研究方法与数据类型
不同研究方法会产生不同类型数据:
数据获取与数据类型
从产生数据的方式方法上又可以有:
问卷数据
访谈数据
文献数据
痕迹数据:大数据。(注意不是痕迹证据!)
在获得数据的同时, 应该还有一份数据,是记录数据获得过程的,通常称之为日志, 它要记录数据是从哪里来的、什么情况下得到的、数据的基本特征又是什么, 比如文字数据有多少页、图片数据有多少张,这就是日志数据
数字化与数值化
从是否数字化来看:
从是否数值化来看:
载体形式1/2
从具体形态来看:
文本数据:
- 访问、观察中的文字记录
- 数字化的字符形态的数据
- 任何文字加载体的数据,比如文字加载于纸张、羊皮卷等
图片数据:
- 访谈时拍的照片、搜集到的图片、照片的底片等等
- 数字化为像素点形态的图片数据
- 任何图形加载体的数据,比如图形加载于纸张、胶片、计算机存储等
载体形式2/2
音频数据:数字化为波形形态的音频数据。
- 访问录音、观察中的语音日志、搜集到的音频记录等。
- 任何音频加上载体,比如音频加载于钢丝、胶片、磁带、光碟、磁碟、闪存盘、硬盘等
视频数据:数字化为像素点加上波形形态的视频数据。
- 访谈时的全程录像、搜集到的各种各样视频。
- 视频加上载体,比如比如视频加载于胶片、光碟、闪存盘、硬盘等
实物数据:任何有实物才可以完整保存信息的实物载体数据
- 访谈中搜集到的实物、观察中观察到的实物,比如出土文物、建筑等
(提问)课堂思考1/3
以上关于数据来源与形式的分类是完全是互斥的吗?
以调查问卷为例:
以上的分类并不完全是互斥的,只是根据显性的特征来做一些划分,其实我们很难找到一个标准把数据的形态类型区分得非常清楚。
(提问)课堂思考2/3
数字与数值是一个意思吗?
图片、音频、视频看起来的确是数字的,但数字不等于数值!
传统照片不是数字的。
数码照片的数字指的是像素点的数字
音频、视频是同样的道理。
(提问)课堂思考3/3
“老师,不管什么时候我都要用计算机做笔记的。”
信息化时代,传统手写记录的文本数据是不是越来越没有价值?
用计算机或各类终端设备来做电子化记录。
用笔和本子做传统记录。
原始数据和研究数据
“老师,我要做一个研究”
“你的数据从哪里来?”
根据数据是否能够直接用于研究分析,数据的状态可以分为:
原始数据:一般不能直接用于研究。
研究数据:是处理为结构化的、有变量、数值、变量、属性标签的数据。
已有数据和更新数据
根据研究数据的持续性,数据的状态有:
1.已经存在的数据。公开数据、正式出版数据、发布的数据,都可以直接使用。
2.将要产生的数据。是系统采集的、不断在推进补充的数据。
一手数据和二手数据
根据研究数据是否由研究者本人产生,数据的状态可分为:
一手数据:是指自己调查获取的数据。自己调查数据是一个不得已的选择,对任何研究者而言,都应该是第二选择而不是第一选择。
二手数据:是指已经被使用过的数据,拿来再做分析。如果你的研究能够使用已经存在的数据,尤其是很多人用过的数据,那么最好用这样的数据(为什么呢?)。
数据获取权限
研究数据的获取权限一般有如下情形:
无需授权就可以使用的数据。正式出版物提供的数据只需要在使用说明中正式说明出处,就不需要授权。
需要申请授权的、公开的数据。大多数的学术研究数据,如果你要使用,是需要申请并且被授权。
需要通过授权的、未公开的数据。行为痕迹管理机构的数据,包括政府数据、赢利和非赢利服务机构的数据,都属于这类数据。
政府数据:几乎任何一笔收入,都是经过机构管理的,都有痕迹数据。
银行数据:每个人都有银行账号,只要是经过银行卡的,都会留下数据。
电信数据:只要是通过网络通信的数据,都会留下数据记录。
“老师,他们保存多久呀?”
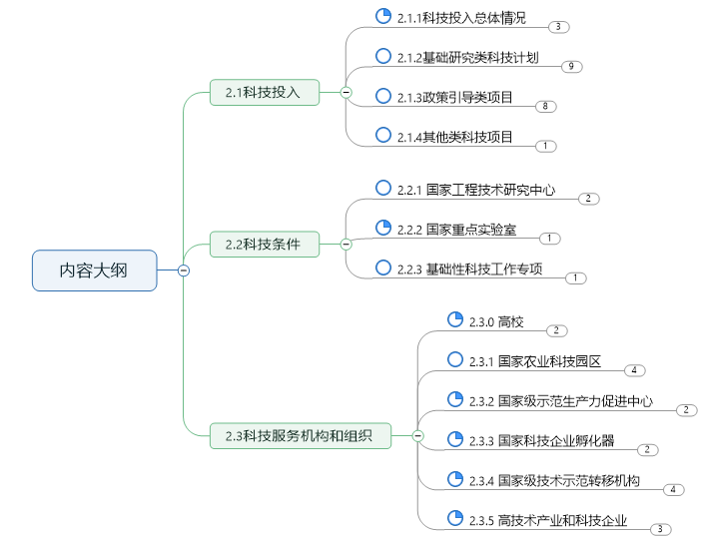
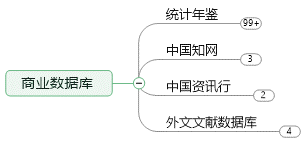
综合型数据平台1(国内文献和数据)
国内文献和统计数据:
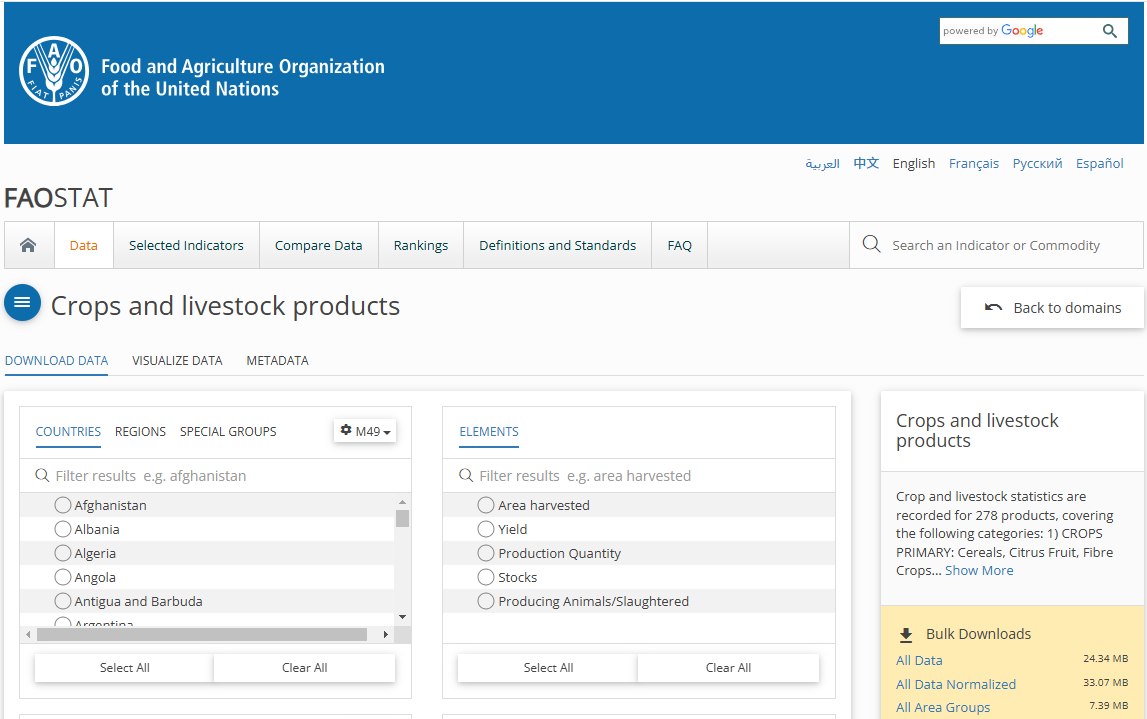
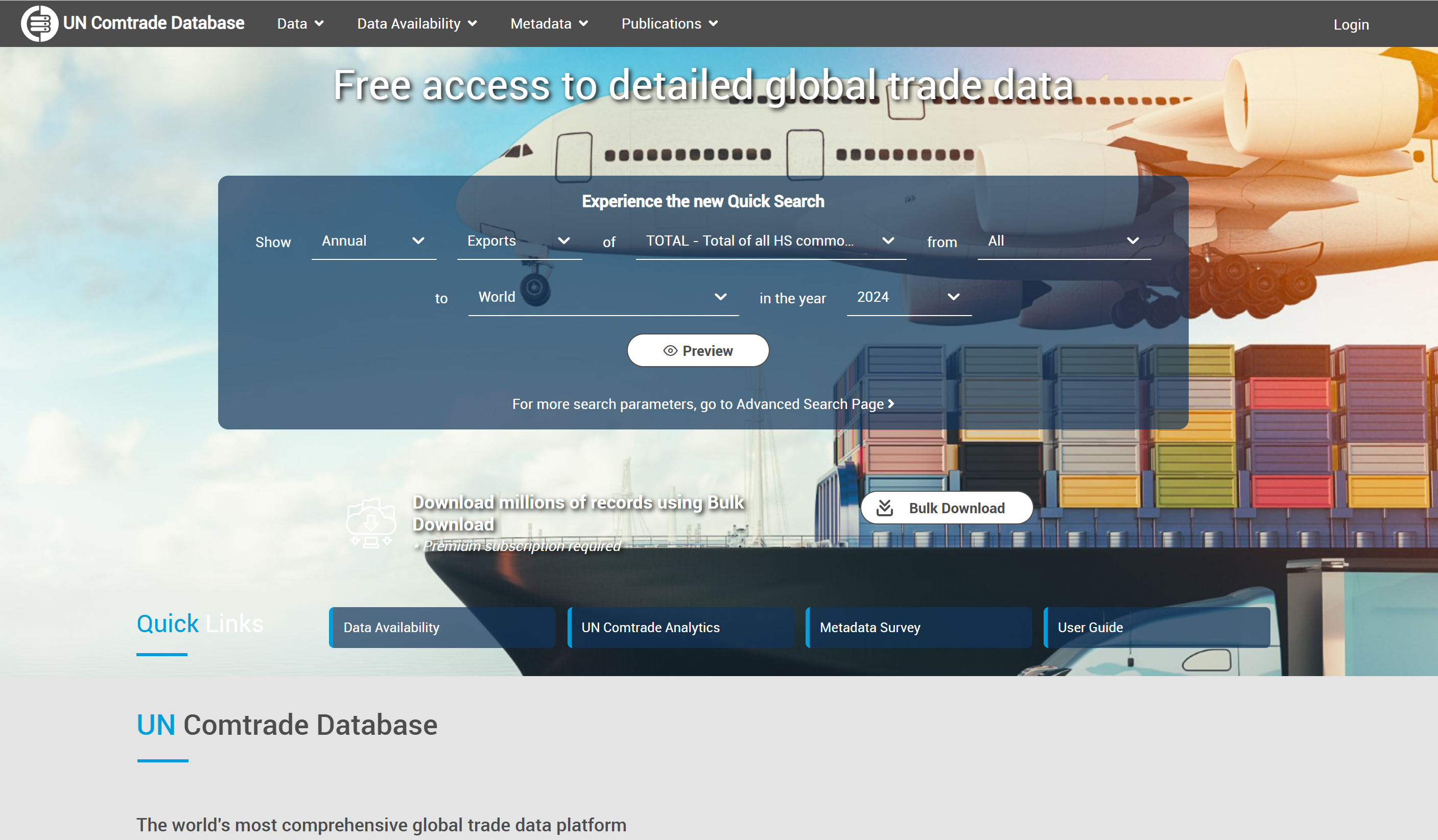
综合型数据平台2(国外文献和数据)
国外文献和统计数据:
开放宏观数据库(国际组织):典型数据集
以下是一些重要的国际组织开放的宏观数据集:
开放宏观数据库(国际组织):数据集获取
上述数据集具有如下几个特点:
数据集具有开放性,可以直接获取。
数据集具有权威性,是国际组织公开发布的数据。
数据集具有系统性,是国际组织多年积累的数据。
数据集具有复杂性,一般具有结构化关联数据子集。
因此,上述数据集的获取,我们需要注意:
具备对数据集的专业内容的深度理解能力。
具备对数据集的结构化关系的数据处理能力。
具备对数据集选择性参数化编程的调用能力。
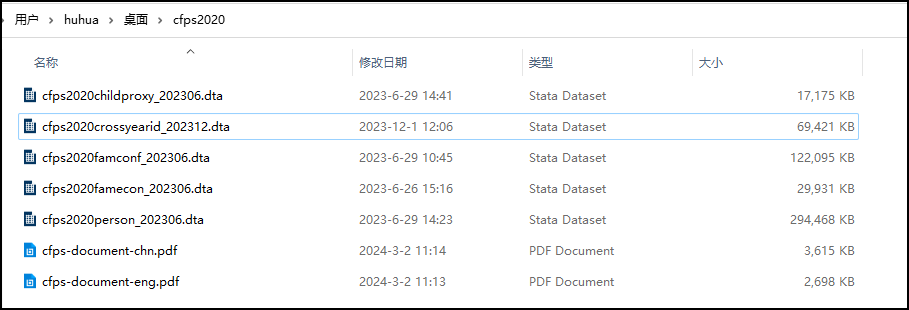
示例1:北大/中国家庭追踪调查(CFPS)的数据申请
示例1:北大/中国家庭追踪调查(CFPS)的数据申请
示例1:北大/中国家庭追踪调查(CFPS)的数据申请
示例1:北大/中国家庭追踪调查(CFPS)的数据申请
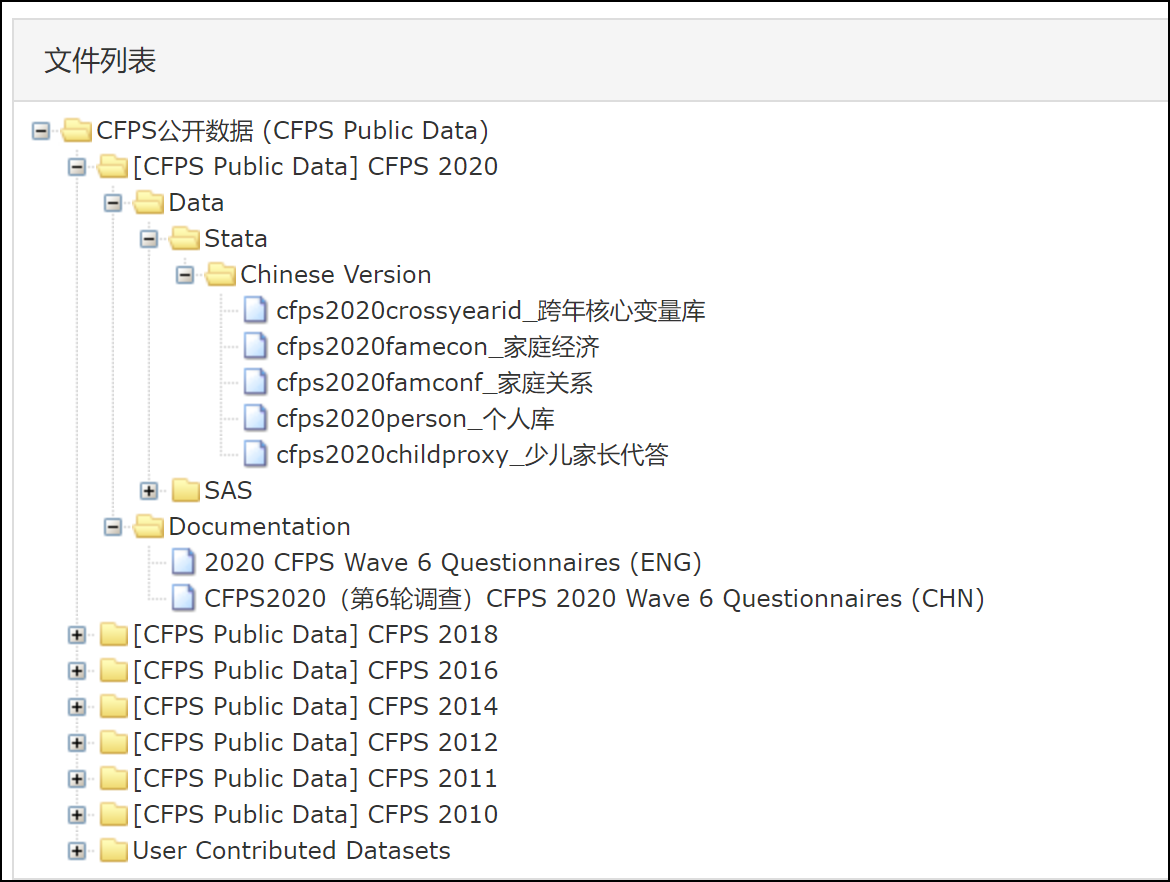
示例1:北大/中国家庭追踪调查(CFPS)数据集列表
示例1:北大/中国家庭追踪调查(CFPS)数据文件
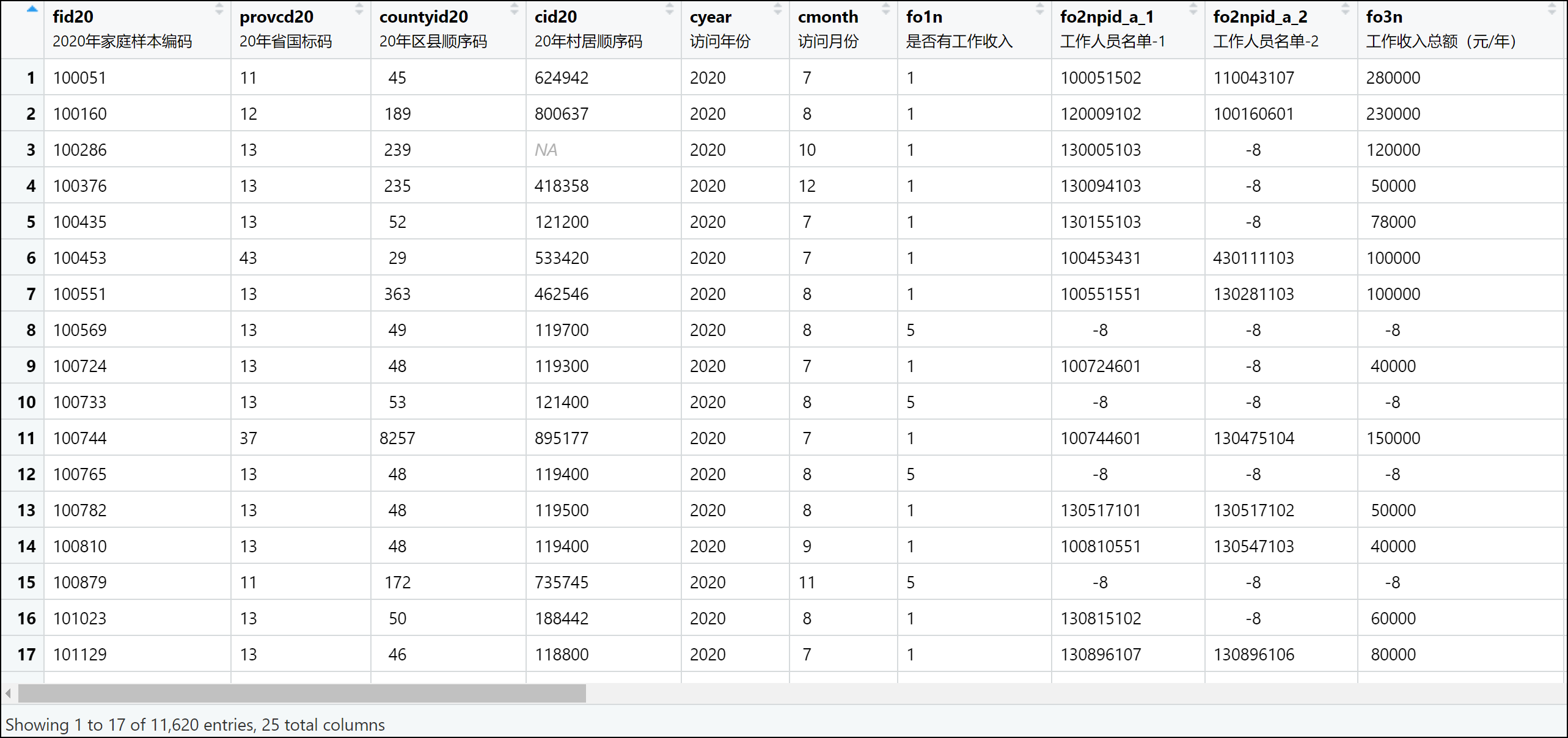
示例1:北大/中国家庭追踪调查(CFPS)工资性收入部分数据
示例1:北大/中国家庭追踪调查(CFPS)工资性收入部分问卷
示例2:北大/中国健康与养老追踪调查(CHARLS)的数据申请
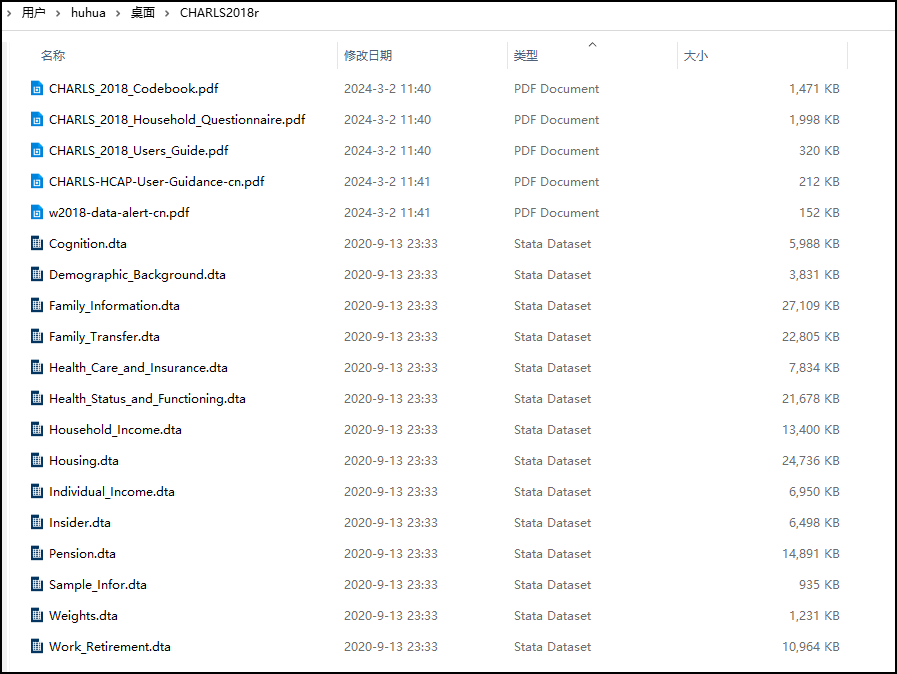
示例2:北大/中国健康与养老追踪调查(CHARLS)数据列表
完整的子数据集包括:
- 基本信息、家庭信息、家庭经济交往、健康状况与功能
- 认知和抑郁、知情人信息收集、医疗保健与保险、工作和退休、养老金
- 家户收入、支出及资产、个人收入及资产、房产和住房情况
- 样本权重、样本信息
示例2:北大/中国健康与养老追踪调查(CHARLS)数据文件
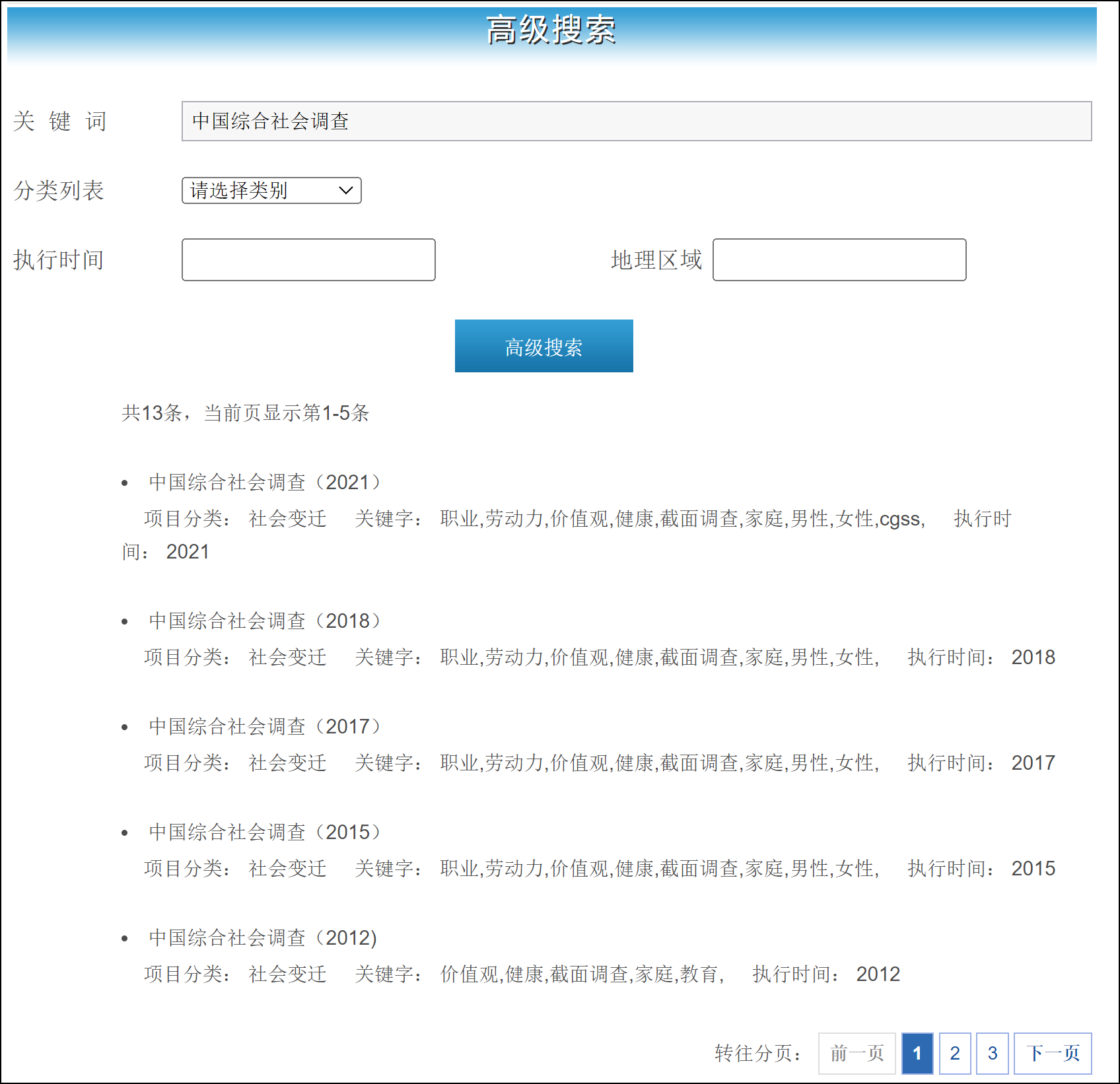
示例2:人大/中国综合社会调查(CGSS)数据集列表
示例2:人大/中国综合社会调查(CGSS)2021数据文件
本项目共3份文档/数据
中国综合社会调查(2021)问卷, 格式: PDF
原始数据,格式stata,变量数700,样本量8148
原始数据,格式spss,变量数700,样本量8148
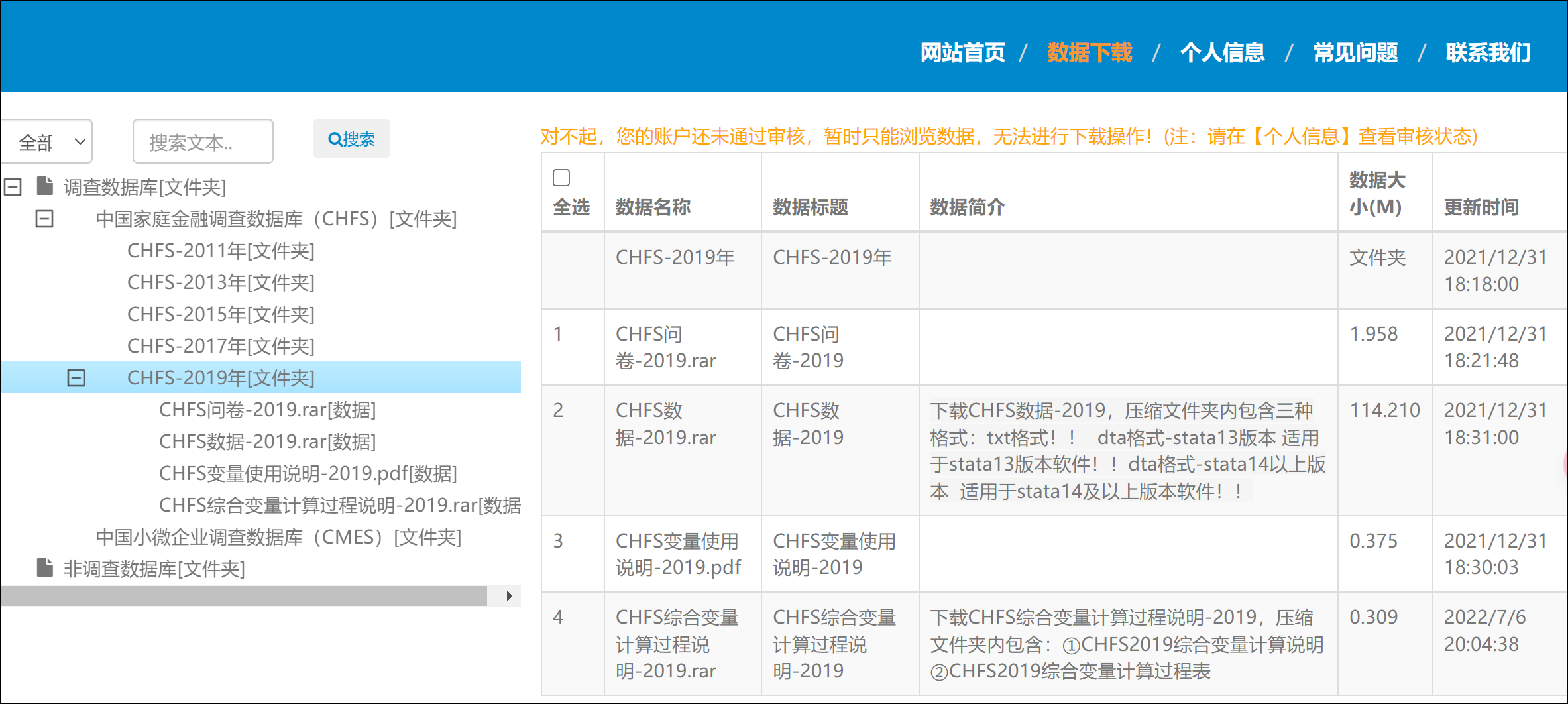
示例2:西南财大/中国家庭金融调查数据集(CHFS)
二手数据使用的几个问题
二手数据可以进行的反复多次的再分析。
- 同样的数据集,使用不同的方法,可以进行检验或者商榷;
- 同样的数据集,用于不同的研究主题和研究目的,则可以用于不同的研究目的。
- 不同的数据集,不同的方法,可以以达成特定的研究目的。
使用二手数据,应按照学术规范说明数据来源。(千万别忘记!)
使用二手数据,往往面临数据处理、转换、加工等技术性的问题。
使用综合性数据库还是专门性数据库,这是个问题!
- 综合性数据不一定能够满足专业兴趣的要求和需求。
- 专业性数据库可能比较专业,难以与你的研究目标一致。
二手数据引用声明(CFPS)
国外绝大部分高质量经济学期刊都明确要求作者提供能供读者复制论文结果的数据或数据申请渠道及分析代码。近些年,国内经济学期刊也陆续提出此要求。
对于CFPS用户来说,应如何回应期刊这一要求?能否将CFPS 微观数据直接放在期刊网站上?
在CFPS 用户注册申请数据的用户协议中已明确指出,用户不能将CFPS 微观数据直接放置于包括期刊网站在内的第三方平台上,无论是原始完整数据,还是整理提取后的数据(如提取部分变量、进行清理后的子样本数据集等)。
CFPS微观数据的版权归北京大学中国社会科学调查中心所有,不可在未经授权的情况下被分享于其他平台。
互联网公开数据爬取
互联网(WWW)世界天然存放了海量的公开信息和数据,是我们收集二手数据的一个重要平台。
主要的开放形式有:
需要的相关技能:
示例:农产品市场价格数据的爬虫自动抓取1
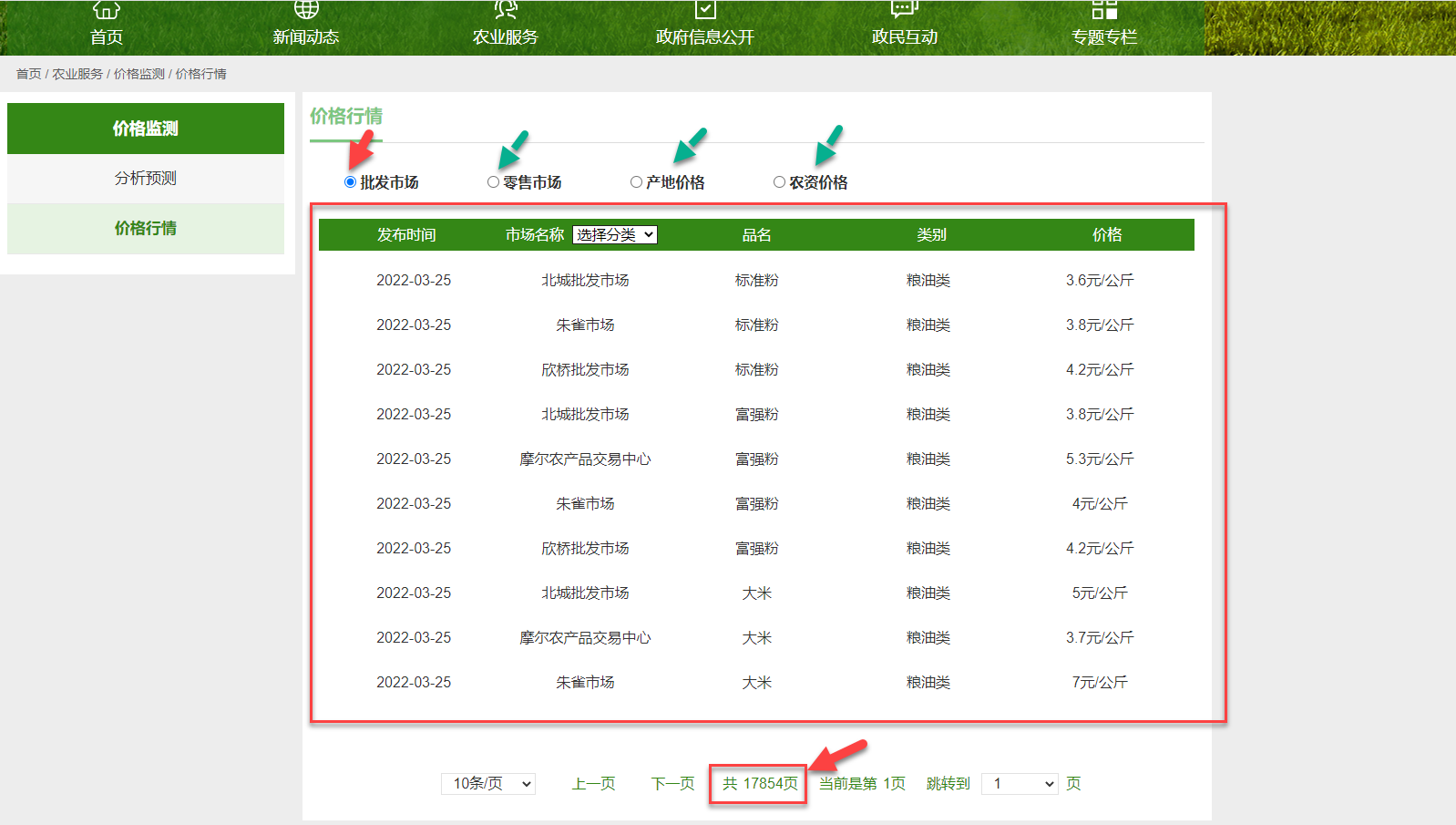
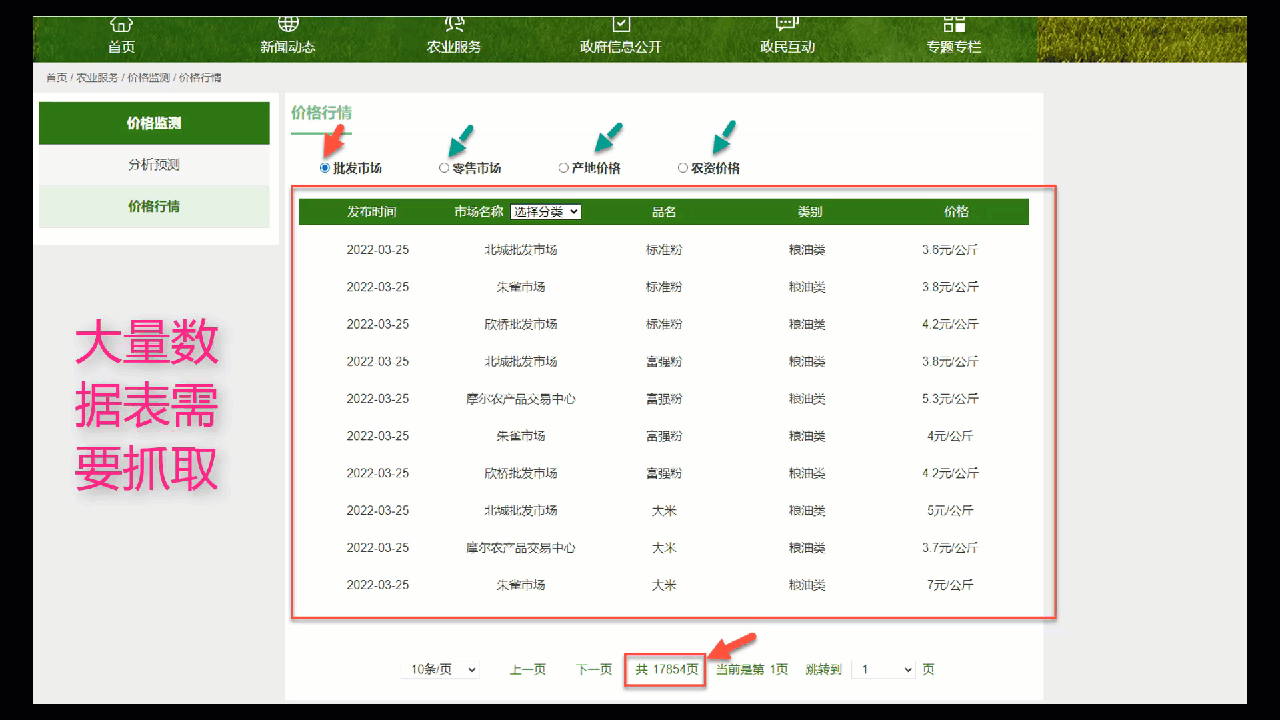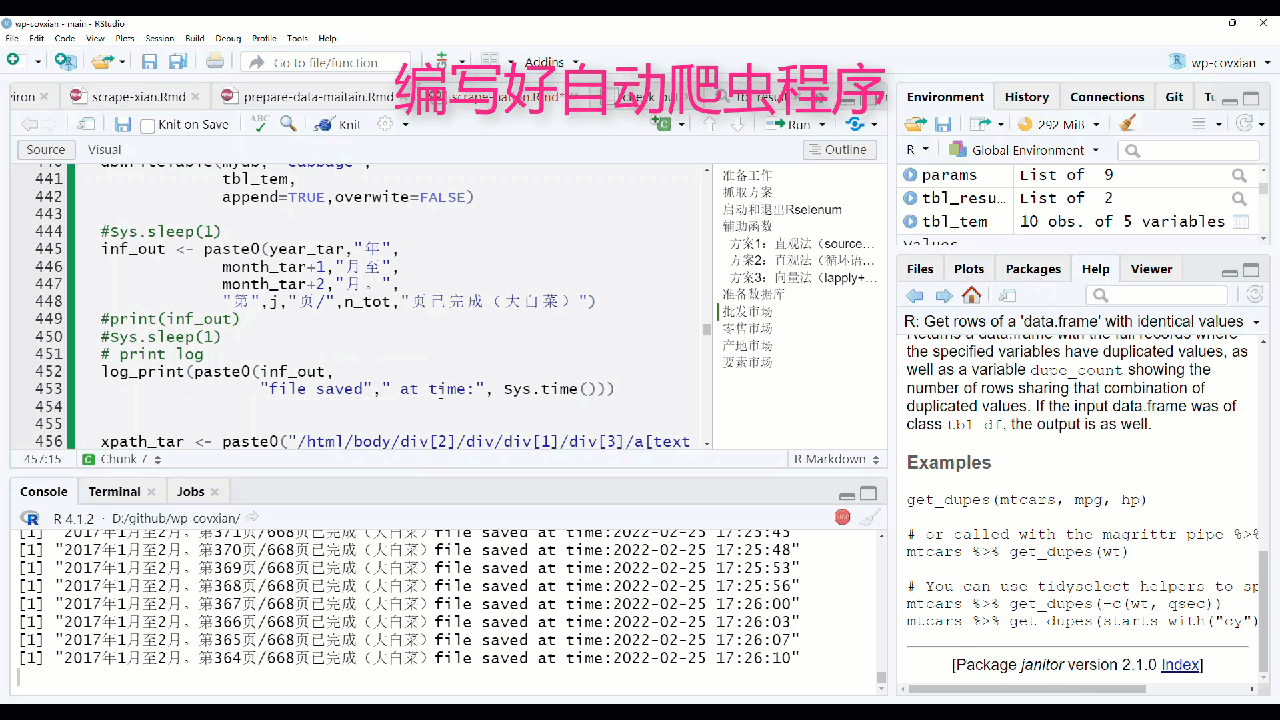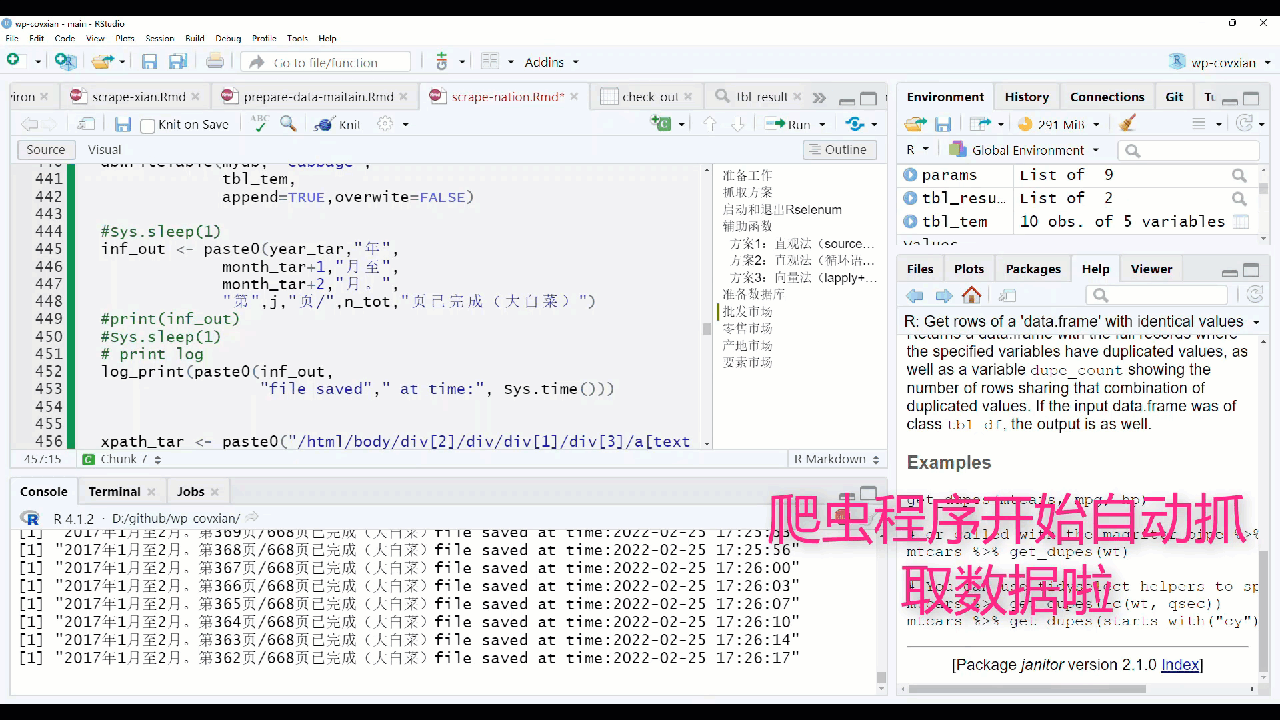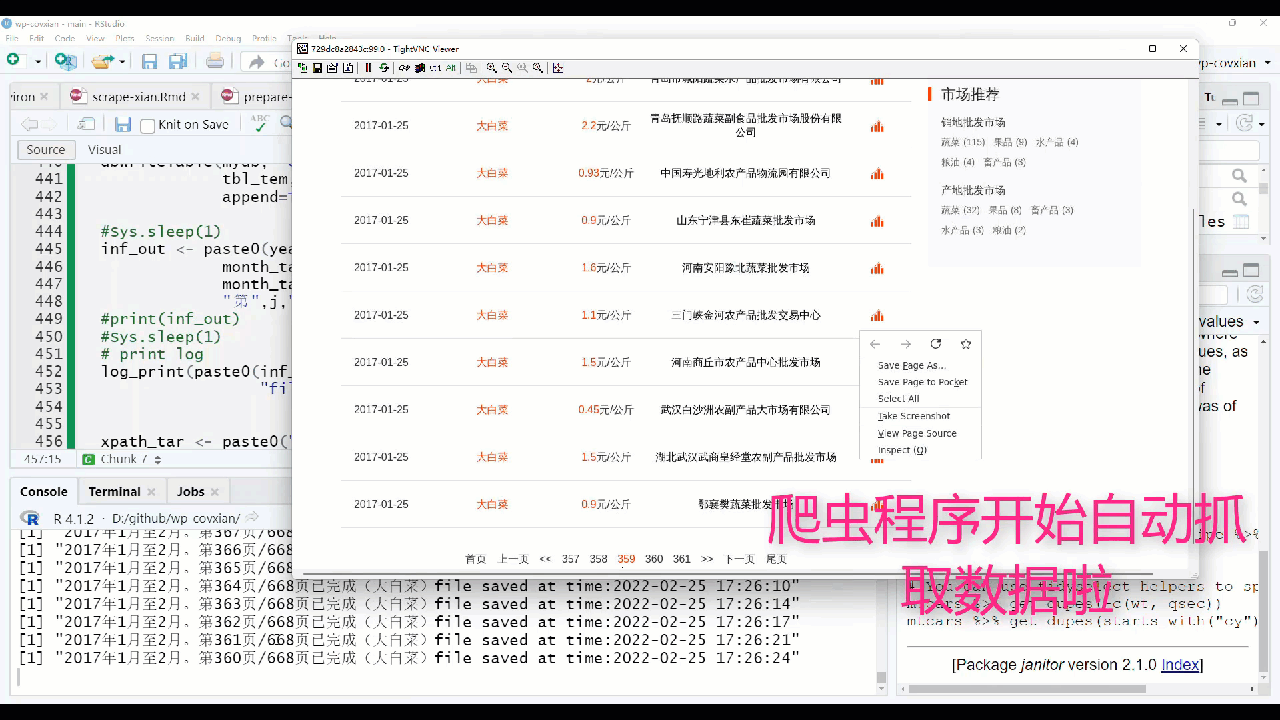
西安市农业农村局(网址)每日会发布不同农产品、多个市场(批发市场、零售市场如超市等)的农产品价格数据。
网站页面分析:
编程爬虫自动化数据抓取方案:
自填式问卷调查
自填式问卷调查:没有调查员协助的情况下由被调查者自己完成调查问卷 问卷递送方法:调查员分发、邮寄、网络、媒体
优点:要求调查问卷结构严谨,有清楚的说明
缺点:
- 问卷的返回率比较低
- 不适合结构复杂的问卷
- 调查周期比较长
- 数据搜集过程中出现的问题难于及时采取调改措施
面访式问卷调查
面访式问卷调查:调查员与被调查者面对面提问、被调查者回答的一种调查方式。
优点:
- 可提高调查的回答率
- 可提高调查数据的质量
- 能调节数据搜集所花费的时间
缺点:
电话式问卷调查
电话式问卷调查:通过电话向被调查者实施调查。
特点:
- 速度快,能在短时间内完成调查
- 适合于样本单位十分分散的情况
局限性:
- 如果被调查者没有电话,调查将无法实施
- 访问的时间不能太长
- 使用的问卷需要简单
- 被访者不愿意接受调查时,难以说服
收集数据的几点忠告
学生:“既然有这么多的数据,这门课是不是可以不学了?”
回答:“这门课你不仅要学,而且要认认真真地学”
掌握数据采集的知识与能力,是用好数据的基础。如果不了解数据是怎么获得的,就没有能力甄别已有的数据到底可不可靠、可不可用,甚至都不知道上哪儿去找数据。
第一,研究数据有多种、多重的来源,好好运用既有的数据是研究者的第一选择;
第二,获取已经存在的数据有很多个方法,也有多种途径
第三,万一没有办法获取需要的研究数据,那就只好自己动手。