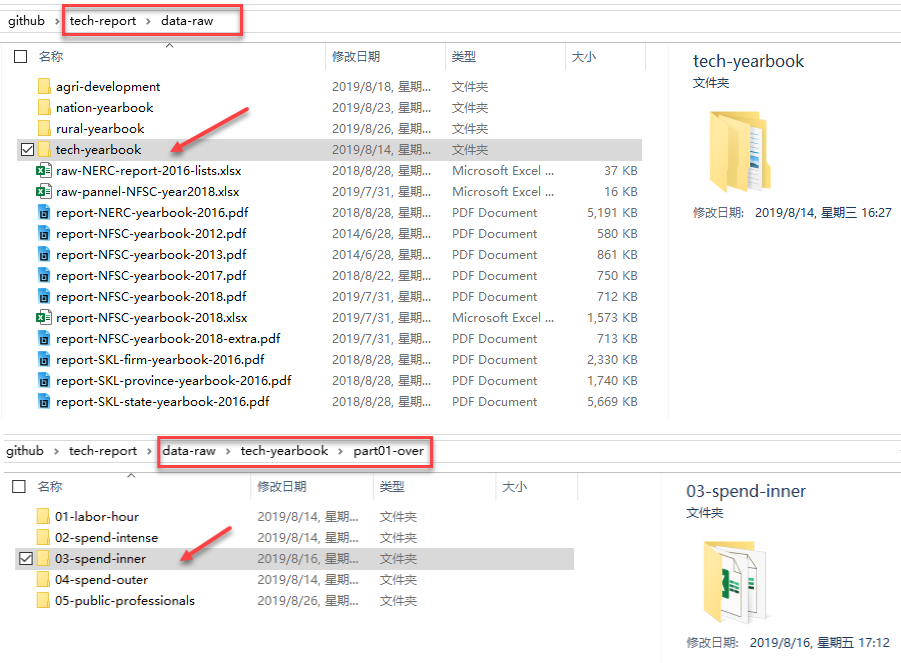
资料整理
文件夹管理:
- 文献资料文件(material):收集到的各种相关资料(.xlsx、.word、.pdf、.html、.png等)
- 粗制的数据文件(raw data):摘录、数值化(.xlsx)
- 提取的数据文件(extract data):整合、合并(.xlsx)
- 加工的数据文件(process data):更新、维护(.xlsx)
- 分析的数据文件(analysis data):调用、子集化(.xlsx)
0. 文献资料1
囊括了研究涉及的全部材料
分门别类在各个文件夹下
形成目录树
文件以原始状态存放
格式各种各样
文献资料1-1
历年的《中国科技统计年鉴》
数据来源:人大经济论坛;中国知网-统计年鉴数据库
部分年鉴数值化(.xls)
部分年鉴仅是数字化(.caj)
每本年鉴都有目录
年鉴中仅部分内容跟研究相关
文献资料1-2
历年《国家工程技术研究中心》资料
数据来源:科技部网站
- 部分资料以年度报告呈现(.pdf)
- 部分资料以公开网页呈现(.html、.doc)
- 资料发布时间不确定
- 资料非标准化,需手工收集整理
文献资料1-1-1
《中国科技统计年鉴2018》
数据来源:人大经济论坛
该年鉴已数值化(.xls)
年鉴统计资料依次以.xls格式呈现
具体文件含义可以查看目录
年鉴中仅部分.xls跟研究相关,需要提取出来
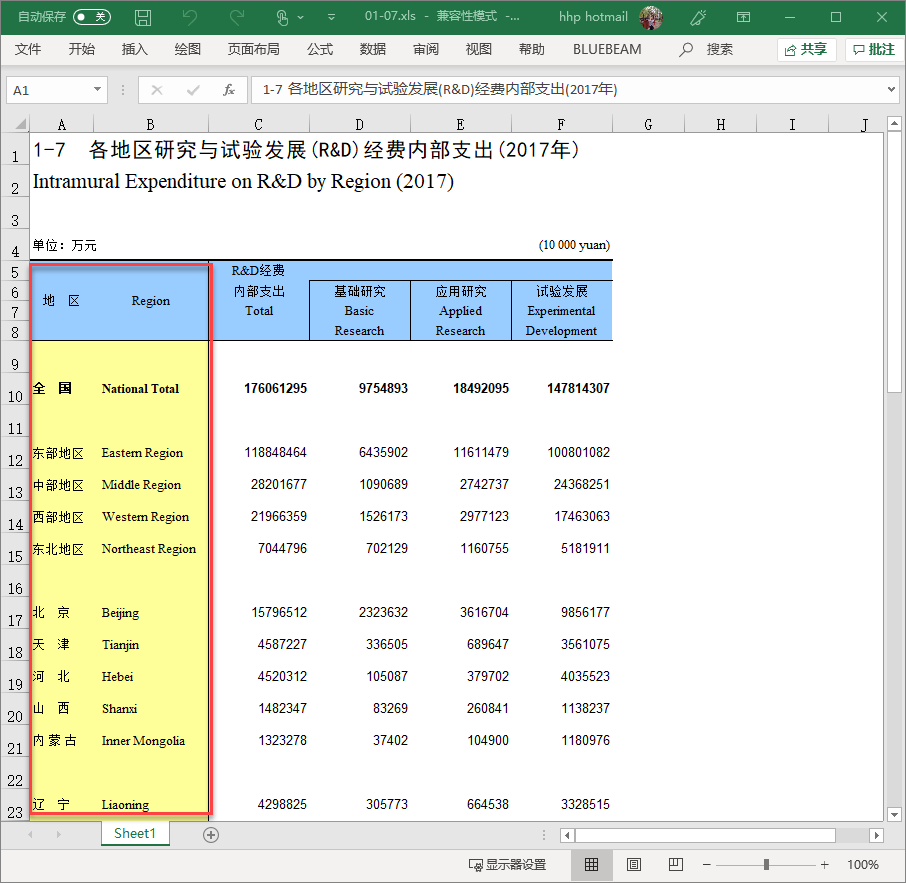
文献资料1-1-1-1
《中国科技统计年鉴2018》
数据来源:人大经济论坛
“表1-7 2017年中国RD支出类型”
原始表格有各种”烦人状况”!
- 看行:空行?字符有空格?意外字符?
- 看列:列变量?中英文?跨多行?
- 看单元格:数值(number)还是文字(character)?
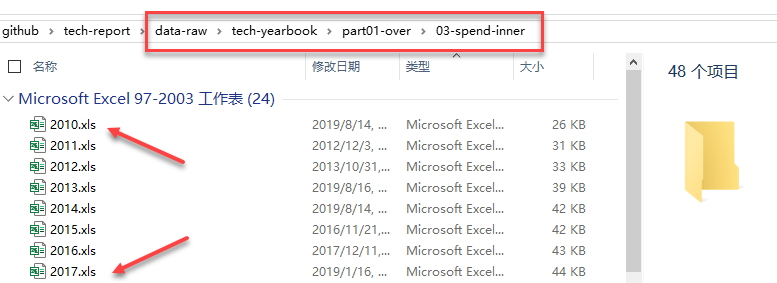
粗制数据(raw data)1
《中国科技统计年鉴2010-2018》
数据来源:人大经济论坛
- 各年年鉴整合
- 不按年份,而按内容来管理文件夹
- 文件夹命名坚持用英文!
粗制数据(raw data)2
《中国科技统计年鉴2010-2018》
数据来源:人大经济论坛
表 中国RD支出类型”(.xls)
取你所需!
- 每年的表格来自每年的年鉴
- 每年的表格单独命名
- 文件命名要有规则
- 确保每个文件的行列数据保持一致!
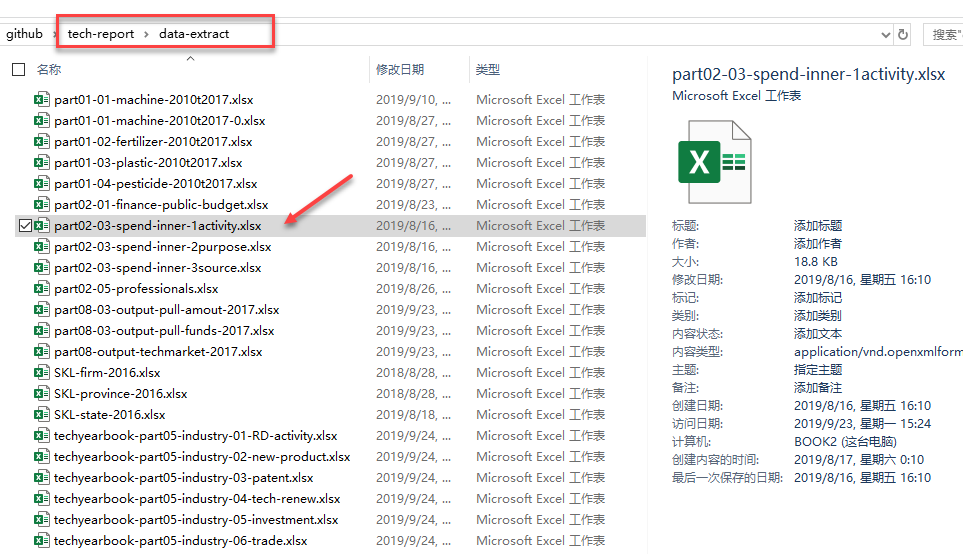
《中国科技统计年鉴2010-2018》表 RD支出类型(2010-2017)
数据来源:人大经济论坛
- 依次读取整合每一年的表 中国RD支出类型.xls”
- 统一变量命名
- 分别写入年份信息
- 行合并年度文件数据
- 确保数据是正确读取的!
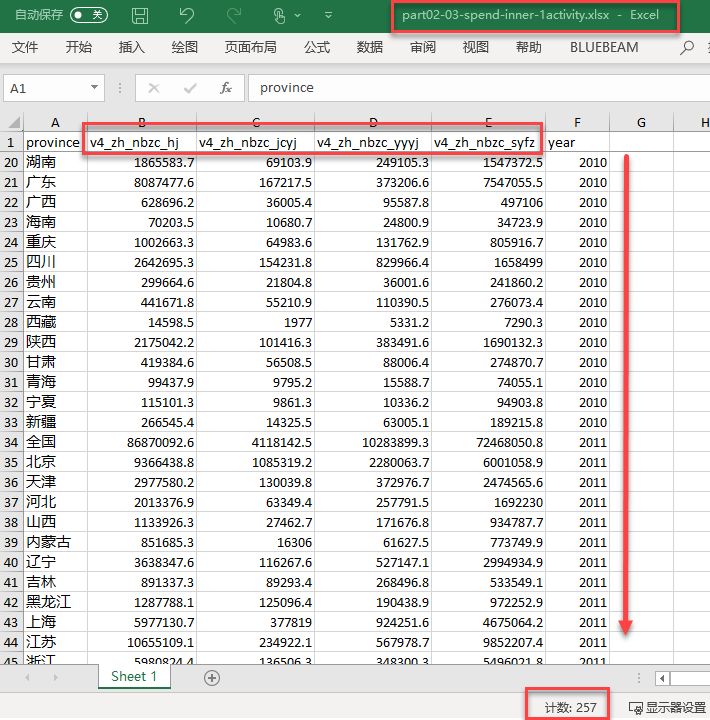
《中国科技统计年鉴2010-2018》
数据来源:人大经济论坛
基本保持原来的数据形态:
- 看行(257行):无空行、地区字符正确标准
- 看列:列变量统一命名
- 看单元格:全部是数值(number)
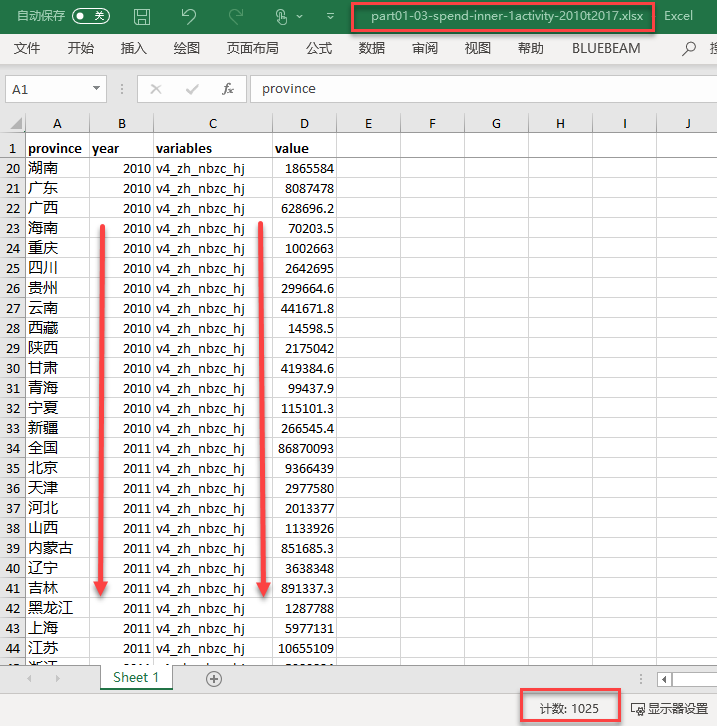
加工数据(process data)1
《中国科技统计年鉴2010-2018》
数据来源:人大经济论坛
需要继续对数据形态加工变形
目标是标准化的数据集!!?
加工数据(process data)2
《中国科技统计年鉴2010-2018》
数据来源:人大经济论坛
这是一份标准化的数据集!!!
- 看行(1025行):按年度(year)、按省份(province)
- 看列:4个变量被折叠对方为1列(variables)!
- 看单元格:全部数值被折叠对方为1列(value)!
分析数据(analysis data)1
《中国科技统计年鉴2010-2018》
- 完整的RD数据集(part01-over-2010t2017.xlsx)
数据来源:人大经济论坛
每一个数据子集被加工完成后,需要继续进行整合
目标是一个标准化的完整数据集!!?
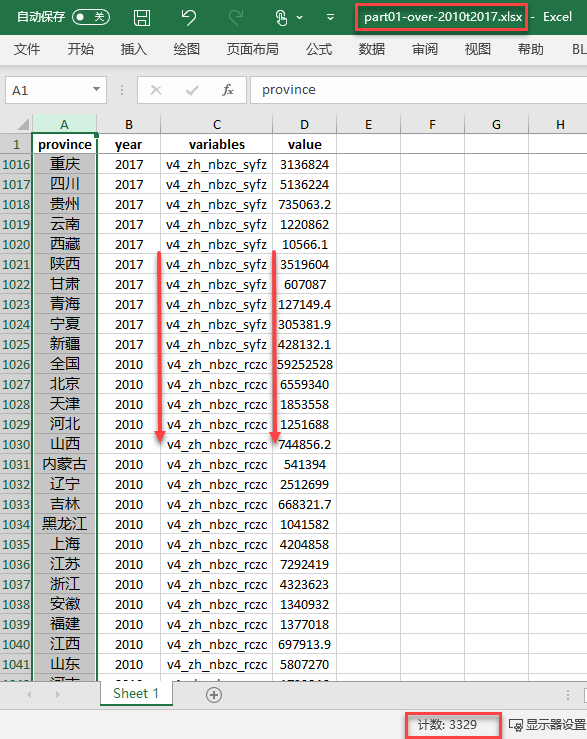
分析数据(analysis data)2
《中国科技统计年鉴2010-2018》
- 完整的RD数据集(part01-over-2010t2017.xlsx)
数据来源:人大经济论坛
- 这是一份完整的、标准化的数据集!!!
- 看行(3329行):按年度(year)、按省份(province)
- 看列:全部变量被折叠对方为1列(variables)!
- 看单元格:全部数值被折叠对方为1列(value)!
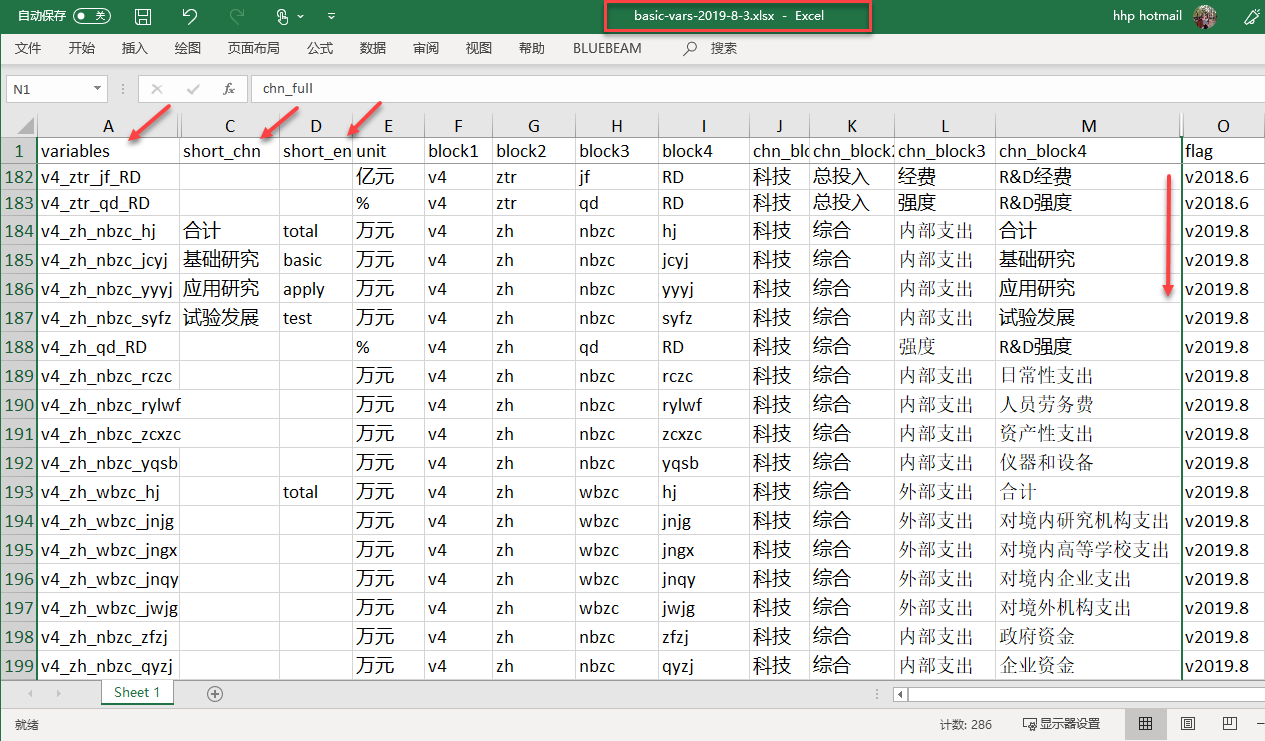
数据和变量关联与管理2/2
原始文件没有变量?
变量形式与其含义?
- 唯一识别变量名(variable):v4_zh_nbzc_hj、v4_zh_nbzc_jcyj、v4_zh_nbzc_yyyj、v4_zh_nbzc_syfz
- 中文变量名(short_chn):合计、基础研究、应用研究、试验发展
- 英文变量名(short_eng):word、word_cat、word_mean_num、word_mean_order、senti_cat、intensity、pos、senti_cat_aux、intensity2、pos2
变量命名如何动态调整?
- 备注变量系统的版本号(flag):v2018.6、v2019.8、v2019.9