统计学原理
(Statistics)
第2章 数据收集、整理和清洗
2-3节 资料整理和数据清洗
Hu Huaping (胡华平)
huhuaping01 at hotmail.com
经济管理学院(CEM)
2025-02-20
2.3 资料整理和数据清洗
资料整理的流程
主要步骤
在数据收集过程中,重要的是条分缕析。
- 分类存储
- 依据数据的载体类型、研究的时间需来进行分类,采用合适存放工具进行存放。
- 纸版问卷,不能随便堆放,需要按照一定分类标准进行存放,便于后续工作。
- 建立目录
- 存放的目的不仅仅只为了存储,更重要的是为了便于使用,建立目录就是便于利用的方式之一。
- 目录是用于检索的,对调查获得数据建立目录,也是为了方便检索。
- 编制索引
- 对于复杂数据,还需要在目录与存储之间建立关联,这就是索引
资料整理的记录
记录的内容
数据收集和整理中不仅需要核实,还需要记录。主要记录:
数据来源信息:
- 如调查项目,调查人, 采集人,采集时间,地点,对象。
数据载体类型信息:
- 具体是什么载体? 比如,纸张的、数字的。
数据描述信息:
- 有多大规模,什么内容,关联什么主题,等等。
数据分类信息:
- 无论是按照载体形态分类还是按照其他标准分类,一个大型项目需要对原始数据根据数据使用,建立基本分类。
数据存储信息:
- 数据以什么样的载体,什么样的方式存储在什么位置?
- 与数据安全相关的信息,如存储的版本、份数、时间变化关系等。
资料的安全
版本可检索
“老师,能把上星期发给我的课件再发一遍吗?我忘记放到哪了?”
“老师,非常的崩溃!电脑的硬盘坏了,写的东西都没有了!”
上述记录信息要尽可能的保存若干个版本。
纸和笔的传统版本。便于在需要的时候翻阅,尤其是使用范围相对较广的数据。
数字化可检索的版本。为什么要做数字化的可检索版本?
目录树法(相对简单的数据)
建立专门的数据库(针对异常复杂或庞大的数据)
多个备份源
数字化数据有一些需要特别注意的问题:
数据存储。随时都有若干个备份!
- 数字化的数据从最初的纸袋到今天的磁盘、硬盘,有各种介质。由于介质的可靠性不同,数据的安全性也不相同。
- 美国的“911”事件。美国联储会的主席格林斯潘知道这个消息的第一时间,他担心的 不是“911”的伤亡情况,而是美国金融数据的安全。
数据安全。安全的风险,要么来自于使用者的误操作,要么来自于内部或者外部的有意攻击。
- 离线保存的目的不仅仅是为了应对各种预想不到的不测,更重要的是为了防止数据泄露。
- 斯诺登事件:任何在线数据事实上都是不安全的,都有安全隐患。
不可抗力与人为因素
文本数据的安全:
文本数据的安全威胁主要来自于不可抗力的一些因素,比如说自然灾害、风蚀等。
当然也来源于人为因素。比如说错误的识别,本来是很重要的数据,却被当作了废纸。
非数字化数据的安全:
图片数据的载体形态比较复杂,胶片、图片由于介质存储特征的差异,不可以混合放置而保管。如胶片就需要防潮,通常要使用防潮器皿。
实物数据的安全具有独特性,应根据实物实物特征进行科学整理和安全管理。比如说兵马俑,那就在兵马俑的原址上盖一个博物馆进行整理。
数据清洗的内容
真实性和完整性评估
数据整理主要是分类和梳理,数据清洗主要讨论的则是检错。通过这两部分的工作减少人为的误差,降低调查误差。数据清洗包括四个工作内容:
真实性评估:确认数据是真实的,不是道听途说,不是张冠李戴,更不是杜撰臆想。
“假新闻”现象就是调查数据在真实性层面出现的问题。
微信群里“令人发指”的各类长辈转发
完整性评估:数据应与研究工作的目标要求相符,研究不需要的就不应该出现在数据中,研究需要的在数据中就不应该缺少。
如果需要补值,就应继续补充收集数据。
可用性和错误性评估
可用性评估:数据是不是可以用于数据库化了?如果不能,还需要做怎样的数据加工?
- 比如对图片数据、 音频、视频数据,甚至文本数据是不是还要做数字化工作。
- 对于痕迹数据,尤其是大数据,如果不是直接采用大数据分析,而是应用于单机分析或服务器分析,是不是还要根据数据量进行抽样。
- 脱敏化处理。对有可能泄露受访者隐私、泄露传感器使用者隐私的部分,还需要做匿名化工作。
错误性评估:评估数据可能的错误来源、可能的错误大小,及其对数据质量的影响。
(示例)调查问卷的数据清洗内容
以调查问卷数据的清洗为例:
真实性的清洗:要确认数据来自于受访者。
完整性的清洗:主要看样本无应答,也就是一整份问卷没有应答。以及选项无应答,也就是应该应答的访题没有应答。
可用性的清洗:主要是看编码是否完成,权数是否可行,以及缺失值如何标记和处理。
错误性的清洗:主要是清洗调查环节的错误,比如样本错误、应答人错误、应答方式错误。
数据清洗的记录
记录的内容
清洗数据工作中的每一项活动都要有记录。记录信息包括:
清洗工作记录
清洗工作的信息记录:
- 数据清洗每一个步骤的做法、参与人、时间、地点、过程信息。
清洗内容记录
与清洗内容相关联的信息记录:
- 数据真实性信息。比如是否真实?是否存在编造、作弊嫌疑?哪些部分存在不真实? 怎么样不真实?。
- 数据完整性信息。比如是否完整?是否有缺失?如果有缺失,哪些部分缺失?缺失哪些数据?
- 数据可用性信息。比如问卷数据是否加权?痕迹数据是否数据化了?大数据如何处理?是运用云计算策略,还是裁剪为单机计算容量?
- 数据错误性信息。比如问卷数据中的缺失,文献数据中的差错等。
示例:一次对原始数据的清洗记录1

示例:一次对原始数据的清洗记录2
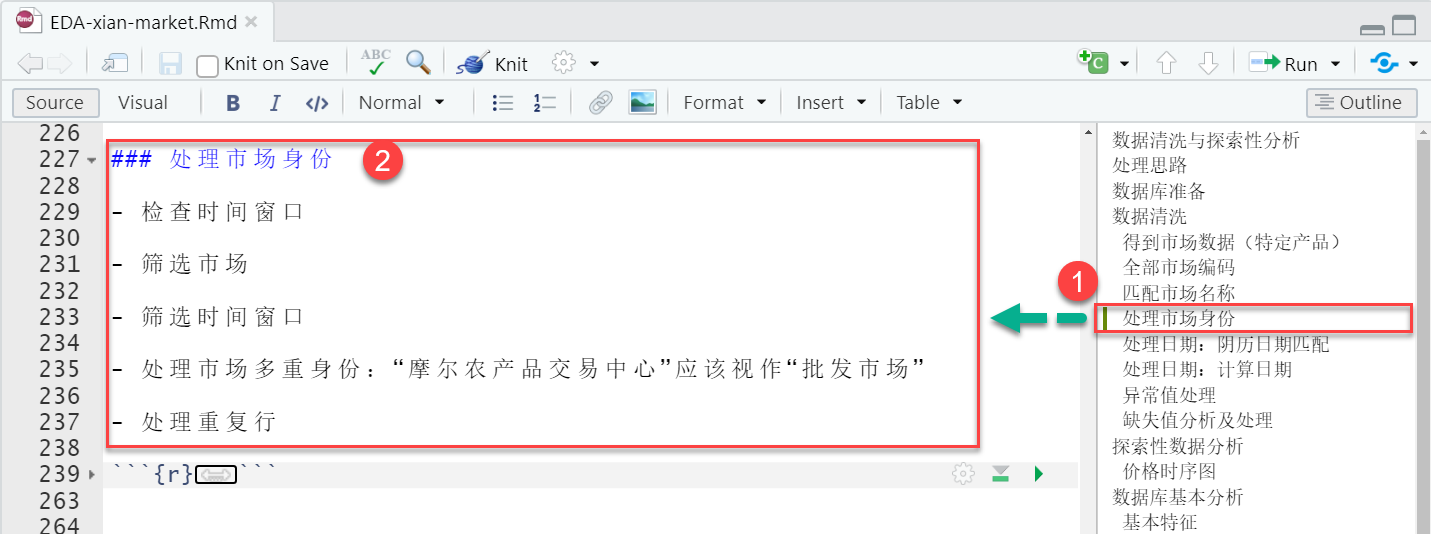
示例:一次对原始数据的清洗记录3
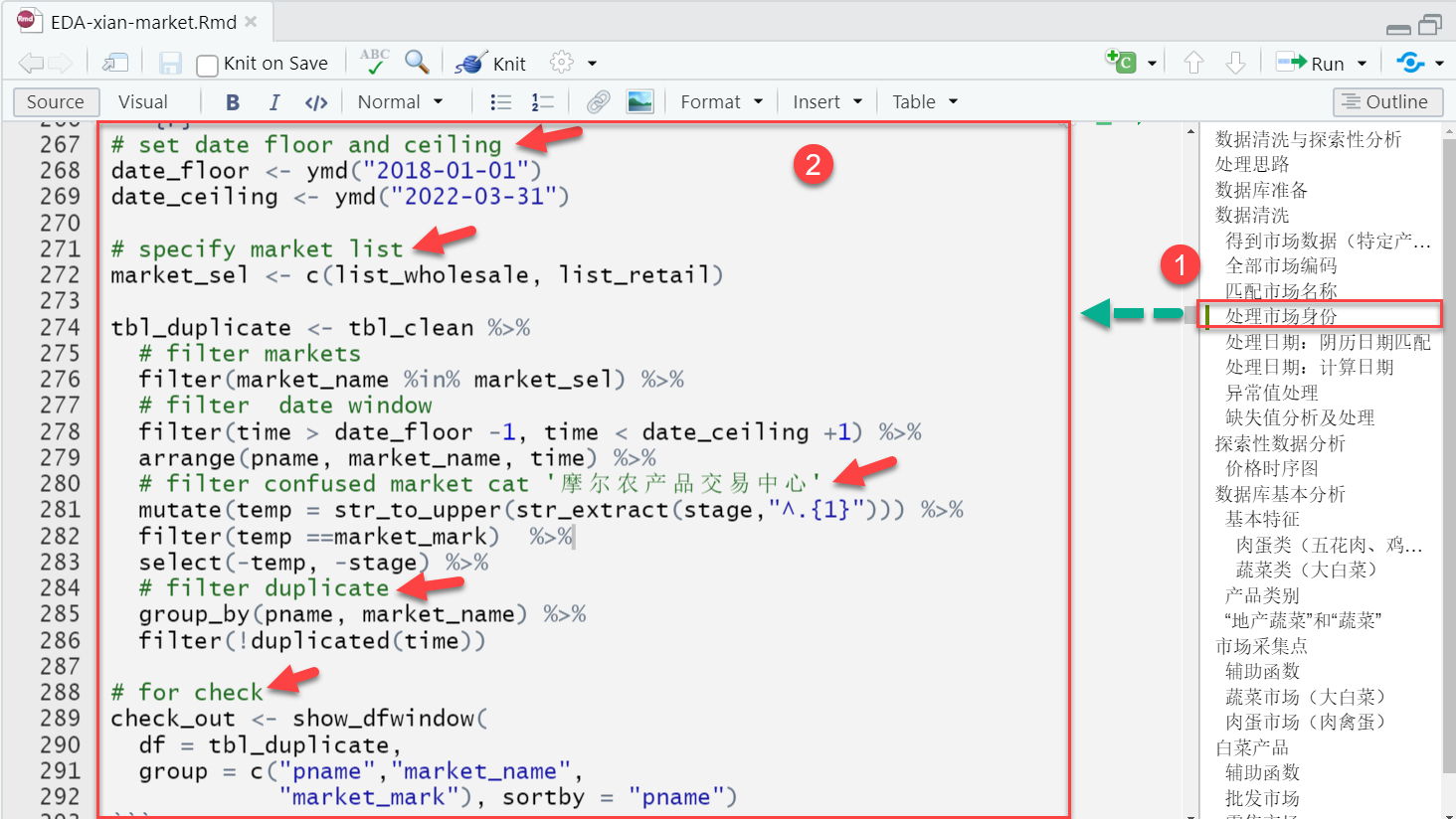
数据清洗的安全
笔记整理
数据清洗的记录信息应尽可能地保留若干不同的版本。一般包括纸笔版本和数字化版本。纸笔版本便于随时翻阅,数字化版本,便于交流,也便于检索。
笔记的整理。不管是哪一类的笔记,所有的笔记都有私用和公用之别,通常人们做笔记都是做给自己看的(私用笔记)。
你把自己的笔记给别人看,别人能看懂吗?
在正式使用之前,需要把笔记数据通过整理,变成任何使用者都可读的笔记(公用笔记),
这就是格式化问题,就是把你个人的笔记整理为数据笔记。
音视频整理
对音频要抄录:
把语音文档,不管是磁带录音,还是数字录音,抄录为文字,表述为文字或者文字加图片这样的格式。
数字录音还有一个格式清洗问题,不同数字设备的录音,可能会 采用不同的格式。
比如olympus的早期设备,采用的就是它自己的格式,DSS格式;如果不是采用它自己的软件就读不出来,最好呢,是转化为通用的格式,比如mp3格式。
对视频清洗编码:
如果是非数字录像,最好先转化为数字格式
如果已经是数字录像,对视频清洗编码需要给出时间记录码。
几点忠告
哦,已经数字化了,可以扔了,那个没用了,可以扔了。
不要轻易地丢弃任何一段看起来没有用处的信息,信息载体。
清洗不是仍东西,是清洗数据,让数据清晰化。
清洗的目的就是将特异性的数据,转化为公共性的数据、分析研究者都可以读的数据。
在清洗的过程中,千万要保留原始观察记录。
一般而言,原始问卷至少要保留十年以上,访谈记录和观察笔记一般要求永久保留。
数据清洗操作
观测性数据
以观察性研究中数据的清洗为例:
观察性数据有一个特点就是差异性,对同一个场景、同一个事件,不同的人去观察,看到的并非完全一致。
每个人的观察记录,都有自己的习惯,有的习惯于采用速写和密写,比如说有些人为了防止别人看他的笔记,长采用密写的方式。 即使是结构式的观察,不同的观察者也会有特异性。
观察性数据的清洗就需要把各类个性化的个人观察数据转变为标准化的观察记录。
文献数据
以文献数据的清洗为例:
笔记的清洗。 比如说:研究用的素材如文献的阅读、标注与笔记、摘录,如果希望未来继续使用,那就需要格式化清洗,把素材转化为数据。如果有必要,还可以为下一步的数据库化做准备,比如编码。
文献的清洗。对阅读过的文献,如果已经获得了数字版本,就需要与数字版本关联的编目信息、阅读信息关联起来整理,结合后边讨论的数据库化工作,把它们转化为个人档案馆。如果没有数字化的版本, 则需要将文献信息与阅读笔记信息关联,结合后边讨论的数据库化工作,把它们变成个人的档案阅读目录数据馆。
痕迹数据
对痕迹数据的“四性”评估和清洗,一般是直接依据数据的来源来确认的。比如,来自于网络爬取的数据,和来自于数据拥有者机构提供的数据,其它的平行数据等等。
一般而言,如果数据来源的渠道没有问题,数据的四性就不会有太大的问题。 清洗痕迹数据最重要的一项工作,就是把非格式化数据 清洗为格式化数据(Why?至少目前的分析工具还不支持直接分析非格式化的数据)
数据格式化:把混杂在一堆数据中的各类数据清洗出来,分门别类。比如说日志数据中的用户行为数据,以淘宝数据为例,订单数据、发单数据、物流数据等等,分门别类整理出来。
数据结构化:把各类数据和变量进行多维度关联。比如把以上日志数据中的各个子集关联到用户之下,形成类似于问卷调查数据的每个样本数据。
大数据
如果痕迹数据是大数据,情况就有些不同了。
在清洗数据之前,需要把清洗策略测试一遍,然后就可以直接采用大数据的清洗模式了。
从大数据中抽取数据,或者是从网页上爬取数据,在处理中尽管不一定会用到云计算, 在处理逻辑上还是一致的。
大数据的清洗,目前运用比较普遍的是Hadoop框架下的Map Reduce。
(示例)阿里巴巴的大数据清洗1/2
阿里巴巴有淘宝、天猫、一淘等等业务,这些业务每时每刻都在产生数据,这些数据涉及到信用、金融、物流、管理等等业务操作。
所有这些操作的数据都会汇集到数据交换平台,由此构成了阿里巴巴的数据动态。
超大数据流
2014年的双十一期间,6个小时之内的处理量就已经达到了100个PB。
在产生的这些数据中,既有结构化的数据,也有非结构化的数据,进出数据平台的数据不是个,不是匹,而是流。
这些数据流,通过数据处理就变成了中间层的数据,可以运用和应用于服务,中间服务,既可以对内,又可以对外。
(示例)阿里巴巴的大数据清洗2/2
问题是,这些数据是怎么处理的呢?数据清洗关心的正是这个问题。
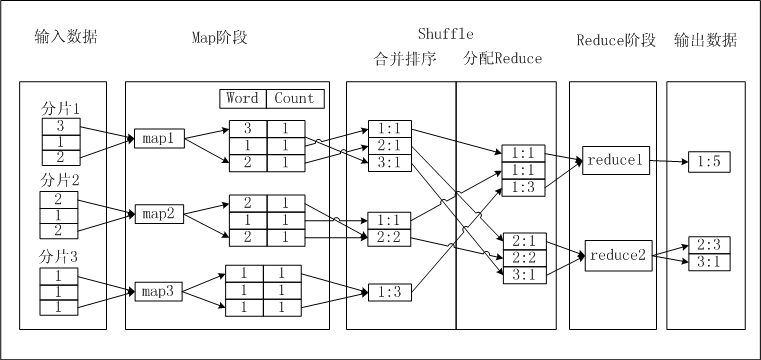
(示例)CGSS数据的清洗:介绍
中国综合社会调查(China General Society Survey,CGSS):
CGSS2013, CGSS2015
属于混合截面数据:也即不同年份的观测单位不是固定的。
我们这里的
CGSS2015数据集,其存放文件格式CGSS2015.dta,这是一种Stata软件的典型标签化(labelled)数据格式。CGSS2015数据集一共有样本数10968,变量总数有1398
数据集标签labels
数据集的标签(labels)属性一般有 3 种类型:
变量标签(variable’ labels):变量的简短描述
值标签(value’ labels):与特定值相关的标签,例如M=男;F=女。
缺失值标签(Missing values’ labels):具体又包括(1)用户定义的缺失值(
SPSS样式),例如定义标签值999表示该题项没有回答;以及(2)标记NA缺失值(Stata和SAS风格)。
(示例)CGSS数据的清洗:数据视图
随机抽取300份样本的前20个变量。CGSS2015数据(样本数=10968)数据如下:
(示例)CGSS数据的清洗:变量视图(全景)
(示例)CGSS数据的清洗:变量视图(局部)
(示例)CGSS数据的清洗:缺失值1
挑选出如下几个变量来观测:
(示例)CGSS数据的清洗:缺失值2
挑选出如下几个变量来观测。CGSS2015回答情况一瞥(随机40个样本):
(示例)CGSS数据的清洗:变量处理
代码型变量名VS研究型变量名
代码型变量名往往难以直接用于分析(但适合进行数据库管理),因此需要先进行转译为研究型变量名,从而便于人类理解和记忆。
(示例)CGSS数据的清洗:异常值处理前
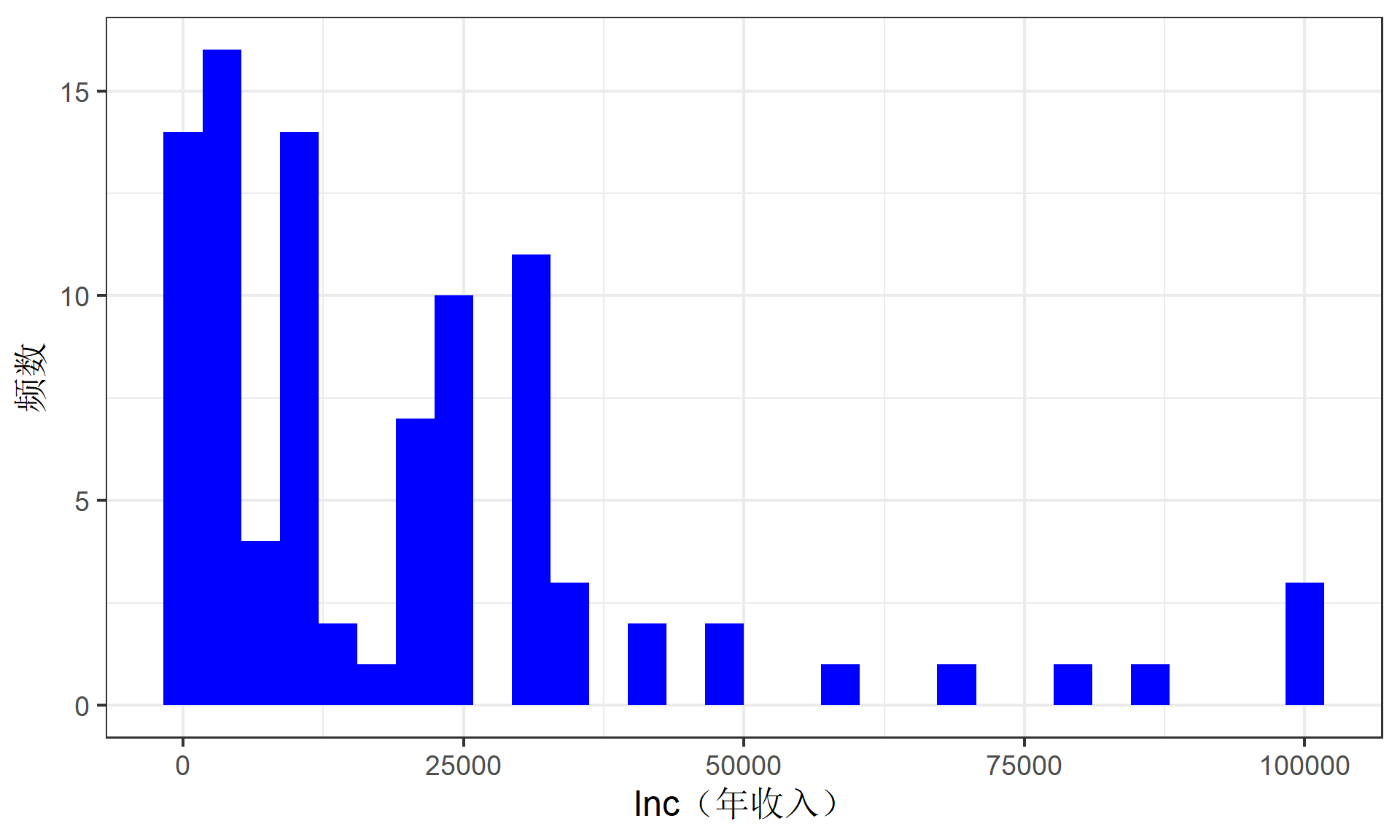
(示例)CGSS数据的清洗:异常值处理办法
异常值的处理办法:
截尾:比如截掉大于0.99分位数的观测值。
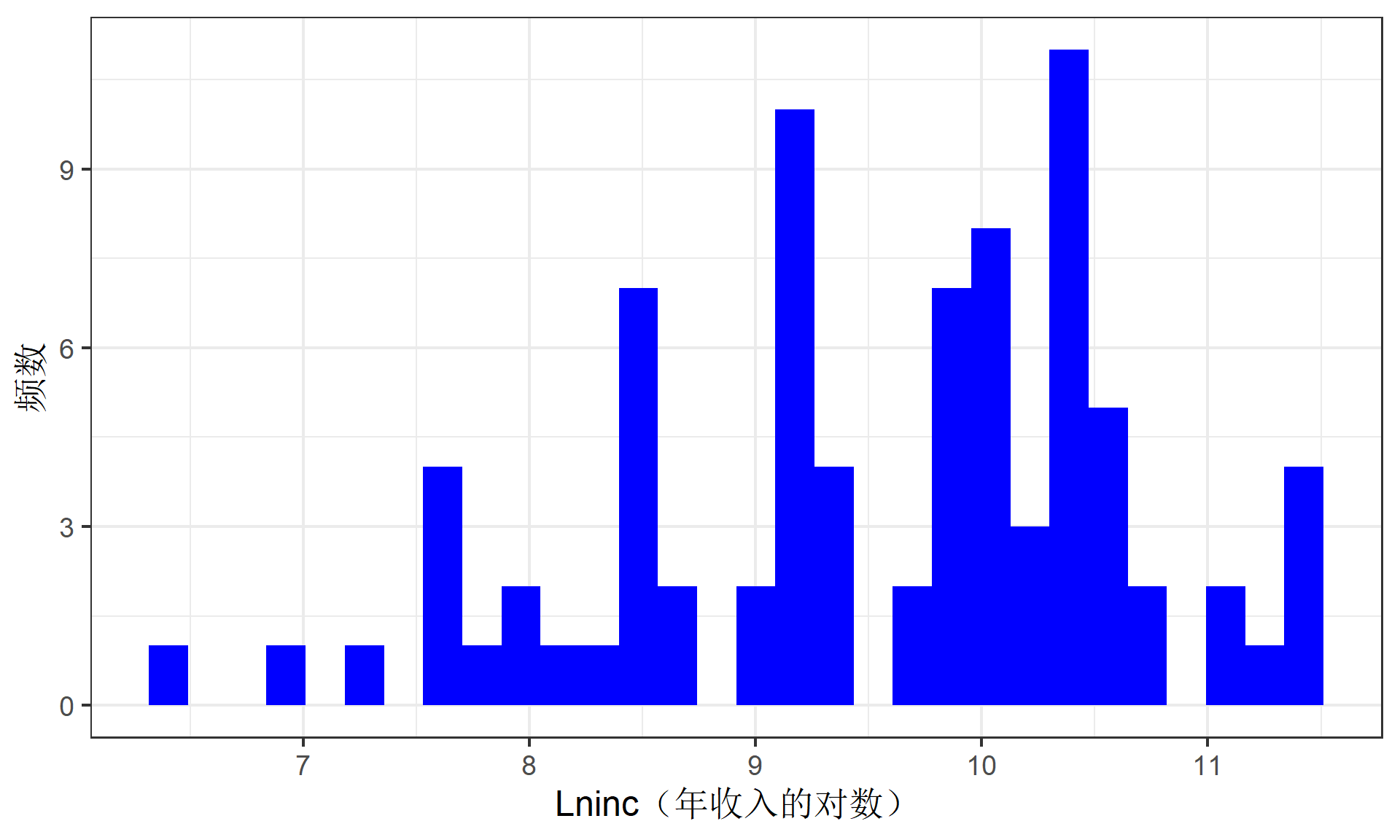
数据的转换:对于右偏分布较严重的变量,即右侧异常值较多,自然对数(ln())可以使其更加对称。比如,年收入及其对数的分布。
(示例)CGSS数据的清洗:异常值对数化处理后
本节结束
![]()
第2章 数据收集、整理和清洗 [2-3节] 资料整理和数据清洗